模型量化包含三种量化方法,分别是动态离线量化方法、静态离线量化方法和量化训练方法。
下图展示了如何选择模型量化方法。
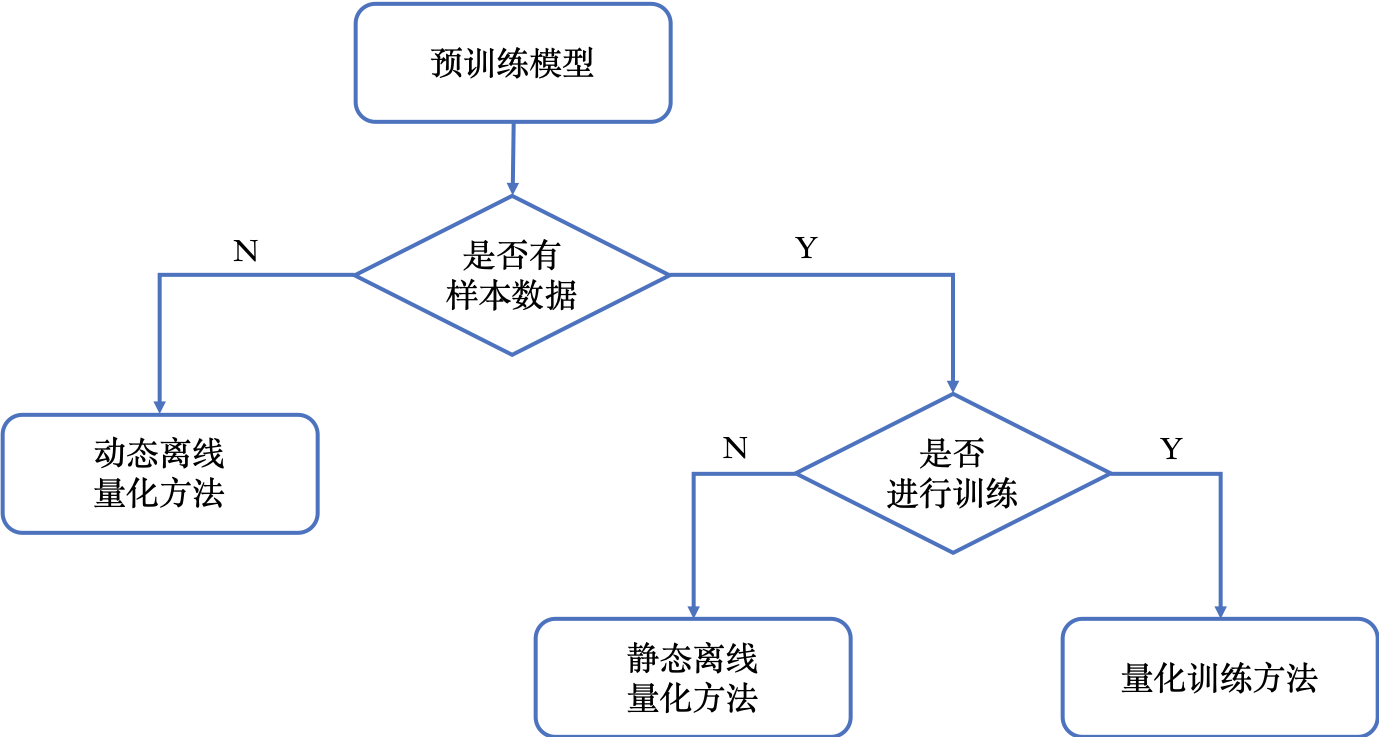
下图综合对比了模型量化方法的使用条件、易用性、精度损失和预期收益。

.. py:class:: paddleslim.QAT(config=None, weight_preprocess=None, act_preprocess=None, weight_quantize=None, act_quantize=None)
使用量化训练方法(Quant Aware Training, QAT)得到模拟量化模型,在需要量化的算子前插入模拟量化节点,为其激活和权重输入提前执行`量化-反量化`逻辑。
参数:
- config(dict, Optional) - 量化配置表。 默认为None,表示使用默认配置, 默认配置参考下方文档。
- weight_preprocess(class, Optional) - 自定义在对权重做量化之前,对权重进行处理的逻辑。这一接口只用于实验不同量化方法,验证量化训练效果。默认为None, 表示不对权重做任何预处理。
- act_preprocess(class, Optional) - 自定义在对激活值做量化之前,对激活值进行处理的逻辑。这一接口只用于实验不同量化方法,验证量化训练效果。默认为None, 表示不对激活值做任何预处理。
- weight_quantize(class, Optional) - 自定义对权重量化的方法。这一接口只用于实验不同量化方法,验证量化训练效果。默认为None, 表示使用默认量化方法。
- act_quantize(class, Optional) - 自定义对激活值量化的方法。这一接口只用于实验不同量化方法,验证量化训练效果。默认为None, 表示使用默认量化方法。
返回: 量化训练器实例。
示例代码:
from paddleslim import QAT
quanter = QAT()量化训练方法的参数配置
{
# weight预处理方法,默认为None,代表不进行预处理;当需要使用`PACT`方法时设置为`"PACT"`
'weight_preprocess_type': None,
# activation预处理方法,默认为None,代表不进行预处理`
'activation_preprocess_type': None,
# weight量化方法, 默认为'channel_wise_abs_max', 此外还支持'abs_max'
'weight_quantize_type': 'channel_wise_abs_max',
# activation量化方法, 默认为'moving_average_abs_max'
'activation_quantize_type': 'moving_average_abs_max',
# weight量化比特数, 默认为 8
'weight_bits': 8,
# activation量化比特数, 默认为 8
'activation_bits': 8,
# 'moving_average_abs_max'的滑动平均超参, 默认为0.9
'moving_rate': 0.9,
# 需要量化的算子类型
'quantizable_layer_type': ['Conv2D', 'Linear'],
# 是否需要融合Conv + BN
'fuse_conv_bn': False,
}.. py:method:: quantize(model)inplace地对模型进行量化训练前的处理,插入量化-反量化节点。
参数:
- model(paddle.nn.Layer) - 一个paddle Layer的实例,需要包含支持量化的算子,如:Conv, Linear
示例:
