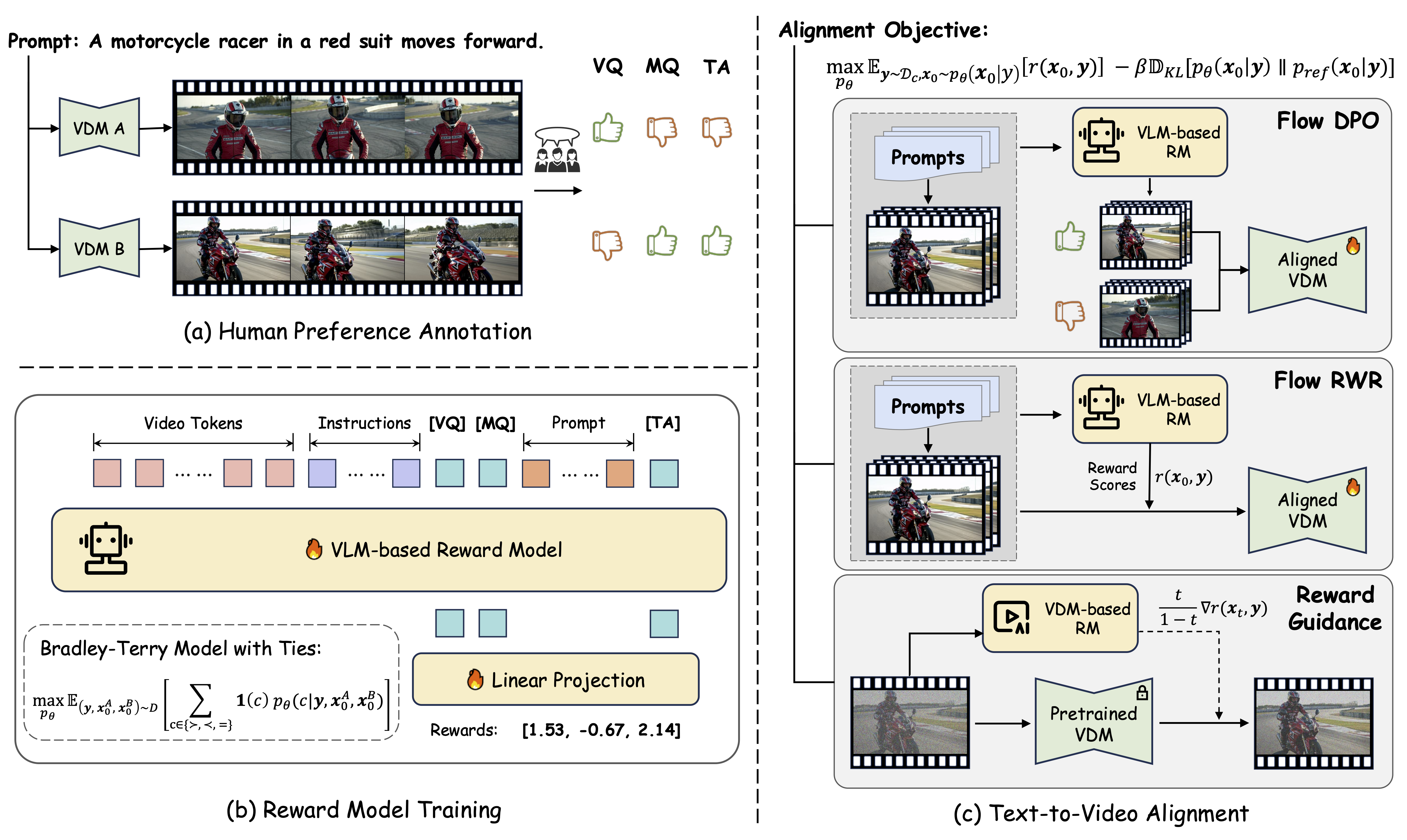
This repository open-sources the VideoReward component -- our VLM-based reward model introduced in the paper Improving Video Generation with Human Feedback. VideoReward evaluates generated videos across three critical dimensions:
- Visual Quality (VQ): The clarity, aesthetics, and single-frame reasonableness.
- Motion Quality (MQ): The dynamic stability, dynamic reasonableness, naturalness, and dynamic degress.
- Text Alignment (TA): The relevance between the generated video and the text prompt.
This versatile reward model can be used for data filtering, guidance, reject sampling, DPO, and other RL methods.
- [2025.02.08]: 🔥 Release the VideoGen-RewardBench and Leaderboard.
- [2025.02.08]: 🔥 Release the Code and Checkpoints of VideoReward.
- [2025.01.23]: Release the Paper and Project Page.
Clone this repository and install packages.
git clone https://github.com/KwaiVGI/VideoAlign
cd VideoAlign
conda env create -f environment.yamlPlease download our checkpoints from Huggingface and put it in ./checkpoints/.
cd checkpoints
git lfs install
git clone https://huggingface.co/KwaiVGI/VideoReward
cd ..python inference.pycd dataset
git lfs install
git clone https://huggingface.co/datasets/KwaiVGI/VideoGen-RewardBench
cd ..python eval_videogen_rewardbench.py1. Prepare your own data as the instruction stated.
sh train.shOur reward model is based on QWen2-VL-2B-Instruct, and our code is build upon TRL and Qwen2-VL-Finetune, thanks to all the contributors!
Please leave us a star ⭐ if you find our work helpful.
@article{liu2025improving,
title={Improving Video Generation with Human Feedback},
author={Jie Liu and Gongye Liu and Jiajun Liang and Ziyang Yuan and Xiaokun Liu and Mingwu Zheng and Xiele Wu and Qiulin Wang and Wenyu Qin and Menghan Xia and Xintao Wang and Xiaohong Liu and Fei Yang and Pengfei Wan and Di Zhang and Kun Gai and Yujiu Yang and Wanli Ouyang},
journal={arXiv preprint arXiv:2501.13918},
year={2025}
}