Harnessing Large Language Models Over Transformer Models for Detecting Bengali Depressive Social Media Text: A Comprehensive Study
In an era of underdiagnosed depression, our research links mental health with social media, focusing on early detection of depression in Bengali text. We explored models like GPT-3.5, GPT-4, and the fine-tuned DepGPT, alongside deep learning models (LSTM, Bi-LSTM, GRU, BiGRU) and transformer models (BERT, BanglaBERT, SahajBERT). The study categorizes social media data into "Depressive" and "Non-Depressive" using a newly curated Bengali Social Media Depressive Dataset (BSMDD).
Our research highlights the performance of SahajBERT and Bi-LSTM (FastText) for Bengali depressive text classification, while also emphasizing the role of LLMs, particularly DepGPT, which achieved a near-perfect accuracy of 0.9796 and an F1-score of 0.9804. DepGPT outperforms Alpaca Lora 7B in zero-shot and few-shot scenarios. Despite the competitive performance of GPT-3.5 Turbo and Alpaca Lora 7B, they show limited effectiveness in these learning contexts.

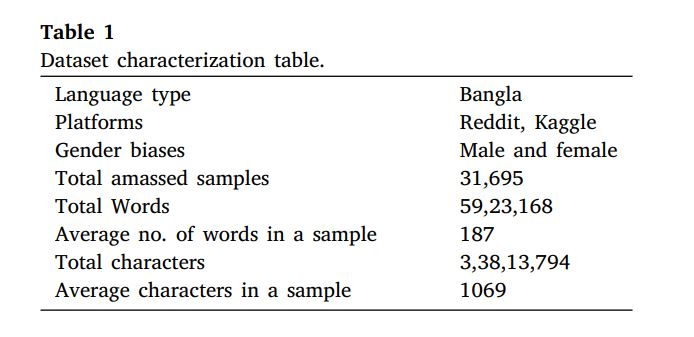
Our dataset, BSMDD, is translated and annotated by native Bengali speakers proficient in both English and Bengali, with a background in mental health. The dataset is available for public access, contributing to further research in depression detection in Bengali social media content. Please, cite this paper if you do further experimentation on this dataset. Approximately, 21,910 cleaned data samples, 10,961 Depressed (labeled 1) and 10,949 Non-Depressed (labeled 0) is published. ResearchGate Link for Dataset access.
Here are the experimental results comparing LLMs in both zero-shot and few-shot scenarios:
| Model | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| Zero-shot | ||||
| GPT-3.5 Turbo | 0.8608 | 0.8931 | 0.8477 | 0.8698 |
| DepGPT (Fine-tuned GPT-3.5) | 0.9248 | 0.8899 | 0.9848 | 0.9349 |
| GPT-4 | 0.8747 | 0.8452 | 0.9442 | 0.8921 |
| Alpaca Lora 7B | 0.7549 | 0.7121 | 0.9291 | 0.8062 |
| Few-shot | ||||
| GPT-3.5 Turbo | 0.8981 | 0.8846 | 0.9205 | 0.9022 |
| DepGPT (Fine-tuned GPT-3.5) | 0.9796 | 0.9615 | 0.9998 | 0.9804 |
| GPT-4 | 0.9388 | 0.9231 | 0.9611 | 0.9412 |
| Alpaca Lora 7B | 0.8571 | 0.8752 | 0.8409 | 0.8571 |
@article{CHOWDHURY2024100075,
title = {Harnessing large language models over transformer models for detecting Bengali depressive social media text: A comprehensive study},
journal = {Natural Language Processing Journal},
volume = {7},
pages = {100075},
year = {2024},
issn = {2949-7191},
doi = {https://doi.org/10.1016/j.nlp.2024.100075},
url = {https://www.sciencedirect.com/science/article/pii/S2949719124000232},
author = {Ahmadul Karim Chowdhury, Saidur Rahman Sujon, Md. Shirajus Salekin Shafi, Tasin Ahmmad, Sifat Ahmed, Khan Md Hasib, Faisal Muhammad Shah}
}