Add DuplicatePropertyNameChecker to ObjectPool #2328
Conversation
| { | ||
| if (_objectsAvailable.Count != 0) | ||
| { | ||
| var obj = _objectsAvailable[0]; |
There was a problem hiding this comment.
I believe because we remove the 0 element two lines down, so 0 is always the "next" available. It might make more sense to use a stack for this in that case, though I'm a bit skeptical of the .net stack implementation (no real reason, I just don't have enough experience with it to say that it's good).
It might be best to just store the index of the next available, and increment/decrement from that. List<T>.RemoveAt is pretty expensive. I would guess you would have even more performance improvement using an index field instead.
There was a problem hiding this comment.
List<T>.RemoveAt() on the last index is constant-time since it only decrements counters. It's also the same as stack.Pop since Stack in .NET is a wrapper around an array (and is similar to List in terms of implementation and perf if I'm not mistaken). Maybe @KenitoInc should consider adding and removing from the end.
There was a problem hiding this comment.
Changed implementation to use a fixed size array.
There was a problem hiding this comment.
Removed the ObjectPool and used the DefaultObjectPool from dotnet extensions.
| /// Release a DuplicatePropertyNameChecker instance. | ||
| /// </summary> | ||
| /// <returns>The created instance.</returns> | ||
| public void ReleaseDuplicatePropertyNameChecker(IDuplicatePropertyNameChecker duplicatePropertyNameChecker) |
There was a problem hiding this comment.
Curious if it would make sense to use IDisposable pattern for this
There was a problem hiding this comment.
Making the DuplicatePropertyNameChecker disposable or the ObjectPool disposable?
There was a problem hiding this comment.
@habbes DuplicateNameChecker seeing as it's always calling "create" -> "do stuff" -> "release"
There was a problem hiding this comment.
Aah okay. But I think that would require the DuplicateNameChecker retains a reference to the ObjectPool so that when "disposed" it can return itself to object pool. Is it advisable to have the duplicate name checker tightly coupled to the object pool? (or maybe some intermediary o)bject IDisposable object could link the name checker and the object pool
There was a problem hiding this comment.
Decided to keep the implementation as it is. We don't need to tightly couple the object pool and the DuplicatePropertyNameChecker.
Similar concept with the ArrayPool where we call Rent and Return directly.
test/FunctionalTests/Microsoft.OData.Core.Tests/JsonLight/ODataJsonLightValueSerializerTests.cs
Show resolved
Hide resolved
| serializer.WriteResourceValue(resourceValue, entityTypeRef, false, serializer.CreateDuplicatePropertyNameChecker()); | ||
| }); | ||
|
|
||
| Assert.Equal(@"{""Name"":""MyName"",""Location"":{""Name"":""AddressName"",""City"":""MyCity""}}", result); |
There was a problem hiding this comment.
Could you include an example test for the failing case?
There was a problem hiding this comment.
There are several existing tests
|
Seeing the allocations reduced to 4 seems to confirm a suspicion I had while reading the code. I don't think the new object pool is being called from multiple threads, is it? If not, then pretty much every use of the object pool says "give me an unused object", does some work, and the gives the object back. Are you sure that we aren't just creating a single |
| { | ||
| if (_objectsAvailable.Count != 0) | ||
| { | ||
| var obj = _objectsAvailable[0]; |
There was a problem hiding this comment.
List<T>.RemoveAt() on the last index is constant-time since it only decrements counters. It's also the same as stack.Pop since Stack in .NET is a wrapper around an array (and is similar to List in terms of implementation and perf if I'm not mistaken). Maybe @KenitoInc should consider adding and removing from the end.
| /// Release a DuplicatePropertyNameChecker instance. | ||
| /// </summary> | ||
| /// <returns>The created instance.</returns> | ||
| public void ReleaseDuplicatePropertyNameChecker(IDuplicatePropertyNameChecker duplicatePropertyNameChecker) |
There was a problem hiding this comment.
Making the DuplicatePropertyNameChecker disposable or the ObjectPool disposable?
|
|
||
| // PERF: the struct wrapper avoids array-covariance-checks from the runtime when assigning to elements of the array. | ||
| // See comment in this PR https://github.com/dotnet/extensions/pull/314#discussion_r169390645 | ||
| private struct ObjectWrapper |
There was a problem hiding this comment.
Can we quantify this performance benefit for our scenarios? I strongly consider this an anti-pattern, given that we can never actually refer to an individual ObjectWrapper without introducing impossible to find bugs. Just this line from the Return method items[i].Element = obj; would not work if written as var wrapper = items[i]; wrapper.Element = obj even though they look to be doing identical things.
There was a problem hiding this comment.
By avoiding runtime checks, we reduce CPU time.
There was a problem hiding this comment.
