diff --git a/.gitignore b/.gitignore
new file mode 100644
index 00000000..320ad2af
--- /dev/null
+++ b/.gitignore
@@ -0,0 +1,123 @@
+# Byte-compiled / optimized / DLL files
+__pycache__/
+*.py[cod]
+*$py.class
+
+# C extensions
+*.so
+
+# Distribution / packaging
+.Python
+build/
+develop-eggs/
+dist/
+downloads/
+eggs/
+.eggs/
+lib/
+lib64/
+parts/
+sdist/
+var/
+wheels/
+*.egg-info/
+.installed.cfg
+*.egg
+MANIFEST
+
+# PyInstaller
+# Usually these files are written by a python script from a template
+# before PyInstaller builds the exe, so as to inject date/other infos into it.
+*.manifest
+*.spec
+
+# Installer logs
+pip-log.txt
+pip-delete-this-directory.txt
+
+# Unit test / coverage reports
+htmlcov/
+.tox/
+.coverage
+.coverage.*
+.cache
+nosetests.xml
+coverage.xml
+*.cover
+.hypothesis/
+.pytest_cache/
+
+# Translations
+*.mo
+*.pot
+
+# Django stuff:
+*.log
+local_settings.py
+db.sqlite3
+
+# Flask stuff:
+instance/
+.webassets-cache
+
+# Scrapy stuff:
+.scrapy
+
+# Sphinx documentation
+docs/en/_build/
+docs/zh_cn/_build/
+
+# PyBuilder
+target/
+
+# Jupyter Notebook
+.ipynb_checkpoints
+
+# pyenv
+.python-version
+
+# celery beat schedule file
+celerybeat-schedule
+
+# SageMath parsed files
+*.sage.py
+
+# Environments
+.env
+.venv
+env/
+venv/
+ENV/
+env.bak/
+venv.bak/
+
+# Spyder project settings
+.spyderproject
+.spyproject
+
+# Rope project settings
+.ropeproject
+
+# mkdocs documentation
+/site
+
+# mypy
+.mypy_cache/
+
+data/
+data
+.vscode
+.idea
+.DS_Store
+
+# custom
+*.pkl
+*.pkl.json
+*.log.json
+docs/modelzoo_statistics.md
+work_dirs/
+
+# Pytorch
+*.pth
+*.py~
+*.sh~
diff --git a/.pre-commit-config.yaml b/.pre-commit-config.yaml
index 5fb9225a..44a13a9e 100644
--- a/.pre-commit-config.yaml
+++ b/.pre-commit-config.yaml
@@ -1,6 +1,6 @@
repos:
- repo: https://gitlab.com/pycqa/flake8.git
- rev: 3.7.9
+ rev: 3.8.3
hooks:
- id: flake8
- repo: https://github.com/asottile/seed-isort-config
diff --git a/configs/mmdet/_base_/datasets/cityscapes_detection.py b/configs/mmdet/_base_/datasets/cityscapes_detection.py
new file mode 100644
index 00000000..e341b59d
--- /dev/null
+++ b/configs/mmdet/_base_/datasets/cityscapes_detection.py
@@ -0,0 +1,56 @@
+# dataset settings
+dataset_type = 'CityscapesDataset'
+data_root = 'data/cityscapes/'
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations', with_bbox=True),
+ dict(
+ type='Resize', img_scale=[(2048, 800), (2048, 1024)], keep_ratio=True),
+ dict(type='RandomFlip', flip_ratio=0.5),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size_divisor=32),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']),
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(2048, 1024),
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size_divisor=32),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img']),
+ ])
+]
+data = dict(
+ samples_per_gpu=1,
+ workers_per_gpu=2,
+ train=dict(
+ type='RepeatDataset',
+ times=8,
+ dataset=dict(
+ type=dataset_type,
+ ann_file=data_root +
+ 'annotations/instancesonly_filtered_gtFine_train.json',
+ img_prefix=data_root + 'leftImg8bit/train/',
+ pipeline=train_pipeline)),
+ val=dict(
+ type=dataset_type,
+ ann_file=data_root +
+ 'annotations/instancesonly_filtered_gtFine_val.json',
+ img_prefix=data_root + 'leftImg8bit/val/',
+ pipeline=test_pipeline),
+ test=dict(
+ type=dataset_type,
+ ann_file=data_root +
+ 'annotations/instancesonly_filtered_gtFine_test.json',
+ img_prefix=data_root + 'leftImg8bit/test/',
+ pipeline=test_pipeline))
+evaluation = dict(interval=1, metric='bbox')
diff --git a/configs/mmdet/_base_/datasets/cityscapes_instance.py b/configs/mmdet/_base_/datasets/cityscapes_instance.py
new file mode 100644
index 00000000..4e3c34e2
--- /dev/null
+++ b/configs/mmdet/_base_/datasets/cityscapes_instance.py
@@ -0,0 +1,56 @@
+# dataset settings
+dataset_type = 'CityscapesDataset'
+data_root = 'data/cityscapes/'
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations', with_bbox=True, with_mask=True),
+ dict(
+ type='Resize', img_scale=[(2048, 800), (2048, 1024)], keep_ratio=True),
+ dict(type='RandomFlip', flip_ratio=0.5),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size_divisor=32),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels', 'gt_masks']),
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(2048, 1024),
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size_divisor=32),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img']),
+ ])
+]
+data = dict(
+ samples_per_gpu=1,
+ workers_per_gpu=2,
+ train=dict(
+ type='RepeatDataset',
+ times=8,
+ dataset=dict(
+ type=dataset_type,
+ ann_file=data_root +
+ 'annotations/instancesonly_filtered_gtFine_train.json',
+ img_prefix=data_root + 'leftImg8bit/train/',
+ pipeline=train_pipeline)),
+ val=dict(
+ type=dataset_type,
+ ann_file=data_root +
+ 'annotations/instancesonly_filtered_gtFine_val.json',
+ img_prefix=data_root + 'leftImg8bit/val/',
+ pipeline=test_pipeline),
+ test=dict(
+ type=dataset_type,
+ ann_file=data_root +
+ 'annotations/instancesonly_filtered_gtFine_test.json',
+ img_prefix=data_root + 'leftImg8bit/test/',
+ pipeline=test_pipeline))
+evaluation = dict(metric=['bbox', 'segm'])
diff --git a/configs/mmdet/_base_/datasets/coco_detection.py b/configs/mmdet/_base_/datasets/coco_detection.py
new file mode 100644
index 00000000..149f590b
--- /dev/null
+++ b/configs/mmdet/_base_/datasets/coco_detection.py
@@ -0,0 +1,49 @@
+# dataset settings
+dataset_type = 'CocoDataset'
+data_root = 'data/coco/'
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations', with_bbox=True),
+ dict(type='Resize', img_scale=(1333, 800), keep_ratio=True),
+ dict(type='RandomFlip', flip_ratio=0.5),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size_divisor=32),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']),
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(1333, 800),
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size_divisor=32),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img']),
+ ])
+]
+data = dict(
+ samples_per_gpu=2,
+ workers_per_gpu=2,
+ train=dict(
+ type=dataset_type,
+ ann_file=data_root + 'annotations/instances_train2017.json',
+ img_prefix=data_root + 'train2017/',
+ pipeline=train_pipeline),
+ val=dict(
+ type=dataset_type,
+ ann_file=data_root + 'annotations/instances_val2017.json',
+ img_prefix=data_root + 'val2017/',
+ pipeline=test_pipeline),
+ test=dict(
+ type=dataset_type,
+ ann_file=data_root + 'annotations/instances_val2017.json',
+ img_prefix=data_root + 'val2017/',
+ pipeline=test_pipeline))
+evaluation = dict(interval=1, metric='bbox')
diff --git a/configs/mmdet/_base_/datasets/coco_instance.py b/configs/mmdet/_base_/datasets/coco_instance.py
new file mode 100644
index 00000000..9901a858
--- /dev/null
+++ b/configs/mmdet/_base_/datasets/coco_instance.py
@@ -0,0 +1,49 @@
+# dataset settings
+dataset_type = 'CocoDataset'
+data_root = 'data/coco/'
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations', with_bbox=True, with_mask=True),
+ dict(type='Resize', img_scale=(1333, 800), keep_ratio=True),
+ dict(type='RandomFlip', flip_ratio=0.5),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size_divisor=32),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels', 'gt_masks']),
