-
Notifications
You must be signed in to change notification settings - Fork 82
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
Showing
2 changed files
with
49 additions
and
55 deletions.
There are no files selected for viewing
80 changes: 49 additions & 31 deletions
80
docs-2.0/nebula-dashboard-ent/4.cluster-operator/1.overview.md
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -1,50 +1,68 @@ | ||
| # Cluster overview | ||
| # Cluster Overview | ||
|
|
||
| This topic introduces the **Overview** page of Dashboard. | ||
| This topic introduces the **Cluster Overview** page of Dashboard, which contains the following parts: | ||
|
|
||
| - **Info Overview** | ||
| - **Cluster Topology** | ||
| - **Monitoring Screen** | ||
|
|
||
| ## Entry | ||
|
|
||
| 1. At the top navigation bar of the Dashboard Enterprise Edition page, click **Cluster Management**. | ||
| 2. Click **Detail** on the right of the cluster management page to check the overview of a specified cluster. | ||
|
|
||
| ## Overview | ||
|
|
||
| The **Overview** page has the following parts: | ||
|
|
||
| - Cluster key information | ||
| - Cluster topology | ||
| - Node monitoring | ||
| - Service monitoring | ||
| ## Info Overview | ||
|
|
||
| ### Cluster key information | ||
|
|
||
| In the cluster key information, the following information is displayed. | ||
|
|
||
| - Cluster health score: Displays the health of the cluster on a percentage basis. It is refreshed every 5 minutes, or immediately if there is an emergency level alarm. The calculation formula can be configured in the **Cluster Diagnostics** page. | ||
| - Monitoring nodes: Shows the number of online nodes/total number of nodes. | ||
| - Monitoring services: Shows the number of online services/total number of services. Different types of services are displayed separately. | ||
| - Cluster information: Displays the cluster name, create time, creator, version, owner, and version upgrade portal. | ||
| - Creation time: The total running time of the cluster. | ||
| - Service online ratio: The ratio of the cluster is in an available state. The calculation formula can be configured in the **Cluster Diagnostics** page. | ||
| - Slow queries: The number of slow queries in the cluster. | ||
| - Max QPS: The maximum QPS in the cluster. | ||
| - Max query latency: The maximum query latency in the cluster. | ||
| - Opened sessions: The total number of sessions created in the cluster. | ||
| - Cluster health score: Displays the health of the cluster on a percentage basis. It is refreshed every 5 minutes, or immediately if there is an emergency level alarm. The calculation formula can be configured on the **Cluster Diagnosis** page. | ||
| - Monitoring nodes and services: Display the number of online nodes/total nodes and the number of online services/total services. Different types of services are displayed separately. Click on  to access the [Service](./operator/service.md) page. | ||
| - Number of slow queries (5min): The number of slow queries in the cluster in the last 5 minutes. | ||
| - Newly created sessions (5min): The number of newly created sessions in the cluster in the last 5 minutes. | ||
| - Latest backup time: The latest backup time of the cluster. Click on  to access the [Backup and Restore](./operator/backup-and-restore.md) page. | ||
| - Total storage usage: The total storage usage of the cluster. Click on  to display more details. | ||
|
|
||
| ### Cluster monitoring panel | ||
|
|
||
| In the cluster monitoring panel, users can select and view monitoring data from different periods. Users can either select a custom time range or choose from predefined time ranges such as the last 5 minutes, 1 hour, 6 hours, 12 hours, 1 day, and 3 days. The monitoring panel displays the following information: | ||
|
|
||
