forked from jackyzha0/quartz
-
Notifications
You must be signed in to change notification settings - Fork 0
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
Pelayo Arbues
committed
Feb 21, 2025
1 parent
e702cd5
commit ffd0ca8
Showing
4 changed files
with
100 additions
and
1 deletion.
There are no files selected for viewing
32 changes: 32 additions & 0 deletions
32
...notes/Articles/Accelerating Scientific Breakthroughs With an AI Co-Scientist.md
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,32 @@ | ||
| --- | ||
| author: [[research.google]] | ||
| title: "Accelerating Scientific Breakthroughs With an AI Co-Scientist" | ||
| date: 2025-02-21 | ||
| tags: | ||
| - articles | ||
| - literature-note | ||
| --- | ||
|  | ||
|
|
||
| ## Metadata | ||
| - Author: [[research.google]] | ||
| - Full Title: Accelerating Scientific Breakthroughs With an AI Co-Scientist | ||
| - URL: https://research.google/blog/accelerating-scientific-breakthroughs-with-an-ai-co-scientist/ | ||
|
|
||
| ## Highlights | ||
| - We introduce AI co-scientist, a multi-agent AI system built with Gemini 2.0 as a virtual scientific collaborator to help scientists generate novel hypotheses and research proposals, and to accelerate the clock speed of scientific and biomedical discoveries. ([View Highlight](https://read.readwise.io/read/01jmkw327hzkfymhv9805rgkzf)) | ||
| - In the pursuit of scientific advances, researchers combine ingenuity and creativity with insight and expertise grounded in literature to generate novel and viable research directions and to guide the exploration that follows. In many fields, this presents a breadth and depth conundrum, since it is challenging to navigate the rapid growth in the rate of scientific publications while integrating insights from unfamiliar domains. Yet overcoming such challenges is critical, as evidenced by the many modern breakthroughs that have emerged from transdisciplinary endeavors. ([View Highlight](https://read.readwise.io/read/01jmkw3mb3d6sbdqy7jx3v1127)) | ||
| - Motivated by unmet needs in the modern scientific discovery process and building on [recent AI advances](https://arxiv.org/abs/2403.05530), including the ability to synthesize across complex subjects and to perform [long-term planning and reasoning](https://deepmind.google/technologies/gemini/flash-thinking/), we developed an [AI co-scientist system](https://storage.googleapis.com/coscientist_paper/ai_coscientist.pdf). The AI co-scientist is a multi-agent AI system that is intended to function as a collaborative tool for scientists. Built on [Gemini 2.0, AI co-scientist