@@ -981,6059 +1079,6233 @@ public The argument {@code object} is first converted into a Tensor using {@link
+ * org.tensorflow.Tensor#create(Object)}, so only Objects supported by this method must be
+ * provided. For example:
*
- * @param scope is a scope used to add the underlying operation.
- * @param data An array containing the values to put into the new constant. The dimensions of the
- * new constant will match those of the array.
- */
- public Constant Creates a constant with the given shape by copying elements from the buffer (starting from
+ * its current position) into the tensor. For example, if {@code shape = {2,3} } (which represents
+ * a 2x3 matrix) then the buffer must have 6 elements remaining, which will be consumed by this
+ * method.
*
* @param scope is a scope used to add the underlying operation.
- * @param data An array containing the values to put into the new constant. The dimensions of the
- * new constant will match those of the array.
+ * @param shape the tensor shape.
+ * @param data a buffer containing the tensor data.
+ * @return an integer constant
+ * @throws IllegalArgumentException If the tensor shape is not compatible with the buffer
+ * @deprecated use {@link Ops#val(Tensor) Ops.constant(Tensor<TInt32>)} instead
*/
- public Constant Creates a constant with the given shape by copying elements from the buffer (starting from
+ * its current position) into the tensor. For example, if {@code shape = {2,3} } (which represents
+ * a 2x3 matrix) then the buffer must have 6 elements remaining, which will be consumed by this
+ * method.
*
* @param scope is a scope used to add the underlying operation.
- * @param data The value to put into the new constant.
- * @return a boolean constant
+ * @param shape the tensor shape.
+ * @param data a buffer containing the tensor data.
+ * @return a long constant
+ * @throws IllegalArgumentException If the tensor shape is not compatible with the buffer
+ * @deprecated use {@link Ops#val(Tensor) Ops.constant(Tensor<TInt64>)} instead
*/
- public Constant Creates a constant with the given shape by copying elements from the buffer (starting from
+ * its current position) into the tensor. For example, if {@code shape = {2,3} } (which represents
+ * a 2x3 matrix) then the buffer must have 6 elements remaining, which will be consumed by this
+ * method.
*
* @param scope is a scope used to add the underlying operation.
- * @param data An array containing the values to put into the new constant. The dimensions of the
- * new constant will match those of the array.
+ * @param shape the tensor shape.
+ * @param data a buffer containing the tensor data.
+ * @return a double constant
+ * @throws IllegalArgumentException If the tensor shape is not compatible with the buffer
+ * @deprecated use {@link Ops#val(Tensor) Ops.constant(Tensor<TFloat64>)} instead
*/
- public Constant Creates a constant with the given shape by copying elements from the buffer (starting from
+ * its current position) into the tensor. For example, if {@code shape = {2,3} } (which represents
+ * a 2x3 matrix) then the buffer must have 6 elements remaining, which will be consumed by this
+ * method.
*
* @param scope is a scope used to add the underlying operation.
- * @param data An array containing the values to put into the new constant. String elements are
- * sequences of bytes from the last array dimension.
+ * @param shape the tensor shape.
+ * @param data a buffer containing the tensor data.
+ * @return a float constant
+ * @throws IllegalArgumentException If the tensor shape is not compatible with the buffer
+ * @deprecated use {@link Ops#val(Tensor) Ops.constant(Tensor<TFloat32>)} instead
*/
- public Constant Creates a Constant with the provided shape of any type where the constant data has been
+ * encoded into {@code data} as per the specification of the TensorFlow C
+ * API.
*
* @param scope is a scope used to add the underlying operation.
- * @param data An array containing the values to put into the new constant. The dimensions of the
- * new constant will match those of the array.
+ * @param type the tensor datatype.
+ * @param shape the tensor shape.
+ * @param data a buffer containing the tensor data.
+ * @return a constant of type `type`
+ * @throws IllegalArgumentException If the tensor datatype or shape is not compatible with the
+ * buffer
+ * @deprecated use {@link Ops#val(Tensor)} instead
*/
- public Constant
+ * This op exists to consume a tensor created by `MutexLock` (other than
+ * direct control dependencies). It should be the only that consumes the tensor,
+ * and will raise an error if it is not. Its only purpose is to keep the
+ * mutex lock tensor alive until it is consumed by this op.
+ *
+ * NOTE: This operation must run on the same device as its input. This may
+ * be enforced via the `colocate_with` mechanism.
*
- * @param scope is a scope used to add the underlying operation.
- * @param data An array containing the values to put into the new constant. String elements are
- * sequences of bytes from the last array dimension.
+ * @param mutexLock A tensor returned by `MutexLock`.
+ * @return a new instance of ConsumeMutexLock
*/
- public Constant
+ * Only useful as a placeholder for control edges.
*
- * @param scope is a scope used to add the underlying operation.
