{kind=link}
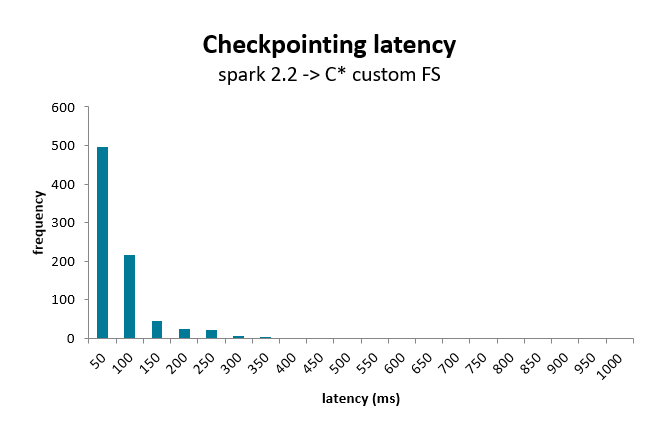
Example of an implementation of hadoop FileSystem on Cassandra. Allow faster checkpointing for structured streaming (<100ms)
Create C* table:
create table $keyspace.$table (path text, name text, is_dir boolean, length bigint, value blob, primary key ((path), name));
Spark configuration:
SparkSession.builder
.config("spark.hadoop.fs.ckfs.impl", "exactlyonce.CassandraSimpleFileSystem")
//optional:
.config("spark.hadoop.cassandra.host", "127.0.0.1")
.config("spark.hadoop.cassandra.checkpointfs.keyspace", "checkpointfs")
.config("spark.hadoop.cassandra.checkpointfs.table", "file")
val query = ds.writeStream
.option("checkpointLocation", "ckfs://127.0.0.1/checkpointing/exactlyOnce")
.queryName("exactlyOnce").foreach(writer).start