Is there a noticeable CPU difference in profiler or benchmarks with and without ObjectWrapper?
There was a problem hiding this comment.
I think some sort of numbers is really necessary to justify introducing this complexity.
| /// <remarks>This object pool is not thread-safe and not intended to be shared across concurrent requests. | ||
| /// Consider using the DefaultObjectPool in 8.x once we drop support for netstandard 1.1 | ||
| /// </remarks> | ||
| internal class ObjectPool<T> where T : class |
There was a problem hiding this comment.
I might be trivializing this, but why isn't this the implementation:
public sealed class ObjectPool<T>
{
private readonly Func<T> factory;
private readonly T[] items;
private readonly int next;
private readonly numberOfObjectsCreated;
public ObjectPool(Func<T> factory, int size)
{
this.factory = factory;
this.items = new T[size];
this.next = 0;
this.numberOfObjectsCreated = 0;
}
public T Get()
{
// do we need to create new items?
if (this.next == this.numberOfObjectsCreated)
{
// are we out of slots for new items?
if (this.numberOfObjectsCreated > this.items.Length)
{
throw new Exception("no more available");
}
this.items[this.next] = this.factory();
this.numberOfObjectsCreated++;
}
return this.items[this.next++];
}
public void Return()
{
this.next--;
}
}
There was a problem hiding this comment.
I'm not sure if it's a good idea to throw an exception when we're out of slots. I think in that case we should either "resize" the array (which is maybe more costly than we want to pay) or create a new object that's not stored in the pool. If there's more demand than what can fit in the pool, then the excess is not pooled, but doesn't throw either. My 2 cents.
There was a problem hiding this comment.
I've consolidated my different feedback threads into this one because I feel like something is getting lost.
- The majority of my feedback revolves around the fact that we are not just using indices to track the next items. Doing so removes so much of the code, and seems to make the total number of operations consistent for each scenario. Particularly, notice how the implementation above is O(1), while the current implementation is O(n). There is a lot of extra code to try to make it mostly perform as O(1), but I don't think we should be optimizing an O(n) algorithm when an O(1) option is available.
- By being fixed size, we lose out on the optimization if the nesting level ever changes. I'm not actually proposing that we just throw an exception if the nesting level changes, and that the customer ends up perplexed. I'm saying that a fixed size
ObjectPoolshould have in its contract that it throws when it runs out of space. We should catch this exception somewhere else (probably in theODataSerializer). If we don't throw an exception and we increase the nesting level, we will never notice that we are losing out on this optimization. I think we should either use a dynamically sized object pool, or we should throw an exception that we surface inDebugconfigurations and don't surface inReleaseconfigurations.
EDIT: another note on this, the case I'm describing here is just the obvious example of nesting levels change. Any bug that returns an extra object will cause the count to be off, and we will start leaking instances and overload the garbage collector just as we do today.
Ultimately, I think we should be using the .NET object pool implementation and we don't use an object pool for versions that don't have it. This should incentivize users to move to newer versions of .NET in order to receive these performance benefits.
There was a problem hiding this comment.
- Your solution still doesn't the resolve the issue where we have a fixed size object pool. We shouldn't be throwing an exception.
- My solution is flexible when the nesting is larger than the array size. We will still spin more objects. What will happen is when returning the objects to the pool, the extra objects will be disposed. The solution is modelled around the .Net object pool.
- In the ObjectPool docstring I have indicated we should switch to the DefaultObjectPool in 8.x once we drop support for
netstandard 1.1. Having 2 types object pools in ODL now only adds extra complexity.
Conclusion: This PR was intended on to reduce heap allocation. At the same time not regress cpu time. Further optimizations can be done later.
There was a problem hiding this comment.
Your solution still doesn't the resolve the issue where we have a fixed size object pool
It does. It throws an exception.
We shouldn't be throwing an exception
Yes we should. We need to notice when we have made an unrelated change that causes us to go beyond the current nesting level and therefore lose out on this optimization. Please address this concern that I have: if we don't throw an exception, how do we, as a team, know that we have inadvertently increased the nesting level?
My solution is flexible when the nesting is larger than the array size. We will still spin more objects.
What is the benefit of doing this? From what I see, it only serves to hide potential bugs.
The solution is modelled around the .Net object pool.
The .NET implementation has an extra requirement of being thread-safe, meaning that Interlocked.Exchange is imperative to its functioning. Because of this, reference types are needed and keeping a reference to the next item is essential. Without that requirement, we can improve performance by using a different algorithm rather than by optimizing the .NET algorithm.