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(1333, 800),
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size_divisor=32),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img']),
+ ])
+]
+data = dict(
+ samples_per_gpu=2,
+ workers_per_gpu=2,
+ train=dict(
+ type=dataset_type,
+ ann_file=data_root + 'annotations/instances_train2017.json',
+ img_prefix=data_root + 'train2017/',
+ pipeline=train_pipeline),
+ val=dict(
+ type=dataset_type,
+ ann_file=data_root + 'annotations/instances_val2017.json',
+ img_prefix=data_root + 'val2017/',
+ pipeline=test_pipeline),
+ test=dict(
+ type=dataset_type,
+ ann_file=data_root + 'annotations/instances_val2017.json',
+ img_prefix=data_root + 'val2017/',
+ pipeline=test_pipeline))
+evaluation = dict(metric=['bbox', 'segm'])
diff --git a/configs/mmdet/_base_/datasets/coco_instance_semantic.py b/configs/mmdet/_base_/datasets/coco_instance_semantic.py
new file mode 100644
index 00000000..6c8bf07b
--- /dev/null
+++ b/configs/mmdet/_base_/datasets/coco_instance_semantic.py
@@ -0,0 +1,54 @@
+# dataset settings
+dataset_type = 'CocoDataset'
+data_root = 'data/coco/'
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='LoadAnnotations', with_bbox=True, with_mask=True, with_seg=True),
+ dict(type='Resize', img_scale=(1333, 800), keep_ratio=True),
+ dict(type='RandomFlip', flip_ratio=0.5),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size_divisor=32),
+ dict(type='SegRescale', scale_factor=1 / 8),
+ dict(type='DefaultFormatBundle'),
+ dict(
+ type='Collect',
+ keys=['img', 'gt_bboxes', 'gt_labels', 'gt_masks', 'gt_semantic_seg']),
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(1333, 800),
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip', flip_ratio=0.5),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size_divisor=32),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img']),
+ ])
+]
+data = dict(
+ samples_per_gpu=2,
+ workers_per_gpu=2,
+ train=dict(
+ type=dataset_type,
+ ann_file=data_root + 'annotations/instances_train2017.json',
+ img_prefix=data_root + 'train2017/',
+ seg_prefix=data_root + 'stuffthingmaps/train2017/',
+ pipeline=train_pipeline),
+ val=dict(
+ type=dataset_type,
+ ann_file=data_root + 'annotations/instances_val2017.json',
+ img_prefix=data_root + 'val2017/',
+ pipeline=test_pipeline),
+ test=dict(
+ type=dataset_type,
+ ann_file=data_root + 'annotations/instances_val2017.json',
+ img_prefix=data_root + 'val2017/',
+ pipeline=test_pipeline))
+evaluation = dict(metric=['bbox', 'segm'])
diff --git a/configs/mmdet/_base_/datasets/coco_panoptic.py b/configs/mmdet/_base_/datasets/coco_panoptic.py
new file mode 100644
index 00000000..dbade7c0
--- /dev/null
+++ b/configs/mmdet/_base_/datasets/coco_panoptic.py
@@ -0,0 +1,59 @@
+# dataset settings
+dataset_type = 'CocoPanopticDataset'
+data_root = 'data/coco/'
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='LoadPanopticAnnotations',
+ with_bbox=True,
+ with_mask=True,
+ with_seg=True),
+ dict(type='Resize', img_scale=(1333, 800), keep_ratio=True),
+ dict(type='RandomFlip', flip_ratio=0.5),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size_divisor=32),
+ dict(type='SegRescale', scale_factor=1 / 4),
+ dict(type='DefaultFormatBundle'),
+ dict(
+ type='Collect',
+ keys=['img', 'gt_bboxes', 'gt_labels', 'gt_masks', 'gt_semantic_seg']),
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(1333, 800),
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size_divisor=32),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img']),
+ ])
+]
+data = dict(
+ samples_per_gpu=2,
+ workers_per_gpu=2,
+ train=dict(
+ type=dataset_type,
+ ann_file=data_root + 'annotations/panoptic_train2017.json',
+ img_prefix=data_root + 'train2017/',
+ seg_prefix=data_root + 'annotations/panoptic_train2017/',
+ pipeline=train_pipeline),
+ val=dict(
+ type=dataset_type,
+ ann_file=data_root + 'annotations/panoptic_val2017.json',
+ img_prefix=data_root + 'val2017/',
+ seg_prefix=data_root + 'annotations/panoptic_val2017/',
+ pipeline=test_pipeline),
+ test=dict(
+ type=dataset_type,
+ ann_file=data_root + 'annotations/panoptic_val2017.json',
+ img_prefix=data_root + 'val2017/',
+ seg_prefix=data_root + 'annotations/panoptic_val2017/',
+ pipeline=test_pipeline))
+evaluation = dict(interval=1, metric=['PQ'])
diff --git a/configs/mmdet/_base_/datasets/deepfashion.py b/configs/mmdet/_base_/datasets/deepfashion.py
new file mode 100644
index 00000000..308b4b2a
--- /dev/null
+++ b/configs/mmdet/_base_/datasets/deepfashion.py
@@ -0,0 +1,53 @@
+# dataset settings
+dataset_type = 'DeepFashionDataset'
+data_root = 'data/DeepFashion/In-shop/'
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations', with_bbox=True, with_mask=True),
+ dict(type='Resize', img_scale=(750, 1101), keep_ratio=True),
+ dict(type='RandomFlip', flip_ratio=0.5),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size_divisor=32),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels', 'gt_masks']),
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(750, 1101),
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size_divisor=32),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img']),
+ ])
+]
+data = dict(
+ imgs_per_gpu=2,
+ workers_per_gpu=1,
+ train=dict(
+ type=dataset_type,
+ ann_file=data_root + 'annotations/DeepFashion_segmentation_query.json',
+ img_prefix=data_root + 'Img/',
+ pipeline=train_pipeline,
+ data_root=data_root),
+ val=dict(
+ type=dataset_type,
+ ann_file=data_root + 'annotations/DeepFashion_segmentation_query.json',
+ img_prefix=data_root + 'Img/',
+ pipeline=test_pipeline,
+ data_root=data_root),
+ test=dict(
+ type=dataset_type,
+ ann_file=data_root +
+ 'annotations/DeepFashion_segmentation_gallery.json',
+ img_prefix=data_root + 'Img/',
+ pipeline=test_pipeline,
+ data_root=data_root))
+evaluation = dict(interval=5, metric=['bbox', 'segm'])
diff --git a/configs/mmdet/_base_/datasets/lvis_v0.5_instance.py b/configs/mmdet/_base_/datasets/lvis_v0.5_instance.py
new file mode 100644
index 00000000..207e0053
--- /dev/null
+++ b/configs/mmdet/_base_/datasets/lvis_v0.5_instance.py
@@ -0,0 +1,24 @@
+# dataset settings
+_base_ = 'coco_instance.py'
+dataset_type = 'LVISV05Dataset'
+data_root = 'data/lvis_v0.5/'
+data = dict(
+ samples_per_gpu=2,
+ workers_per_gpu=2,
+ train=dict(
+ _delete_=True,
+ type='ClassBalancedDataset',
+ oversample_thr=1e-3,
+ dataset=dict(
+ type=dataset_type,
+ ann_file=data_root + 'annotations/lvis_v0.5_train.json',
+ img_prefix=data_root + 'train2017/')),
+ val=dict(
+ type=dataset_type,
+ ann_file=data_root + 'annotations/lvis_v0.5_val.json',
+ img_prefix=data_root + 'val2017/'),
+ test=dict(
+ type=dataset_type,
+ ann_file=data_root + 'annotations/lvis_v0.5_val.json',
+ img_prefix=data_root + 'val2017/'))
+evaluation = dict(metric=['bbox', 'segm'])
diff --git a/configs/mmdet/_base_/datasets/lvis_v1_instance.py b/configs/mmdet/_base_/datasets/lvis_v1_instance.py
new file mode 100644
index 00000000..be791edd
--- /dev/null
+++ b/configs/mmdet/_base_/datasets/lvis_v1_instance.py
@@ -0,0 +1,24 @@
+# dataset settings
+_base_ = 'coco_instance.py'