- * @param data An array containing the values to put into the new constant. The dimensions of the
- * new constant will match those of the array.
+ * @return a new instance of ControlTrigger
*/
- public Constant
+ * All subsequent operations using the resource will result in a NotFound
+ * error status.
*
- * @param scope is a scope used to add the underlying operation.
- * @param data An array containing the values to put into the new constant. The dimensions of the
- * new constant will match those of the array.
+ * @param resource handle to the resource to delete.
+ * @param options carries optional attributes values
+ * @return a new instance of DestroyResourceOp
*/
- public Constant
+ * Sets output to the value of the Tensor pointed to by 'ref', then destroys
+ * the temporary variable called 'var_name'.
+ * All other uses of 'ref' must have executed before this op.
+ * This is typically achieved by chaining the ref through each assign op, or by
+ * using control dependencies.
+ *
+ * Outputs the final value of the tensor pointed to by 'ref'.
*
- * @param scope is a scope used to add the underlying operation.
- * @param data An array containing the values to put into the new constant. The dimensions of the
- * new constant will match those of the array.
+ * @param
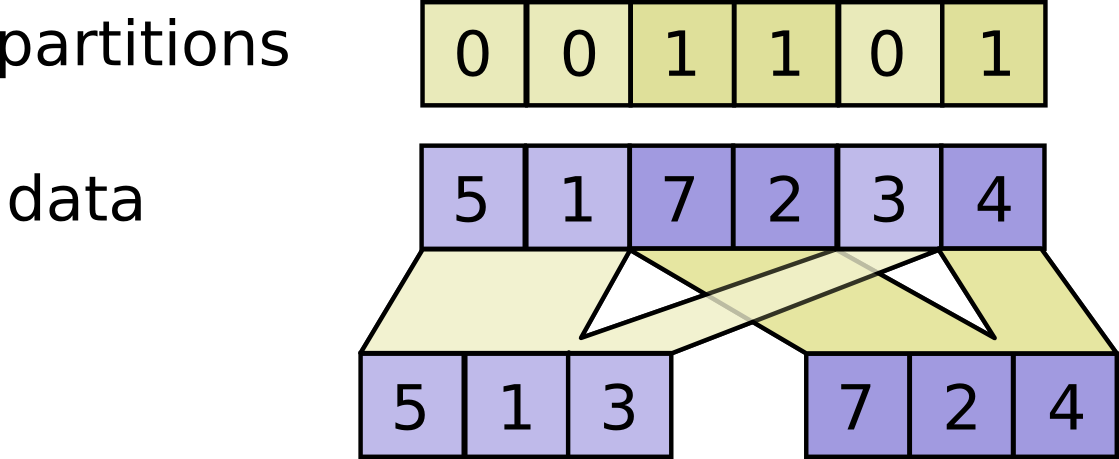
+ * For each index tuple `js` of size `partitions.ndim`, the slice `data[js, ...]`
+ * becomes part of `outputs[partitions[js]]`. The slices with `partitions[js] = i`
+ * are placed in `outputs[i]` in lexicographic order of `js`, and the first
+ * dimension of `outputs[i]` is the number of entries in `partitions` equal to `i`.
+ * In detail,
+ *
+ * For example:
+ *
+ *
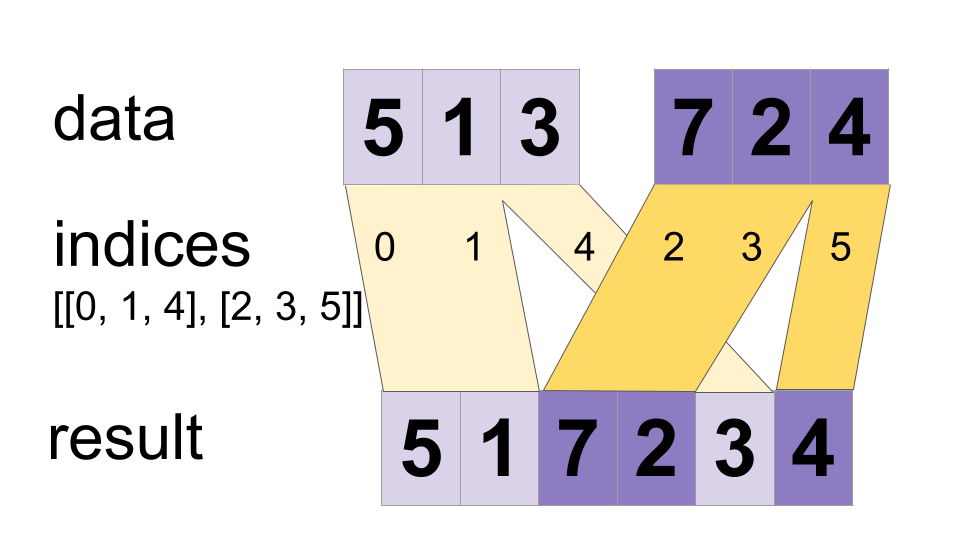
+ * Builds a merged tensor such that
+ *
+ * merged.shape = [max(indices)] + constant
+ *
+ * Values are merged in order, so if an index appears in both `indices[m][i]` and
+ * `indices[n][j]` for `(m,i) < (n,j)` the slice `data[n][j]` will appear in the
+ * merged result. If you do not need this guarantee, ParallelDynamicStitch might
+ * perform better on some devices.
+ *
+ * For example:
+ *
+ * The inputs are variable-length sequences provided by SparseTensors
+ * (hypothesis_indices, hypothesis_values, hypothesis_shape)
+ * and
+ * (truth_indices, truth_values, truth_shape).
+ *
+ * The inputs are:
*
- * @param scope is a scope used to add the underlying operation.
- * @param data An array containing the values to put into the new constant. The dimensions of the
- * new constant will match those of the array.
+ * @param hypothesisIndices The indices of the hypothesis list SparseTensor.
+ * This is an N x R int64 matrix.
+ * @param hypothesisValues The values of the hypothesis list SparseTensor.
+ * This is an N-length vector.
+ * @param hypothesisShape The shape of the hypothesis list SparseTensor.
+ * This is an R-length vector.
+ * @param truthIndices The indices of the truth list SparseTensor.
+ * This is an M x R int64 matrix.
+ * @param truthValues The values of the truth list SparseTensor.
+ * This is an M-length vector.
+ * @param truthShape truth indices, vector.
+ * @param options carries optional attributes values
+ * @return a new instance of EditDistance
*/
- public Constant
+ * This operation creates a tensor of `shape` and `dtype`.
*
- * @param scope is a scope used to add the underlying operation.
- * @param data An array containing the values to put into the new constant. The dimensions of the
- * new constant will match those of the array.
+ * @param
+ * All list elements must be tensors of dtype element_dtype and shape compatible
+ * with element_shape.
+ *
+ * handle: an empty tensor list.
+ * element_dtype: the type of elements in the list.
+ * element_shape: a shape compatible with that of elements in the list.
*
- * @param scope is a scope used to add the underlying operation.
- * @param data An array containing the values to put into the new constant. The dimensions of the
- * new constant will match those of the array.
+ * @param elementShape
+ * @param maxNumElements
+ * @param elementDtype
+ * @return a new instance of EmptyTensorList
*/
- public Constant
+ * Raises an error if the input tensor's shape does not match the specified shape.
+ * Returns the input tensor otherwise.
*
- * @param scope is a scope used to add the underlying operation.
- * @param data An array containing the values to put into the new constant. The dimensions of the
- * new constant will match those of the array.
+ * @param
+ * Given a tensor `input`, this operation inserts a dimension of 1 at the
+ * dimension index `axis` of `input`'s shape. The dimension index `axis` starts at
+ * zero; if you specify a negative number for `axis` it is counted backward from
+ * the end.
+ *
+ * This operation is useful if you want to add a batch dimension to a single
+ * element. For example, if you have a single image of shape `[height, width,
+ * channels]`, you can make it a batch of 1 image with `expand_dims(image, 0)`,
+ * which will make the shape `[1, height, width, channels]`.
+ *
+ * Other examples:
+ *
+ * `-1-input.dims() <= dim <= input.dims()`
+ *
+ * This operation is related to `squeeze()`, which removes dimensions of
+ * size 1.
+ *
+ * @param
+ * We specify the size-related attributes as:
+ *
+ * This operation creates a tensor of shape `dims` and fills it with `value`.
+ *
+ * For example:
+ *
+ * @compatibility(numpy) Equivalent to np.full
+ * @end_compatibility
+ * @return a new instance of Fill
*/
- public Constant
+ * Generates fingerprint values of `data`.
+ *
+ * Fingerprint op considers the first dimension of `data` as the batch dimension,
+ * and `output[i]` contains the fingerprint value generated from contents in
+ * `data[i, ...]` for all `i`.
+ *
+ * Fingerprint op writes fingerprint values as byte arrays. For example, the
+ * default method `farmhash64` generates a 64-bit fingerprint value at a time.
+ * This 8-byte value is written out as an `uint8` array of size 8, in little-endian
+ * order.
+ *
+ * For example, suppose that `data` has data type `DT_INT32` and shape (2, 3, 4),
+ * and that the fingerprint method is `farmhash64`. In this case, the output shape
+ * is (2, 8), where 2 is the batch dimension size of `data`, and 8 is the size of
+ * each fingerprint value in bytes. `output[0, :]` is generated from 12 integers in
+ * `data[0, :, :]` and similarly `output[1, :]` is generated from other 12 integers
+ * in `data[1, :, :]`.
+ *
+ * Note that this op fingerprints the raw underlying buffer, and it does not
+ * fingerprint Tensor's metadata such as data type and/or shape. For example, the
+ * fingerprint values are invariant under reshapes and bitcasts as long as the
+ * batch dimension remain the same:
+ *
+ * `indices` must be an integer tensor of any dimension (usually 0-D or 1-D).
+ * Produces an output tensor with shape `params.shape[:axis] + indices.shape +
+ * params.shape[axis + 1:]` where:
+ *
+ * Note that on CPU, if an out of bound index is found, an error is returned.
+ * On GPU, if an out of bound index is found, a 0 is stored in the
+ * corresponding output value.
+ *
+ * See also `tf.batch_gather` and `tf.gather_nd`.
+ *
+ * @param
+ * `indices` is a K-dimensional integer tensor, best thought of as a
+ * (K-1)-dimensional tensor of indices into `params`, where each element defines a
+ * slice of `params`:
+ *
+ * output[\\(i_0, ..., i_{K-2}\\)] = params[indices[\\(i_0, ..., i_{K-2}\\)]]
+ *
+ * Whereas in `tf.gather` `indices` defines slices into the `axis`
+ * dimension of `params`, in `tf.gather_nd`, `indices` defines slices into the
+ * first `N` dimensions of `params`, where `N = indices.shape[-1]`.
+ *
+ * The last dimension of `indices` can be at most the rank of
+ * `params`:
+ *
+ * indices.shape[-1] <= params.rank
+ *
+ * The last dimension of `indices` corresponds to elements
+ * (if `indices.shape[-1] == params.rank`) or slices
+ * (if `indices.shape[-1] < params.rank`) along dimension `indices.shape[-1]`
+ * of `params`. The output tensor has shape
+ *
+ * indices.shape[:-1] + params.shape[indices.shape[-1]:]
+ *
+ * Note that on CPU, if an out of bound index is found, an error is returned.
+ * On GPU, if an out of bound index is found, a 0 is stored in the
+ * corresponding output value.
+ *
+ * Some examples below.
+ *
+ * Simple indexing into a matrix:
+ *
+ * If {@code Options.dx()} values are set, they are as the initial symbolic partial derivatives of some loss
+ * function {@code L} w.r.t. {@code y}. {@code Options.dx()} must have the size of {@code y}.
+ *
+ * If {@code Options.dx()} is not set, the implementation will use dx of {@code OnesLike} for all
+ * shapes in {@code y}.
+ *
+ * The partial derivatives are returned in output {@code dy}, with the size of {@code x}.
+ *
+ * Example of usage:
+ *
+ * The runtime is then free to make optimizations based on this.
+ *
+ * Only accepts value typed tensors as inputs and rejects resource variable handles
+ * as input.
+ *
+ * Returns the input tensor without modification.
*
- * @param scope is a scope used to add the underlying operation.
- * @param data An array containing the values to put into the new constant. The dimensions of the
- * new constant will match those of the array.
+ * @param
+ * This op creates a hash table, specifying the type of its keys and values.
+ * Before using the table you will have to initialize it. After initialization the
+ * table will be immutable.
*
- * @param scope is a scope used to add the underlying operation.
- * @param data An array containing the values to put into the new constant. The dimensions of the
- * new constant will match those of the array.
+ * @param keyDtype Type of the table keys.
+ * @param valueDtype Type of the table values.
+ * @param options carries optional attributes values
+ * @return a new instance of HashTable
*/
- public Constant
+ * Given the tensor `values`, this operation returns a rank 1 histogram counting
+ * the number of entries in `values` that fall into every bin. The bins are
+ * equal width and determined by the arguments `value_range` and `nbins`.
+ *
+ * Given the tensor `values`, this operation returns a rank 1 histogram counting
+ * the number of entries in `values` that fall into every bin. The bins are
+ * equal width and determined by the arguments `value_range` and `nbins`.
+ *
+ * tensors.
+ *
+ * This op can be used to override the gradient for complicated functions. For
+ * example, suppose y = f(x) and we wish to apply a custom function g for backprop
+ * such that dx = g(dy). In Python,
+ *
+ * The current implementation memmaps the tensor from a file.
*
- * @param scope is a scope used to add the underlying operation.
- * @param data The string to put into the new constant.
- * @return a string constant
+ * @param
+ * It inserts one key-value pair into the table for each line of the file.
+ * The key and value is extracted from the whole line content, elements from the
+ * split line based on `delimiter` or the line number (starting from zero).
+ * Where to extract the key and value from a line is specified by `key_index` and
+ * `value_index`.
+ *
+ * - A value of -1 means use the line number(starting from zero), expects `int64`.
+ * - A value of -2 means use the whole line content, expects `string`.