In the ObjectPool docstring I have indicated we should switch to the DefaultObjectPool in 8.x once we drop support for netstandard 1.1
Please create an issue for this so that the work can be planned for and assigned
Having 2 types object pools in ODL now only adds extra complexity
I am not proposing that we have 2. I am proposing that we don't ship this optimization for older versions of .NET. This will incentivize customers to use newer versions of .NET. Alternatively, we could simply take the .NET implementation and place it directly into our repo, referencing where it came from. Then, we can ship down-level, but have complete consistency across versions.
There was a problem hiding this comment.
I don't think it's a good idea to throw an exception, because that's implying that having responses with depths that exceed the object pool size is an error. The size of the object pool shouldn't impose a limit on the depth of the response (there's a separate setting for that).
If the goal of the exception is for sanity checks to ensure we are not exceeding the object pool size due a bug in our code rather than due to the depth of the response, maybe we could have debug messages or assertions when the object pool size is exceeded, when the number of returned objects is not equal the number of requested objects, etc.
Or did you mean that we conditionally throw exceptions based on #if DEBUG or something like that?
I prefer the simpler implementation provided by @corranrogue9, but I still think it's valuable to delay allocating the array until the second element is requested, that way we avoid unnecessary allocations for non-nested responses. Unless we can demonstrate that the cost of having the if statement that's always checked is worse.
Also, since the point of this PR is to reduce allocations (and GC), I think it's okay to only care about reference types.
| { | ||
| /// <summary> | ||
| /// Caches property processing state. | ||
| /// </summary> | ||
| private IDictionary<string, State> propertyState = new Dictionary<string, State>(); | ||
| private bool disposedValue; |
There was a problem hiding this comment.
I know disposedValue is the default name suggested by VS snipped, but I think disposed sounds better and is easier to understand.
| if (this.nullDuplicatePropertyNameChecker == null) | ||
| { | ||
| // NullDuplicatePropertyNameChecker does nothing, so we can use a single instance during the writing process. | ||
| this.nullDuplicatePropertyNameChecker = new NullDuplicatePropertyNameChecker(); |
There was a problem hiding this comment.
Maybe we could even re-use a single instance across all requests. A singleton basically.
There was a problem hiding this comment.
Here we are creating it once for every writing cycle
| { | ||
| #if NETSTANDARD2_0_OR_GREATER | ||
| // We only return the DuplicatePropertyNameChecker to the object pool and ignore the NullDuplicatePropertyNameChecker. | ||
| if (settings.ThrowOnDuplicatePropertyNames) |
There was a problem hiding this comment.
Curious, does this setting guarantee that we're dealing with DuplicatePropertyNameChecker and not NullDuplicatePropertyNameChecker?
| @@ -15,12 +15,13 @@ namespace Microsoft.OData | |||
| /// 2) No duplicate "@odata.associationLink" on a property. | |||
| /// 3) "@odata.associationLink"s are put on navigation properties. | |||
| /// </summary> | |||
| internal class DuplicatePropertyNameChecker : IDuplicatePropertyNameChecker | |||
| internal class DuplicatePropertyNameChecker : IDuplicatePropertyNameChecker, IDisposable | |||
There was a problem hiding this comment.
I haven't seen the Dispose() method or a using statement being used anywhere for objects of this type. How is the IDisposable applied for this type?
When getting the item from the pool, you're calling duplicateNameChecker.Reset() manually, which is the only thing that dispose seems to be doing. Not sure where else dispose is being applied.
| { | ||
| if (disposing) | ||
| { | ||
| Reset(); |
There was a problem hiding this comment.
Is it necessary to reset the duplicate checker if it's not going to be used again?
|
This PR has Quantification details
Why proper sizing of changes matters
Optimal pull request sizes drive a better predictable PR flow as they strike a
What can I do to optimize my changes
How to interpret the change counts in git diff output
Was this comment helpful? 👍 :ok_hand: :thumbsdown: (Email) |

Issues
This pull request fixes #2180 .
Description
We were creating a new instance of the
DuplicatePropertyNameCheckerwhen serializing everyODataResource. This resulted in too many allocations causing pressure on the GC.This PR adds an ObjectPool which stores instances of
DuplicatePropertyNameChecker. Everytime we are serializing anODataResource, we request aDuplicatePropertyNameCheckerfrom the ObjectPool. Once we are done serializing theODataResource, we release theDuplicatePropertyNameCheckerto the ObjectPool.Performance profiler comparison results
We wrote a sample service that writes this response 5000 times
{ "@odata.context": "http://www.example.com/$metadata#Customers", "value": [ { "Id": 1, "Name": "Cust1", "Emails": [ "emailA$1", "emailB1 " ], "HomeAddress": { "City": "City1", "Street": "Street1" }, "Addresses": [ { "Name": "CityA1", "City": "CityA1", "Street": "StreetA1", "PostalAddress": { "Name": "PostalAddressNameA1", "PostalBox": "PostalBoxA1", "PostalCode": "PostalCodeA1", "PostalAddressLocation": { "Town": "TownA1", "County": "CountyA1" } } }, { "Name": "CityB1", "City": "CityB1", "Street": "StreetB1", "PostalAddress": { "Name": "PostalAddressNameB1", "PostalBox": "PostalBoxB1", "PostalCode": "PostalCodeB1", "PostalAddressLocation": { "Town": "TownB1", "County": "CountyB1" } } }, { "Name": "CityC1", "City": "CityC1", "Street": "StreetC1", "PostalAddress": { "Name": "PostalAddressNameC1", "PostalBox": "PostalBoxC1", "PostalCode": "PostalCodeC1", "PostalAddressLocation": { "Town": "TownC1", "County": "CountyC1" } } }, { "Name": "CityD1", "City": "CityD1", "Street": "StreetD1", "PostalAddress": { "Name": "PostalAddressNameD1", "PostalBox": "PostalBoxD1", "PostalCode": "PostalCodeD1", "PostalAddressLocation": { "Town": "TownD1", "County": "CountyD1" } } }, { "Name": "CityE1", "City": "CityE1", "Street": "StreetE1", "PostalAddress": { "Name": "PostalAddressNameE1", "PostalBox": "PostalBoxE1", "PostalCode": "PostalCodeE1", "PostalAddressLocation": { "Town": "TownE1", "County": "CountyE1" } } } ] } ] }Before the fix
We had 85000 allocations of the
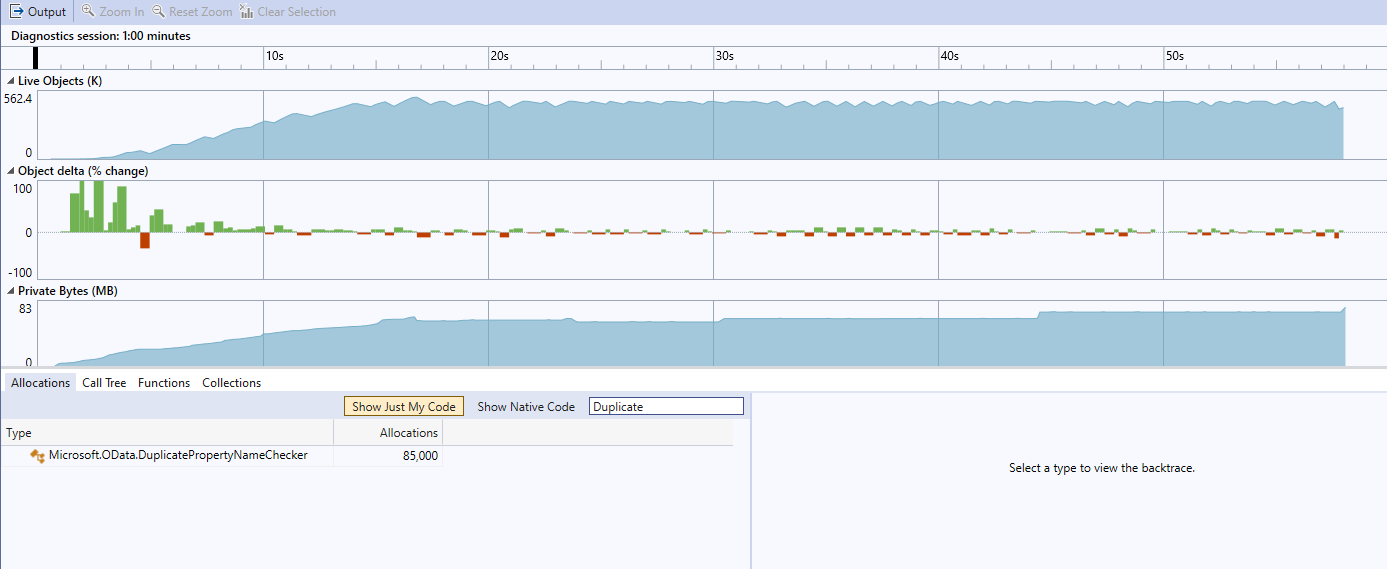
DuplicatePropertyNameCheckerTotal CPU usage was 0.52% + 0.07% = 0.59%
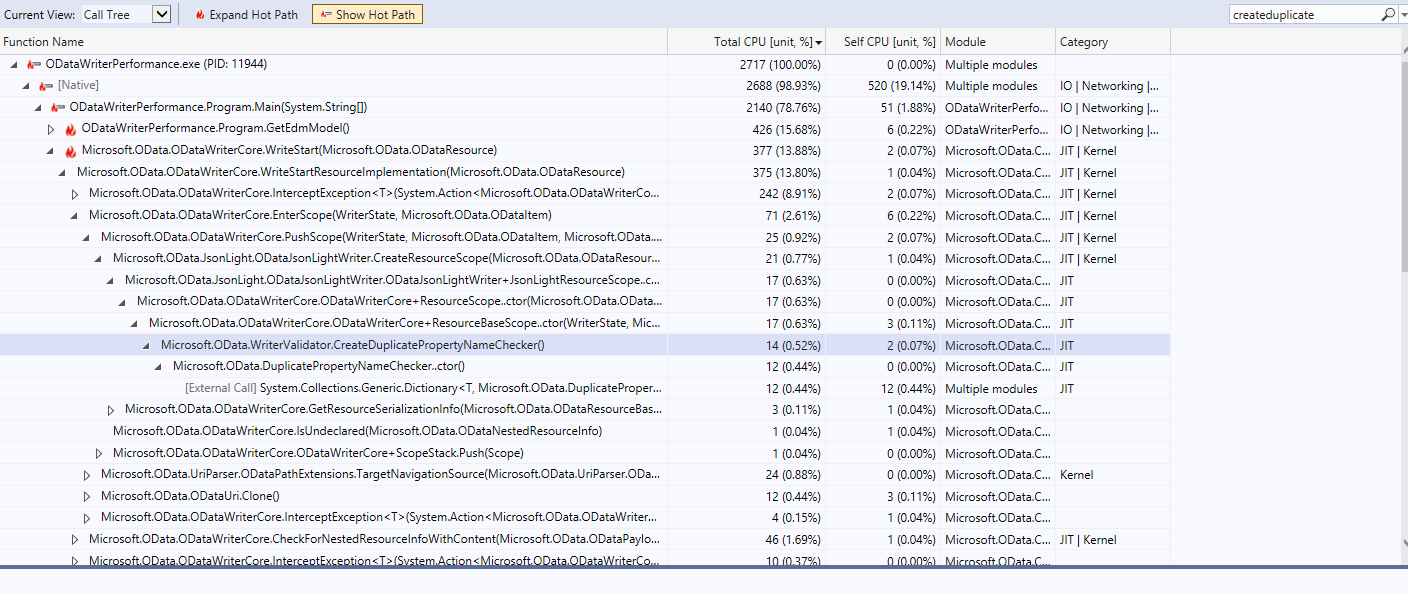
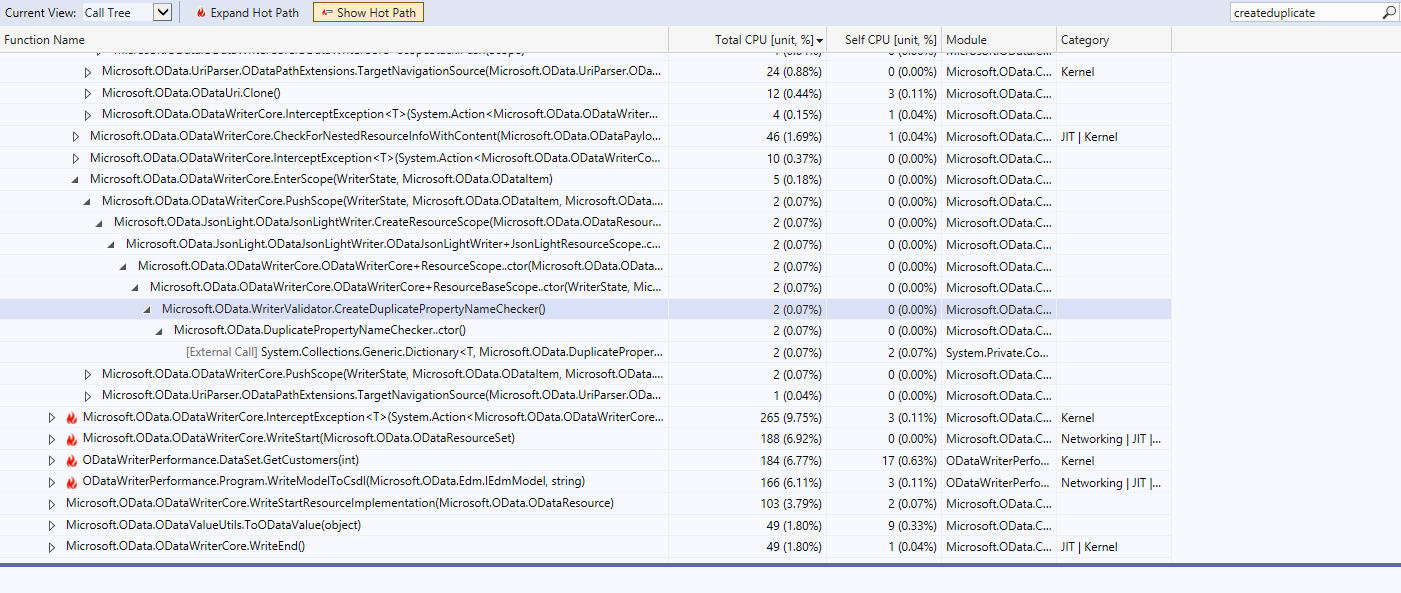
After the fix
Allocations reduced to 4
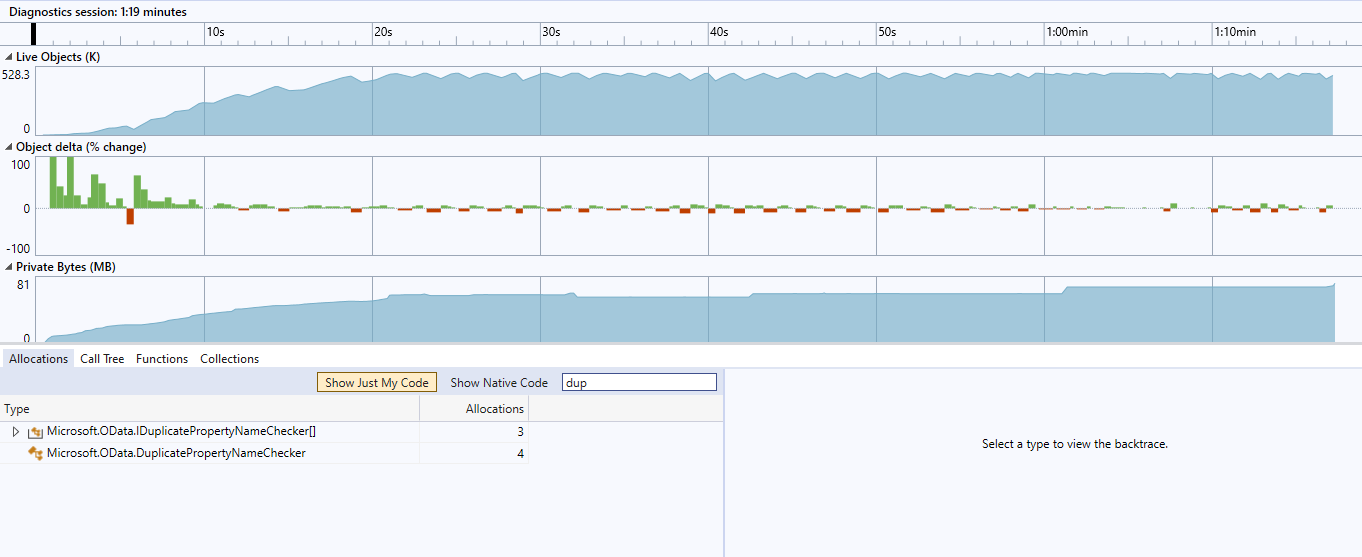
Total CPU usage dropped to 0.07% + 0.07% = 0.14%