+dataset_type = 'LVISV1Dataset'
+data_root = 'data/lvis_v1/'
+data = dict(
+ samples_per_gpu=2,
+ workers_per_gpu=2,
+ train=dict(
+ _delete_=True,
+ type='ClassBalancedDataset',
+ oversample_thr=1e-3,
+ dataset=dict(
+ type=dataset_type,
+ ann_file=data_root + 'annotations/lvis_v1_train.json',
+ img_prefix=data_root)),
+ val=dict(
+ type=dataset_type,
+ ann_file=data_root + 'annotations/lvis_v1_val.json',
+ img_prefix=data_root),
+ test=dict(
+ type=dataset_type,
+ ann_file=data_root + 'annotations/lvis_v1_val.json',
+ img_prefix=data_root))
+evaluation = dict(metric=['bbox', 'segm'])
diff --git a/configs/mmdet/_base_/datasets/openimages_detection.py b/configs/mmdet/_base_/datasets/openimages_detection.py
new file mode 100644
index 00000000..a65d3063
--- /dev/null
+++ b/configs/mmdet/_base_/datasets/openimages_detection.py
@@ -0,0 +1,65 @@
+# dataset settings
+dataset_type = 'OpenImagesDataset'
+data_root = 'data/OpenImages/'
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations', with_bbox=True, denorm_bbox=True),
+ dict(type='Resize', img_scale=(1024, 800), keep_ratio=True),
+ dict(type='RandomFlip', flip_ratio=0.5),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size_divisor=32),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']),
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(1024, 800),
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size_divisor=32),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img']),
+ ],
+ ),
+]
+data = dict(
+ samples_per_gpu=2,
+ workers_per_gpu=0, # workers_per_gpu > 0 may occur out of memory
+ train=dict(
+ type=dataset_type,
+ ann_file=data_root + 'annotations/oidv6-train-annotations-bbox.csv',
+ img_prefix=data_root + 'OpenImages/train/',
+ label_file=data_root + 'annotations/class-descriptions-boxable.csv',
+ hierarchy_file=data_root +
+ 'annotations/bbox_labels_600_hierarchy.json',
+ pipeline=train_pipeline),
+ val=dict(
+ type=dataset_type,
+ ann_file=data_root + 'annotations/validation-annotations-bbox.csv',
+ img_prefix=data_root + 'OpenImages/validation/',
+ label_file=data_root + 'annotations/class-descriptions-boxable.csv',
+ hierarchy_file=data_root +
+ 'annotations/bbox_labels_600_hierarchy.json',
+ meta_file=data_root + 'annotations/validation-image-metas.pkl',
+ image_level_ann_file=data_root +
+ 'annotations/validation-annotations-human-imagelabels-boxable.csv',
+ pipeline=test_pipeline),
+ test=dict(
+ type=dataset_type,
+ ann_file=data_root + 'annotations/validation-annotations-bbox.csv',
+ img_prefix=data_root + 'OpenImages/validation/',
+ label_file=data_root + 'annotations/class-descriptions-boxable.csv',
+ hierarchy_file=data_root +
+ 'annotations/bbox_labels_600_hierarchy.json',
+ meta_file=data_root + 'annotations/validation-image-metas.pkl',
+ image_level_ann_file=data_root +
+ 'annotations/validation-annotations-human-imagelabels-boxable.csv',
+ pipeline=test_pipeline))
+evaluation = dict(interval=1, metric='mAP')
diff --git a/configs/mmdet/_base_/datasets/voc0712.py b/configs/mmdet/_base_/datasets/voc0712.py
new file mode 100644
index 00000000..ae09acdd
--- /dev/null
+++ b/configs/mmdet/_base_/datasets/voc0712.py
@@ -0,0 +1,55 @@
+# dataset settings
+dataset_type = 'VOCDataset'
+data_root = 'data/VOCdevkit/'
+img_norm_cfg = dict(
+ mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
+train_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(type='LoadAnnotations', with_bbox=True),
+ dict(type='Resize', img_scale=(1000, 600), keep_ratio=True),
+ dict(type='RandomFlip', flip_ratio=0.5),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size_divisor=32),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']),
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(1000, 600),
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=True),
+ dict(type='RandomFlip'),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='Pad', size_divisor=32),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img']),
+ ])
+]
+data = dict(
+ samples_per_gpu=2,
+ workers_per_gpu=2,
+ train=dict(
+ type='RepeatDataset',
+ times=3,
+ dataset=dict(
+ type=dataset_type,
+ ann_file=[
+ data_root + 'VOC2007/ImageSets/Main/trainval.txt',
+ data_root + 'VOC2012/ImageSets/Main/trainval.txt'
+ ],
+ img_prefix=[data_root + 'VOC2007/', data_root + 'VOC2012/'],
+ pipeline=train_pipeline)),
+ val=dict(
+ type=dataset_type,
+ ann_file=data_root + 'VOC2007/ImageSets/Main/test.txt',
+ img_prefix=data_root + 'VOC2007/',
+ pipeline=test_pipeline),
+ test=dict(
+ type=dataset_type,
+ ann_file=data_root + 'VOC2007/ImageSets/Main/test.txt',
+ img_prefix=data_root + 'VOC2007/',
+ pipeline=test_pipeline))
+evaluation = dict(interval=1, metric='mAP')
diff --git a/configs/mmdet/_base_/datasets/wider_face.py b/configs/mmdet/_base_/datasets/wider_face.py
new file mode 100644
index 00000000..d1d649be
--- /dev/null
+++ b/configs/mmdet/_base_/datasets/wider_face.py
@@ -0,0 +1,63 @@
+# dataset settings
+dataset_type = 'WIDERFaceDataset'
+data_root = 'data/WIDERFace/'
+img_norm_cfg = dict(mean=[123.675, 116.28, 103.53], std=[1, 1, 1], to_rgb=True)
+train_pipeline = [
+ dict(type='LoadImageFromFile', to_float32=True),
+ dict(type='LoadAnnotations', with_bbox=True),
+ dict(
+ type='PhotoMetricDistortion',
+ brightness_delta=32,
+ contrast_range=(0.5, 1.5),
+ saturation_range=(0.5, 1.5),
+ hue_delta=18),
+ dict(
+ type='Expand',
+ mean=img_norm_cfg['mean'],
+ to_rgb=img_norm_cfg['to_rgb'],
+ ratio_range=(1, 4)),
+ dict(
+ type='MinIoURandomCrop',
+ min_ious=(0.1, 0.3, 0.5, 0.7, 0.9),
+ min_crop_size=0.3),
+ dict(type='Resize', img_scale=(300, 300), keep_ratio=False),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='RandomFlip', flip_ratio=0.5),
+ dict(type='DefaultFormatBundle'),
+ dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']),
+]
+test_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='MultiScaleFlipAug',
+ img_scale=(300, 300),
+ flip=False,
+ transforms=[
+ dict(type='Resize', keep_ratio=False),
+ dict(type='Normalize', **img_norm_cfg),
+ dict(type='ImageToTensor', keys=['img']),
+ dict(type='Collect', keys=['img']),
+ ])
+]
+data = dict(
+ samples_per_gpu=60,
+ workers_per_gpu=2,
+ train=dict(
+ type='RepeatDataset',
+ times=2,
+ dataset=dict(
+ type=dataset_type,
+ ann_file=data_root + 'train.txt',
+ img_prefix=data_root + 'WIDER_train/',
+ min_size=17,
+ pipeline=train_pipeline)),
+ val=dict(
+ type=dataset_type,
+ ann_file=data_root + 'val.txt',
+ img_prefix=data_root + 'WIDER_val/',
+ pipeline=test_pipeline),
+ test=dict(
+ type=dataset_type,
+ ann_file=data_root + 'val.txt',
+ img_prefix=data_root + 'WIDER_val/',
+ pipeline=test_pipeline))
diff --git a/configs/mmdet/_base_/default_runtime.py b/configs/mmdet/_base_/default_runtime.py
new file mode 100644
index 00000000..5b0b1452
--- /dev/null
+++ b/configs/mmdet/_base_/default_runtime.py
@@ -0,0 +1,27 @@
+checkpoint_config = dict(interval=1)
+# yapf:disable
+log_config = dict(
+ interval=50,
+ hooks=[
+ dict(type='TextLoggerHook'),
+ # dict(type='TensorboardLoggerHook')
+ ])
+# yapf:enable
+custom_hooks = [dict(type='NumClassCheckHook')]
+
+dist_params = dict(backend='nccl')
+log_level = 'INFO'
+load_from = None
+resume_from = None
