Looking Backward: Streaming Video-to-Video Translation with Feature Banks
梁丰,
Akio Kodaira,
徐晨丰,
Masayoshi Tomizuka,
Kurt Keutzer,
Diana Marculescu
The International Conference on Learning Representations (ICLR), 2025
我们的StreamV2V可以在一块RTX 4090 GPU上实时执行视频到视频的翻译。查看视频并亲自尝试!
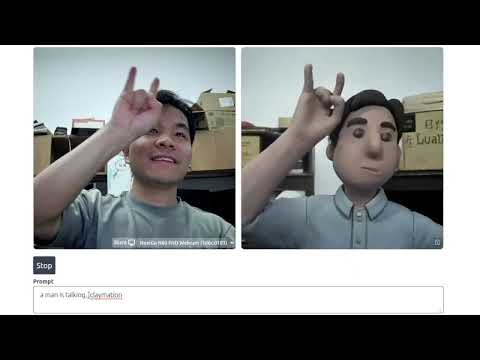
在功能方面,我们的StreamV2V支持面部交换(例如:变成埃隆·马斯克或威尔·史密斯)和视频风格化(例如:变成黏土动画或涂鸦艺术)。查看视频并复现结果!

尽管StreamV2V是为vid2vid任务设计的,但它可以无缝集成到txt2img应用程序中。与每图像的StreamDiffusion相比,StreamV2V 连续地从文本生成图像,提供了更加平滑的过渡。查看视频并亲自试试!

请查看安装指南。
请查看开始使用说明。
请查看带摄像头的演示指南。
请查看连续的文生图的演示指南.
StreamV2V根据德克萨斯大学奥斯汀分校研究许可证进行许可。
StreamV2V在很大程度上依赖于开源社区。我们的代码是从StreamDiffusion 和 LCM-LORA 复制并适应的。除了基础的SD 1.5 模型外,我们还使用了CIVITAI 的多种LORAs。
如果您在研究中使用StreamV2V或希望引用论文中发布的基准结果,请使用以下BibTeX条目。
@article{liang2024looking,
title={Looking Backward: Streaming Video-to-Video Translation with Feature Banks},
author={Liang, Feng and Kodaira, Akio and Xu, Chenfeng and Tomizuka, Masayoshi and Keutzer, Kurt and Marculescu, Diana},
journal={arXiv preprint arXiv:2405.15757},
year={2024}
}
@article{kodaira2023streamdiffusion,
title={StreamDiffusion: A Pipeline-level Solution for Real-time Interactive Generation},
author={Kodaira, Akio and Xu, Chenfeng and Hazama, Toshiki and Yoshimoto, Takanori and Ohno, Kohei and Mitsuhori, Shogo and Sugano, Soichi and Cho, Hanying and Liu, Zhijian and Keutzer, Kurt},
journal={arXiv preprint arXiv:2312.12491},
year={2023}
}