+ * - A value >= 0 means use the index (starting at zero) of the split line based
+ * on `delimiter`.
*
- * @param scope is a scope used to add the underlying operation.
- * @param data An array containing the values to put into the new constant. The dimensions of the
- * new constant will match those of the array.
+ * @param tableHandle Handle to a table which will be initialized.
+ * @param filename Filename of a vocabulary text file.
+ * @param keyIndex Column index in a line to get the table `key` values from.
+ * @param valueIndex Column index that represents information of a line to get the table
+ * `value` values from.
+ * @param options carries optional attributes values
+ * @return a new instance of InitializeTableFromTextFile
*/
- public Constant
+ * Computes y = x; y[i, :] += v; return y.
*
- * @param scope is a scope used to add the underlying operation.
- * @param data An array containing the values to put into the new constant. The dimensions of the
- * new constant will match those of the array.
+ * @param
+ * Computes y = x; y[i, :] -= v; return y.
*
- * @param scope is a scope used to add the underlying operation.
- * @param data The value to put into the new constant.
- * @return a long constant
+ * @param
+ * Computes `x[i, :] = v; return x`.
*
- * @param scope is a scope used to add the underlying operation.
- * @param tensor a Tensor holding the constant value
- * @return a constant of the same data type as `tensor`
+ * @param
+ * Outputs boolean scalar indicating whether the tensor has been initialized.
*
- * @param scope is a scope used to add the underlying operation.
- * @param charset The encoding from String to bytes.
- * @param data The string to put into the new constant.
- * @return a string constant
+ * @param ref Should be from a `Variable` node. May be uninitialized.
+ * @return a new instance of IsVariableInitialized
*/
- public Constant The argument {@code object} is first converted into a Tensor using {@link
- * org.tensorflow.Tensor#create(Object)}, so only Objects supported by this method must be
- * provided. For example:
- *
+ * Generates values in an interval.
+ *
+ * A sequence of `num` evenly-spaced values are generated beginning at `start`.
+ * If `num > 1`, the values in the sequence increase by `stop - start / num - 1`,
+ * so that the last one is exactly `stop`.
+ *
+ * For example:
* Creates a constant with the given shape by copying elements from the buffer (starting from
- * its current position) into the tensor. For example, if {@code shape = {2,3} } (which represents
- * a 2x3 matrix) then the buffer must have 6 elements remaining, which will be consumed by this
- * method.
+ * Outputs all keys and values in the table.
*
- * @param scope is a scope used to add the underlying operation.
- * @param shape the tensor shape.
- * @param data a buffer containing the tensor data.
- * @return a double constant
- * @throws IllegalArgumentException If the tensor shape is not compatible with the buffer
+ * @param Creates a constant with the given shape by copying elements from the buffer (starting from
- * its current position) into the tensor. For example, if {@code shape = {2,3} } (which represents
- * a 2x3 matrix) then the buffer must have 6 elements remaining, which will be consumed by this
- * method.
+ * Looks up keys in a table, outputs the corresponding values.
+ *
+ * The tensor `keys` must of the same type as the keys of the table.
+ * The output `values` is of the type of the table values.
+ *
+ * The scalar `default_value` is the value output for keys not present in the
+ * table. It must also be of the same type as the table values.
*
- * @param scope is a scope used to add the underlying operation.
- * @param shape the tensor shape.
- * @param data a buffer containing the tensor data.
- * @return an integer constant
- * @throws IllegalArgumentException If the tensor shape is not compatible with the buffer
+ * @param data type for {@code values()} output
+ * @param tableHandle Handle to the table.
+ * @param keys Any shape. Keys to look up.
+ * @param defaultValue
+ * @return a new instance of LookupTableFind
*/
- public Constant Creates a constant with the given shape by copying elements from the buffer (starting from
- * its current position) into the tensor. For example, if {@code shape = {2,3} } (which represents
- * a 2x3 matrix) then the buffer must have 6 elements remaining, which will be consumed by this
- * method.
+ * Replaces the contents of the table with the specified keys and values.
+ *
+ * The tensor `keys` must be of the same type as the keys of the table.
+ * The tensor `values` must be of the type of the table values.
*
- * @param scope is a scope used to add the underlying operation.
- * @param shape the tensor shape.
- * @param data a buffer containing the tensor data.
- * @return a long constant
- * @throws IllegalArgumentException If the tensor shape is not compatible with the buffer
+ * @param tableHandle Handle to the table.
+ * @param keys Any shape. Keys to look up.
+ * @param values Values to associate with keys.
+ * @return a new instance of LookupTableImport
*/
- public Constant Creates a constant with the given shape by copying elements from the buffer (starting from
- * its current position) into the tensor. For example, if {@code shape = {2,3} } (which represents
- * a 2x3 matrix) then the buffer must have 6 elements remaining, which will be consumed by this
- * method.
