Hybrid ECS is a C++23 header-only library for ECS (Entity Component System) offering high performance and ease of use.
'Hybrid' refers to the library's mixed storage approach, combining chunk-based and sparse set-based storage, which ensures ECS maintains performance in complex compositions and large-scale applications.
Additionally, the storage is automatically managed, eliminating the need for manual data storage management.
Note: This library is currently incomplete, and support for multithreading and task orchestration is in progress.
ECS (Entity Component System), as an architectural design pattern, has garnered increasing attention in game development and high-performance computing in recent years. While Unity's ECS implementation has demonstrated strong potential in performance, it has been criticized for a cumbersome development experience. This library is an attempt to break through ECS design limitations.
This document aims to summarize the advantages and disadvantages of existing ECS systems and explore how a hybrid storage and modular grouping strategy can build a more efficient ECS solution.
There are numerous resources and projects about ECS for reference.
Refer to the following links:
- Unity's official ECS documentation
- GDC Talk: Introduction to ECS Architecture
- Game Architecture Design: Data-Oriented Programming (DOP) - KillerAery
- Blog: ECS and Data-Oriented Design
- ECS Back and Forth - EnTT
- Open Source C++ ECS Framework: UECS
The author of Flecs has a comprehensive overview of the current state of ECS development:
ECS design philosophy deeply embodies the principles of Data-Oriented Programming, aiming to maximize program performance and scalability. This philosophy emphasizes:
- Cache-Friendly Data Layouts: Optimizing CPU cache hit rates by tightly packing related data, thereby reducing access latency.
- Decoupling Logic from Data: Implementing high-efficiency parallelism in logic through independent system processing.
The essence of components lies not in what they store but in how they are stored. Efficient data layout is the starting point of ECS philosophy.
- Component composition essentially partitions sets, where different components define the behaviors of entities. The significance of systems lies not only in implementing computational logic but also in maximizing hardware resource utilization. ECS philosophy here reflects:
- Treating systems as data processors rather than data owners.
- Enhancing task scheduling parallelism through modular logic design.
This design positions ECS not just as an architectural pattern but as a holistic optimization mindset from hardware to program logic.
The current ECS storage implementations are primarily divided into two main approaches:
Entities with identical sets of components are grouped into the same array, referred to as an "Archetype Array." Storage schemes of ECS systems like Unity, Unreal, and flecs utilize this approach.
The primary advantage of using Archetype is that data for entities with the same components can be tightly packed together in sequence, making traversal more cache-friendly.
However, the Archetype approach introduces some issues:
- When an entity's components change, all its data must be transferred to a new Archetype, incurring high copying costs.
- Only entities with identical components are placed in the same Archetype:
- When an Archetype contains only a few entities, it can lead to significant memory wastage.
- With diverse component combinations, storage fragmentation can occur. In the worst-case scenario, every entity ends up in a different Archetype, which not only fails to improve cache hit rates but also incurs significant overhead due to indirect component addressing.
- Random access to components has higher addressing overhead.
Rather than calling it a Sparse Set, it might be more appropriate to call it a Component Table. In this structure, each component type has its own table, and entities map to the data within each component table via an index.
A Sparse Set is essentially an optimized mapping table container for entity indexing and traversal, functioning similarly to a hash table.
EnTT is a notable example of an ECS implementation using this structure.
This structure avoids many of the issues associated with Archetype-based systems, enabling flexible addition and removal of components and better random access performance.
Additionally, it offers a unique advantage: the ability to sort entities by specific components.
The trade-offs of using this structure include:
- For component combination queries, only one component can be accessed sequentially, while others require random access. This is an area where Archetypes have an advantage.
- Queries are more complex: With Archetypes, queries only need to identify the relevant Archetypes. In contrast, Sparse Set queries must track entity component states across multiple component tables to determine whether entities should be included in the query results. In essence, with Sparse Sets, each entity is equivalent to an Archetype in an Archetype-based system.
Archetype and Sparse Set methods each excel in different scenarios, making them complementary. Combining these two methods can yield better performance in a wider range of situations: Archetype is ideal for scenarios with a large number of similar entities, while Sparse Set handles fragmented scenarios more effectively.
Typically, an entity may have components from various modules, such as rendering, physics, AI, and other gameplay logic. Each module may contain different component combinations.
If there are
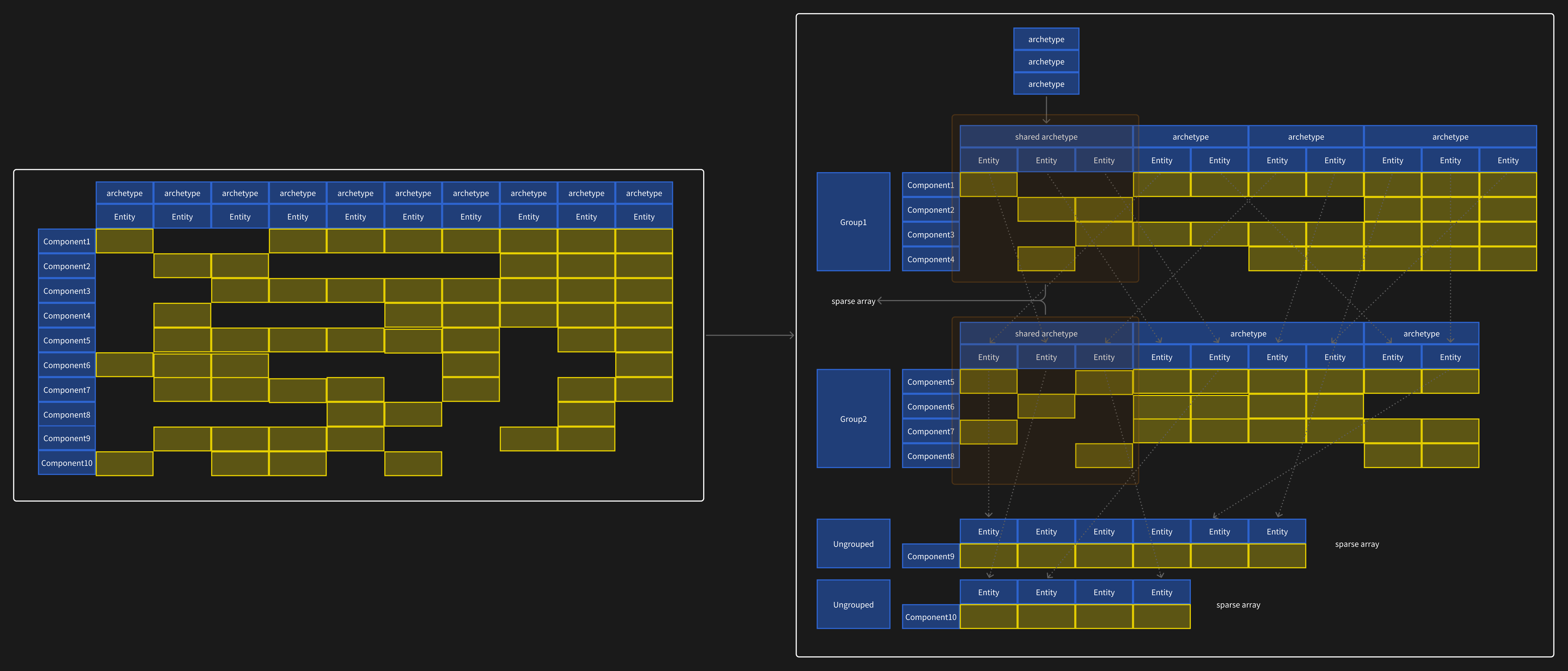
The Component Group is at the core of the hybrid method.
Components are divided into groups based on functionality, and Archetypes are only formed within groups. This significantly reduces the number of component combinations globally to
Archetypes within each group are independent, largely avoiding fragmentation. Cross-group component queries require random access.
Since most computation and data exchange occur within individual modules, grouping components according to module functionality ensures sufficient cache hit rates during hotspot computations within the module.
(Note: EnTT also has a concept of groups, but it only allows specifying components to form a single sorted group, effectively creating just one Archetype per group.)
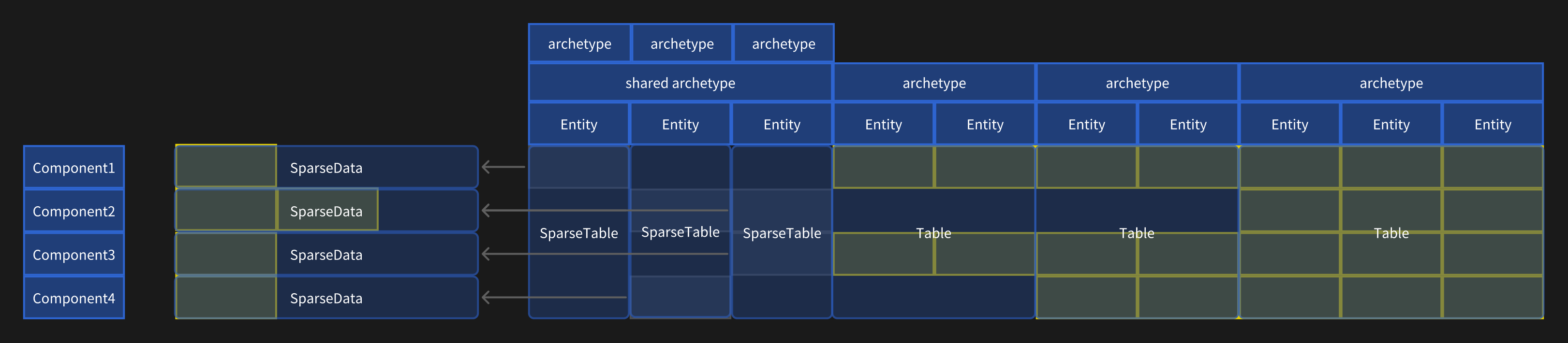
Because Archetypes with few entities not only waste memory but also exacerbate fragmentation, this hybrid storage method is employed:
- When an Archetype's memory usage is below a threshold, Sparse Set storage is used.
- When an Archetype's memory usage exceeds a threshold, chunk-based Archetype storage is used to reduce the addressing overhead for random component access.
In some cases, Sparse Sets, with their tightly packed components, can improve cache hit rates during random access.
Adding or removing components with Archetype storage incurs copying overhead.
While adding or removing components should be minimized, it is often unavoidable in ECS development, where components are frequently added or removed to control the execution of systems.
Various ECS implementations offer solutions to this problem. For example, Unity's IEnableableComponent occupies space within the Archetype just like normal components. By adding a series of masks to mark whether the component is present for a specific entity, this solution is straightforward but introduces issues:
- Memory Waste: Especially when only a small subset of entities in an Archetype requires this feature.
- Query Overhead: Queries must traverse the Archetype, which can become costly if only a small portion of entities in the Archetype need this feature.
