forked from jackyzha0/quartz
-
Notifications
You must be signed in to change notification settings - Fork 0
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
Pelayo Arbues
committed
Jan 21, 2025
1 parent
2bc1a91
commit 0c78727
Showing
2 changed files
with
74 additions
and
0 deletions.
There are no files selected for viewing
53 changes: 53 additions & 0 deletions
53
content/literature-notes/Articles/Pipelines & Prompt Optimization With DSPy.md
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,53 @@ | ||
| --- | ||
| author: [[Drew Breunig]] | ||
| title: "Pipelines & Prompt Optimization With DSPy" | ||
| date: 2025-01-21 | ||
| tags: | ||
| - articles | ||
| - literature-note | ||
| --- | ||
|  | ||
|
|
||
| ## Metadata | ||
| - Author: [[Drew Breunig]] | ||
| - Full Title: Pipelines & Prompt Optimization With DSPy | ||
| - URL: https://www.dbreunig.com/2024/12/12/pipelines-prompt-optimization-with-dspy.html | ||
|
|
||
| ## Highlights | ||
| - From their site, “DSPy is the framework for programming—rather than prompting—language models.” | ||
| And it’s true: you spend much, *much* less time prompting when you use DSPy to build LLM-powered applications. Because you let DSPy handle that bit for you. | ||
| *There’s something really clean and freeing about ceding the details and nuance of the prompt back to an LLM.* ([View Highlight](https://read.readwise.io/read/01jj5564x3pwnxrt534327fcyw)) | ||
| - DSPy reduces time spent prompting by providing you with boilerplate prompting that frames your tasks, which you define with “signatures”. **Signatures** are a way of expressing what you want an LLM to do by defining the desired input and outputs. They can be as simple as strings, like: | ||
| 'question -> answer' | ||
| You can also specify your types as well, like: | ||
| 'sentence -> sentiment: bool' | ||
| Instinctually, I started looking for a dictionary of input and output types for signatures. But there isn’t one: signatures can use whatever terms you’d like, so long as they’re descriptive of your desired inputs and outputs. For example: | ||
| 'document -> summary' | ||
| 'novella -> tldr' | ||
| 'baseball_player -> affiliated_team' ([View Highlight](https://read.readwise.io/read/01jj556rmr2w6adk2ydfwggjty)) | ||
| - **Signatures** define your desired work, but they are used to generate prompts by DSPy “modules”. For our purposes today, think of **modules** as runners which apply a specific set of prompt techniques to generate a prompt and run it against an LLM. The foundational module is `Predict`, which doesn’t do much out of the box besides frame your signature with some boilerplate instructions. ([View Highlight](https://read.readwise.io/read/01jj5574ehjrns37q83whnfpfn)) | ||
| - For example, given the signature, `question -> answer` and the input question, “What is the captital of France?” the `Predict` model will call an LLM with the following system promp ([View Highlight](https://read.readwise.io/read/01jj557nj0s8x0rr9yy090jrxg)) | ||
| - he **module** is performing some [basic string formatting to contextualize](https://github.com/stanfordnlp/dspy/blob/62463014d2f13d3ef1dfe13b4ca046b5831aaff5/dspy/adapters/chat_adapter.py#L311) your provided **signature**. ([View Highlight](https://read.readwise.io/read/01jj558w9f1n2n1s95eymt6gbx)) | ||
| - Off the bat, this is helpful for quick LLM tasks, especially if you’re a beginner with prompts. But where DSPy really shines is when you ask it to optimize your prompts based on a provided training set. ([View Highlight](https://read.readwise.io/read/01jj55900szvmhnq2r5zntjrr4)) | ||
| - To illustrate how we can optimize prompts with DSPy, we’re going to use a simple toy problem: categorizing descriptions of historic events. ([View Highlight](https://read.readwise.io/read/01jj559g1gkmg81j1fb4ph6wws)) | ||
| - We’ve gathered the event descriptions by scraping Wikipedia’s [date pages](https://en.wikipedia.org/wiki/December_12), obtaining a whole mess of descriptions like, “Battle of Nineveh: A Byzantine army under Emperor Heraclius defeats Emperor Khosrau II’s Persian forces, commanded by General Rhahzadh.” ([View Highlight](https://read.readwise.io/read/01jj559jyz5jdc7xq7nzn5wht7)) | ||
| - We’re going to use a [*class-based*](https://dspy.ai/learn/programming/signatures/#class-based-dspy-signatures) signature because it lets us explicitly specify the categories we want our events categorized with ([View Highlight](https://read.readwise.io/read/01jj55bc9fr5c55eq7a8chpam9)) | ||
| - Let’s quickly look at what prompt the `Predict` module generates for us based off this definition when we pass in the `event`, ““Second Boer War: In the Battle of Magersfontein the Boers commanded by general Piet Cronjé inflict a defeat on the forces of the British Empire commanded by Lord Methuen trying to relieve the Siege of Kimberley ([View Highlight](https://read.readwise.io/read/01jj55bpjtftyz7stapvdg7ja2)) | ||
| - Your input fields are: `event` (str) Your output fields are: 1. `category` (Literal[Wars and Conflicts, Politics and Governance, Science and Innovation, Cultural and Artistic Movements, Exploration and Discovery, Economic Events, Social Movements, Man-Made Disasters and Accidents, Natural Disasters and Climate, Sports and Entertainment, Famous Personalities and Achievements]) 2. `confidence` (float) All interactions will be structured in the following way, with the appropriate values filled in. [[ ## event ## ]] {event} [[ ## category ## ]] {category} # note: the value you produce must be one of: Wars and Conflicts; Politics and Governance; Science and Innovation; Cultural and Artistic Movements; Exploration and Discovery; Economic Events; Social Movements; Man-Made Disasters and Accidents; Natural Disasters and Climate; Sports and Entertainment; Famous Personalities and Achievements [[ ## confidence ## ]] {confidence} # note: the value you produce must be a single float value [[ ## completed ## ]] In adhering to this structure, your objective is: Classify historic events. ([View Highlight](https://read.readwise.io/read/01jj55bzpbc4wc0t7s1vm0zz0e)) | ||
| - Already, this is a *huge* win. We’ve spec-ed out our categorization problem in a few lines, in a way that it will be much easier to edit our potential categories, and got back structured results without having to get our hands dirty with prompting boilerplate or manipulating the LLM response. ([View Highlight](https://read.readwise.io/read/01jj55ddknqxcmrecmck54s7pw)) | ||
| - But the actual answers? They’re *okay*…not great. Lots of war events are categorized as poltical events (which…fair, *I guess*) and other times a tricky keyword will throw the results. We could go through and hand sort the results, but let’s take advantage of DSPy’s ease of model switching to compare Llama 3.2 1b to the new, *excellent* Llama 3.3 70b. ([View Highlight](https://read.readwise.io/read/01jj55dqsgvvhtw9ka4r442hrj)) | ||
