add initial local client database models #9
Conversation
af8b59d to
1662a1a
Compare
There was a problem hiding this comment.
The sql generated right now is:
CREATE TABLE alembic_version (
version_num VARCHAR(32) NOT NULL,
CONSTRAINT alembic_version_pkc PRIMARY KEY (version_num)
);
INFO [alembic.runtime.migration] Running upgrade -> 5344fc3a3d3f, add user table
-- Running upgrade -> 5344fc3a3d3f
CREATE TABLE users (
id INTEGER NOT NULL,
username VARCHAR(255) NOT NULL,
PRIMARY KEY (id),
UNIQUE (username)
);
INSERT INTO alembic_version (version_num) VALUES ('5344fc3a3d3f');
INFO [alembic.runtime.migration] Running upgrade 5344fc3a3d3f -> fe7656c21eaa, add remainder of database models
-- Running upgrade 5344fc3a3d3f -> fe7656c21eaa
CREATE TABLE sources (
id INTEGER NOT NULL,
uuid VARCHAR(36) NOT NULL,
journalist_designation VARCHAR(255) NOT NULL,
is_flagged BOOLEAN,
public_key VARCHAR(10000),
interaction_count INTEGER NOT NULL,
is_starred BOOLEAN,
last_updated DATETIME,
PRIMARY KEY (id),
UNIQUE (uuid),
CHECK (is_flagged IN (0, 1)),
CHECK (is_starred IN (0, 1))
);
CREATE TABLE replies (
id INTEGER NOT NULL,
source_id INTEGER,
journalist_id INTEGER,
filename VARCHAR(255) NOT NULL,
size INTEGER NOT NULL,
PRIMARY KEY (id),
FOREIGN KEY(journalist_id) REFERENCES users (id),
FOREIGN KEY(source_id) REFERENCES sources (id)
);
CREATE TABLE submissions (
id INTEGER NOT NULL,
uuid VARCHAR(36) NOT NULL,
filename VARCHAR(255) NOT NULL,
size INTEGER NOT NULL,
is_downloaded BOOLEAN,
is_read BOOLEAN,
source_id INTEGER,
PRIMARY KEY (id),
FOREIGN KEY(source_id) REFERENCES sources (id),
UNIQUE (uuid),
CHECK (is_downloaded IN (0, 1)),
CHECK (is_read IN (0, 1))
);
UPDATE alembic_version SET version_num='fe7656c21eaa' WHERE alembic_version.version_num = '5344fc3a3d3f';Additionally, all default values should use sever_default to enforce the defaults at the sqlite level and not the ORM level.
| @@ -17,6 +19,79 @@ | |||
| Base = declarative_base() | |||
|
|
|||
|
|
|||
| class Source(Base): | |||
| __tablename__ = 'sources' | |||
There was a problem hiding this comment.
We should add __table_args__ = {'sqlite_autoincrement': True} to force sqlite to use the autoincrement feature.
There was a problem hiding this comment.
can you explain why you recommend we use autoincrement? from the SQLite docs:
The AUTOINCREMENT keyword imposes extra CPU, memory, disk space, and disk I/O overhead and should be avoided if not strictly needed. It is usually not needed.
There was a problem hiding this comment.
I was assuming we do that to move that to the database level instead of the ORM level. Like, if this was postgres, we'd force the autoincrement into the DB too. Idk. Maybe this isn't needed.
|
|
||
|
|
||
| class Submission(Base): | ||
| __tablename__ = 'submissions' |
There was a problem hiding this comment.
We should add __table_args__ = {'sqlite_autoincrement': True} to force sqlite to use the autoincrement feature.
|
|
||
|
|
||
| class Reply(Base): | ||
| __tablename__ = 'replies' |
There was a problem hiding this comment.
We should add __table_args__ = {'sqlite_autoincrement': True} to force sqlite to use the autoincrement feature.
| sa.Column('journalist_designation', sa.String(length=255), | ||
| nullable=False), | ||
| sa.Column('is_flagged', sa.Boolean(), nullable=True), | ||
| sa.Column('public_key', sa.String(length=10000), nullable=True), |
There was a problem hiding this comment.
This should be TEXT because we probably don't want a limit here actually.
| sa.Column('uuid', sa.String(length=36), nullable=False), | ||
| sa.Column('journalist_designation', sa.String(length=255), | ||
| nullable=False), | ||
| sa.Column('is_flagged', sa.Boolean(), nullable=True), |
There was a problem hiding this comment.
Without a ton of knowledge about what these things mean in SD land, flagged and starred booleans jump out to me as attributes which may be better modeled similarly to how you might model tags- either directly in a table with two columns (source-id (int), tag-name (varchar)) or via a join table into a table of possible tag values. In this first case, you avoids a migration if you want to grow the set of labels you want to hang on sources, and in the second case the migration is super easy (just a value to the table of possible labels). In either case, you still are able to make queries which filter by various labels.
There was a problem hiding this comment.
i like the join table with possible tag values pattern (because normalization), let's do that when we add more tags. btw as background here are some notes about these columns:
-
is_flagged: this column tracks if SecureDrop's flag for reply functionality has been enabled for that source. This flag for reply functionality is a DoS mitigation (it prevents the generation of source keys if many sources are created in a limited time period). Check out these screenshots to see how this looks from the journalist's perspective -
is_starred: this is a system-wide star - so SecureDrop starring is like pinned messages on Slack, which is a little confusing imho (this is legacy behavior) - users might expect this to be per-user.
| sa.Column('public_key', sa.String(length=10000), nullable=True), | ||
| sa.Column('interaction_count', sa.Integer(), nullable=False), | ||
| sa.Column('is_starred', sa.Boolean(), nullable=True), | ||
| sa.Column('last_updated', sa.DateTime(), nullable=True), |
There was a problem hiding this comment.
A pattern I've generally used is to keep two timestamps on records like this: a created_at and an updated_at. Not sure in this case it matters, but in previous projects it's been nice to know both in different circumstances.
There was a problem hiding this comment.
that is a solid pattern, the thing is - for SecureDrop sources we have an unusual situation, in that to reduce metadata, we store (on the server) only the latest timestamp the source submitted a message or document. This last timestamp is kept such that we can display e.g. 2 days ago to show when a source last submitted something in the journalist UI. Not storing the rest of the timestamps is to minimize useful information for leak investigators in case of server compromise. But we do store the order of messages/replies/documents via storing the interaction count (the integer which begins each filename e.g. 2-glued-abnormality.msg) so the conversation view is still possible, but it wouldn't have created timestamps in this initial iteration (the MVP here is using the existing SecureDrop servers).
that said, it seems like this information would be useful for journalists being able to see the fully history of when files/messages/documents were submitted. We should consider this for the future: we could store this timestamp information only in the client-side vault VMs, and then store those columns encrypted on the server. I'll file a followup for this. Edit: filed #13
| sa.Column('id', sa.Integer(), nullable=False), | ||
| sa.Column('uuid', sa.String(length=36), nullable=False), | ||
| sa.Column('journalist_designation', sa.String(length=255), | ||
| nullable=False), |
There was a problem hiding this comment.
See just below for a discussion about tag-like data modeling... again without knowing exactly what journalist designation means here, maybe something like tagging is applicable here too?
There was a problem hiding this comment.
