Hadoop input format for (possibly gzipped) logfiles with multiline log statements.
This document consists of the following sections:
- Process and motivation
- Usage
- The sample program
- Tests
This library was developed in the context of an Apache Spark program written in Java. Therefore, all examples are in Spark/Java and the lib is only tested in this context. As the input format is a general Hadoop/HDFS concept, feel free to try it in other contexts. Feedback is appreciated.
If you have logfiles where single log records may consist of multiple lines, the built-in input formats of Hadoop cannot help you to process these files as they read line by line. Due to parallelization you will most probably not end up with complete log records. What you need is this:
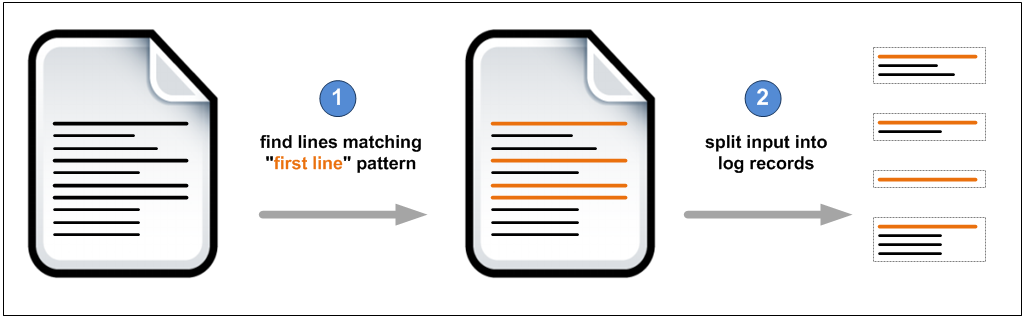
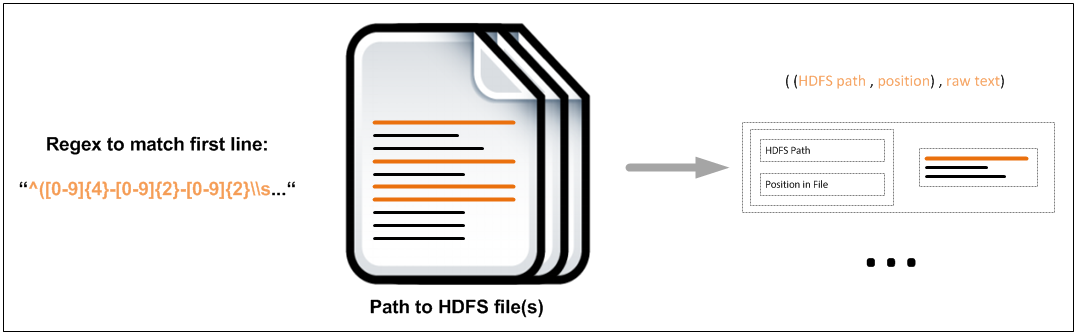
The input format must be provided with a regex to match the first line of each record. It can be applied on an HDFS path that may refer to multiple files. The data it produces (as a RDD for example) consists of pairs that contain:
- a pair of HDFS path and position where the log record was found
- the raw text of the log record
The following image shows in- and output:
The following snippet of code demonstrates the usage of the input format. For further exploration, please read the well documented source of Test and Sample (see following sections).
// create Hadoop configuration (if not received from caller or the like...)
final Configuration hadoopConfig = new Configuration(true);
// However you receive these in your environment ...
final SparkConf sparkConfig = ...
final JavaSparkContext sparkContext = ....
// Java regex pattern
final Pattern pattern = ...
// This static helper method puts the given pattern into the context
// for the input format to access it.
// If you like to use different patterns for different HDFS paths, please
// see the overloaded version of setPattern() in the source code.
LogfileInputFormat.setPattern(hadoopConfig, pattern);
// Create pair RDD using the input format
// params:
// 1) Path(s) as String
// 2) class of input format
// 3) class of key (provided as constant, the value is a really weird expression, have a look ;-)
// 4) class of value (build-in Hadoop class)
// 5) Hadoop config (see above)
JavaPairRDD<Tuple2<Path, Long>, Text> rdd = sparkContext.newAPIHadoopFile(
inputPath.toString(),
LogfileInputFormat.class,
LogfileInputFormat.KEY_CLASS,
Text.class,
hadoopConfig);
// The RDD can now be processed further as usual in Spark...
The sample program de.comdirect.hadoop.logfile.inputformat.cli.Sample is an Apache Spark driver that can be used in your Hadoop cluster. It acts as an example you can study to understand the usage of the input format.
This driver program uses the input format to draw a sample and save it in a new file in HDFS
The program describes its params itself:
usage: de.comdirect.hadoop.logfile.inputformat.cli.Sample
-i,--inputPath <arg> HDFS input path(s)
-o,--outputPath <arg> HDFS output path(s)
-p,--pattern <arg> regex pattern that defines the first line of a log record
-s,--sampleFraction <arg> expected size of the sample as a fraction of total # of records (defaults to 0.01 = 1 percent) [0.0 .. 1.0]
As the author is not capable of (or too lazy) writing JUnit tests which start Hadoop clusters instantly, the lib comes with a test program that can be run on a Hadoop cluster after the packaging.
usage: de.comdirect.hadoop.logfile.inputformat.cli.Test
-d,--directory <arg> HDFS directory where the temporary files are stored. Directory has to be empty respectively gets created by this test.
The program does the following
- Creates 10 logfiles containing a total of 172,800,000 log entries of different levels (INFO, WARN, ERROR)
- Creates logfiles with exactly the same entries as *.gz files.
- Reads the raw logfiles with the LogfileInputFormat and counts total number and numbers grouped by log level
- Reads the gzipped logfiles with the LogfileInputFormat and counts total number and numbers grouped by log level
- Compares expected values with each of the reads and prints out summary.
Warning! The Spark driver uses about 20G (piece of cake for a real cluster, but mayby annoyingly large for dev environment) net HDFS space and may take a while to complete.