is](https://blog.google/technology/google-deepmind/google-gemini-ai-update-december-2024/) designed to mirror the reasoning process underpinning the scientific method. Beyond standard literature review, summarization and “deep research” tools, the AI co-scientist system is intended to uncover new, original knowledge and to formulate demonstrably novel research hypotheses and proposals, building upon prior evidence and tailored to specific research objectives. ([View Highlight](https://read.readwise.io/read/01jmkw3vy7fcw5kd08bsjybjk3)) | ||
| - Given a scientist’s research goal that has been specified in natural language, the AI co-scientist is designed to generate novel research hypotheses, a detailed research overview, and experimental protocols. To do so, it uses a coalition of specialized agents — *Generation*, *Reflection*, *Ranking*, *Evolution*, *Proximity* and *Meta-review* — that are inspired by the scientific method itself. These agents use automated feedback to iteratively generate, evaluate, and refine hypotheses, resulting in a self-improving cycle of increasingly high-quality and novel outputs. ([View Highlight](https://read.readwise.io/read/01jmkw43z9b68hf2kyjbtk5h9c)) | ||
| - Purpose-built for collaboration, scientists can interact with the system in many ways, including by directly providing their own seed ideas for exploration or by providing feedback on generated outputs in natural language. The AI co-scientist also uses tools, like web-search and specialized AI models, to enhance the grounding and quality of generated hypotheses. | ||
| 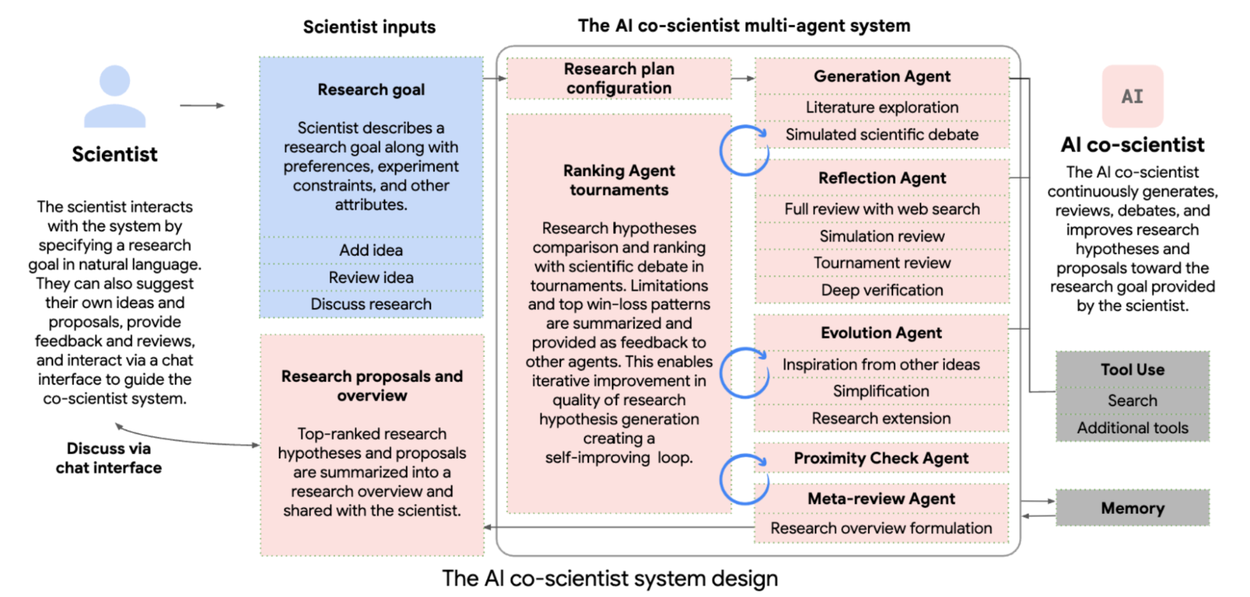 ([View Highlight](https://read.readwise.io/read/01jmkw4cwx1h75hnhjr48f1gcz)) | ||
| - The AI co-scientist parses the assigned goal into a research plan configuration, managed by a Supervisor agent. The Supervisor agent assigns the specialized agents to the worker queue and allocates resources. This design enables the system to flexibly scale compute and to iteratively improve its scientific reasoning towards the specified research goal. | ||
| 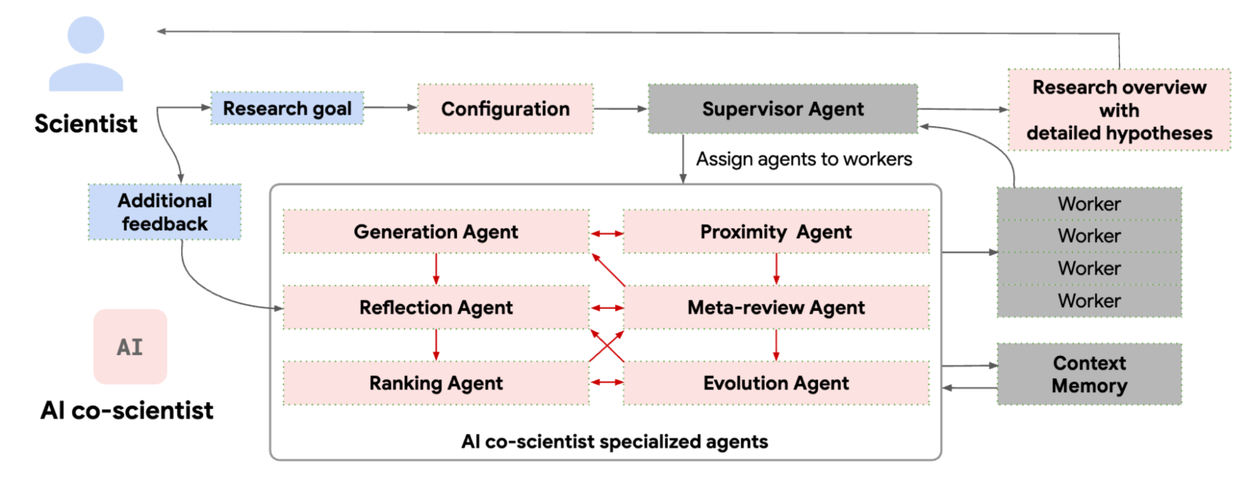 ([View Highlight](https://read.readwise.io/read/01jmkw4n88v8f7wq0wmyy7nmr1)) | ||
| - The AI co-scientist leverages [test-time compute](https://arxiv.org/abs/2408.03314) scaling to iteratively reason, evolve, and improve outputs. Key reasoning steps include [self-play](https://deepmind.google/discover/blog/alphago-zero-starting-from-scratch/)–based scientific debate for novel hypothesis generation, ranking tournaments for hypothesis comparison, and an "evolution" process for quality improvement. The system's agentic nature facilitates recursive self-critique, including tool use for feedback to refine hypotheses and proposals. ([View Highlight](https://read.readwise.io/read/01jmkw54fjm09f6dpp04q6cfa5)) | ||