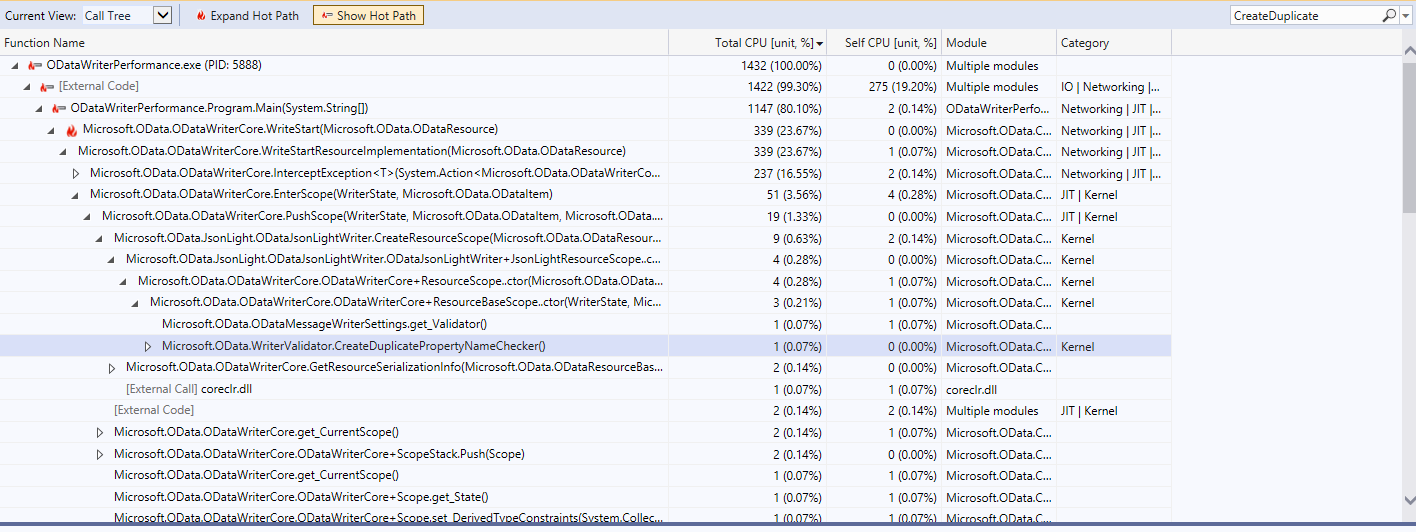
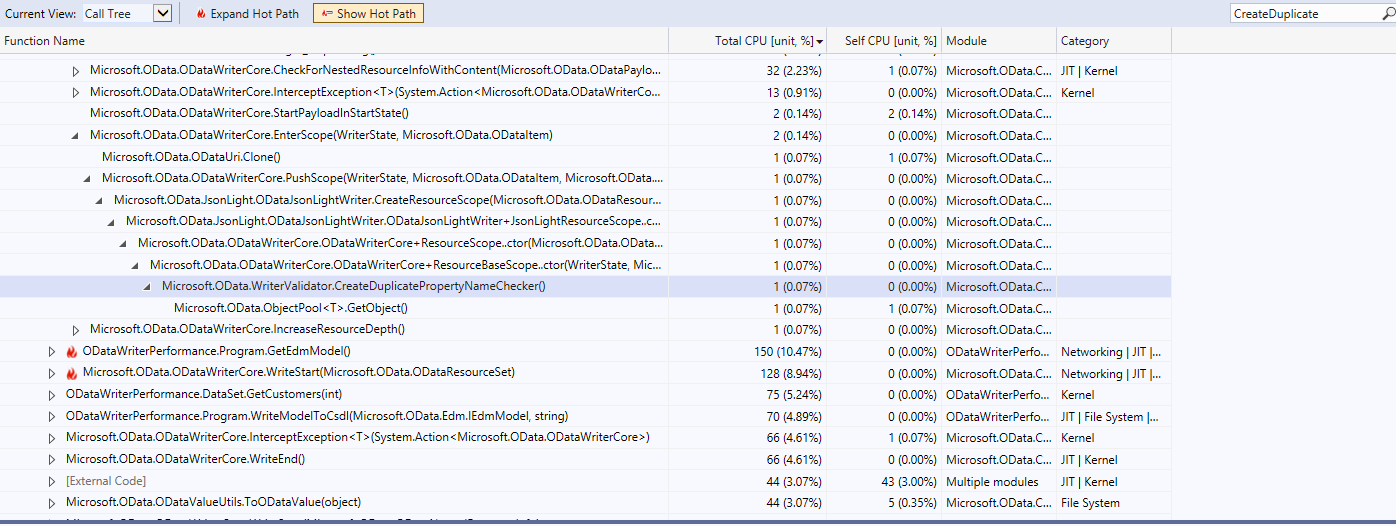
After the fix with Array
Allocations reduced to 4
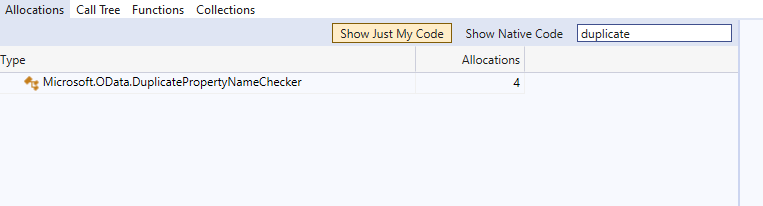
CPU reduced to 0.22%
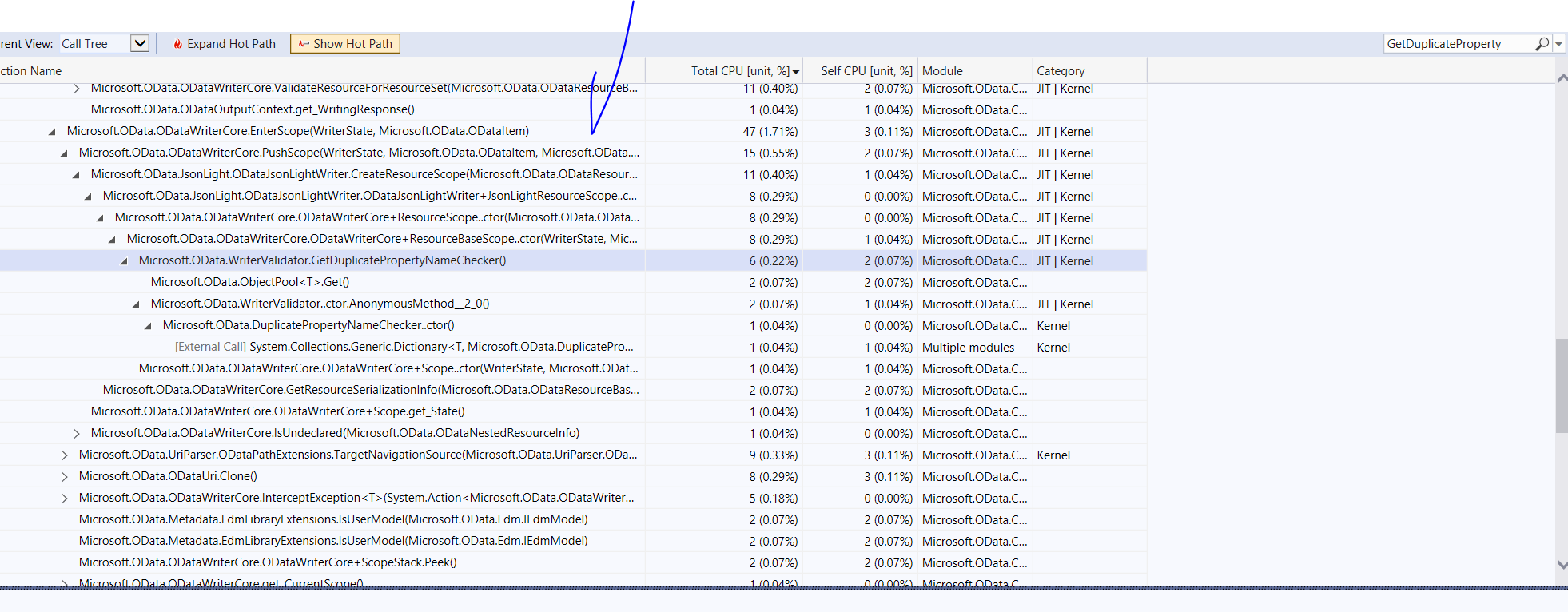
Results Comparer
Allocations
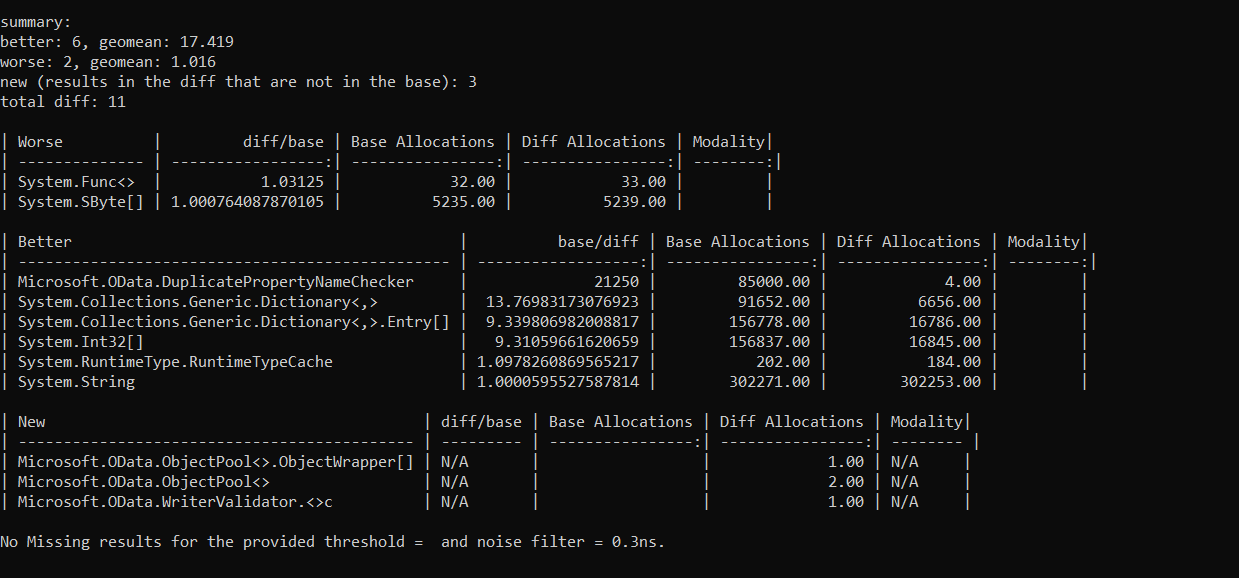
Benchmark results
Before the fix
After the fix
After the fix with Array
Checklist (Uncheck if it is not completed)
Additional work necessary
If documentation update is needed, please add "Docs Needed" label to the issue and provide details about the required document change in the issue.