Ahh so this is (admittedly not the clearest...) nomenclature from the SecureDrop server side: the journalist designation is the name for the source that the journalist sees, i.e. glued abnormality in this screenshot
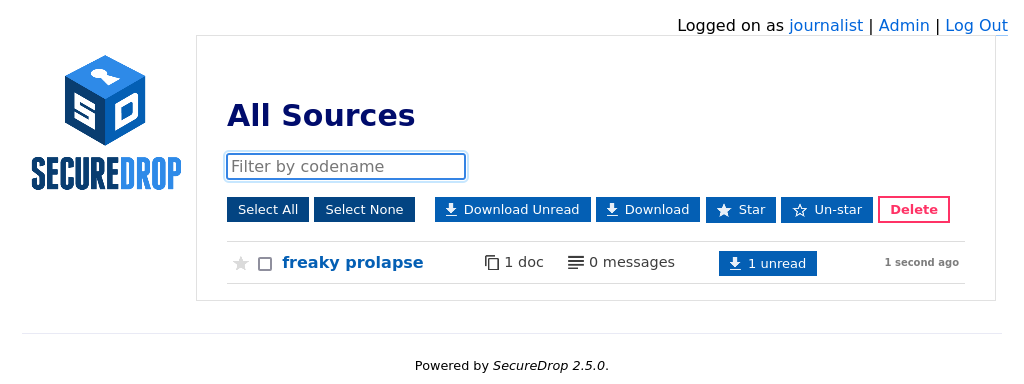{kind=link}
| sa.Column('id', sa.Integer(), nullable=False), | ||
| sa.Column('username', sa.String(length=255), nullable=False), | ||
| sa.PrimaryKeyConstraint('id'), | ||
| sa.UniqueConstraint('username') |
There was a problem hiding this comment.
Do users (journalists) authenticate themselves with the application? Do we need any auth data here?
There was a problem hiding this comment.
I've written out my thoughts so far on auth here: #14, I was thinking that we'd only store the API token in memory (the API token lasts for 8 hours), and then require users re-enter their creds to login again to the server. What do you think?
There was a problem hiding this comment.
I would want them to authenticate every time they reopen the application or token is timed out. This is not a big time consuming operation and they will keep how the whole idea much simpler.
| sa.Column('source_id', sa.Integer(), nullable=True), | ||
| sa.Column('journalist_id', sa.Integer(), nullable=True), | ||
| sa.Column('filename', sa.String(length=255), nullable=False), | ||
| sa.Column('size', sa.Integer(), nullable=False), |
There was a problem hiding this comment.
Do we want a date on replies?
There was a problem hiding this comment.
the comments above (re: #13) apply here too
| sa.Column('size', sa.Integer(), nullable=False), | ||
| sa.Column('is_downloaded', sa.Boolean(), nullable=True), | ||
| sa.Column('is_read', sa.Boolean(), nullable=True), | ||
| sa.Column('source_id', sa.Integer(), nullable=True), |
There was a problem hiding this comment.
Do we want a date on submissions?
Do we want to keep other state on submissions, to indicate to other users stuff aside from "is_read"?
There was a problem hiding this comment.
Do we want a date on submissions?
#13 applies here
Do we want to keep other state on submissions, to indicate to other users stuff aside from "is_read"?
Thinking beyond the MVP for a second, we definitely do want to store additional per-submission and per-source data when we can store it on the server (encrypted by the clients) as backup, likely candidates are custom tags, journalist assignments (something that has frequently come up in user research are the various hacky methods that organizations are using to manage which journalists are working on which SecureDrop stories, this is information that we should store in the workstations). What do you think - any other ideas we should keep in mind?
Dismissing review because I don't want it to block
In a conversation flow, there may be one source and multiple journalists. In order to display the usernames of journalists, we must save locally the journalist UUID and last observed username. Note that usernames can change, so each time we synchronize data from the server, we should update the username if it has changed.
|
chatted with @joshuathayer re: this one today, we agreed to merge as is and we can make further changes in followups (we can squash all migrations prior to initial release) |
Fixes #8 (and adds linting to CI)
Note: clients will need to add journalist users to the local users table locally as they are observed in API reply responses (which are yet to be implemented: freedomofpress/securedrop#3676. We do want to return the user in these responses so that we can display who is replied to a particular source, i.e. show the multi-party conversation flow on the journalist side. Good news - we already are storing all the necessary information on SecureDrop servers to display this to journalists).
At this point I am pausing for SDK discussion (as referenced in my email 😇), once that is done we can import here and continue on with implementation of basic methods described in freedomofpress/securedrop-workstation#88 (comment)