The repo contains source codes for ACL 2023 Findings paper DiffuSum: Generation Enhanced Extractive Summarization with Diffusion
https://arxiv.org/abs/2305.01735
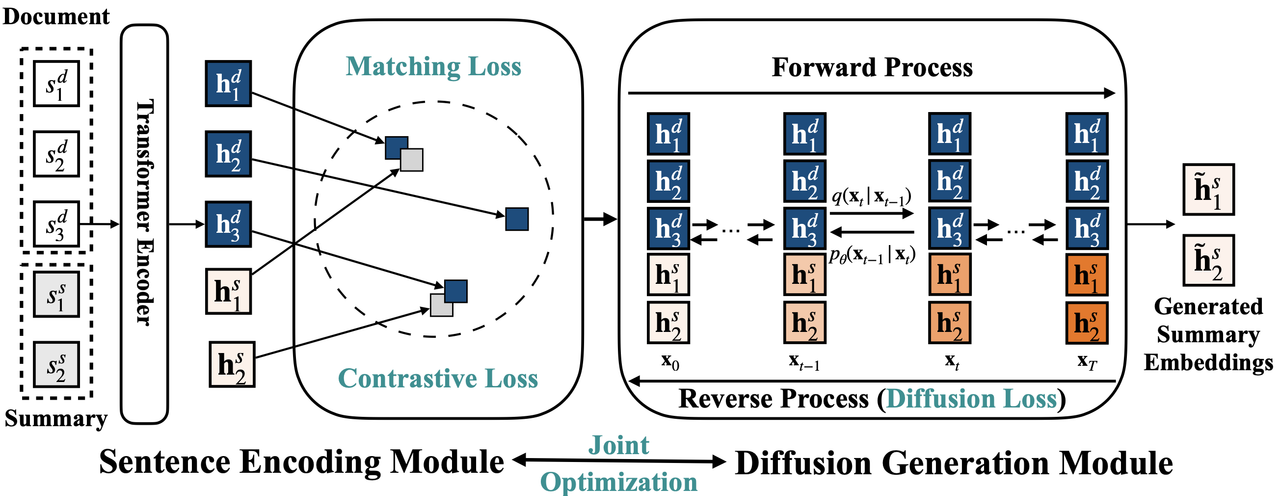
Extractive summarization aims to form a summary by directly extracting sentences from the source document. Existing works mostly formulate it as a sequence labeling problem by making individual sentence label predictions. This paper proposes DiffuSum, a novel paradigm for extractive summarization, by directly generating the desired summary sentence representations with diffusion models and extracting sentences based on sentence representation matching. In addition, DiffuSum jointly optimizes a contrastive sentence encoder with a matching loss for sentence representation alignment and a multi-class contrastive loss for representation diversity. Experimental results show that DiffuSum achieves the new state-of-the-art extractive results on CNN/DailyMail with ROUGE scores of
We reuse some codes from:
Li, Xiang Lisa, et al. "Diffusion-LM Improves Controllable Text Generation.".
and
Khosla, Prannay, et al. "Supervised contrastive learning."
conda create --name [envname] python=3.8
pip install -r requirements.txtWe reuse the preprocessed data from MatchSum repo: https://github.com/maszhongming/MatchSum . Please download the data and put it in the corresponeding directories.
# train on CNN/DM
python run_train_sum.py --diff_steps 500 --model_arch transformer_sum --lr 1e-5 --seed 101 --noise_schedule sqrt --in_channel 128 --modality roc --submit no --padding_mode pad --app "--predict_xstart True --training_mode e2e --roc_train cnn_ext " --notes cnn --bsz 64 --epochs 10
# train on PubMed
python run_train_sum.py --diff_steps 500 --model_arch transformer_sum --lr 1e-5 --seed 101 --noise_schedule sqrt --in_channel 128 --modality roc --submit no --padding_mode pad --app "--predict_xstart True --training_mode e2e --roc_train pubmed " --notes pubmed --bsz 64 --epochs 10
# train on XSum
python run_train_sum.py --diff_steps 500 --model_arch transformer_sum --lr 1e-5 --seed 101 --noise_schedule sqrt --in_channel 128 --modality roc --submit no --padding_mode pad --app "--predict_xstart True --training_mode e2e --roc_train xsum " --notes xsum --bsz 64 --epochs 10
python batch_decode_sum.py [checkpoint_path] -1.0 ema@article{Zhang2023DiffuSumGE,
title={DiffuSum: Generation Enhanced Extractive Summarization with Diffusion},
author={Haopeng Zhang and Xiao Liu and Jiawei Zhang},
journal={ArXiv},
year={2023},
volume={abs/2305.01735}
}