| - Llama 3.3’s size provides much more context to situate these events, many of which couldn’t be categorized without knowledge of their subjects. In these instances, there’s not much we can do to help Llama 3.1. Prompt engineering or fine-tuning isn’t going to add the needed diverse base knowledge needed for these calls. | ||
| But there’s enough near misses that I think some improved prompting can eek out some gains from the 1b model. ([View Highlight](https://read.readwise.io/read/01jj55ebrbqvjf21x90zt9bep7)) | ||
| - An aspect about DSPy **modules** we haven’t yet discussed is that we can *optimize* them. To do this, we need to defined a *metric* and prepare some *training data*. | ||
| In DPSy, metrics are functions that take examples with ideal output and compare them to the output of our system. H ([View Highlight](https://read.readwise.io/read/01jj55exscskjkb7q0z5q3chb8)) | ||
| - As simple as it gets. If our example doesn’t match the output, it fails. ([View Highlight](https://read.readwise.io/read/01jj55f68b1x9h89enf4z8h1d9)) | ||
| - These answers are great, but generating them took awhile. A good reminder why we should try to eek as much value out of smaller models for these exercises. ([View Highlight](https://read.readwise.io/read/01jj55fn7ds3ehtg7gvsh6q3n5)) | ||
| - 51.9% of the time Llama 3.2 1b gets it right, about in line with our previous comparison. Nice to know this scales. | ||
| To improve our system, we specify an [optimizer](https://dspy.ai/learn/optimization/optimizers/) and ask DSPy to run it on our function with using our training data ([View Highlight](https://read.readwise.io/read/01jj55g540sew7c53sa300hjac)) | ||
| - Getting into the depths of DSPy optimizers is beyond the scope of this post, but we’re choosing MIPROv2 because we *only want to optimize the prompt the module and signature are using*. We aren’t fine-tuning any weights, just trying to find a way of prompting our LLM so we get results more in line with our desired output. ([View Highlight](https://read.readwise.io/read/01jj55gg89125wdfpt83fce112)) | ||
| - DSPy will use the LLM to generate other ways of prompting our model –– trying rephrases, using examples from our training set, and more –– to find a prompt which outperforms the boilerplate it generated above. As you stack modules and signatures, forming more complex prompting chains, this can get much more complex and obtain *much* better gains. Here we’re keeping it simple, using only one module and signature and asking that the optimizer not try *few-shot prompts* (aka prompts that involve a round or two of back and forth with the LLM). ([View Highlight](https://read.readwise.io/read/01jj55gzee7b1ffxz81e7nnh2z)) | ||
| - That second part is some very-specific [over-fitting](https://en.wikipedia.org/wiki/Overfitting)! Though the instructions to mind your synonyms seems benficial and more generic. And the results look…pretty good! Running the new signature on a wider batch of data and eyeballing the results appears promising. | ||
| But we can do better. DSPy has a really neat feature that lets us specify the model we want to use for the *task itself* and another model *for generating prompts*. This is perfect for us, as it lets us leverage the much better Llama 3.3 to come up with prompting strategies while evaluating them against the tiny 3.1 model. ([View Highlight](https://read.readwise.io/read/01jj55hxc4gxp57snx3qdms7fy)) | ||
| - On first blush, this yields *worse* results: 62% vs our previous 63%. But the output looks much better on initial review. It’s easy to see how using a big LLM helped us avoid over-fitting and obtain better instructions. ([View Highlight](https://read.readwise.io/read/01jj55j8rr44ybr3kef8sjjqmw)) | ||
| - Saving allows us to reload the optimized system during a different session. | ||
| DSPy is super useful, especially as your pipeline grows from a single, 0-shot call to a multistep, tool-using agent. The pattern of abstracting prompt generation away and leaving it to the models to figure out based on defined metrics is quite powerful. ([View Highlight](https://read.readwise.io/read/01jj55jkrh26pyrt77dzge9z54)) |
21 changes: 21 additions & 0 deletions
21
content/literature-notes/Articles/Spaces Using BSC-LTALIA-40b 6.md
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,21 @@ | ||
| --- | ||
| author: [[huggingface.co]] | ||
| title: "Spaces Using BSC-LT/ALIA-40b 6" | ||
| date: 2025-01-21 | ||
| tags: | ||
| - articles | ||
| - literature-note | ||
| --- | ||
|  | ||
|
|
||
| ## Metadata | ||
| - Author: [[huggingface.co]] | ||
| - Full Title: Spaces Using BSC-LT/ALIA-40b 6 | ||
| - URL: https://huggingface.co/BSC-LT/ALIA-40b | ||
|
|
||
| ## Highlights | ||
| - The pre-training corpus comprises data from 35 European languages and 92 programming languages, with detailed data sources provided below. The initial 1.5 training epochs used 2.4 trillion tokens, obtained by manually adjusting data proportion to balance the representation and give more importance to Spain’s co-official (Spanish, Catalan, Galician, and Basque). This way, we downsampled code and English data to half, Spanish co-official languages were oversampled by 2x, and the remaining languages were kept in their original proportions. ([View Highlight](https://read.readwise.io/read/01jj53d5py79rdpz1btvhhe1q7)) | ||
| - during the following epochs (still training), the Colossal OSCAR dataset was replaced with the FineWebEdu dataset. This adjustment resulted in a total of 2.68 trillion tokens, distributed as outlined below: | ||
| [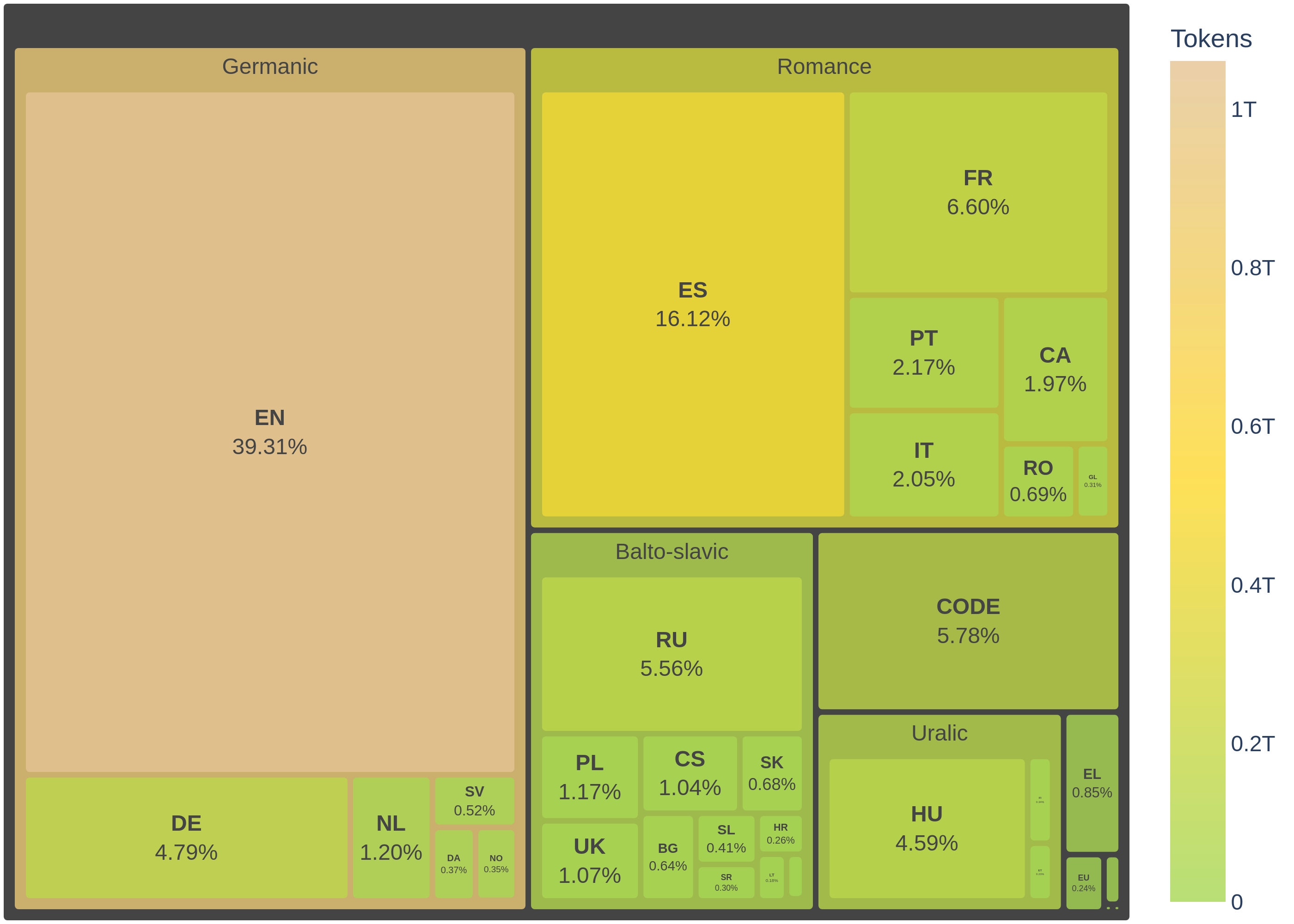](https://huggingface.co/BSC-LT/ALIA-40b/blob/main/images/corpus_languages.png) ([View Highlight](https://read.readwise.io/read/01jj53dbz7qg1ae43b7jdchdqp)) | ||
| - The pretraining corpus is predominantly composed of data from Colossal OSCAR, which contributes a significant 53,05% of the total tokens. Following this, Starcoder provides 13,67%, and FineWebEdu (350B tokens subset) adds 10,24%. The next largest sources are HPLT at 4,21% and French-PD at 3,59%. Other notable contributions include MaCoCu, Legal-ES, and EurLex, each contributing around 1.72% to 1.41%. These major sources collectively form the bulk of the corpus, ensuring a rich and diverse dataset for training the language model. ([View Highlight](https://read.readwise.io/read/01jj53djxr3g1sa0jks012kv9r)) | ||
| - We evaluate on a set of tasks taken from [SpanishBench](https://github.com/EleutherAI/lm-evaluation-harness/tree/main/lm_eval/tasks/spanish_bench), [CatalanBench](https://github.com/EleutherAI/lm-evaluation-harness/tree/main/lm_eval/tasks/catalan_bench), [BasqueBench](https://github.com/EleutherAI/lm-evaluation-harness/tree/main/lm_eval/tasks/basque_bench) and [GalicianBench](https://github.com/EleutherAI/lm-evaluation-harness/tree/main/lm_eval/tasks/galician_bench). We also use English tasks already available on the LM Evaluation Harness. These benchmarks include both new and existing tasks and datasets. In the tables below, we include the results in a selection of evaluation datasets that represent model's performance across a variety of tasks within these benchmarks. ([View Highlight](https://read.readwise.io/read/01jj53dvmr63feeedp09sys61p)) |