+workflow = [('train', 1)]
+
+# disable opencv multithreading to avoid system being overloaded
+opencv_num_threads = 0
+# set multi-process start method as `fork` to speed up the training
+mp_start_method = 'fork'
+
+# Default setting for scaling LR automatically
+# - `enable` means enable scaling LR automatically
+# or not by default.
+# - `base_batch_size` = (8 GPUs) x (2 samples per GPU).
+auto_scale_lr = dict(enable=False, base_batch_size=16)
diff --git a/configs/mmdet/_base_/models/cascade_mask_rcnn_r50_fpn.py b/configs/mmdet/_base_/models/cascade_mask_rcnn_r50_fpn.py
new file mode 100644
index 00000000..2902ccae
--- /dev/null
+++ b/configs/mmdet/_base_/models/cascade_mask_rcnn_r50_fpn.py
@@ -0,0 +1,196 @@
+# model settings
+model = dict(
+ type='CascadeRCNN',
+ backbone=dict(
+ type='ResNet',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ frozen_stages=1,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ norm_eval=True,
+ style='pytorch',
+ init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')),
+ neck=dict(
+ type='FPN',
+ in_channels=[256, 512, 1024, 2048],
+ out_channels=256,
+ num_outs=5),
+ rpn_head=dict(
+ type='RPNHead',
+ in_channels=256,
+ feat_channels=256,
+ anchor_generator=dict(
+ type='AnchorGenerator',
+ scales=[8],
+ ratios=[0.5, 1.0, 2.0],
+ strides=[4, 8, 16, 32, 64]),
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[.0, .0, .0, .0],
+ target_stds=[1.0, 1.0, 1.0, 1.0]),
+ loss_cls=dict(
+ type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
+ loss_bbox=dict(type='SmoothL1Loss', beta=1.0 / 9.0, loss_weight=1.0)),
+ roi_head=dict(
+ type='CascadeRoIHead',
+ num_stages=3,
+ stage_loss_weights=[1, 0.5, 0.25],
+ bbox_roi_extractor=dict(
+ type='SingleRoIExtractor',
+ roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),
+ out_channels=256,
+ featmap_strides=[4, 8, 16, 32]),
+ bbox_head=[
+ dict(
+ type='Shared2FCBBoxHead',
+ in_channels=256,
+ fc_out_channels=1024,
+ roi_feat_size=7,
+ num_classes=80,
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[0., 0., 0., 0.],
+ target_stds=[0.1, 0.1, 0.2, 0.2]),
+ reg_class_agnostic=True,
+ loss_cls=dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=False,
+ loss_weight=1.0),
+ loss_bbox=dict(type='SmoothL1Loss', beta=1.0,
+ loss_weight=1.0)),
+ dict(
+ type='Shared2FCBBoxHead',
+ in_channels=256,
+ fc_out_channels=1024,
+ roi_feat_size=7,
+ num_classes=80,
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[0., 0., 0., 0.],
+ target_stds=[0.05, 0.05, 0.1, 0.1]),
+ reg_class_agnostic=True,
+ loss_cls=dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=False,
+ loss_weight=1.0),
+ loss_bbox=dict(type='SmoothL1Loss', beta=1.0,
+ loss_weight=1.0)),
+ dict(
+ type='Shared2FCBBoxHead',
+ in_channels=256,
+ fc_out_channels=1024,
+ roi_feat_size=7,
+ num_classes=80,
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[0., 0., 0., 0.],
+ target_stds=[0.033, 0.033, 0.067, 0.067]),
+ reg_class_agnostic=True,
+ loss_cls=dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=False,
+ loss_weight=1.0),
+ loss_bbox=dict(type='SmoothL1Loss', beta=1.0, loss_weight=1.0))
+ ],
+ mask_roi_extractor=dict(
+ type='SingleRoIExtractor',
+ roi_layer=dict(type='RoIAlign', output_size=14, sampling_ratio=0),
+ out_channels=256,
+ featmap_strides=[4, 8, 16, 32]),
+ mask_head=dict(
+ type='FCNMaskHead',
+ num_convs=4,
+ in_channels=256,
+ conv_out_channels=256,
+ num_classes=80,
+ loss_mask=dict(
+ type='CrossEntropyLoss', use_mask=True, loss_weight=1.0))),
+ # model training and testing settings
+ train_cfg=dict(
+ rpn=dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.7,
+ neg_iou_thr=0.3,
+ min_pos_iou=0.3,
+ match_low_quality=True,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=256,
+ pos_fraction=0.5,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=False),
+ allowed_border=0,
+ pos_weight=-1,
+ debug=False),
+ rpn_proposal=dict(
+ nms_pre=2000,
+ max_per_img=2000,
+ nms=dict(type='nms', iou_threshold=0.7),
+ min_bbox_size=0),
+ rcnn=[
+ dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.5,
+ neg_iou_thr=0.5,
+ min_pos_iou=0.5,
+ match_low_quality=False,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=512,
+ pos_fraction=0.25,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=True),
+ mask_size=28,
+ pos_weight=-1,
+ debug=False),
+ dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.6,
+ neg_iou_thr=0.6,
+ min_pos_iou=0.6,
+ match_low_quality=False,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=512,
+ pos_fraction=0.25,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=True),
+ mask_size=28,
+ pos_weight=-1,
+ debug=False),
+ dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.7,
+ neg_iou_thr=0.7,
+ min_pos_iou=0.7,
+ match_low_quality=False,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=512,
+ pos_fraction=0.25,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=True),
+ mask_size=28,
+ pos_weight=-1,
+ debug=False)
+ ]),
+ test_cfg=dict(
+ rpn=dict(
+ nms_pre=1000,
+ max_per_img=1000,
+ nms=dict(type='nms', iou_threshold=0.7),
+ min_bbox_size=0),
+ rcnn=dict(
+ score_thr=0.05,
+ nms=dict(type='nms', iou_threshold=0.5),
+ max_per_img=100,
+ mask_thr_binary=0.5)))
diff --git a/configs/mmdet/_base_/models/cascade_rcnn_r50_fpn.py b/configs/mmdet/_base_/models/cascade_rcnn_r50_fpn.py
new file mode 100644
index 00000000..42f74ae7
--- /dev/null
+++ b/configs/mmdet/_base_/models/cascade_rcnn_r50_fpn.py
@@ -0,0 +1,179 @@
+# model settings
+model = dict(
+ type='CascadeRCNN',
+ backbone=dict(
+ type='ResNet',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ frozen_stages=1,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ norm_eval=True,
+ style='pytorch',
+ init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')),
+ neck=dict(
+ type='FPN',
+ in_channels=[256, 512, 1024, 2048],
+ out_channels=256,
+ num_outs=5),
+ rpn_head=dict(
+ type='RPNHead',
+ in_channels=256,
+ feat_channels=256,
+ anchor_generator=dict(
+ type='AnchorGenerator',
+ scales=[8],
+ ratios=[0.5, 1.0, 2.0],
+ strides=[4, 8, 16, 32, 64]),
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[.0, .0, .0, .0],
+ target_stds=[1.0, 1.0, 1.0, 1.0]),
+ loss_cls=dict(
+ type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
+ loss_bbox=dict(type='SmoothL1Loss', beta=1.0 / 9.0, loss_weight=1.0)),
+ roi_head=dict(
+ type='CascadeRoIHead',
+ num_stages=3,
+ stage_loss_weights=[1, 0.5, 0.25],
+ bbox_roi_extractor=dict(
+ type='SingleRoIExtractor',
+ roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),
+ out_channels=256,
+ featmap_strides=[4, 8, 16, 32]),
+ bbox_head=[
+ dict(
+ type='Shared2FCBBoxHead',
+ in_channels=256,
+ fc_out_channels=1024,
+ roi_feat_size=7,
+ num_classes=80,
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[0., 0., 0., 0.],
+ target_stds=[0.1, 0.1, 0.2, 0.2]),
+ reg_class_agnostic=True,
+ loss_cls=dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=False,
+ loss_weight=1.0),
+ loss_bbox=dict(type='SmoothL1Loss', beta=1.0,
+ loss_weight=1.0)),
+ dict(
+ type='Shared2FCBBoxHead',
+ in_channels=256,
+ fc_out_channels=1024,
+ roi_feat_size=7,
+ num_classes=80,
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[0., 0., 0., 0.],
+ target_stds=[0.05, 0.05, 0.1, 0.1]),
+ reg_class_agnostic=True,
+ loss_cls=dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=False,
+ loss_weight=1.0),
+ loss_bbox=dict(type='SmoothL1Loss', beta=1.0,
+ loss_weight=1.0)),
+ dict(
+ type='Shared2FCBBoxHead',
+ in_channels=256,
+ fc_out_channels=1024,
+ roi_feat_size=7,
+ num_classes=80,
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[0., 0., 0., 0.],
+ target_stds=[0.033, 0.033, 0.067, 0.067]),
+ reg_class_agnostic=True,
+ loss_cls=dict(
+ type='CrossEntropyLoss',
+ use_sigmoid=False,
+ loss_weight=1.0),
+ loss_bbox=dict(type='SmoothL1Loss', beta=1.0, loss_weight=1.0))
+ ]),
+ # model training and testing settings
+ train_cfg=dict(
+ rpn=dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.7,
+ neg_iou_thr=0.3,
+ min_pos_iou=0.3,
+ match_low_quality=True,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=256,
+ pos_fraction=0.5,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=False),
+ allowed_border=0,
+ pos_weight=-1,
+ debug=False),
+ rpn_proposal=dict(
+ nms_pre=2000,
+ max_per_img=2000,
+ nms=dict(type='nms', iou_threshold=0.7),
+ min_bbox_size=0),
+ rcnn=[
+ dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.5,
+ neg_iou_thr=0.5,
+ min_pos_iou=0.5,
+ match_low_quality=False,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=512,
+ pos_fraction=0.25,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=True),
+ pos_weight=-1,
+ debug=False),
+ dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.6,
+ neg_iou_thr=0.6,
+ min_pos_iou=0.6,
+ match_low_quality=False,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=512,
+ pos_fraction=0.25,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=True),
+ pos_weight=-1,
+ debug=False),
+ dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.7,
+ neg_iou_thr=0.7,
+ min_pos_iou=0.7,
+ match_low_quality=False,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=512,
+ pos_fraction=0.25,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=True),
+ pos_weight=-1,
+ debug=False)
+ ]),
+ test_cfg=dict(
+ rpn=dict(
+ nms_pre=1000,
+ max_per_img=1000,
+ nms=dict(type='nms', iou_threshold=0.7),
+ min_bbox_size=0),
+ rcnn=dict(
+ score_thr=0.05,
+ nms=dict(type='nms', iou_threshold=0.5),
+ max_per_img=100)))
diff --git a/configs/mmdet/_base_/models/fast_rcnn_r50_fpn.py b/configs/mmdet/_base_/models/fast_rcnn_r50_fpn.py
new file mode 100644
index 00000000..9982fe09
--- /dev/null
+++ b/configs/mmdet/_base_/models/fast_rcnn_r50_fpn.py
@@ -0,0 +1,62 @@
+# model settings
+model = dict(
+ type='FastRCNN',
+ backbone=dict(
+ type='ResNet',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ frozen_stages=1,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ norm_eval=True,
+ style='pytorch',
+ init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')),
+ neck=dict(
+ type='FPN',
+ in_channels=[256, 512, 1024, 2048],
+ out_channels=256,
+ num_outs=5),
+ roi_head=dict(
+ type='StandardRoIHead',
+ bbox_roi_extractor=dict(
+ type='SingleRoIExtractor',
+ roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),
+ out_channels=256,
+ featmap_strides=[4, 8, 16, 32]),
+ bbox_head=dict(
+ type='Shared2FCBBoxHead',
+ in_channels=256,
+ fc_out_channels=1024,
+ roi_feat_size=7,
+ num_classes=80,
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[0., 0., 0., 0.],
+ target_stds=[0.1, 0.1, 0.2, 0.2]),
+ reg_class_agnostic=False,
+ loss_cls=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
+ loss_bbox=dict(type='L1Loss', loss_weight=1.0))),
+ # model training and testing settings
+ train_cfg=dict(
+ rcnn=dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.5,
+ neg_iou_thr=0.5,
+ min_pos_iou=0.5,
+ match_low_quality=False,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=512,
+ pos_fraction=0.25,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=True),
+ pos_weight=-1,
+ debug=False)),
+ test_cfg=dict(
+ rcnn=dict(
+ score_thr=0.05,
+ nms=dict(type='nms', iou_threshold=0.5),
+ max_per_img=100)))
diff --git a/configs/mmdet/_base_/models/faster_rcnn_r50_caffe_c4.py b/configs/mmdet/_base_/models/faster_rcnn_r50_caffe_c4.py
new file mode 100644
index 00000000..dbf965af
--- /dev/null
+++ b/configs/mmdet/_base_/models/faster_rcnn_r50_caffe_c4.py
@@ -0,0 +1,117 @@
+# model settings
+norm_cfg = dict(type='BN', requires_grad=False)
+model = dict(
+ type='FasterRCNN',
+ backbone=dict(
+ type='ResNet',
+ depth=50,
+ num_stages=3,
+ strides=(1, 2, 2),
+ dilations=(1, 1, 1),
+ out_indices=(2, ),
+ frozen_stages=1,
+ norm_cfg=norm_cfg,
+ norm_eval=True,
+ style='caffe',
+ init_cfg=dict(
+ type='Pretrained',
+ checkpoint='open-mmlab://detectron2/resnet50_caffe')),
+ rpn_head=dict(
+ type='RPNHead',
+ in_channels=1024,
+ feat_channels=1024,
+ anchor_generator=dict(
+ type='AnchorGenerator',
+ scales=[2, 4, 8, 16, 32],
+ ratios=[0.5, 1.0, 2.0],
+ strides=[16]),
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[.0, .0, .0, .0],
+ target_stds=[1.0, 1.0, 1.0, 1.0]),
+ loss_cls=dict(
+ type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
+ loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
+ roi_head=dict(
+ type='StandardRoIHead',
+ shared_head=dict(
+ type='ResLayer',
+ depth=50,
+ stage=3,
+ stride=2,
+ dilation=1,
+ style='caffe',
+ norm_cfg=norm_cfg,
+ norm_eval=True,
+ init_cfg=dict(
+ type='Pretrained',
+ checkpoint='open-mmlab://detectron2/resnet50_caffe')),
+ bbox_roi_extractor=dict(
+ type='SingleRoIExtractor',
+ roi_layer=dict(type='RoIAlign', output_size=14, sampling_ratio=0),
+ out_channels=1024,
+ featmap_strides=[16]),
+ bbox_head=dict(
+ type='BBoxHead',
+ with_avg_pool=True,
+ roi_feat_size=7,
+ in_channels=2048,
+ num_classes=80,
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[0., 0., 0., 0.],
+ target_stds=[0.1, 0.1, 0.2, 0.2]),
+ reg_class_agnostic=False,
+ loss_cls=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
+ loss_bbox=dict(type='L1Loss', loss_weight=1.0))),
+ # model training and testing settings
+ train_cfg=dict(
+ rpn=dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.7,
+ neg_iou_thr=0.3,
+ min_pos_iou=0.3,
+ match_low_quality=True,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=256,
+ pos_fraction=0.5,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=False),
+ allowed_border=-1,
+ pos_weight=-1,
+ debug=False),
+ rpn_proposal=dict(
+ nms_pre=12000,
+ max_per_img=2000,
+ nms=dict(type='nms', iou_threshold=0.7),
+ min_bbox_size=0),
+ rcnn=dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.5,
+ neg_iou_thr=0.5,
+ min_pos_iou=0.5,
+ match_low_quality=False,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=512,
+ pos_fraction=0.25,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=True),
+ pos_weight=-1,
+ debug=False)),
+ test_cfg=dict(
+ rpn=dict(
+ nms_pre=6000,
+ max_per_img=1000,
+ nms=dict(type='nms', iou_threshold=0.7),
+ min_bbox_size=0),
+ rcnn=dict(
+ score_thr=0.05,
+ nms=dict(type='nms', iou_threshold=0.5),
+ max_per_img=100)))
diff --git a/configs/mmdet/_base_/models/faster_rcnn_r50_caffe_dc5.py b/configs/mmdet/_base_/models/faster_rcnn_r50_caffe_dc5.py
new file mode 100644
index 00000000..a377a6f0
--- /dev/null
