In the previous section, we've seen how to load and preprocess data in ML.NET. In this section, we'll continue working on our Github issue classifier by training the model.
We'll cover the following topics:
- Adding a trainer to the machine learning pipeline
- Training a model
Let's start extending the machine learning pipeline from the previous section with a trainer.
Remember that in the previous section, we had created a new machine learning pipeline with preprocessing steps. Now it's time to extend the pipeline with a trainer for a classification model.
Open up the Program.cs file from the Trainer project and add the following
code to the end of the Main method:
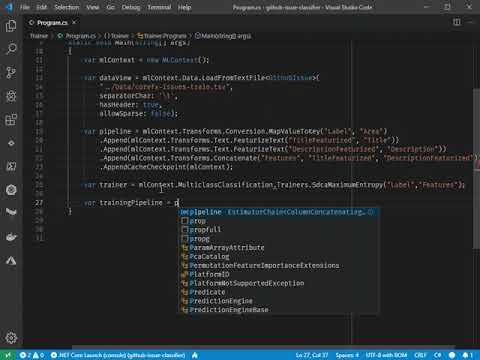
var trainer = mlContext.MulticlassClassification.Trainers.SdcaMaximumEntropy("Label", "Features");
var trainingPipeline = pipeline.Append(trainer).Append(
mlContext.Transforms.Conversion.MapKeyToValue("PredictedLabel"));The code does the following:
- Create a new trainer that uses the SDCA algorithm with maximum entropy to create a multi-class classification model.
- Append the trainer to the pipeline and add a mapping for the predicted label so we can access it in the output.
Now that we have a training pipeline let's run it and train a model.
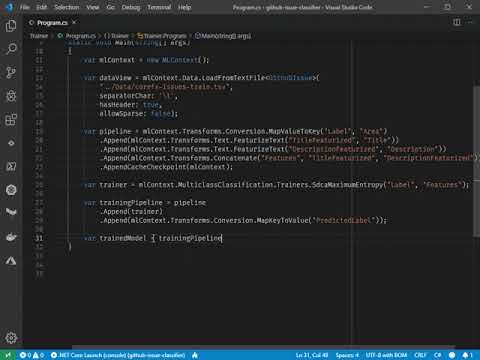
Now that we have a training pipeline, let's feed it some data to train the
model. Add the following code to the end of the Main method in the
Program.cs file:
var trainedModel = trainingPipeline.Fit(dataView);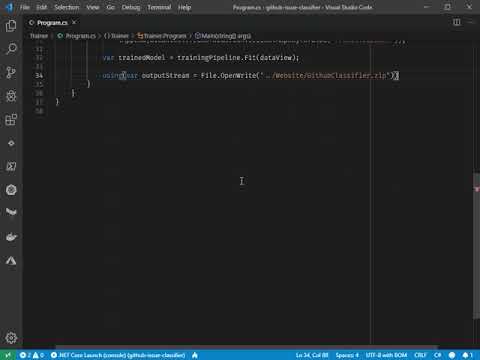
The code invokes the fit method on the pipeline using the data view we created earlier. The output of the method is a trained model that we can store on disk using the following code:
using (var outputStream = File.OpenWrite("../Website/GithubClassifier.zip"))
{
mlContext.Model.Save(trainedModel, dataView.Schema, outputStream);
}This code performs the following steps:
- We open a new stream to the GithubClassifier.zip file in the website project.
- Next, we're saving the model with the right schema to the output stream.
When you run the application, you'll notice that it generates a
GithubClassifier.zip file in the website project. This file contains the
trained model, including schema metadata.
In a later section, we'll use the model in the ASP.NET Core website project.
In this section of the tutorial, we've worked on getting a training pipeline. Once we had a training pipeline, we used it to train a model and save it to disk.
In the next section, we'll expand the code a little bit to include validation logic to test whether the model is working correctly.