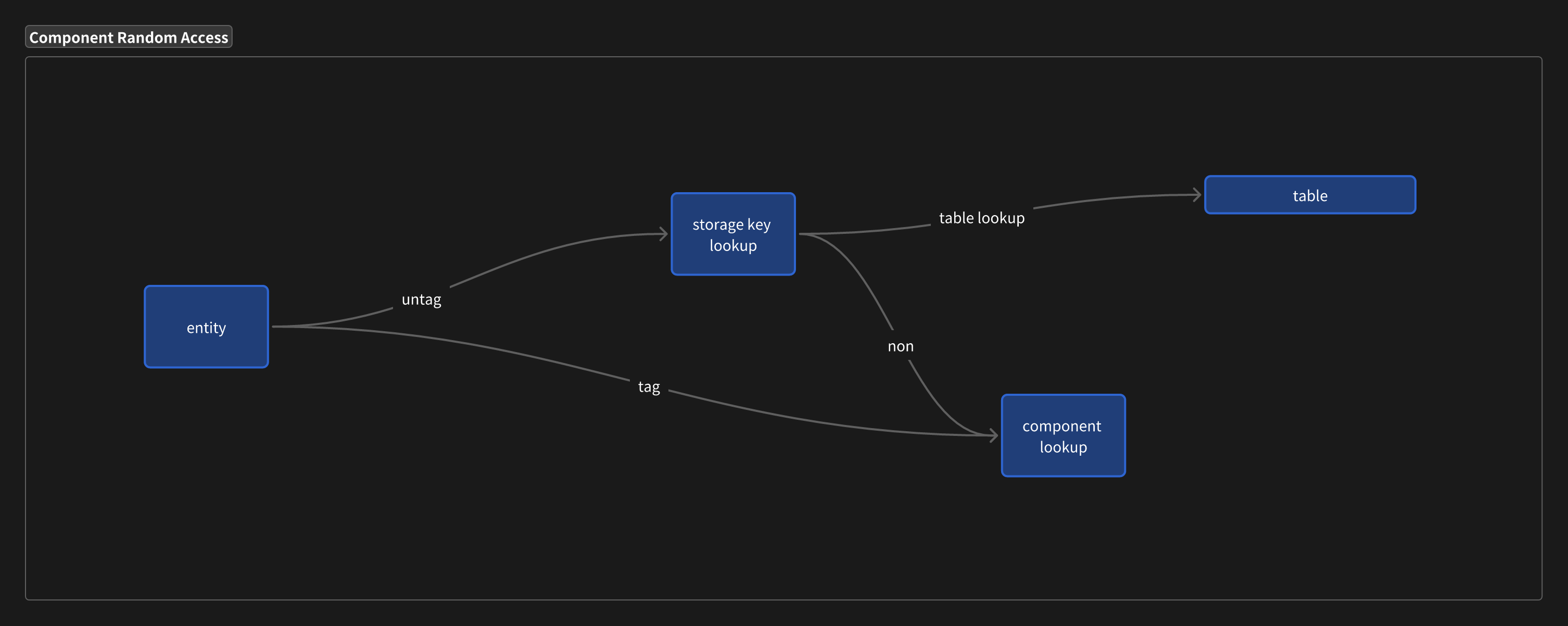
To address this, frequently added or removed components can be marked as Tag Components.
Tag Components are not stored in Archetypes but in Sparse Sets, avoiding memory waste and making them inherently efficient for addition and removal. Empty components require no storage at all.
Tag Components are typically components without associated data and are generally represented as empty structs. I couldn't think of a better name, so "Tag Component" seems the most fitting.
To enable efficient querying of Tag Components, Tag Archetypes are introduced. Essentially, a Tag Archetype represents a subset of entities within an Archetype.
- Tag Archetypes are mutually exclusive but are always subsets of an Archetype.
- During queries, Tag Archetypes within the same Archetype are aggregated, improving cache hit rates.
In ECS, users focus on logic within Systems and the data required by Queries, while ECS handles many other considerations.
A Query serves as the bridge between logic and data, forming a core concept in ECS.
Queries identify the relevant data by describing the conditions.
In many ECS implementations, Queries are relatively simple. For example:
- In Archetype-based systems, implementations typically iterate through all Archetypes to filter the desired data. Since Queries are not performance bottlenecks in purely Archetype-based ECS systems, this approach suffices.
- In Sparse Set-based systems, Queries often cache the entities matching the conditions and monitor additions/removals in the relevant component tables to update the cache.
In Hybrid ECS (HECS), due to its mixed storage architecture, optimization for aggregation, and the potential presence of numerous Queries and Archetypes, Query complexity increases significantly, necessitating a dedicated module to address these issues.