| - QPS: The time-series diagram of the QPS. | ||
| - Query latency: The time-series diagram of the query latency. | ||
| - Query latency(P95): The time-series diagram of the query latency. | ||
| - CPU usage: The CPU usage of the cluster. | ||
| - Memory Utilization: The memory utilization of the cluster. | ||
| - Opened sessions: The total number of sessions created in the cluster. | ||
| - Slow Query: The number of slow queries in the cluster. | ||
|
|
||
| Users can click  to jump to the detailed service monitoring panel page. | ||
|
|
||
| ## Cluster topology | ||
|
|
||
| Shows the distribution and status of nodes and services in the cluster. Click **Cluster Topology** at the top of the page to enter the Cluster Topology page. | ||
|
|
||
| ## Monitoring screen | ||
|
|
||
| The monitoring screen helps users understand the health status of the cluster and the information on services and nodes at a glance. | ||
|
|
||
| Click **Switch to Monitoring Screen** to enter the monitoring screen page. | ||
|
|
||
| ### Cluster topology | ||
| 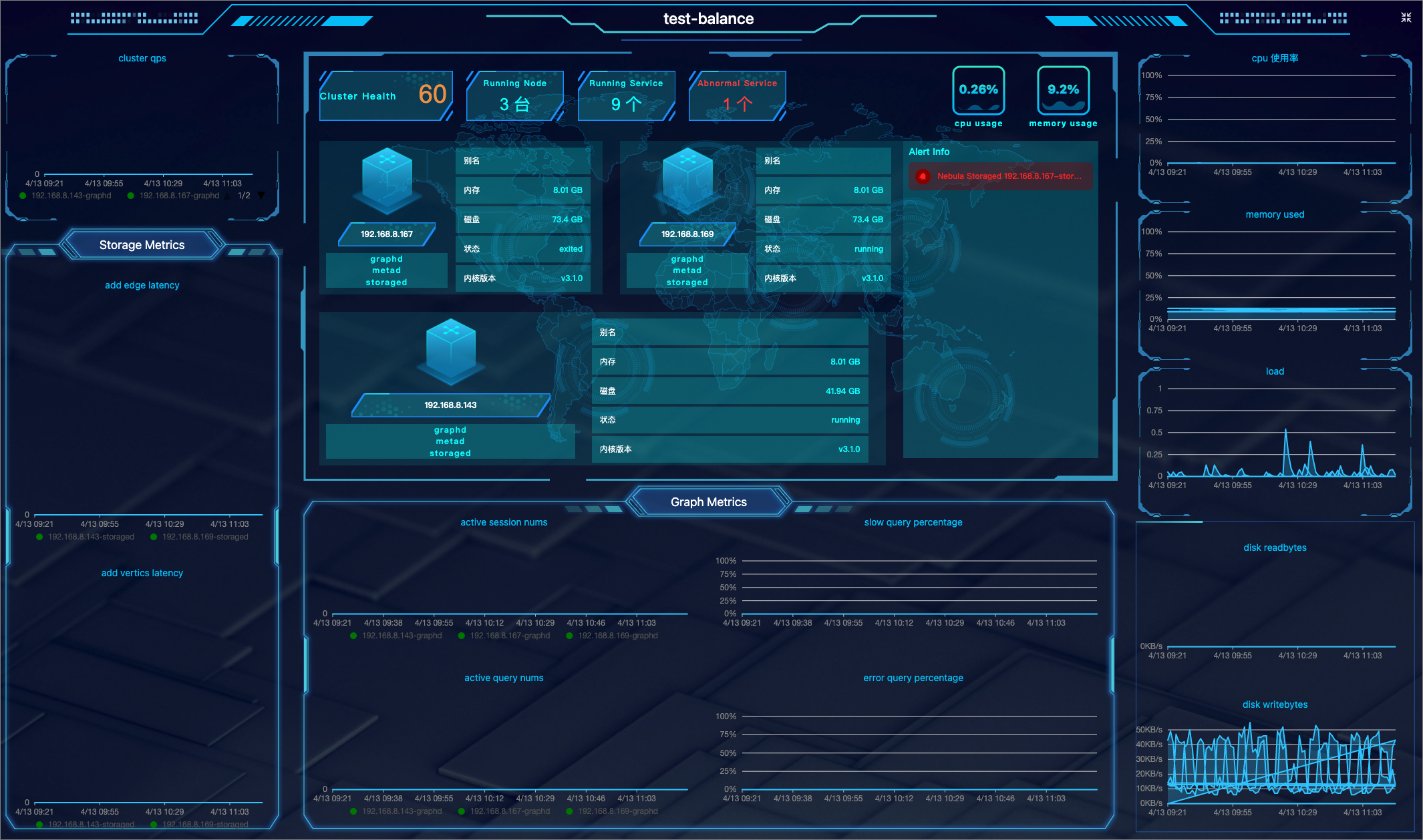 | ||
|
|
||
| Shows the distribution and status of nodes and services in the cluster. | ||
| | Screen area | Information displayed | | ||
| | ------------ | ------------------------------------------------------------ | | ||
| | Upper middle area | 1. The health degree of your cluster. The system scores the health of your cluster. For more information, see the following note. <br>2. The information and number of running nodes, the number of running services and abnormal services in the cluster. <br/>3. CPU and memory usage of the node at the current time.<br/>4. Alert notifications. The system displays the 5 most recently triggered alert messages based on their severity level (emergency>critical>warning). For more information, [Monitoring alerts](../4.cluster-operator/9.notification.md). | | ||
| | Lower middle area | Monitoring information of 4 Graph service metrics at different periods. The 4 metrics are: <br/>1. num_active_sessions<br/>2. num_slow_queries<br/>3. num_active_queries<br/>4. num_query_errors | | ||
| | Left side of the area | 1. QPS (Query Per Second) of your cluster.<br/>2. The monitoring information of 2 Storage service metrics at different periods. The two metrics are: add_edges_latency_us,add_vertices_latency_us. | | ||
| | Right side of the area | The node-related metrics information at different periods. Metrics include: <br/>1. cpu_utilization<br/>2. memory_utilization<br/>3. load_1m<br/>4. disk_readbytes<br/>5. disk_writebytes | | ||
|
|
||
| ### Node monitoring | ||
| For more information about the monitoring metrics, see [Metrics](../7.monitor-parameter.md). | ||
|
|
||
| - You can view the information of node monitoring quickly, and add or delete monitoring metrics. | ||
| - You can click  on the page to insert a base line. | ||
| - You can click  to jump to the detailed node monitoring page. | ||
| !!! note | ||
|
|
||
| ### Service monitoring | ||
| Cluster scoring rules are as follows: | ||
|
|
||
| - You can view the information of service monitoring quickly, and add or delete monitoring metrics. | ||
| - You can click  **Set up** to insert a base line. | ||
| - You can click  **View** to jump to the detailed service monitoring page. | ||
| - The maximum score is 100; The minimum score is 13. | ||
| - When 100≥Health Degree≥80, the score is blue; When 80>Health Degree≥60, the score is yellow; When Health Degree<60, the score is yellow. | ||
| - Algorithm: (1-number of abnormal services/total number of services)*100%. | ||
| - Except for the appearance of the first `emergency` level alert that deducts 40 points, 10 points are deducted for each of the other `emergency` level alerts and other levels of alerts. |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters