Application of Transfer learning and Deep Feature Extraction Networks to detect COVID-19 from Chest-CT Scans and Chest-X_rays
Dataset Used: https://github.com/abr-98/COVID_dataset
Reference Papers:
- https://doi.org/10.1016/j.bspc.2021.102588 ## Architecture Adaptation
- https://doi.org/10.1016/j.imu.2020.100360 ## Architecture Adaptation
- https://www.nature.com/articles/s41598-020-76550-z
- https://link.springer.com/article/10.1007/s00330-021-07715-1
- https://openaccess.thecvf.com/content_cvpr_2017/papers/Lin_Feature_Pyramid_Networks_CVPR_2017_paper.pdf
https://github.com/abr-98/COVID_dataset/tree/main/COVID_CT
Contains 12058 images of processed city scan images of chest of patients, the metadata contains the labels. Images are present in '.tif' format.
The followed Architecture is a modified approach based on the architecture proposed by the authors of: https://doi.org/10.1016/j.bspc.2021.102588.

In the publication, the defined size of the image is (512,512,1), in this work the size of the image used is reduces to (256,256,1). The original work uses softmax and categorical cross-entropy and a 2-node output, which has been modified to 1-node in the output layer, sigmoid function, and binary-crossentropy. No imagedatageneration is used in the work.
The authors have used a ResNet based Feature Pyramid Network(FPN) for better discovery of features and increase in performance of the network. The ResNet are deep convolutional networks with skip connections which helps with the issue of Vanishing and Exploding Gradients. https://openaccess.thecvf.com/content_cvpr_2016/papers/He_Deep_Residual_Learning_CVPR_2016_paper.pdf the original publication for ResNets.
The FPNs are deep feature extracting networks based on the idea of Image Pyramids. Image Pyramids stack different spatial dimensional transforms of the same images, using Upsampling, Subsampling and gaussian filtering operations. The idea is different dimensions help to capture a variety of different features. The Gaussian filters help to cope with data loss and control the blurring. Normally, on spatial data, we capture spatial data on two axes (x,y). Image Pyramids stacks the dimensions of images and adds another dimension lambda to the space, for feature discovery.

The links https://medium.com/@vad710/cv-for-busy-devs-scale-space-9368e3be938b, https://medium.com/analytics-vidhya/a-beginners-guide-to-computer-vision-part-4-pyramid-3640edeffb00 can be used as guides on Image pyramids.
The image pyramids are very computationally inefficient, so, FPNs have been introduced.(https://openaccess.thecvf.com/content_cvpr_2017/papers/Lin_Feature_Pyramid_Networks_CVPR_2017_paper.pdf)

The above figure tries to project an idea. In this type of architecture, we use convolutional layers directly to reduce the image size. It has two limbs: A botton-up limb and a top-down limb. The Bottom-Up limb decreases the dimensions of the image, the top down layers are used to upsample and extract features from each of the spatial dimension.

The image shows the implementing architecture. The Bottom-up limb and the top-down limb is concatenated with a 1x1 conv. 1x1 conv helps in dimension reduction, channelwise. The concatenation is done to decrease the aliasing effect of the upsampling, that doubles the size of image in the top-down limb. The upsampling layer simply increases the dimension of the image by twice.
The resource https://jonathan-hui.medium.com/understanding-feature-pyramid-networks-for-object-detection-fpn-45b227b9106c can be used for better understanding.
The model has achieved an test accuracy of 99%
The Accuracy curve

The loss curve

Available: https://github.com/abr-98/COVID_dataset
Subset of Covidx dataset as benchmark proposed by authors of https://www.nature.com/articles/s41598-020-76550-z. The details of the dataset can be found on https://github.com/abr-98/COVID_dataset.
Architecture proposed by the authors of https://www.nature.com/articles/s41598-020-76550-z:
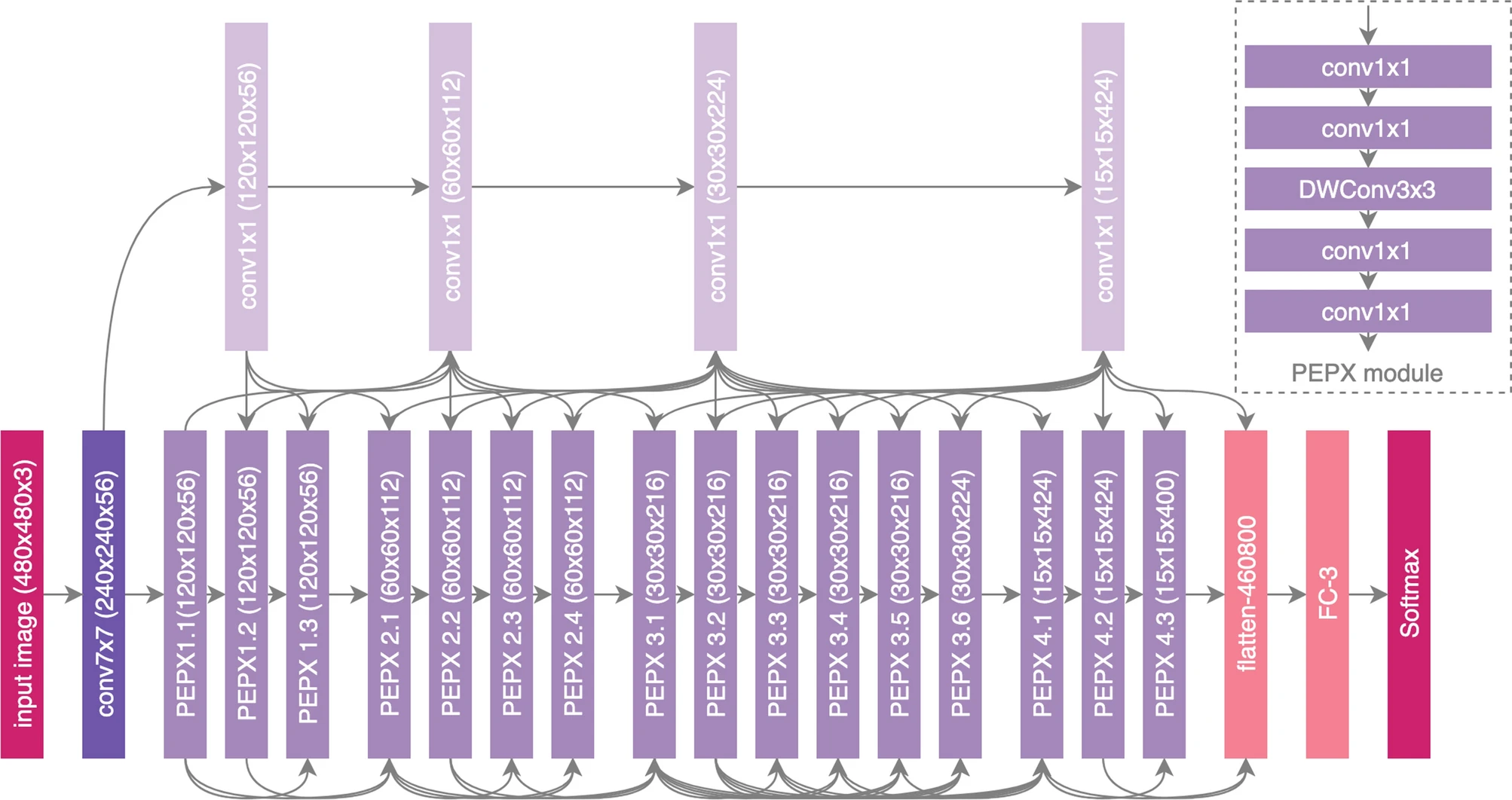
The archtecture is a light-weight projection-expansion-projection-extenstion (PEPX) module for deep feature extraction from Chest-X-rays.
For this work, a slightly modified approach proposed by the authors of https://doi.org/10.1016/j.imu.2020.100360 have been adapted:

The architecture uses two of the most used and important deep convolutional networks Residual, and Xception Network (https://openaccess.thecvf.com/content_cvpr_2017/papers/Chollet_Xception_Deep_Learning_CVPR_2017_paper.pdf). Xception Networks stands for extreme inception and builds on the idea of 1x1 convolution to decrease the computational cost to a further level. Xception uses a concept of seperable convolutional layers. It uses seperable depth-wise convolutional network and a point-wise convolutional layers. The idea is to explore each channel spatially and then go for the depth wise feature discovery.
References for Xception:
- https://maelfabien.github.io/deeplearning/xception/#
- https://towardsdatascience.com/a-comprehensive-introduction-to-different-types-of-convolutions-in-deep-learning-669281e58215
- https://towardsdatascience.com/an-intuitive-guide-to-deep-network-architectures-65fdc477db41
The proposed architecture parallely uses these two networks for feature extraction purposes and then passes the concatenation of the features obtained through another convolutional layers and finally uses softmax to predict.
Originally, the proposed architecture classified in three classes, so used softmax, but in this work, the model has been modified for a binary clasification of Normal and Covid cases. The input data dimension has also been modified.
We have achieved a 97% accuracy using the best model on validation dataset.

The above image represents the classification report for the proposed network.