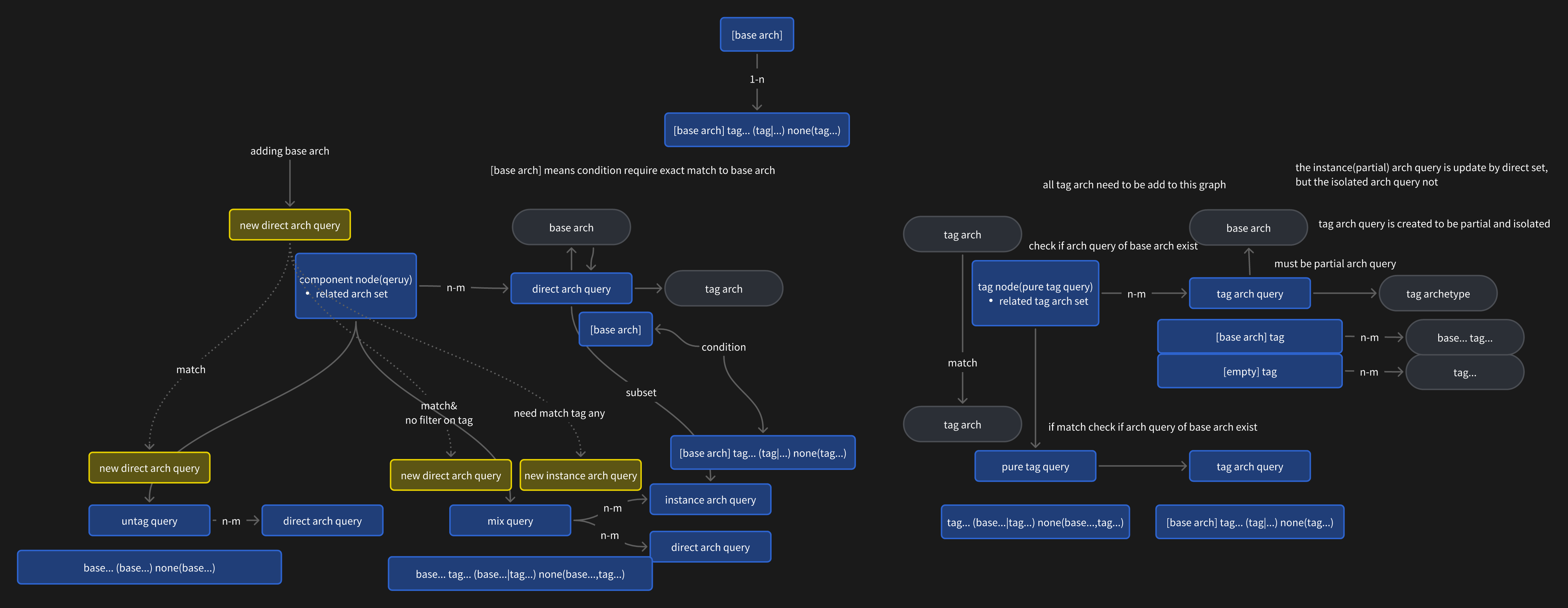
Queries are divided into two parts: data access updates and data querying.
A Query specifies conditions to identify a subset of entities.
Archetypes represent individual points within this subset.
Essentially, Queries perform two tasks:
- Adding new Archetypes that match the Query.
- Adding new Queries that match the Archetype.
Supported query types include:
- All Matching (
all) - Any Matching (
any) - Exclude (
none)
A complete condition can be described as:
base... tag... ((base...|tag...) ...) none(base...,tag...)
This can be split into three parts:
- All Part:
base... tag... - Any Part:
(base...|tag...) ... - None Part:
none(base...,tag...)
Depending on the presence of tags, Queries can be classified as:
- Untagged Queries / Direct Queries:
- Conditions do not include tags.