+ * Updates the table to associates keys with values.
+ *
+ * The tensor `keys` must be of the same type as the keys of the table.
+ * The tensor `values` must be of the type of the table values.
*
- * @param scope is a scope used to add the underlying operation.
- * @param shape the tensor shape.
- * @param data a buffer containing the tensor data.
- * @return a float constant
- * @throws IllegalArgumentException If the tensor shape is not compatible with the buffer
+ * @param tableHandle Handle to the table.
+ * @param keys Any shape. Keys to look up.
+ * @param values Values to associate with keys.
+ * @return a new instance of LookupTableInsert
*/
- public Constant{@code
+ * Constant.create(scope, new int[]{{1, 2}, {3, 4}}, TInt32.DTYPE); // returns a 2x2 integer matrix
+ * }
*
* @param scope is a scope used to add the underlying operation.
- * @param data An array containing the values to put into the new constant. String elements are
- * sequences of bytes from the last array dimension.
+ * @param object a Java object representing the constant.
+ * @return a constant of type `type`
+ * @see org.tensorflow.Tensor#create(Object) Tensor.create
+ * @deprecated use {@link Ops#val(Tensor)} instead
*/
- public Constant{@code
+ * outputs[i].shape = [sum(partitions == i)] + data.shape[partitions.ndim:]
+ *
+ * outputs[i] = pack([data[js, ...] for js if partitions[js] == i])
+ * }
+ * `data.shape` must start with `partitions.shape`.
+ * {@code
+ * # Scalar partitions.
+ * partitions = 1
+ * num_partitions = 2
+ * data = [10, 20]
+ * outputs[0] = [] # Empty with shape [0, 2]
+ * outputs[1] = [[10, 20]]
+ *
+ * # Vector partitions.
+ * partitions = [0, 0, 1, 1, 0]
+ * num_partitions = 2
+ * data = [10, 20, 30, 40, 50]
+ * outputs[0] = [10, 20, 50]
+ * outputs[1] = [30, 40]
+ * }
+ * See `dynamic_stitch` for an example on how to merge partitions back.
+ *  + *
+ * {@code
+ * merged[indices[m][i, ..., j], ...] = data[m][i, ..., j, ...]
+ * }
+ * For example, if each `indices[m]` is scalar or vector, we have
+ * {@code
+ * # Scalar indices:
+ * merged[indices[m], ...] = data[m][...]
*
- * @param scope is a scope used to add the underlying operation.
- * @param data An array containing the values to put into the new constant. The dimensions of the
- * new constant will match those of the array.
+ * # Vector indices:
+ * merged[indices[m][i], ...] = data[m][i, ...]
+ * }
+ * Each `data[i].shape` must start with the corresponding `indices[i].shape`,
+ * and the rest of `data[i].shape` must be constant w.r.t. `i`. That is, we
+ * must have `data[i].shape = indices[i].shape + constant`. In terms of this
+ * `constant`, the output shape is
+ * {@code
+ * indices[0] = 6
+ * indices[1] = [4, 1]
+ * indices[2] = [[5, 2], [0, 3]]
+ * data[0] = [61, 62]
+ * data[1] = [[41, 42], [11, 12]]
+ * data[2] = [[[51, 52], [21, 22]], [[1, 2], [31, 32]]]
+ * merged = [[1, 2], [11, 12], [21, 22], [31, 32], [41, 42],
+ * [51, 52], [61, 62]]
+ * }
+ * This method can be used to merge partitions created by `dynamic_partition`
+ * as illustrated on the following example:
+ * {@code
+ * # Apply function (increments x_i) on elements for which a certain condition
+ * # apply (x_i != -1 in this example).
+ * x=tf.constant([0.1, -1., 5.2, 4.3, -1., 7.4])
+ * condition_mask=tf.not_equal(x,tf.constant(-1.))
+ * partitioned_data = tf.dynamic_partition(
+ * x, tf.cast(condition_mask, tf.int32) , 2)
+ * partitioned_data[1] = partitioned_data[1] + 1.0
+ * condition_indices = tf.dynamic_partition(
+ * tf.range(tf.shape(x)[0]), tf.cast(condition_mask, tf.int32) , 2)
+ * x = tf.dynamic_stitch(condition_indices, partitioned_data)
+ * # Here x=[1.1, -1., 6.2, 5.3, -1, 8.4], the -1. values remain
+ * # unchanged.
+ * }
+ *  + *
+ * {@code
+ * # 't' is a tensor of shape [2]
+ * shape(expand_dims(t, 0)) ==> [1, 2]
+ * shape(expand_dims(t, 1)) ==> [2, 1]
+ * shape(expand_dims(t, -1)) ==> [2, 1]
*
- * @param scope is a scope used to add the underlying operation.
