(Formally "Stochastic time-series analyses highlight the day-to-day dynamics of lexical frequencies", under review )
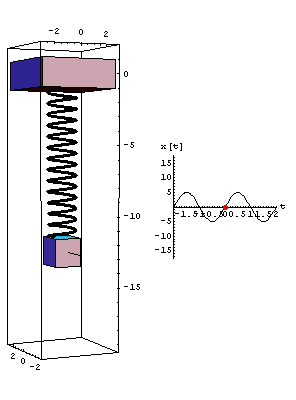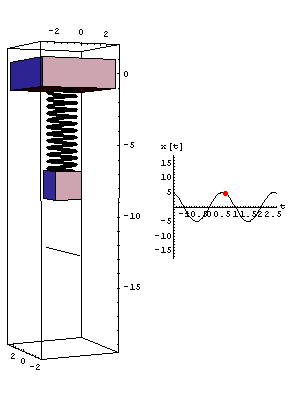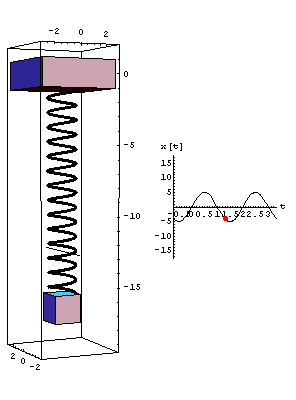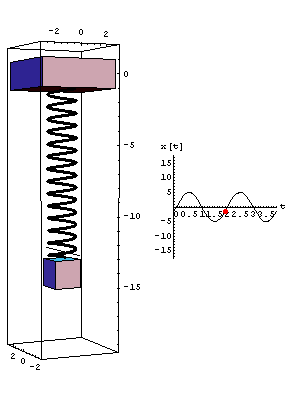
Think of a spring with a weight attached to the end. If we know the thickness of the spring, the weight of the object, and the initial displacement, we can get a pretty good idea of how the weight will move (and it's corresponding sine wave). Basically knowing only a few parameters of the system allows us to compare the behavior of two similar systems.
This project uses the same intuition. We think of words as having certain basic characteristics (kind of like weight, displacement, etc. in the spring example) that govern how they will change over time (plus noise, of course). For example, one of these parameters could be something like burstiness, or how rpaidly a word increases/decreases in usage (e.g., "wildfire" might be very bursty in a news cycle, while we'd expect "tree" to be less so). These features are latent, but we can infer them from data, i.e. a few million news articles scraped every 20 minutes for three years.
So in the end we have a bunch of parameters fit for each word and now we can talk about how words change over time by referring to their parameter values! Some words drift along, some rapidly spring into the lexicon, and some slowly decay out of favor. To our knowledge, this is the first time these types of probabilistic parameterizations have been applied to real world language.
Standard models in quantitative linguistics assume that word usage follows a fixed frequency distribution, often Zipf's law or a close relative. This view, however, does not capture the near daily variations in topics of conversation, nor the short-term dynamics of language change. In order to understand the dynamics of human language use, we present a corpus of daily word frequency variation scraped from online news sources every 20 minutes for more than two years. We construct a simple time-varying model with a latent state, which is observed via word frequency counts. We use Bayesian techniques to infer the parameters of this model for 20,000 words, allowing us to convert complex word-frequency trajectories into low-dimensional parameters in word usage. By analyzing the inferred parameters of this model, we quantify the relative mobility and drift of words on a day-to-day basis, while accounting for sampling error. We quantify this variation and show evidence against “rich-get-richer” models of word use, which have been previously hypothesized to explain statistical patterns in language.