This code is a language detection model that uses the Naive Bayes algorithm to classify a given text into one of the 22 languages present in the dataset.
The code imports various libraries such as pandas for data manipulation and analysis, numpy for scientific computing and working with arrays, CountVectorizer for extracting features from text data, train_test_split for splitting data into training and testing sets, and tabulate for printing out data in a formatted table.
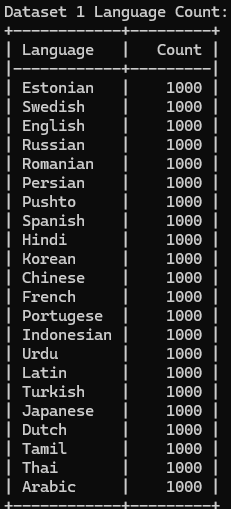
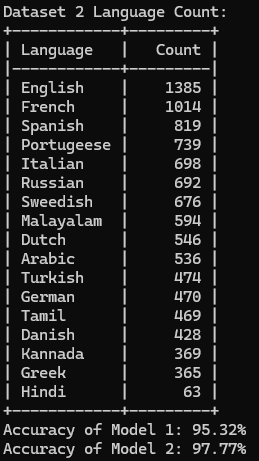
The datasets used in this code contain 39 languages (combined) with more than 1000 sentences from each language, and the output should show the count of each language in the dataset.
The code then splits the data into training and test sets and trains the Naive Bayes algorithm on the training set to predict the language of a given text. Finally, the code prints a table with the predicted language of the input text.
{kind=link}
 |
 |
|
|---|---|---|
| Dataset 1 language count | Dataset 2 language count | Language Prediction |