Question about ACFM #6
Comments
This is a good question. My assumption is: 1. ACFM is a cross-layer fusion module, and the information is transmitted forward layer by layer, that is, the high-level information (Fb) should keep close to the low-level information (Fa). Therefore, after the initial fusion and calculation of MSCA, M should be used as the Fa attention weight. 2. If the same M is used to multiply Fa and Fb at the same time, the flexibility is lost, so 1-M is used to let the module allocate the weights of Fa and Fb during model learning. I'm sorry I didn't explain this point in the paper. Thank you for your attention. |
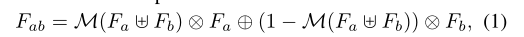
I see, thanks a lot. |
Hi, thanks for your excellent work. In this article, I have a little confusion about ACFM. Why do you use 1-M as a weighting factor to multiply Fb in the formula of the article, instead of multiplying it by M as Fa.
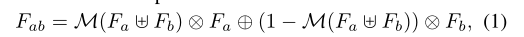
The text was updated successfully, but these errors were encountered: