This folder provides more information on various experiments conducted using the pipeline. Furthermore, we provide here more detailed information regarding the PubMed queries such as their distribution, their click-through rates, etc. We also evaluated different algorithms for the first layer setup besides BM25 and we report the results of these experiments.
Our choice of using BM25 is based on its performance. We conducted additional experiments with consistent results found in the past studies (e.g. Managing Gigabytes: Compressing and Indexing Documents and Images by Witten I, Moffat A, and Bell TC. 1999). We show below our experiments using Divergence from Randomness (DFR) (Amati et al. 2002) instead of BM25 for the first layer document ranking. As can be seen, given the very high number of results we fetch for re-ranking (500), there is not much difference between this approach and BM25. We also studied how to combine results of DFR and BM25, following the COMBSUM strategy suggested in (Fox and Shaw, 1994). All results are displayed in the table below.
| Evaluation | BM25 | DfR - I(ne)L2 | BM25 & DfR (using the COMBSUM junction) |
|---|---|---|---|
| Precision@500 | 0.037 | 0.037 | 0.036 |
| Recall@500 | 0.445 | 0.447 | 0.444 |
| NDCG@20 | 0.151 | 0.151 | 0.151 |
| NDCG@20 after L2R | 0.483 | 0.483 | 0.481 |
As shown, the real performance gain lies in the addition of the second stage re-ranking by L2R: The ranking quality of the top 20 results, measured by NDCG scores, improves dramatically by a factor of 3.
We provide in this section further information regarding the queries. Particularly, we focus on their popularity distribution, the CTR associated to this distribution, the NDCG distributions and the improvement or deterioration brought by L2R.
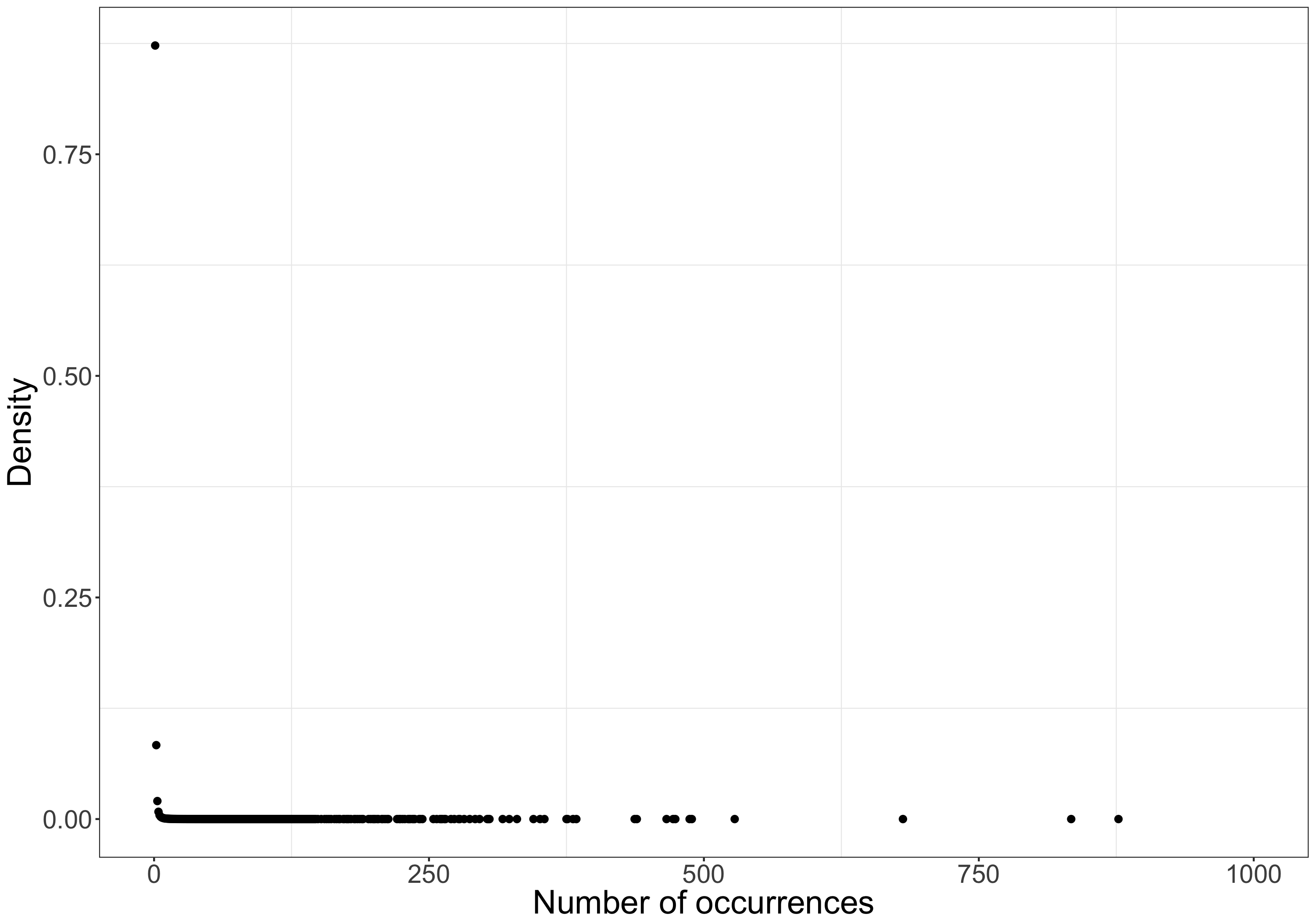
Although some PubMed queries are very popular, they only represent a very small fraction of total queries. The figures below depict the volume of queries in PubMed based on how many times they occur in a year, with a focus on queries occurring one to ten times. As can be seen, 87.3% of queries are unique in PubMed, and 98.8% of queries occur less than 10 times in a year.

The set of 46,000 queries we used for training contains unique queries only (i.e. duplicates are merged). The figures below depict the average CTR@20 scores observed with respect to different query popularities. As shown, the increase in CTR is applicable to a wide variety of different queries. That is, both popular and infrequent queries benefit from the new Best Match algorithm. For instance, over 87% of PubMed queries are unique and they have an average CTR@20 of 0.407.


The histogram below shows the NDCG distribution for the test dataset, which consists of 13,800 unique queries in total. As shown, results by BM25 yields a skewed distribution (with many queries close to NDCG@20=0). By contrast, L2R output provides a more homogeneous distribution which explains its overall improved ranking quality.

The density curve below shows the proportion of queries in the test set for which the results deteriorated after adding L2R (below 0) and the proportion for which the results improved after L2R's addition. As can be seen, the area under the curve is significantly higher in the improvement side (on the right). As a matter of fact, over 86% of queries are with improved NDCG scores after re-ranked by L2R.