| - The system's self-improvement relies on the [Elo](https://en.wikipedia.org/wiki/Elo_rating_system) auto-evaluation metric derived from its tournaments. Due to their core role, we assessed whether higher Elo ratings correlate with higher output quality. We analyzed the concordance between Elo auto-ratings and [GPQA benchmark](https://arxiv.org/abs/2311.12022) accuracy on its diamond set of challenging questions, and we found that higher Elo ratings positively correlate with a higher probability of correct answers. | ||
| 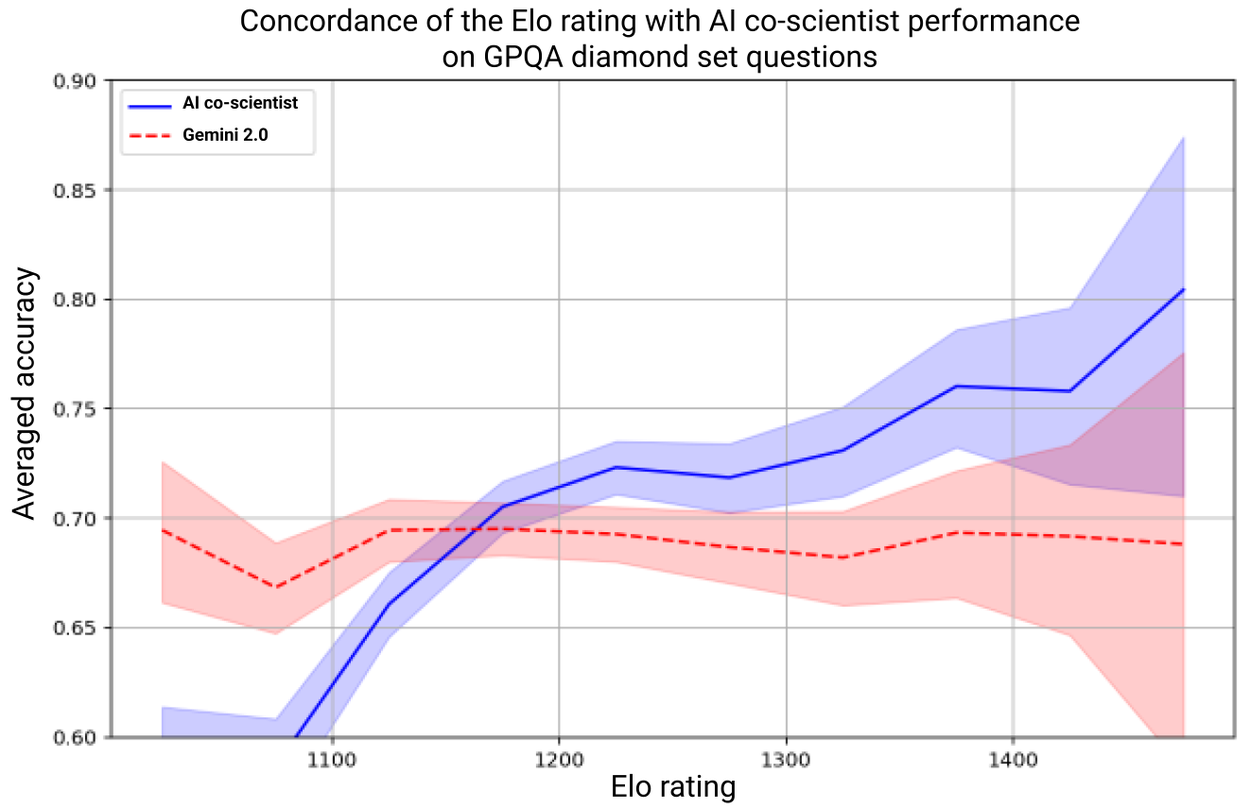 ([View Highlight](https://read.readwise.io/read/01jmkw56z03rnjn311ghbnxatj)) | ||
| - Seven domain experts curated 15 open research goals and best guess solutions in their field of expertise. Using the automated Elo metric we observed that the AI co-scientist outperformed other state-of-the-art agentic and reasoning models for these complex problems. The analysis reproduced the benefits of scaling test-time compute using inductive biases derived from the scientific method. As the system spends more time reasoning and improving, the self-rated quality of results improve and surpass models and unassisted human experts. | ||
| 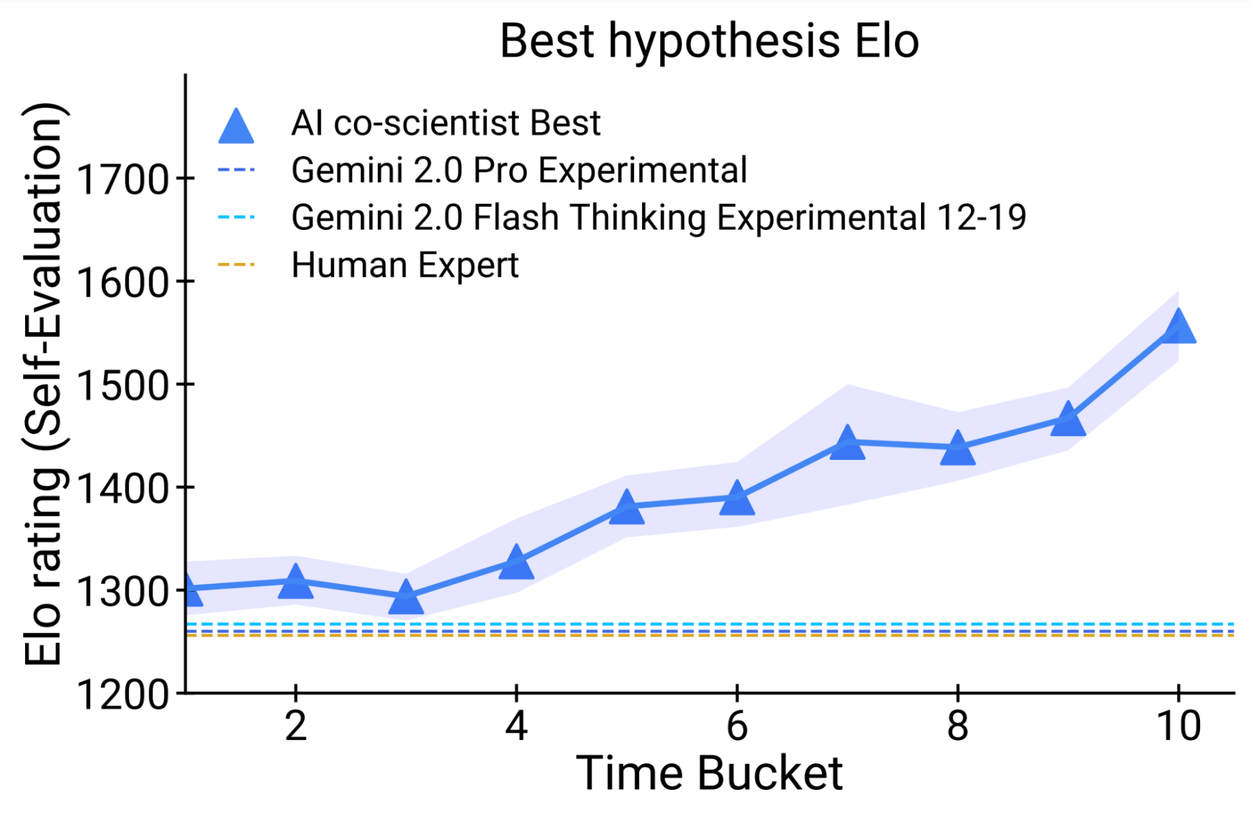 ([View Highlight](https://read.readwise.io/read/01jmkw5ajkm5et7j78fn5bee9z)) | ||
| - On a smaller subset of 11 research goals, experts assessed the novelty and impact of the AI co-scientist–generated results compared to other relevant baselines; they also provided overall preference. While the sample size was small, experts assessed the AI co-scientist to have higher potential for novelty and impact, and preferred its outputs compared to other models. Further, these human expert preferences also appeared to be concordant with the previously introduced Elo auto-evaluation metric. ([View Highlight](https://read.readwise.io/read/01jmkw5e4hp80d3f22fhkxs6rp)) | ||
| - n our report we address several limitations of the system and opportunities for improvement, including enhanced literature reviews, factuality checking, cross-checks with external tools, auto-evaluation techniques, and larger-scale evaluation involving more subject matter experts with varied research goals. The AI co-scientist represents a promising advance toward AI-assisted technologies for scientists to help accelerate discovery. ([View Highlight](https://read.readwise.io/read/01jmkw5wwb083s5qsxheccdsq5)) | ||
| - Its ability to generate novel, testable hypotheses across diverse scientific and biomedical domains — some already validated experimentally — and its capacity for recursive self-improvement with increased compute, demonstrate its potential to accelerate scientists' efforts to address grand challenges in science and medicine. ([View Highlight](https://read.readwise.io/read/01jmkw61kwc07r8bvtnc2rv1b3)) |
21 changes: 21 additions & 0 deletions
21
...icles/Introducing PaliGemma 2 mix A vision-language model for multiple tasks.md
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,21 @@ | ||
| --- | ||
| author: [[Omar Sanseviero]] | ||
| title: "Introducing PaliGemma 2 mix: A vision-language model for multiple tasks" | ||
| date: 2025-02-21 | ||
| tags: | ||
| - articles | ||
| - literature-note | ||
| --- | ||
|  | ||
|
|
||
| ## Metadata | ||
| - Author: [[Omar Sanseviero]] | ||
| - Full Title: Introducing PaliGemma 2 mix: A vision-language model for multiple tasks | ||
| - URL: https://developers.googleblog.com/en/introducing-paligemma-2-mix/ | ||
|
|
||
| ## Highlights | ||
| - This past December, [we launched PaliGemma 2](https://developers.googleblog.com/en/introducing-paligemma-2-powerful-vision-language-models-simple-fine-tuning/), an upgraded vision-language model in the [Gemma](https://ai.google.dev/gemma) family. The release included pretrained checkpoints of different sizes (3B, 10B, and 28B parameters) that can be easily fine-tuned on a wide range of vision-language tasks and domains, such as image segmentation, short video captioning, scientific question answering and text-related tasks with high performance. ([View Highlight](https://read.readwise.io/read/01jmkw25nqpg8srfyxy5tmh394)) | ||
| - **What’s new in PaliGemma 2 mix?** | ||
| • **Multiple tasks with one model**: PaliGemma 2 mix can solve tasks such as short and long captioning, optical character recognition (OCR), image question answering, object detection and segmentation. | ||
| • **Developer-friendly sizes**: Use the best model for your needs thanks to the different model sizes (3B, 10B, and 28B parameters) and resolutions (224px and 448px). | ||
| • **Use with your preferred framework**: Leverage your preferred tools and frameworks, including [Hugging Face Transformers](https://huggingface.co/blog/paligemma2mix), [Keras](https://ai.google.dev/gemma/docs/paligemma/inference-with-keras), PyTorch, JAX, and [Gemma.cp](https://github.com/google/gemma.cpp/tree/main?tab=readme-ov-file#paligemma-vision-language-model) ([View Highlight](https://read.readwise.io/read/01jmkw298fakxnhtfs191xmsq8)) |