- Directly access Archetypes.
- Format:
base... (base...) none(base...)
- Mixed Queries:
- Conditions include tags.
- Access Archetypes or Tag Archetypes.
- Format:
base... tag... ((base...|tag...) ...) none(base...,tag...)
- Pure Tag Queries:
- All matching conditions consist only of tags.
- Access only Tag Archetypes.
- Format:
tag... ((base...|tag...) ...) none(base...,tag...)
Additionally, there are special Query types:
- Archetype Query: Queries Tag Archetypes with identical Archetypes.
- Component Query: Queries containing only one component, used as a basic node.
A Subquery is a subset of entities defined by another Query.
Filtering Archetypes from a parent Query reduces the search space, improving efficiency.
Cross-Group Query is an extension of In-Group Query, which can query across multiple groups.
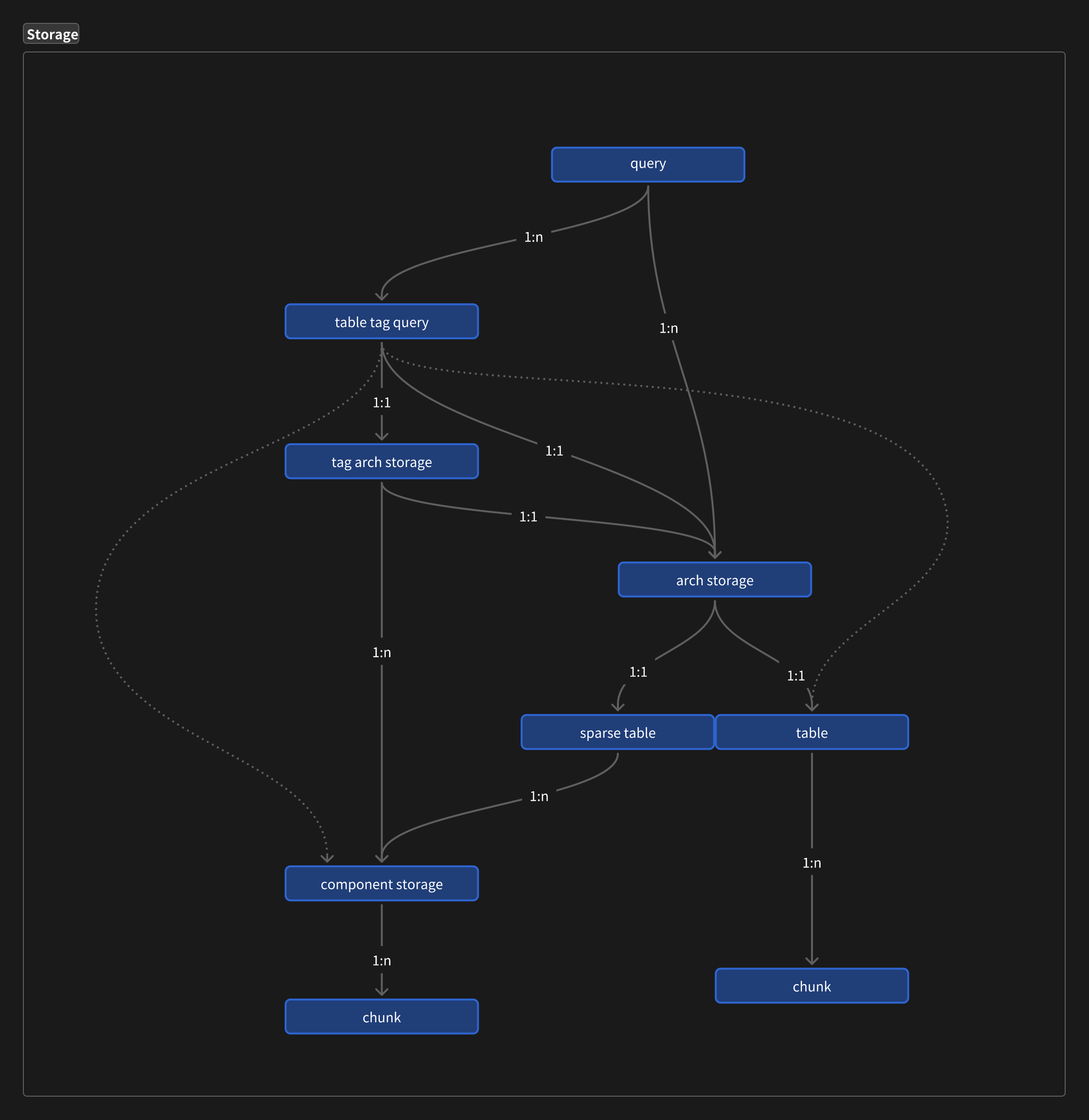