- * @param data An array containing the values to put into the new constant. String elements are
- * sequences of bytes from the last array dimension.
+ * # 't2' is a tensor of shape [2, 3, 5]
+ * shape(expand_dims(t2, 0)) ==> [1, 2, 3, 5]
+ * shape(expand_dims(t2, 2)) ==> [2, 3, 1, 5]
+ * shape(expand_dims(t2, 3)) ==> [2, 3, 5, 1]
+ * }
+ * This operation requires that:
+ * {@code
+ * ksizes = [1, ksize_planes, ksize_rows, ksize_cols, 1]
+ * strides = [1, stride_planes, strides_rows, strides_cols, 1]
+ * }
+ * @return a new instance of ExtractVolumePatches
*/
- public Constant{@code
+ * # Output tensor has shape [2, 3].
+ * fill([2, 3], 9) ==> [[9, 9, 9]
+ * [9, 9, 9]]
+ * }
+ * `tf.fill` differs from `tf.constant` in a few ways:
+ *
+ *
{@code
+ * Fingerprint(data) == Fingerprint(Reshape(data, ...))
+ * Fingerprint(data) == Fingerprint(Bitcast(data, ...))
+ * }
+ * For string data, one should expect `Fingerprint(data) !=
+ * Fingerprint(ReduceJoin(data))` in general.
*
- * @param scope is a scope used to add the underlying operation.
- * @param data An array containing the values to put into the new constant. The dimensions of the
- * new constant will match those of the array.
+ * @param data Must have rank 1 or higher.
+ * @param method Fingerprint method used by this op. Currently available method is
+ * `farmhash::fingerprint64`.
+ * @return a new instance of Fingerprint
*/
- public Constant{@code
+ * # Scalar indices (output is rank(params) - 1).
+ * output[a_0, ..., a_n, b_0, ..., b_n] =
+ * params[a_0, ..., a_n, indices, b_0, ..., b_n]
*
- * @param scope is a scope used to add the underlying operation.
- * @param data An array containing the values to put into the new constant. The dimensions of the
- * new constant will match those of the array.
+ * # Vector indices (output is rank(params)).
+ * output[a_0, ..., a_n, i, b_0, ..., b_n] =
+ * params[a_0, ..., a_n, indices[i], b_0, ..., b_n]
+ *
+ * # Higher rank indices (output is rank(params) + rank(indices) - 1).
+ * output[a_0, ..., a_n, i, ..., j, b_0, ... b_n] =
+ * params[a_0, ..., a_n, indices[i, ..., j], b_0, ..., b_n]
+ * }
+ *  + *
+ * {@code
+ * indices = [[0, 0], [1, 1]]
+ * params = [['a', 'b'], ['c', 'd']]
+ * output = ['a', 'd']
+ * }
+ * Slice indexing into a matrix:
+ * {@code
+ * indices = [[1], [0]]
+ * params = [['a', 'b'], ['c', 'd']]
+ * output = [['c', 'd'], ['a', 'b']]
+ * }
+ * Indexing into a 3-tensor:
+ * {@code
+ * indices = [[1]]
+ * params = [[['a0', 'b0'], ['c0', 'd0']],
+ * [['a1', 'b1'], ['c1', 'd1']]]
+ * output = [[['a1', 'b1'], ['c1', 'd1']]]
*
- * @param scope is a scope used to add the underlying operation.
- * @param data An array containing the values to put into the new constant. The dimensions of the
- * new constant will match those of the array.
+ *
+ * indices = [[0, 1], [1, 0]]
+ * params = [[['a0', 'b0'], ['c0', 'd0']],
+ * [['a1', 'b1'], ['c1', 'd1']]]
+ * output = [['c0', 'd0'], ['a1', 'b1']]
+ *
+ *
+ * indices = [[0, 0, 1], [1, 0, 1]]
+ * params = [[['a0', 'b0'], ['c0', 'd0']],
+ * [['a1', 'b1'], ['c1', 'd1']]]
+ * output = ['b0', 'b1']
+ * }
+ * Batched indexing into a matrix:
+ * {@code
+ * indices = [[[0, 0]], [[0, 1]]]
+ * params = [['a', 'b'], ['c', 'd']]
+ * output = [['a'], ['b']]
+ * }
+ * Batched slice indexing into a matrix:
+ * {@code
+ * indices = [[[1]], [[0]]]
+ * params = [['a', 'b'], ['c', 'd']]
+ * output = [[['c', 'd']], [['a', 'b']]]
+ * }
+ * Batched indexing into a 3-tensor:
+ * {@code
+ * indices = [[[1]], [[0]]]
+ * params = [[['a0', 'b0'], ['c0', 'd0']],
+ * [['a1', 'b1'], ['c1', 'd1']]]
+ * output = [[[['a1', 'b1'], ['c1', 'd1']]],
+ * [[['a0', 'b0'], ['c0', 'd0']]]]
+ *
+ * indices = [[[0, 1], [1, 0]], [[0, 0], [1, 1]]]
+ * params = [[['a0', 'b0'], ['c0', 'd0']],
+ * [['a1', 'b1'], ['c1', 'd1']]]
+ * output = [[['c0', 'd0'], ['a1', 'b1']],
+ * [['a0', 'b0'], ['c1', 'd1']]]
+ *
+ *
+ * indices = [[[0, 0, 1], [1, 0, 1]], [[0, 1, 1], [1, 1, 0]]]
+ * params = [[['a0', 'b0'], ['c0', 'd0']],
+ * [['a1', 'b1'], ['c1', 'd1']]]
+ * output = [['b0', 'b1'], ['d0', 'c1']]
+ * }
+ * See also `tf.gather` and `tf.batch_gather`.
+ *
+ * @param {@code
+ * Gradients gradients = tf.gradients(loss, Arrays.asList(w, b));
+ * Scalar
*
- * @param scope is a scope used to add the underlying operation.
- * @param data The value to put into the new constant.
- * @return a float constant
+ * @param y output of the function to derive
+ * @param x inputs of the function for which partial derivatives are computed
+ * @param options carries optional attributes values
+ * @return a new instance of {@code Gradients}
+ * @throws IllegalArgumentException if execution environment is not a graph
*/
- public Constant{@code
+ * # Bins will be: (-inf, 1), [1, 2), [2, 3), [3, 4), [4, inf)
+ * nbins = 5
+ * value_range = [0.0, 5.0]
+ * new_values = [-1.0, 0.0, 1.5, 2.0, 5.0, 15]
*
- * @param scope is a scope used to add the underlying operation.
- * @param data The value to put into the new constant.
- * @return a double constant
+ * with tf.get_default_session() as sess:
+ * hist = tf.histogram_fixed_width(new_values, value_range, nbins=5)
+ * variables.global_variables_initializer().run()
+ * sess.run(hist) => [2, 1, 1, 0, 2]
+ * }
+ *
+ * @param data type for {@code out()} output
+ * @param values Numeric `Tensor`.
+ * @param valueRange Shape [2] `Tensor` of same `dtype` as `values`.
+ * values <= value_range[0] will be mapped to hist[0],
+ * values >= value_range[1] will be mapped to hist[-1].
+ * @param nbins Scalar `int32 Tensor`. Number of histogram bins.
+ * @return a new instance of HistogramFixedWidth
*/
- public Constant{@code
+ * # Bins will be: (-inf, 1), [1, 2), [2, 3), [3, 4), [4, inf)
+ * nbins = 5
+ * value_range = [0.0, 5.0]
+ * new_values = [-1.0, 0.0, 1.5, 2.0, 5.0, 15]
*
- * @param scope is a scope used to add the underlying operation.
- * @param data An array containing the values to put into the new constant. The dimensions of the
- * new constant will match those of the array.
+ * with tf.get_default_session() as sess:
+ * hist = tf.histogram_fixed_width(new_values, value_range, nbins=5)
+ * variables.global_variables_initializer().run()
+ * sess.run(hist) => [2, 1, 1, 0, 2]
+ * }
+ *
+ * @param data type for {@code out()} output
+ * @param values Numeric `Tensor`.
+ * @param valueRange Shape [2] `Tensor` of same `dtype` as `values`.
+ * values <= value_range[0] will be mapped to hist[0],
+ * values >= value_range[1] will be mapped to hist[-1].
+ * @param nbins Scalar `int32 Tensor`. Number of histogram bins.
+ * @param dtype
+ * @return a new instance of HistogramFixedWidth
*/
- public Constant{@code
+ * with tf.get_default_graph().gradient_override_map(
+ * {'IdentityN': 'OverrideGradientWithG'}):
+ * y, _ = identity_n([f(x), x])
*
- * @param scope is a scope used to add the underlying operation.
- * @param data An array containing the values to put into the new constant. The dimensions of the
- * new constant will match those of the array.
+ * @tf.RegisterGradient('OverrideGradientWithG') def ApplyG(op, dy, _):
+ * return [None, g(dy)] # Do not backprop to f(x).
+ * }
+ * @param input
+ * @return a new instance of IdentityN
*/
- public Constant{@code
- * Constant.create(scope, new int[]{{1, 2}, {3, 4}}, TInt32.DTYPE); // returns a 2x2 integer matrix
+ * tf.linspace(10.0, 12.0, 3, name="linspace") => [ 10.0 11.0 12.0]
* }
*
- * @param scope is a scope used to add the underlying operation.
- * @param object a Java object representing the constant.
- * @return a constant of type `type`
- * @see org.tensorflow.Tensor#create(Object) Tensor.create
+ * @param