46 changes: 46 additions & 0 deletions
46
...rature-notes/Articles/SigLIP 2 A Better Multilingual Vision Language Encoder.md
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,46 @@ | ||
| --- | ||
| author: [[Hugging Face - Blog]] | ||
| title: "SigLIP 2: A Better Multilingual Vision Language Encoder" | ||
| date: 2025-02-21 | ||
| tags: | ||
| - articles | ||
| - literature-note | ||
| --- | ||
|  | ||
|
|
||
| ## Metadata | ||
| - Author: [[Hugging Face - Blog]] | ||
| - Full Title: SigLIP 2: A Better Multilingual Vision Language Encoder | ||
| - URL: https://huggingface.co/blog/siglip2 | ||
|
|
||
| ## Highlights | ||
| - Today Google releases a new and better family of *multilingual* vision-language encoders, [SigLIP 2](https://huggingface.co/collections/google/siglip2-67b5dcef38c175486e240107). The authors have extended the training objective of SigLIP (*sigmoid loss*) with additional objectives for improved semantic understanding, localization, and dense features. ([View Highlight](https://read.readwise.io/read/01jmkvy349df0ght5aadbfxnfp)) | ||
| - SigLIP 2 models **outperform** the older SigLIP ones *at all model scales* in core capabilities, including zero-shot classification, image-text retrieval, and transfer performance when extracting visual representations for Vision-Language Models (VLMs). ([View Highlight](https://read.readwise.io/read/01jmkvy7eqhbtmq0npw1538t23)) | ||
| - Vision encoders are simple - they take an image, encode it into a representation, and that representation is used for downstream tasks like classification, object detection, image segmentation, and more vision tasks. Researchers are always in pursuit of visual representations that are **dense**, **locality-aware**, and **semantically rich**. ([View Highlight](https://read.readwise.io/read/01jmkvyaset1gya5xcvpavqa42)) | ||
| - [CLIP](https://huggingface.co/docs/transformers/en/model_doc/clip) and [ALIGN](https://huggingface.co/docs/transformers/en/model_doc/align) are the first examples of image encoders and text encoders aligned together through joint training. This approach opened new ways to train vision models. [SigLIP](https://huggingface.co/docs/transformers/en/model_doc/siglip) took it further, replacing CLIP's *contrastive loss* with *sigmoid loss* for even better encoders. ([View Highlight](https://read.readwise.io/read/01jmkvyk02szgaa4k0x1c1jb19)) | ||