+++ b/configs/mmdet/_base_/models/faster_rcnn_r50_caffe_dc5.py
@@ -0,0 +1,105 @@
+# model settings
+norm_cfg = dict(type='BN', requires_grad=False)
+model = dict(
+ type='FasterRCNN',
+ backbone=dict(
+ type='ResNet',
+ depth=50,
+ num_stages=4,
+ strides=(1, 2, 2, 1),
+ dilations=(1, 1, 1, 2),
+ out_indices=(3, ),
+ frozen_stages=1,
+ norm_cfg=norm_cfg,
+ norm_eval=True,
+ style='caffe',
+ init_cfg=dict(
+ type='Pretrained',
+ checkpoint='open-mmlab://detectron2/resnet50_caffe')),
+ rpn_head=dict(
+ type='RPNHead',
+ in_channels=2048,
+ feat_channels=2048,
+ anchor_generator=dict(
+ type='AnchorGenerator',
+ scales=[2, 4, 8, 16, 32],
+ ratios=[0.5, 1.0, 2.0],
+ strides=[16]),
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[.0, .0, .0, .0],
+ target_stds=[1.0, 1.0, 1.0, 1.0]),
+ loss_cls=dict(
+ type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
+ loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
+ roi_head=dict(
+ type='StandardRoIHead',
+ bbox_roi_extractor=dict(
+ type='SingleRoIExtractor',
+ roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),
+ out_channels=2048,
+ featmap_strides=[16]),
+ bbox_head=dict(
+ type='Shared2FCBBoxHead',
+ in_channels=2048,
+ fc_out_channels=1024,
+ roi_feat_size=7,
+ num_classes=80,
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[0., 0., 0., 0.],
+ target_stds=[0.1, 0.1, 0.2, 0.2]),
+ reg_class_agnostic=False,
+ loss_cls=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
+ loss_bbox=dict(type='L1Loss', loss_weight=1.0))),
+ # model training and testing settings
+ train_cfg=dict(
+ rpn=dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.7,
+ neg_iou_thr=0.3,
+ min_pos_iou=0.3,
+ match_low_quality=True,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=256,
+ pos_fraction=0.5,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=False),
+ allowed_border=0,
+ pos_weight=-1,
+ debug=False),
+ rpn_proposal=dict(
+ nms_pre=12000,
+ max_per_img=2000,
+ nms=dict(type='nms', iou_threshold=0.7),
+ min_bbox_size=0),
+ rcnn=dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.5,
+ neg_iou_thr=0.5,
+ min_pos_iou=0.5,
+ match_low_quality=False,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=512,
+ pos_fraction=0.25,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=True),
+ pos_weight=-1,
+ debug=False)),
+ test_cfg=dict(
+ rpn=dict(
+ nms=dict(type='nms', iou_threshold=0.7),
+ nms_pre=6000,
+ max_per_img=1000,
+ min_bbox_size=0),
+ rcnn=dict(
+ score_thr=0.05,
+ nms=dict(type='nms', iou_threshold=0.5),
+ max_per_img=100)))
diff --git a/configs/mmdet/_base_/models/faster_rcnn_r50_fpn.py b/configs/mmdet/_base_/models/faster_rcnn_r50_fpn.py
new file mode 100644
index 00000000..1ef8e7b2
--- /dev/null
+++ b/configs/mmdet/_base_/models/faster_rcnn_r50_fpn.py
@@ -0,0 +1,108 @@
+# model settings
+model = dict(
+ type='FasterRCNN',
+ backbone=dict(
+ type='ResNet',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ frozen_stages=1,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ norm_eval=True,
+ style='pytorch',
+ init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')),
+ neck=dict(
+ type='FPN',
+ in_channels=[256, 512, 1024, 2048],
+ out_channels=256,
+ num_outs=5),
+ rpn_head=dict(
+ type='RPNHead',
+ in_channels=256,
+ feat_channels=256,
+ anchor_generator=dict(
+ type='AnchorGenerator',
+ scales=[8],
+ ratios=[0.5, 1.0, 2.0],
+ strides=[4, 8, 16, 32, 64]),
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[.0, .0, .0, .0],
+ target_stds=[1.0, 1.0, 1.0, 1.0]),
+ loss_cls=dict(
+ type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
+ loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
+ roi_head=dict(
+ type='StandardRoIHead',
+ bbox_roi_extractor=dict(
+ type='SingleRoIExtractor',
+ roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),
+ out_channels=256,
+ featmap_strides=[4, 8, 16, 32]),
+ bbox_head=dict(
+ type='Shared2FCBBoxHead',
+ in_channels=256,
+ fc_out_channels=1024,
+ roi_feat_size=7,
+ num_classes=80,
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[0., 0., 0., 0.],
+ target_stds=[0.1, 0.1, 0.2, 0.2]),
+ reg_class_agnostic=False,
+ loss_cls=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
+ loss_bbox=dict(type='L1Loss', loss_weight=1.0))),
+ # model training and testing settings
+ train_cfg=dict(
+ rpn=dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.7,
+ neg_iou_thr=0.3,
+ min_pos_iou=0.3,
+ match_low_quality=True,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=256,
+ pos_fraction=0.5,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=False),
+ allowed_border=-1,
+ pos_weight=-1,
+ debug=False),
+ rpn_proposal=dict(
+ nms_pre=2000,
+ max_per_img=1000,
+ nms=dict(type='nms', iou_threshold=0.7),
+ min_bbox_size=0),
+ rcnn=dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.5,
+ neg_iou_thr=0.5,
+ min_pos_iou=0.5,
+ match_low_quality=False,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=512,
+ pos_fraction=0.25,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=True),
+ pos_weight=-1,
+ debug=False)),
+ test_cfg=dict(
+ rpn=dict(
+ nms_pre=1000,
+ max_per_img=1000,
+ nms=dict(type='nms', iou_threshold=0.7),
+ min_bbox_size=0),
+ rcnn=dict(
+ score_thr=0.05,
+ nms=dict(type='nms', iou_threshold=0.5),
+ max_per_img=100)
+ # soft-nms is also supported for rcnn testing
+ # e.g., nms=dict(type='soft_nms', iou_threshold=0.5, min_score=0.05)
+ ))
diff --git a/configs/mmdet/_base_/models/mask_rcnn_r50_caffe_c4.py b/configs/mmdet/_base_/models/mask_rcnn_r50_caffe_c4.py
new file mode 100644
index 00000000..122202e1
--- /dev/null
+++ b/configs/mmdet/_base_/models/mask_rcnn_r50_caffe_c4.py
@@ -0,0 +1,125 @@
+# model settings
+norm_cfg = dict(type='BN', requires_grad=False)
+model = dict(
+ type='MaskRCNN',
+ backbone=dict(
+ type='ResNet',
+ depth=50,
+ num_stages=3,
+ strides=(1, 2, 2),
+ dilations=(1, 1, 1),
+ out_indices=(2, ),
+ frozen_stages=1,
+ norm_cfg=norm_cfg,
+ norm_eval=True,
+ style='caffe',
+ init_cfg=dict(
+ type='Pretrained',
+ checkpoint='open-mmlab://detectron2/resnet50_caffe')),
+ rpn_head=dict(
+ type='RPNHead',
+ in_channels=1024,
+ feat_channels=1024,
+ anchor_generator=dict(
+ type='AnchorGenerator',
+ scales=[2, 4, 8, 16, 32],
+ ratios=[0.5, 1.0, 2.0],
+ strides=[16]),
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[.0, .0, .0, .0],
+ target_stds=[1.0, 1.0, 1.0, 1.0]),
+ loss_cls=dict(
+ type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
+ loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
+ roi_head=dict(
+ type='StandardRoIHead',
+ shared_head=dict(
+ type='ResLayer',
+ depth=50,
+ stage=3,
+ stride=2,
+ dilation=1,
+ style='caffe',
+ norm_cfg=norm_cfg,
+ norm_eval=True),
+ bbox_roi_extractor=dict(
+ type='SingleRoIExtractor',
+ roi_layer=dict(type='RoIAlign', output_size=14, sampling_ratio=0),
+ out_channels=1024,
+ featmap_strides=[16]),
+ bbox_head=dict(
+ type='BBoxHead',
+ with_avg_pool=True,
+ roi_feat_size=7,
+ in_channels=2048,
+ num_classes=80,
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[0., 0., 0., 0.],
+ target_stds=[0.1, 0.1, 0.2, 0.2]),
+ reg_class_agnostic=False,
+ loss_cls=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
+ loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
+ mask_roi_extractor=None,
+ mask_head=dict(
+ type='FCNMaskHead',
+ num_convs=0,
+ in_channels=2048,
+ conv_out_channels=256,
+ num_classes=80,
+ loss_mask=dict(
+ type='CrossEntropyLoss', use_mask=True, loss_weight=1.0))),
+ # model training and testing settings
+ train_cfg=dict(
+ rpn=dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.7,
+ neg_iou_thr=0.3,
+ min_pos_iou=0.3,
+ match_low_quality=True,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=256,
+ pos_fraction=0.5,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=False),
+ allowed_border=0,
+ pos_weight=-1,
+ debug=False),
+ rpn_proposal=dict(
+ nms_pre=12000,
+ max_per_img=2000,
+ nms=dict(type='nms', iou_threshold=0.7),
+ min_bbox_size=0),
+ rcnn=dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.5,
+ neg_iou_thr=0.5,
+ min_pos_iou=0.5,
+ match_low_quality=False,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=512,
+ pos_fraction=0.25,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=True),
+ mask_size=14,
+ pos_weight=-1,
+ debug=False)),
+ test_cfg=dict(
+ rpn=dict(
+ nms_pre=6000,
+ nms=dict(type='nms', iou_threshold=0.7),
+ max_per_img=1000,
+ min_bbox_size=0),
+ rcnn=dict(
+ score_thr=0.05,
+ nms=dict(type='nms', iou_threshold=0.5),
+ max_per_img=100,
+ mask_thr_binary=0.5)))
diff --git a/configs/mmdet/_base_/models/mask_rcnn_r50_fpn.py b/configs/mmdet/_base_/models/mask_rcnn_r50_fpn.py
new file mode 100644
index 00000000..d903e55e
--- /dev/null
+++ b/configs/mmdet/_base_/models/mask_rcnn_r50_fpn.py
@@ -0,0 +1,120 @@
+# model settings
+model = dict(
+ type='MaskRCNN',
+ backbone=dict(
+ type='ResNet',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ frozen_stages=1,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ norm_eval=True,
+ style='pytorch',
+ init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')),
+ neck=dict(
+ type='FPN',
+ in_channels=[256, 512, 1024, 2048],
+ out_channels=256,
+ num_outs=5),
+ rpn_head=dict(
+ type='RPNHead',
+ in_channels=256,
+ feat_channels=256,
+ anchor_generator=dict(
+ type='AnchorGenerator',
+ scales=[8],
+ ratios=[0.5, 1.0, 2.0],
+ strides=[4, 8, 16, 32, 64]),
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[.0, .0, .0, .0],
+ target_stds=[1.0, 1.0, 1.0, 1.0]),
+ loss_cls=dict(
+ type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
+ loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
+ roi_head=dict(
+ type='StandardRoIHead',
+ bbox_roi_extractor=dict(
+ type='SingleRoIExtractor',
+ roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),
+ out_channels=256,
+ featmap_strides=[4, 8, 16, 32]),
+ bbox_head=dict(
+ type='Shared2FCBBoxHead',
+ in_channels=256,
+ fc_out_channels=1024,
+ roi_feat_size=7,
+ num_classes=80,
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[0., 0., 0., 0.],
+ target_stds=[0.1, 0.1, 0.2, 0.2]),
+ reg_class_agnostic=False,
+ loss_cls=dict(
+ type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
+ loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
+ mask_roi_extractor=dict(
+ type='SingleRoIExtractor',
+ roi_layer=dict(type='RoIAlign', output_size=14, sampling_ratio=0),
+ out_channels=256,
+ featmap_strides=[4, 8, 16, 32]),
+ mask_head=dict(
+ type='FCNMaskHead',
+ num_convs=4,
+ in_channels=256,
+ conv_out_channels=256,
+ num_classes=80,
+ loss_mask=dict(
+ type='CrossEntropyLoss', use_mask=True, loss_weight=1.0))),
+ # model training and testing settings
+ train_cfg=dict(
+ rpn=dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.7,
+ neg_iou_thr=0.3,
+ min_pos_iou=0.3,
+ match_low_quality=True,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=256,
+ pos_fraction=0.5,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=False),
+ allowed_border=-1,
+ pos_weight=-1,
+ debug=False),
+ rpn_proposal=dict(
+ nms_pre=2000,
+ max_per_img=1000,
+ nms=dict(type='nms', iou_threshold=0.7),
+ min_bbox_size=0),
+ rcnn=dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.5,
+ neg_iou_thr=0.5,
+ min_pos_iou=0.5,
+ match_low_quality=True,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=512,
+ pos_fraction=0.25,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=True),
+ mask_size=28,
+ pos_weight=-1,
+ debug=False)),
+ test_cfg=dict(
+ rpn=dict(
+ nms_pre=1000,
+ max_per_img=1000,
+ nms=dict(type='nms', iou_threshold=0.7),
+ min_bbox_size=0),
+ rcnn=dict(
+ score_thr=0.05,
+ nms=dict(type='nms', iou_threshold=0.5),
+ max_per_img=100,
+ mask_thr_binary=0.5)))
diff --git a/configs/mmdet/_base_/models/retinanet_r50_fpn.py b/configs/mmdet/_base_/models/retinanet_r50_fpn.py
new file mode 100644
index 00000000..56e43fa7
--- /dev/null
+++ b/configs/mmdet/_base_/models/retinanet_r50_fpn.py
@@ -0,0 +1,60 @@
+# model settings
+model = dict(
+ type='RetinaNet',
+ backbone=dict(
+ type='ResNet',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ frozen_stages=1,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ norm_eval=True,
+ style='pytorch',
+ init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')),
+ neck=dict(
+ type='FPN',
+ in_channels=[256, 512, 1024, 2048],
+ out_channels=256,
+ start_level=1,
+ add_extra_convs='on_input',
+ num_outs=5),
+ bbox_head=dict(
+ type='RetinaHead',
+ num_classes=80,
+ in_channels=256,
+ stacked_convs=4,
+ feat_channels=256,
+ anchor_generator=dict(
+ type='AnchorGenerator',
+ octave_base_scale=4,
+ scales_per_octave=3,
+ ratios=[0.5, 1.0, 2.0],
+ strides=[8, 16, 32, 64, 128]),
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[.0, .0, .0, .0],
+ target_stds=[1.0, 1.0, 1.0, 1.0]),
+ loss_cls=dict(
+ type='FocalLoss',
+ use_sigmoid=True,
+ gamma=2.0,
+ alpha=0.25,
+ loss_weight=1.0),
+ loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
+ # model training and testing settings
+ train_cfg=dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.5,
+ neg_iou_thr=0.4,
+ min_pos_iou=0,
+ ignore_iof_thr=-1),
+ allowed_border=-1,
+ pos_weight=-1,
+ debug=False),
+ test_cfg=dict(
+ nms_pre=1000,
+ min_bbox_size=0,
+ score_thr=0.05,
+ nms=dict(type='nms', iou_threshold=0.5),
+ max_per_img=100))
diff --git a/configs/mmdet/_base_/models/rpn_r50_caffe_c4.py b/configs/mmdet/_base_/models/rpn_r50_caffe_c4.py
new file mode 100644
index 00000000..8b32ca99
--- /dev/null
+++ b/configs/mmdet/_base_/models/rpn_r50_caffe_c4.py
@@ -0,0 +1,58 @@
+# model settings
+model = dict(
+ type='RPN',
+ backbone=dict(
+ type='ResNet',
+ depth=50,
+ num_stages=3,
+ strides=(1, 2, 2),
+ dilations=(1, 1, 1),
+ out_indices=(2, ),
+ frozen_stages=1,
+ norm_cfg=dict(type='BN', requires_grad=False),
+ norm_eval=True,
+ style='caffe',
+ init_cfg=dict(
+ type='Pretrained',
+ checkpoint='open-mmlab://detectron2/resnet50_caffe')),
+ neck=None,
+ rpn_head=dict(
+ type='RPNHead',
+ in_channels=1024,
+ feat_channels=1024,
+ anchor_generator=dict(
+ type='AnchorGenerator',
+ scales=[2, 4, 8, 16, 32],
+ ratios=[0.5, 1.0, 2.0],
+ strides=[16]),
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[.0, .0, .0, .0],
+ target_stds=[1.0, 1.0, 1.0, 1.0]),
+ loss_cls=dict(
+ type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
+ loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
+ # model training and testing settings
+ train_cfg=dict(
