Apriori算法一种挖掘关联规则频繁项集的算法,利用了Apriori性质:频繁项集的所有非空子集也必须是频繁的
- A∪B不可能比A更频繁的出现
- 反单调性:一个集合如果不能通过测试,则该集合的所有超集也不能通过相同的测试
- 通过减少搜索空间,来提高频繁项集产生的效率

这里用一个例子来说明一下(example.csv):
| TID | transation |
|---|---|
| 0 | {1,3,4} |
| 1 | {2,3,5} |
| 2 | {1,2,3,5} |
| 3 | {2,5} |
TID可以理解为序号,没有实际意义,仅用于区分的唯一标识符transation是交易,表示购买了哪几种东西,其中的数字1 2 5只是一个标志符,用来代表一种物品,相当于有一个大的序列表保存所有物品{1:paper, 2:book, 3:computer ...}然后使用一个标识符1表示该序列表第一项paper
Apriori的算法流程:
-
首先寻找频繁一项集
统计各个物品出现的次数(连接):
itemset sup(support) {1} 2 {2} 3 {3} 3 {4} 1 {5} 3 支持度(support)用于剪枝阶段,所有 sup 数量小于n * support的被去掉,大于等于的保留下来作为频繁一项集,其中 n 为 TID 总数量, support 通常是一个百分数, 我们已support = 50 %为例, 也就是所有 sup 小于 4*0.5=2 的去掉,所以最后得到的频繁一项集为itemset sup(support) {1} 2 {2} 3 {3} 3 {5} 3 -
接下来计算频繁二项集,因为已经计算出了频繁一项集,只需要组合其中的元素,查找原表中是否同一行中两项都在,统计个数
itemset sup(support) {1,2} 1 {1,3} 2 {1,5} 1 {2,3} 2 {2,5} 3 {3,5} 2 1 2 3 5排列组合得到六种情况,分别查找,统计数量,然后不足2的去掉itemset sup(support) {1,3} 2 {2,3} 2 {2,5} 3 {3,5} 2 这样就得到了频繁二项集
-
同理,排列组合频繁二项集中的元素,查找,剪枝生成频繁三项集
itemset sup(support) {2,3,5} 2 -
现在得到了频繁三项集,这时我们去寻找频繁四项集,但是找不到存在的项,故递归结束
这里值得强调的是,并不是说最后剩下一个就是结束了不再往下找了.也不是说最后结果只能是一个.
递归结束的条件是不能再找到满足条件的频繁 N 项集,最后的结果频繁 N-1 项集可以有多个结果
-
最后得到的所有频繁项集为
-
频繁一项集
itemset sup(support) {1} 2 {2} 3 {3} 3 {5} 3 -
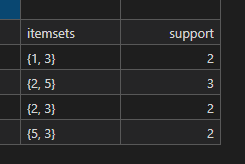
频繁二项集
itemset sup(support) {1,3} 2 {2,3} 2 {2,5} 3 {3,5} 2 -
频繁三项集
itemset sup(support) {2,3,5} 2
-
-
什么是最大频繁项集呢?
频繁 N 项集中的元素不在频繁 N+1 项集中出现的,就属于最大频繁 N 项集
比如本题,频繁一项集中元素为
{1} {2} {3} {5},频繁二项集中的元素为{1,3},{2,3},{2,5},{3,5},1,2,3,5所有元素都在频繁二项集中出现了,所以没有最大频繁一项集如果说频繁一项集中还有一个
{6},并且频繁二项集中的组合没有包含{x,6}这种的,那么{6}就是最大频繁一项集频繁二项集中,
{1,3}中的1没有在频散三项集中出现,所以{1,3}为最大频繁二项集不存在频繁四项集,所以频繁三项集中的所有项都属于最大频繁三项集
-
强关联规则? 置信度/可信度(confidence)是什么意思呢?
强关联规则顾名思义就是物品之间具有很强的关联性,也就是例子中的 尿布与啤酒 经常一起出现,表示很有可能他们两个的关联性很高,表示包含 A 的同时也包含 B 的概率.
从频繁二项集开始,因为一项集只有一项没有关联性的概念
-
频繁二项集
itemset sup(support) {1,3} 2 {2,3} 2 {2,5} 3 {3,5} 2 对于第一行,也就是说我们需要考虑
{1,3}之间的关联性如何,存在两种关联方式1->3和3->1,已知一个存在,另一个是否存在.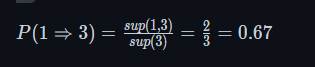
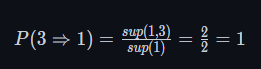
如果最后结果大于置信度/可信度那么我们认为他们具有强关联,现在又
1->3的强关联规则但是没有3->1对于频繁三项集也是同理
{2,3,5}不过是规则多了点,可以分为{2,3}->{5},{2,5}->3....,套用公式,下方的sup(2,3,5)相同都是2,只需要每次去频繁二项集中查找数据带入计算即可,最后于置信度比较即可得到强关联规则
-
cd homework-2/Apriori
python Apriori.pyarguments:
-
-d(optional):默认使用README中示例的数据,但是我感觉这个数据量太小了没啥意思,于是我去搜索了下apriori算法的数据集,结果没有找到标准数据集,好像都是自定义数据或者爬下来的数据,也没有一个benchmark之类的数据集,感觉很怪?
经过查找我找到了一篇论文讨论了不同数据集对于算法的影响,不过他也没有采用标准数据集而是使用了程序生成不同情况的数据集
浏览Github又找到了一个相对正规的项目,但是他的 CSV 文件数据不对齐,有点差,我不太喜欢
最后选择了另一个Github项目使用的数据集,不过这个一言难尽吧...,数据还是可以用的,我将其保存在dataset.csv,使用参数调用该数据集
python Apriori.py -d
-
-s: min_support -
-c: min_confidence
-
使用 example.txt 中的数据得到结果保存为
example.xlsx(运行程序自动生成)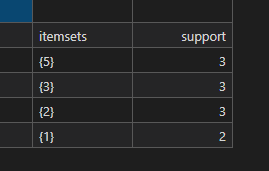

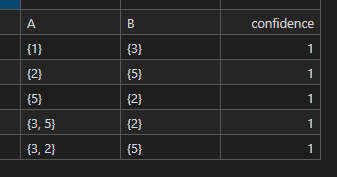
-
使用 dataset.txt 中的数据得到结果保存为
dataset.xlsx(运行程序自动生成)数据较多截图不便,可直接浏览 dataset.xlsx