Looking Backward: Streaming Video-to-Video Translation with Feature Banks
Feng Liang,
Akio Kodaira,
Chenfeng Xu,
Masayoshi Tomizuka,
Kurt Keutzer,
Diana Marculescu
The International Conference on Learning Representations (ICLR), 2025
私たちのStreamV2Vは、RTX 4090 GPUでリアルタイムのビデオ・ツー・ビデオ翻訳を実行することができます。動画をチェックして、自分で試してみてください!
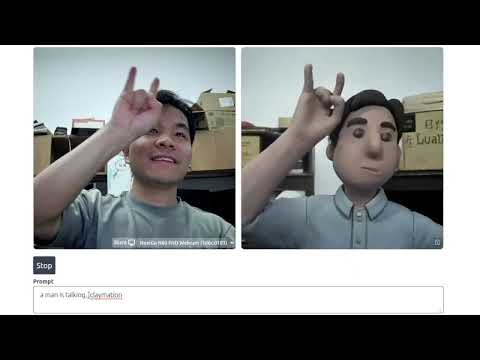
機能面では、StreamV2Vは顔交換(例:イーロン・マスクやウィル・スミス)やビデオのスタイリゼーション(例:クレイアニメーションやドゥードルアート)をサポートしています。動画をチェックして、結果を再現してみてください!

StreamV2Vはvid2vidタスクのために設計されていますが、txt2imgアプリケーションとシームレスに統合できます。各画像ごとのStreamDiffusionと比較して、StreamV2Vは継続的にテキストから画像を生成し、よりスムーズな移行を提供します。 ビデオをチェックして、自分で試してみてください!

インストールガイドをご覧ください。
はじめにをご覧ください。
カメラガイド付きデモをご覧ください。
デモの連続的なテキストから画像へをご覧ください。
StreamV2Vはテキサス大学オースティン校の研究ライセンスの下でライセンスされています。
StreamV2Vはオープンソースコミュニティに大きく依存しています。当社のコードは、StreamDiffusion と LCM-LORA からコピーして適応されています。SD 1.5 モデルの基本以外にも、CIVITAI から多様なLORAsを使用しています。
StreamV2Vを研究に使用する場合や、論文で公開されているベースライン結果を参照する場合は、以下のBibTeXエントリを使用してください。
@article{liang2024looking,
title={Looking Backward: Streaming Video-to-Video Translation with Feature Banks},
author={Liang, Feng and Kodaira, Akio and Xu, Chenfeng and Tomizuka, Masayoshi and Keutzer, Kurt and Marculescu, Diana},
journal={arXiv preprint arXiv:2405.15757},
year={2024}
}
@article{kodaira2023streamdiffusion,
title={StreamDiffusion: A Pipeline-level Solution for Real-time Interactive Generation},
author={Kodaira, Akio and Xu, Chenfeng and Hazama, Toshiki and Yoshimoto, Takanori and Ohno, Kohei and Mitsuhori, Shogo and Sugano, Soichi and Cho, Hanying and Liu, Zhijian and Keutzer, Kurt},
journal={arXiv preprint arXiv:2312.12491},
year={2023}
}