+ rpn=dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.7,
+ neg_iou_thr=0.3,
+ min_pos_iou=0.3,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=256,
+ pos_fraction=0.5,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=False),
+ allowed_border=0,
+ pos_weight=-1,
+ debug=False)),
+ test_cfg=dict(
+ rpn=dict(
+ nms_pre=12000,
+ max_per_img=2000,
+ nms=dict(type='nms', iou_threshold=0.7),
+ min_bbox_size=0)))
diff --git a/configs/mmdet/_base_/models/rpn_r50_fpn.py b/configs/mmdet/_base_/models/rpn_r50_fpn.py
new file mode 100644
index 00000000..edaf4d4b
--- /dev/null
+++ b/configs/mmdet/_base_/models/rpn_r50_fpn.py
@@ -0,0 +1,58 @@
+# model settings
+model = dict(
+ type='RPN',
+ backbone=dict(
+ type='ResNet',
+ depth=50,
+ num_stages=4,
+ out_indices=(0, 1, 2, 3),
+ frozen_stages=1,
+ norm_cfg=dict(type='BN', requires_grad=True),
+ norm_eval=True,
+ style='pytorch',
+ init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')),
+ neck=dict(
+ type='FPN',
+ in_channels=[256, 512, 1024, 2048],
+ out_channels=256,
+ num_outs=5),
+ rpn_head=dict(
+ type='RPNHead',
+ in_channels=256,
+ feat_channels=256,
+ anchor_generator=dict(
+ type='AnchorGenerator',
+ scales=[8],
+ ratios=[0.5, 1.0, 2.0],
+ strides=[4, 8, 16, 32, 64]),
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[.0, .0, .0, .0],
+ target_stds=[1.0, 1.0, 1.0, 1.0]),
+ loss_cls=dict(
+ type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
+ loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
+ # model training and testing settings
+ train_cfg=dict(
+ rpn=dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.7,
+ neg_iou_thr=0.3,
+ min_pos_iou=0.3,
+ ignore_iof_thr=-1),
+ sampler=dict(
+ type='RandomSampler',
+ num=256,
+ pos_fraction=0.5,
+ neg_pos_ub=-1,
+ add_gt_as_proposals=False),
+ allowed_border=0,
+ pos_weight=-1,
+ debug=False)),
+ test_cfg=dict(
+ rpn=dict(
+ nms_pre=2000,
+ max_per_img=1000,
+ nms=dict(type='nms', iou_threshold=0.7),
+ min_bbox_size=0)))
diff --git a/configs/mmdet/_base_/models/ssd300.py b/configs/mmdet/_base_/models/ssd300.py
new file mode 100644
index 00000000..f17df010
--- /dev/null
+++ b/configs/mmdet/_base_/models/ssd300.py
@@ -0,0 +1,56 @@
+# model settings
+input_size = 300
+model = dict(
+ type='SingleStageDetector',
+ backbone=dict(
+ type='SSDVGG',
+ depth=16,
+ with_last_pool=False,
+ ceil_mode=True,
+ out_indices=(3, 4),
+ out_feature_indices=(22, 34),
+ init_cfg=dict(
+ type='Pretrained', checkpoint='open-mmlab://vgg16_caffe')),
+ neck=dict(
+ type='SSDNeck',
+ in_channels=(512, 1024),
+ out_channels=(512, 1024, 512, 256, 256, 256),
+ level_strides=(2, 2, 1, 1),
+ level_paddings=(1, 1, 0, 0),
+ l2_norm_scale=20),
+ bbox_head=dict(
+ type='SSDHead',
+ in_channels=(512, 1024, 512, 256, 256, 256),
+ num_classes=80,
+ anchor_generator=dict(
+ type='SSDAnchorGenerator',
+ scale_major=False,
+ input_size=input_size,
+ basesize_ratio_range=(0.15, 0.9),
+ strides=[8, 16, 32, 64, 100, 300],
+ ratios=[[2], [2, 3], [2, 3], [2, 3], [2], [2]]),
+ bbox_coder=dict(
+ type='DeltaXYWHBBoxCoder',
+ target_means=[.0, .0, .0, .0],
+ target_stds=[0.1, 0.1, 0.2, 0.2])),
+ # model training and testing settings
+ train_cfg=dict(
+ assigner=dict(
+ type='MaxIoUAssigner',
+ pos_iou_thr=0.5,
+ neg_iou_thr=0.5,
+ min_pos_iou=0.,
+ ignore_iof_thr=-1,
+ gt_max_assign_all=False),
+ smoothl1_beta=1.,
+ allowed_border=-1,
+ pos_weight=-1,
+ neg_pos_ratio=3,
+ debug=False),
+ test_cfg=dict(
+ nms_pre=1000,
+ nms=dict(type='nms', iou_threshold=0.45),
+ min_bbox_size=0,
+ score_thr=0.02,
+ max_per_img=200))
+cudnn_benchmark = True
diff --git a/configs/mmdet/_base_/schedules/schedule_1x.py b/configs/mmdet/_base_/schedules/schedule_1x.py
new file mode 100644
index 00000000..13b3783c
--- /dev/null
+++ b/configs/mmdet/_base_/schedules/schedule_1x.py
@@ -0,0 +1,11 @@
+# optimizer
+optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[8, 11])
+runner = dict(type='EpochBasedRunner', max_epochs=12)
diff --git a/configs/mmdet/_base_/schedules/schedule_20e.py b/configs/mmdet/_base_/schedules/schedule_20e.py
new file mode 100644
index 00000000..00e85902
--- /dev/null
+++ b/configs/mmdet/_base_/schedules/schedule_20e.py
@@ -0,0 +1,11 @@
+# optimizer
+optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[16, 19])
+runner = dict(type='EpochBasedRunner', max_epochs=20)
diff --git a/configs/mmdet/_base_/schedules/schedule_2x.py b/configs/mmdet/_base_/schedules/schedule_2x.py
new file mode 100644
index 00000000..69dc9ee8
--- /dev/null
+++ b/configs/mmdet/_base_/schedules/schedule_2x.py
@@ -0,0 +1,11 @@
+# optimizer
+optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
+optimizer_config = dict(grad_clip=None)
+# learning policy
+lr_config = dict(
+ policy='step',
+ warmup='linear',
+ warmup_iters=500,
+ warmup_ratio=0.001,
+ step=[16, 22])
+runner = dict(type='EpochBasedRunner', max_epochs=24)
diff --git a/configs/mmdet/albu_example/README.md b/configs/mmdet/albu_example/README.md
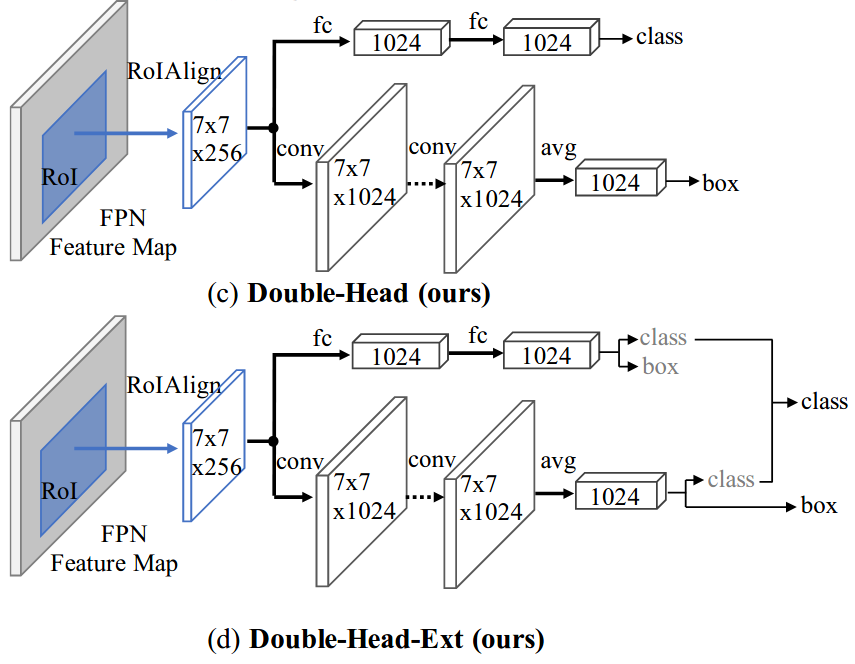
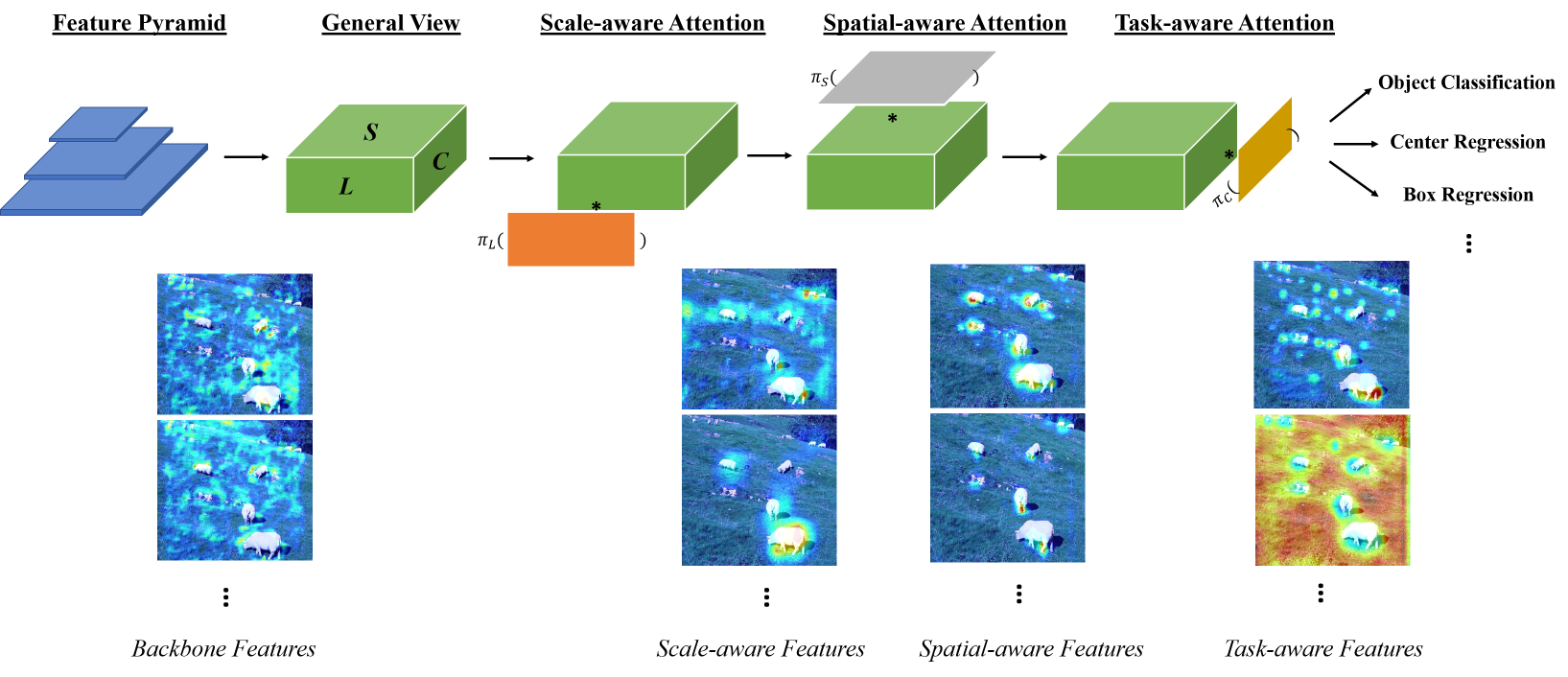
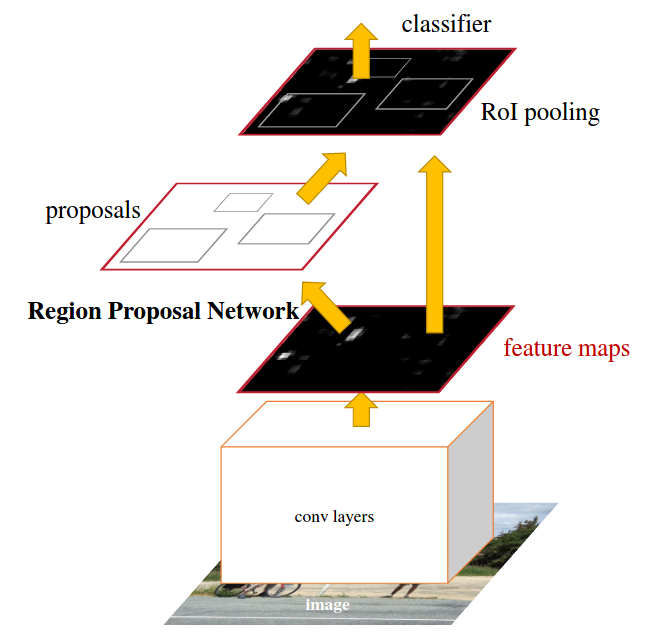
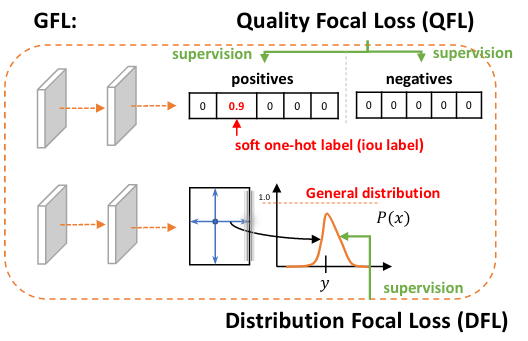
new file mode 100644
index 00000000..49edbf3f
--- /dev/null
+++ b/configs/mmdet/albu_example/README.md
@@ -0,0 +1,31 @@
+# Albu Example
+
+> [Albumentations: fast and flexible image augmentations](https://arxiv.org/abs/1809.06839)
+
+
+
+## Abstract
+
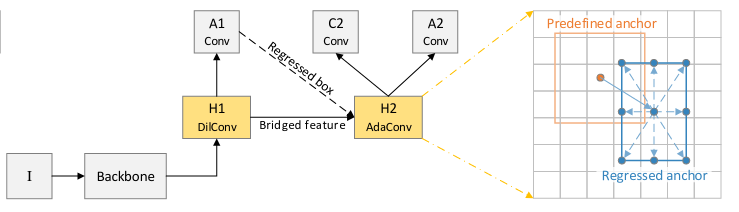
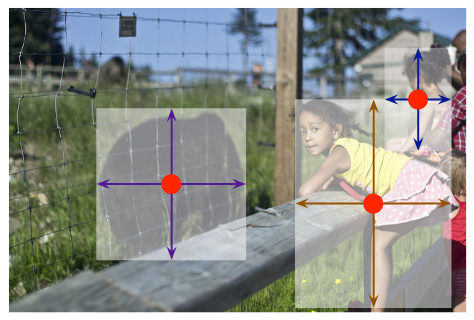
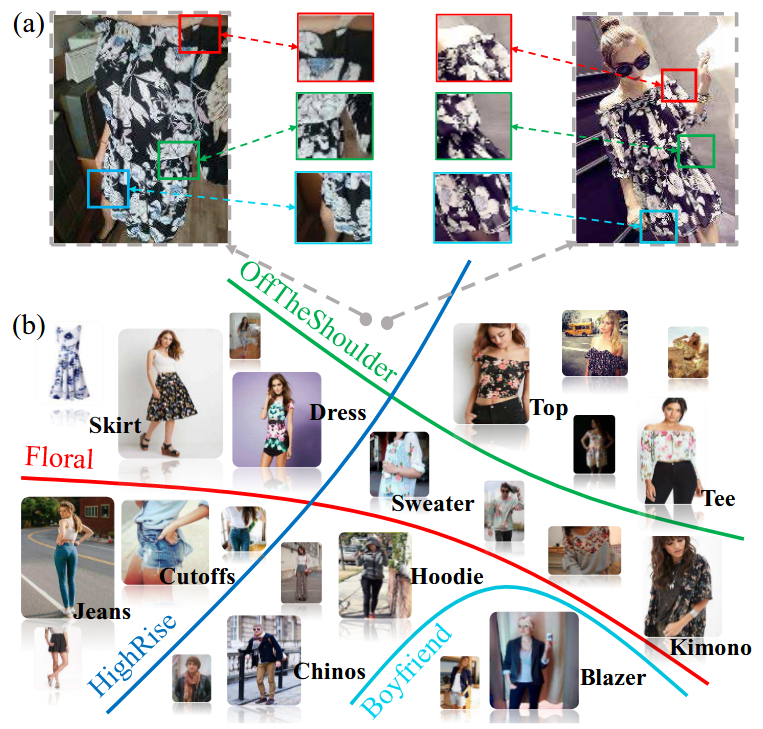
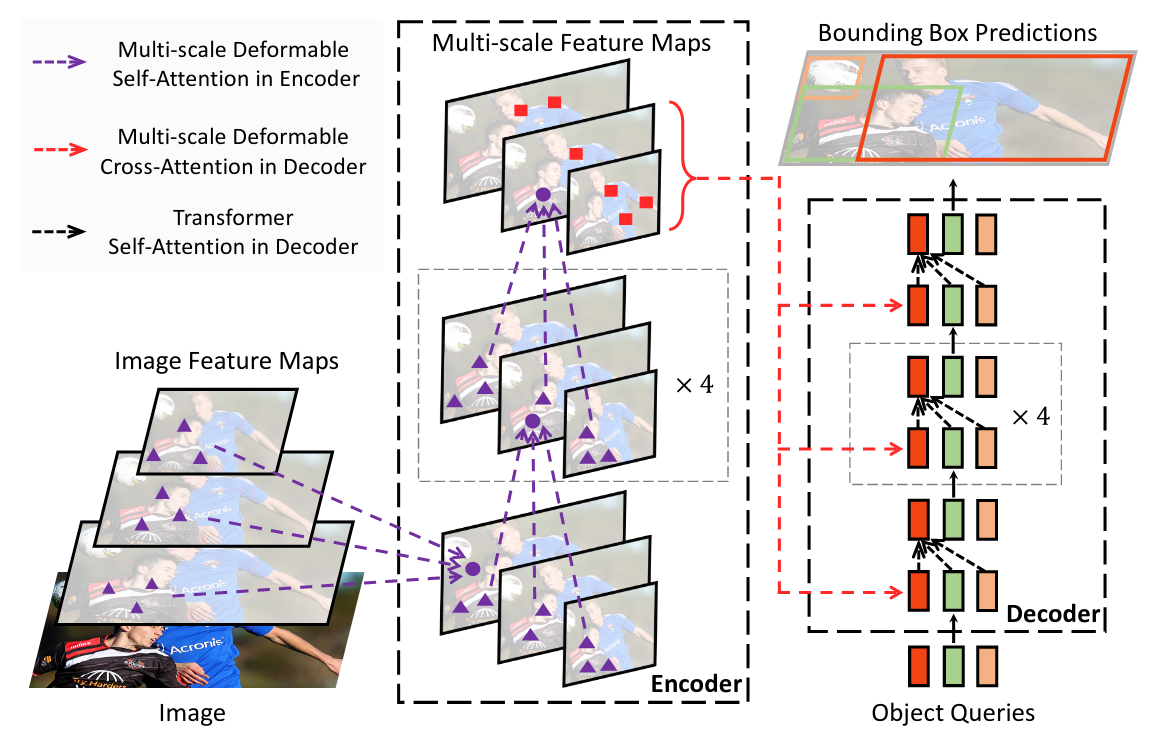
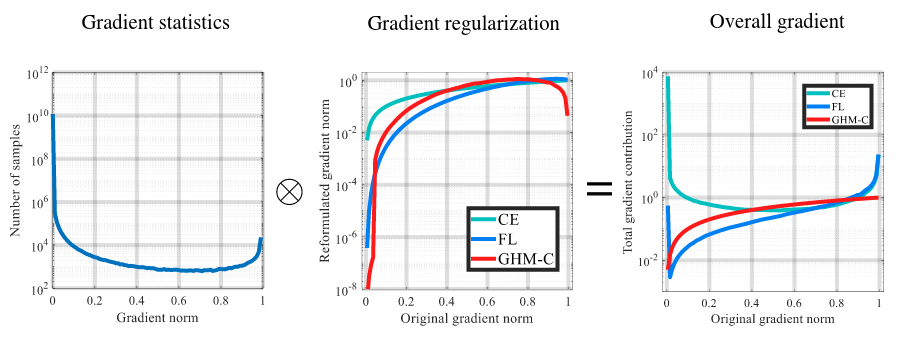
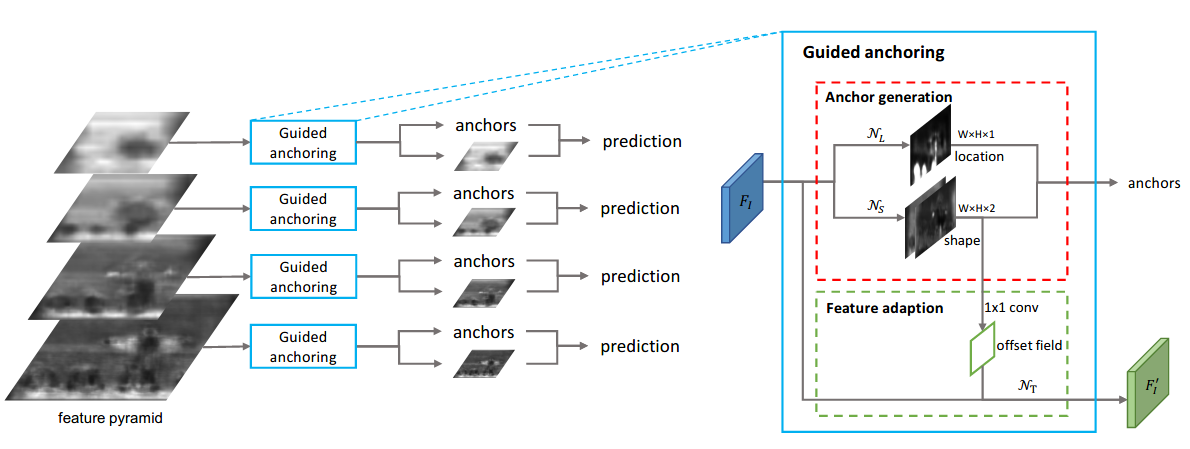
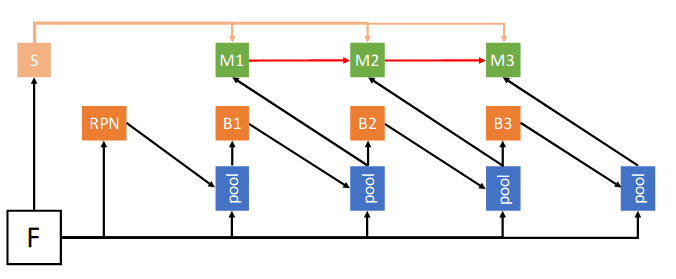
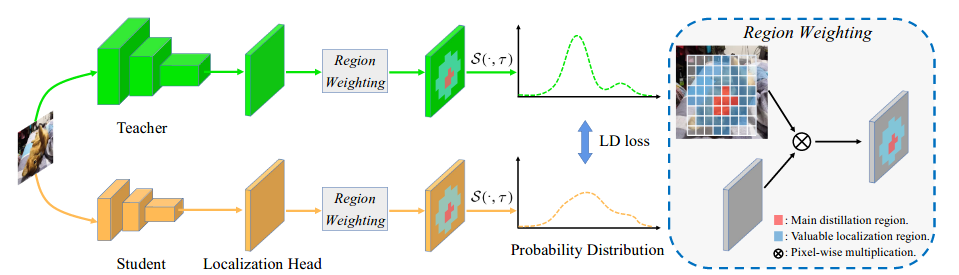
+Data augmentation is a commonly used technique for increasing both the size and the diversity of labeled training sets by leveraging input transformations that preserve output labels. In computer vision domain, image augmentations have become a common implicit regularization technique to combat overfitting in deep convolutional neural networks and are ubiquitously used to improve performance. While most deep learning frameworks implement basic image transformations, the list is typically limited to some variations and combinations of flipping, rotating, scaling, and cropping. Moreover, the image processing speed varies in existing tools for image augmentation. We present Albumentations, a fast and flexible library for image augmentations with many various image transform operations available, that is also an easy-to-use wrapper around other augmentation libraries. We provide examples of image augmentations for different computer vision tasks and show that Albumentations is faster than other commonly used image augmentation tools on the most of commonly used image transformations.
+
+
+

+
+

+
+

+
+

+
+

+
+
+
+
+
+

+
+

+
+

+
+

+
+
+
+
+
+

+
+

+
+
+
+
+
+

+
+

+
+

+
+
+
+

+
+

+
+

+
+

+
+

+
+

+
+
+
+
+
+

+
+

+
+

+
+

+
+
+
+

+
+
+
+

+
+

+
+
+
+

+
+

+
+

+
+
+
+

+
+

+
+

+
+
+
+
+
+

+
+

+
+

+
+

+
+

+
+

+
+

+
+

+
+

+
+

+
+
+
+

+
+

+
+

+
+

+
+

+
+

+
+

+
+

+
+

+
+
+
+

+
+

+
+

+
+

+
+

+
+

+
+

+
+

+
+

+
+

+
+

+
+

+
+
+