



A robust, extensible Python data tagging framework for dynamic processing and intelligent filtering of pretraining corpora for AI models.
Install from PyPi:
pip install postit
To learn more about using Post-It, please visit the documentation.
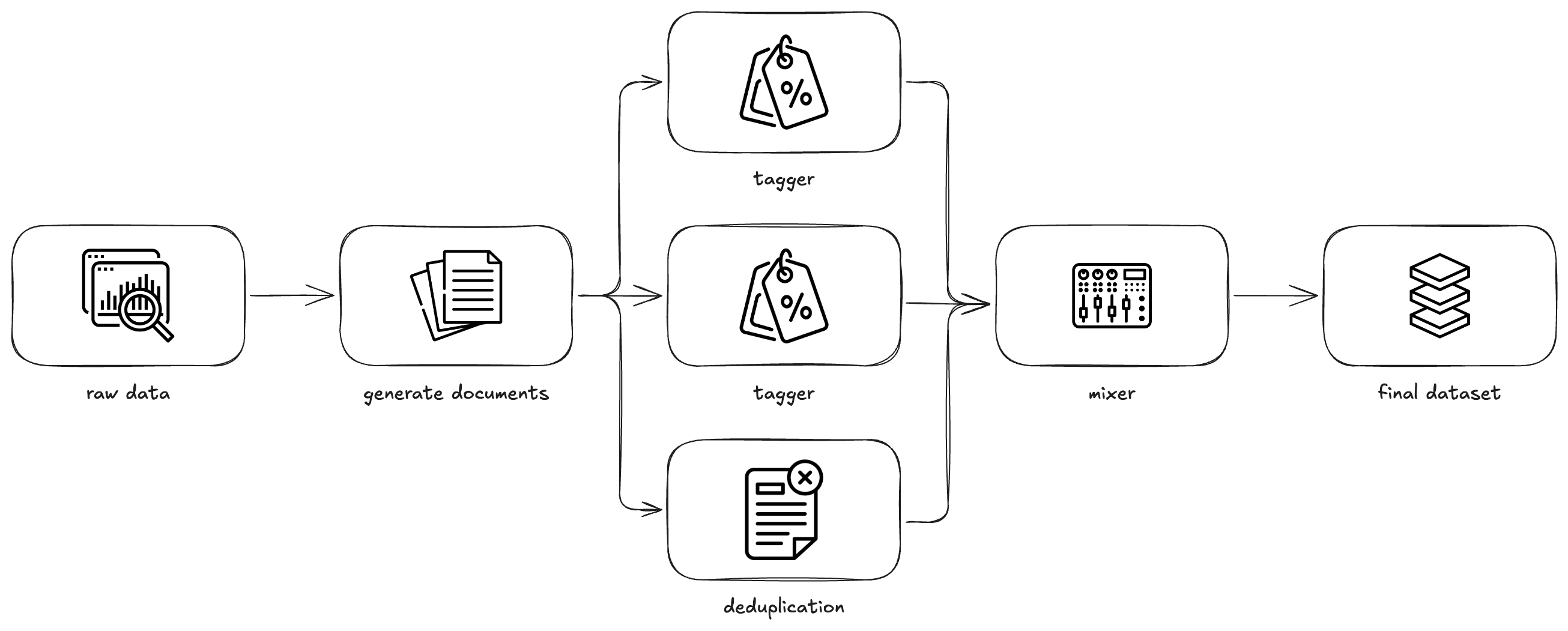
Datasets form the backbone of modern machine learning. A high-quality dataset is vital to successfully train an AI model. Data tagging is the process of labeling raw data based on the content of the data and related metadata.
The labels created by data tagging can then be used to filter out low-quality data to create a final training corpus. Efficient data tagging is becoming increasingly important with the growing popularity of continued pretraining (pretraining an existing LLM, often to adapt the model to a specific domain).
Without data tagging, creating a high-quality dataset involves directly filtering out poor data. This makes iteration and testing of different types of filters difficult and inefficient.
- Extensible: Designed for easy adaptation into any number of data processing workflows.
- Fast: Built-in parallization enables efficient processing of large datasets.
- Flexible: Supports local and remote cloud storage.
- Capable: Packaged with a variety of popular taggers, ready to use out of the box.
See contributing.