| - The takeaway? With smarter training objectives, we keep building vision encoders that are more structured, fine-grained, and powerful. SigLIP 2 is just that, a bunch of really interesting and smart training objectives applied on top of that of SigLIP's to provide better and stronger vision language encoders. ([View Highlight](https://read.readwise.io/read/01jmkvyn3rg63pqt5ge2sz8bg2)) | ||
| - We will try something new with this blog post. Rather than stating what is new and where to find it, we will go through a little exercise together. We start off with SigLIP and then brainstorm a series of questions (prefixed with 🤔) and answers (a new heading) to gradually cover all the updates in SigLIP 2. Sounds good? ([View Highlight](https://read.readwise.io/read/01jmkvyqxmgt6n0xs6s5zm631r)) | ||
| - Add a decoder (it’s that simple) | ||
| Let’s add a decoder to the mix. Now we have an image encoder, a text encoder, and a *text decoder*. The text decoder will have three objectives: | ||
| 1. Predict a holistic image caption | ||
| 2. Predict bounding box coordinates given captions describing *specific* image regions | ||
| 3. Predict region-specific caption given bounding box coordinates | ||
| The decoder provides an additional signal to the vision encoder, making it location-aware. This marks the first improvement to the training recipe in SigLIP 2. ([View Highlight](https://read.readwise.io/read/01jmkvz1revk4y9xk8rcecsws6)) | ||
| - **Question 2: How do we improve fine-grained local semantics of the image representation?** | ||
| Self-distillation with Global-Local loss and Masked Prediction | ||
| To improve fine-grained local semantics in image representation, we introduce two key training objectives, Global-Local Loss, and Masked Prediction Loss. Taking inspiration from self-supervised learning literature, we use *self-distillation*. We can use a model as a teacher, and the same model as a student. Upon each iteration the teacher will be the moving average of the student's parameters. | ||
| 1. **Global-Local Loss**: The student network gets a partial (local) view of the training image, and is trained to match the teacher’s representation, derived from the full image. | ||
| 2. **Masked Prediction Loss**: 50% of the embedded image patches in the student network are masked with mask tokens. The student needs to match the features of the teacher at masked locations. ([View Highlight](https://read.readwise.io/read/01jmkw07r6z3pbesbard715rwv)) | ||
| - These objectives teach the vision encoder to be spatially aware and improve its local semantics. The authors add this loss only after **80%** of the training is done with the sigmoid and decoder loss. This is done in order to save compute (additional losses are pretty expensive) and to not negatively affect the encoders. ([View Highlight](https://read.readwise.io/read/01jmkw0aqcb6mbmdt4w74z5yq0)) | ||