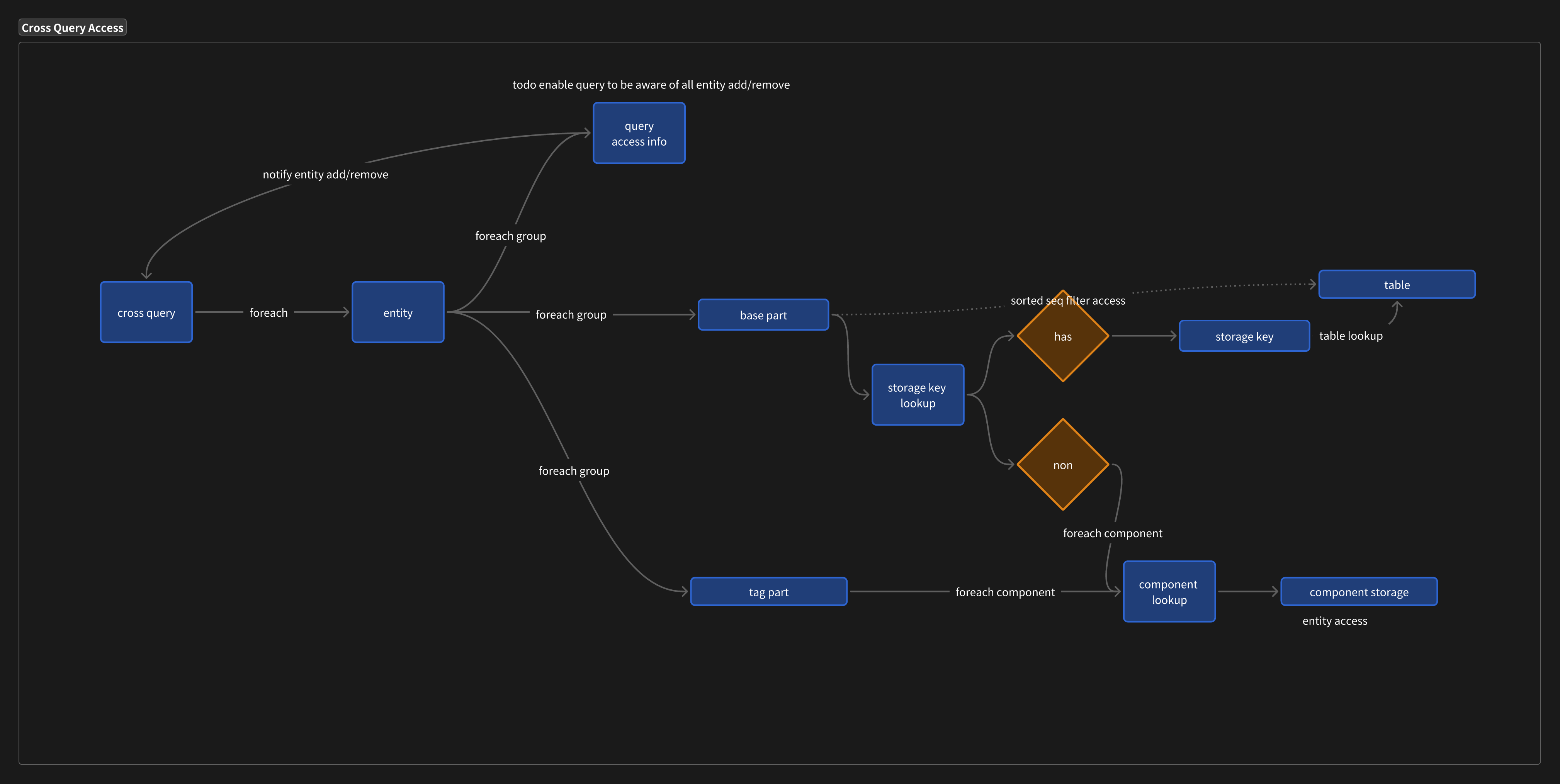
The memory access model of In-Group Query is as follows:
- query: An entry point for accessing an In-Group Query
- table tag query: Filter by tag, access a subset of a table, for each table, query its tags
- arch storage: Storage of Archetypes, for each table, query its base
- sparse table: Archetypes use sparse set storage
- table: Archetypes use table storage
- component storage: Components implemented using sparse set storage
An example of a query might be as follows:
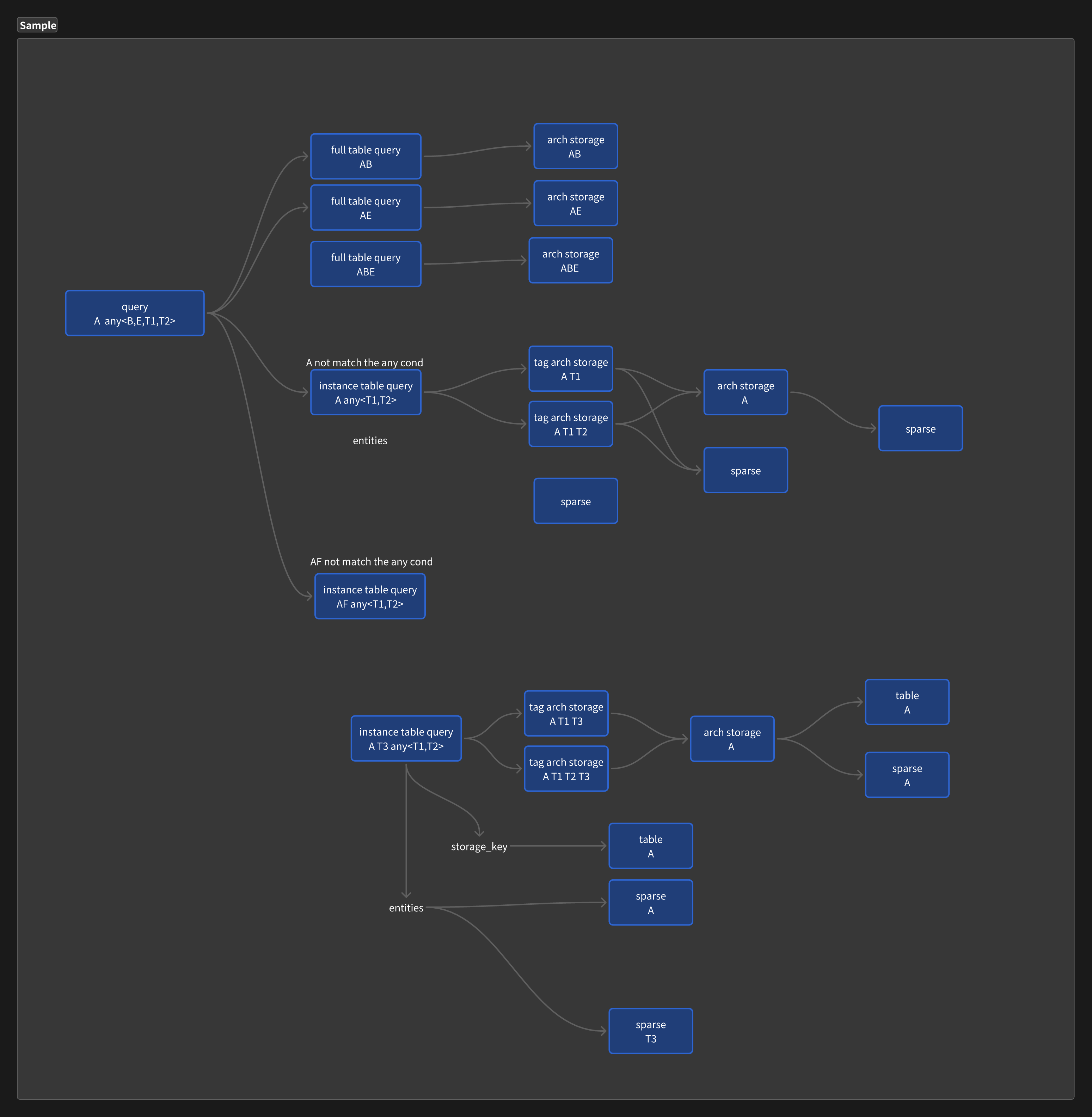
Cross-Group Query is implemented by counting potential combinations.
A count table: Records the number of groups that match each entity. An entity cache table: Records entities that meet the conditions.
Cross-Group cannot be accessed sequentially, only randomly group by group.
[todo]
[todo]
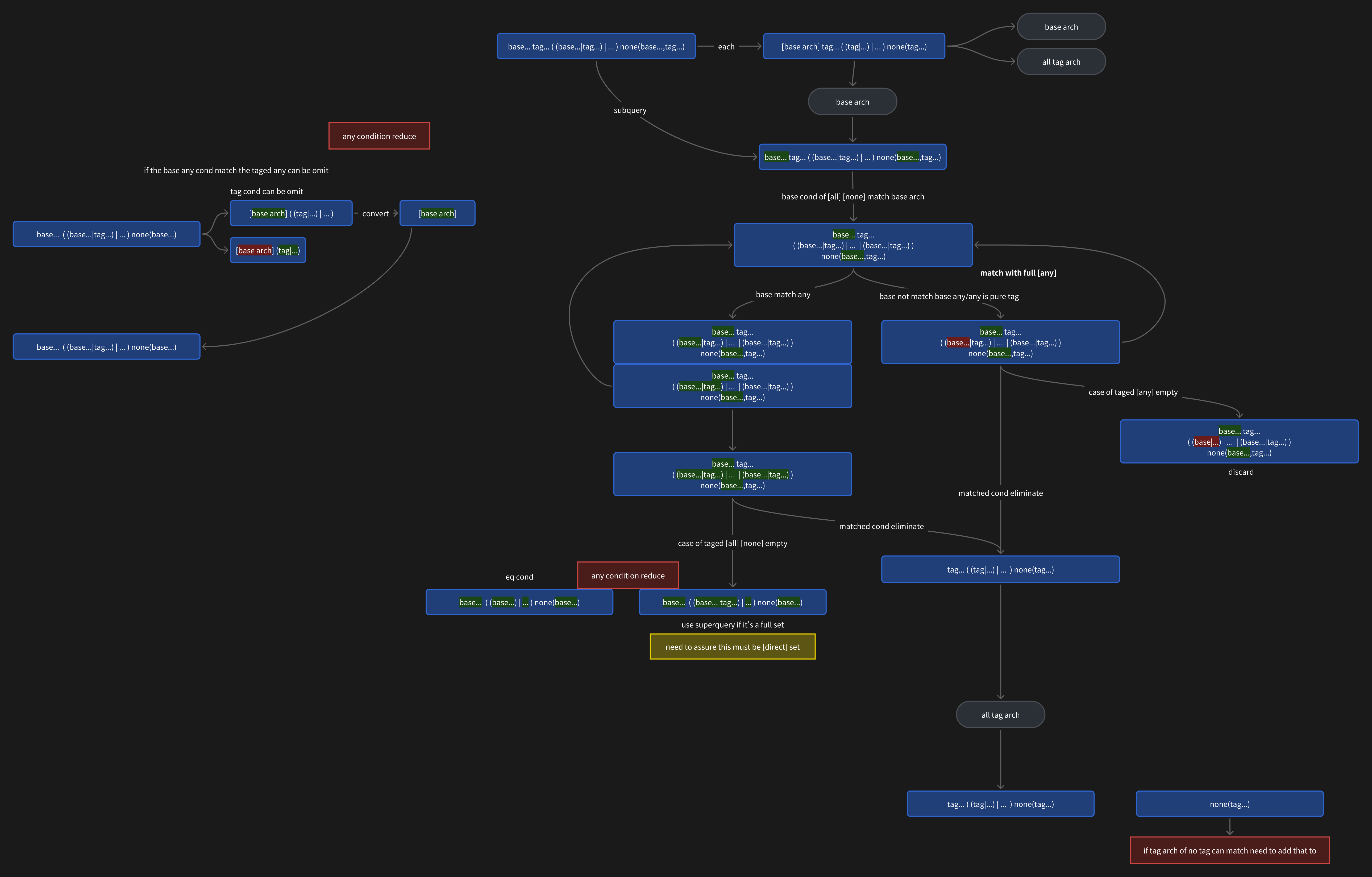
Cross-Group Query is implemented by counting potential combinations.
A count table: Records the number of groups that match each entity. An entity cache table: Records entities that meet the conditions.
[todo]
C++ provides strong type description capabilities. For convenience in writing Systems, it is ideal to describe static query conditions directly in the function parameters of a System.
Work in progress.
builder.register_executer([](
const A& a,
B& b,
D& d,
optional<const C&> c,
none_of<E, F>,
relation_ref<"o1">,
relation_ref<"o2">,
begin_rel_scope<relation1, "o1">,
const A& a1,
B& b1,
none_of<C, D>,
relation_ref<"o3">,
end_rel_scope,
begin_rel_scope<relation2, "o2">,
const A& a2,
const B& b2,
const C& c2,
relation_ref<"o3">,
end_rel_scope,
begin_rel_scope<relation3, "o3">,
A& a3,
B& b3,
end_rel_scope,
multi_relation<child(
A&,
B&
)> rel2
)
{
// System body...
});Event-driven programming is indispensable in logic development, yet many ECS frameworks lack comprehensive support for it. Unity's ECS, for instance, does not support event-driven programming at all, making certain logic challenging to implement purely through ECS.
Event-driven programming provides timely responses and ensures the proper execution order of Systems.
While data-oriented programming may seem unrelated to event-driven programming, events can be conceptually viewed as responses to changes in specific data. Unlike the highly coupled approach of "calling one procedure during another," event-driven programming delegates the scheduling of processes to a data management mechanism.
In ECS, event responses are treated as writing and processing specific data.
For example, after updating numeric data in a UI component, there should be a System to handle the change.
Work in progress.
When developing logic, it’s often necessary to process data across multiple entities. However, handling interactions between entities without a dedicated Relation system in ECS can be cumbersome.
Typically, developers need to manually record related entities within a component and access their data through random component lookups. This approach leads to several issues:
- Uncontrolled Lifecycles: The lifecycle of the other entity is not managed, potentially leading to invalid entity references.
- Unconstrained Components: The presence of specific components in other entities is not guaranteed, requiring the developer to handle these cases manually, which affects reliability and maintainability.
- Inefficient Access: Jointly accessing multiple components of other entities introduces more random access overhead.
Without a Relation system to handle these complexities, ECS development becomes increasingly painful.
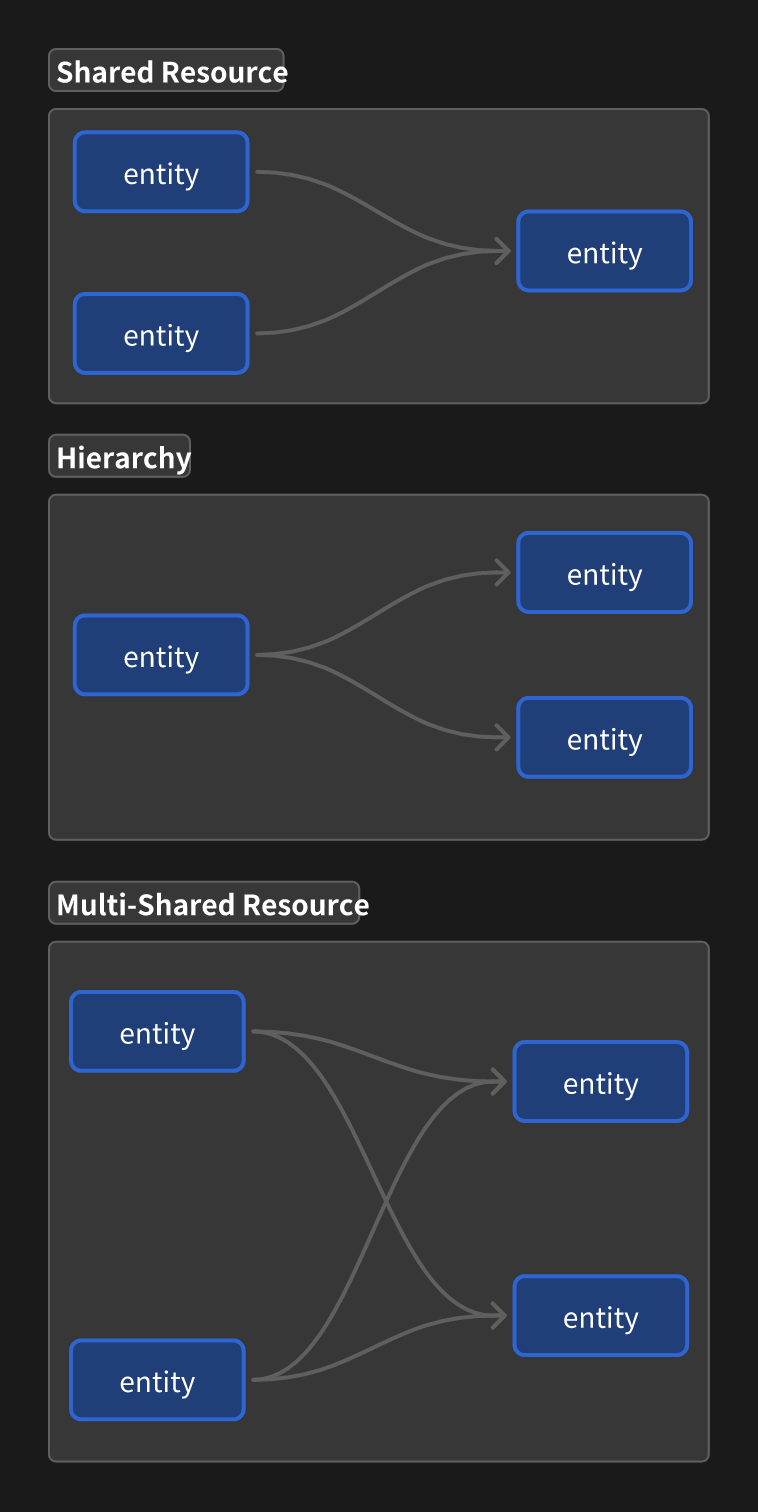
Work in progress.
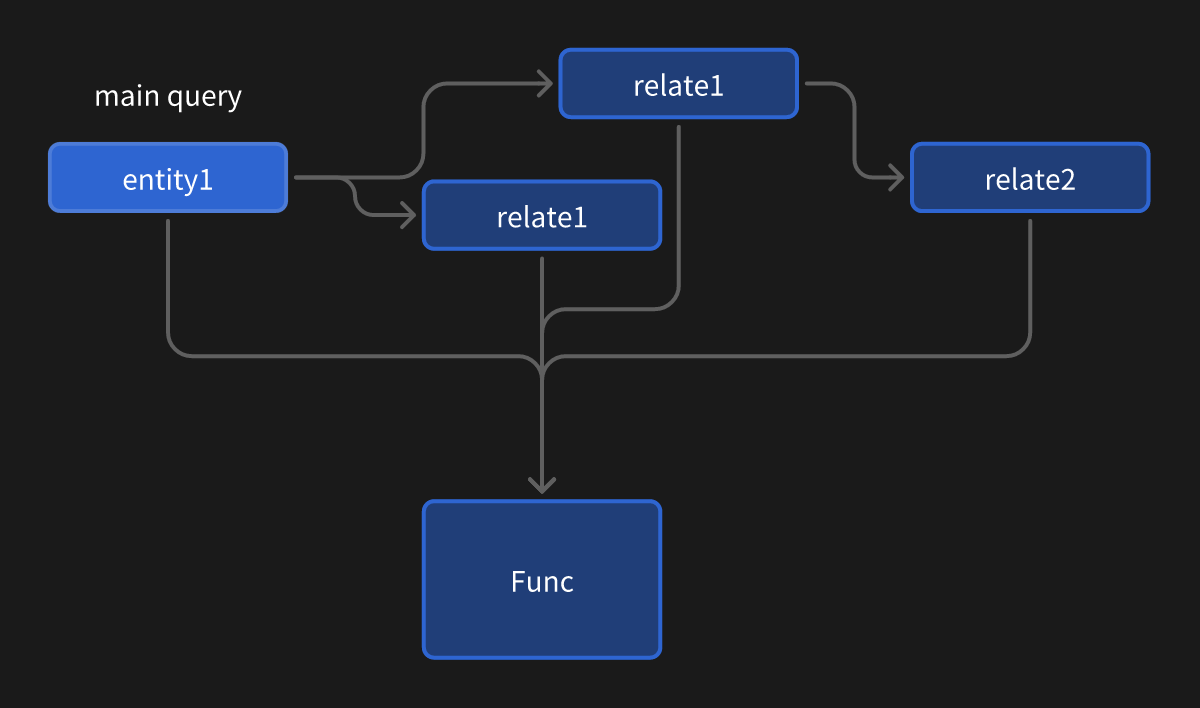
Work in progress.