| - **🤔 Question 3: How to adapt models to different resolutions?** | ||
| Adapting to different resolutions | ||
| It is a known fact that image models can be very sensitive to varying resolutions and aspect ratios. Here we can leverage two distinct methodologies to adapt these models on different resolutions and patch sizes. | ||
| 1. **Fixed resolution variant**: Taking the checkpoints from 95% training, we can resize the positional embeddings and the patch embeddings and then continue training for a requested (potentially larger) resolution. | ||
| 2. **Dynamic resolution variant**: Taking inspiration from [FlexiViT](https://huggingface.co/papers/2212.08013), which uses inputs with different sequence lengths, and [NaViT](https://huggingface.co/papers/2307.06304), which adheres to the native aspect ratios, we can create **NaFlex** variants. This is interesting because we can use a single model for OCR (little aspect ratio distortion) and document understanding (appropriate resolution). ([View Highlight](https://read.readwise.io/read/01jmkw0g1cycw54rt5kqexs7jc)) | ||
| - Zero-shot Classification | ||
| Here we use the handy `pipeline` API to showcase zero-shot classification capabilities for SigLIP 2. | ||
| Let’s visualize the outputs. | ||
| [](https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/sg2-blog/zero-shot.png) ([View Highlight](https://read.readwise.io/read/01jmkw0rv70r7z9wxtaz0ff742)) | ||
| - Using the encoder for VLMs | ||
| Vision encoders aligned to textual information have become increasingly vital in the development of **Vision Language Models** (VLMs). A common approach to building VLMs involves combining a pretrained vision encoder with a pretrained LLM, and training them together using multimodal data across a diverse set of vision-language tasks. | ||
| One standout example of a VLM leveraging the SigLIP family of vision encoders is **PaliGemma**. One can dive deeper into PaliGemma's capabilities in this [PaliGemma](https://huggingface.co/blog/paligemma) blog post. Building on this foundation, the recently introduced [PaliGemma 2](https://huggingface.co/blog/paligemma2) takes it a step further by integrating SigLIP with the advanced Gemma 2 LLM. It would be really exciting to swap out SigLIP with SigLIP 2 in a PaliGemma like setting and see how that model fares. ([View Highlight](https://read.readwise.io/read/01jmkw19xh20avaesfce7ch0yz)) |
Oops, something went wrong.