import paddle from paddle.vision.models import mobilenet_v1 from paddleslim import QAT net = mobilenet_v1(pretrained=False) quant_config = { 'activation_preprocess_type': 'PACT', 'quantizable_layer_type': ['Conv2D', 'Linear'], } quanter = QAT(config=quant_config) quanter.quantize(net) paddle.summary(net, (1, 3, 224, 224)).. py:method:: save_quantized_model(model, path, input_spec=None)将指定的动态图量化模型导出为静态图预测模型,用于预测部署。
量化预测模型可以使用`VisualDL`软件打开,进行可视化查看。该量化预测模型和普通FP32预测模型一样,可以使用PaddleLite和PaddleInference加载预测,具体请参考`推理部署`章节。
参数:
- model(paddle.nn.Layer) - 量化训练结束,需要导出的量化模型,该模型由`quantize`接口产出。
- path(str) - 导出的量化预测模型保存的路径,导出后在该路径下可以找到`model`和`params`文件。
- input_spec(list[InputSpec|Tensor], Optional) - 描述存储模型forward方法的输入,可以通过InputSpec或者示例Tensor进行描述。如果为 None ,所有原 Layer forward方法的输入变量将都会被配置为存储模型的输入变量。默认为 None。
示例:
import paddle from paddle.vision.models import mobilenet_v1 from paddleslim import QAT net = mobilenet_v1(pretrained=False) quant_config = { 'activation_preprocess_type': 'PACT', 'quantizable_layer_type': ['Conv2D', 'Linear'], } quanter = QAT(config=quant_config) quanter.quantize(net) paddle.summary(net, (1, 3, 224, 224)) quanter.save_quantized_model( net, './quant_model', input_spec=[paddle.static.InputSpec(shape=[None, 3, 224, 224], dtype='float32')])
.. py:class:: paddleslim.PTQ(activation_quantizer='KLQuantizer', weight_quantizer='PerChannelAbsmaxQuantizer', **kwargs)
参数:
- activation_quantizer(str, Optional) - 激活量化方式。 可选择`KLQuantizer`、HistQuantizer`和`AbsmaxQuantizer,默认为`KLQuantizer`。
- weight_quantizer(str, Optional) - 激活量化方式。 可选择`AbsmaxQuantizer`和`PerChannelAbsmaxQuantizer`,默认为`PerChannelAbsmaxQuantizer`。
返回: 离线量化器实例。
KLQuantizer参数: - **quant_bits(int): ** - 量化比特数,默认是8。 - **bins(int): ** - 指定统计的区间个数,默认是1024。 - **upsample_bins(int): ** - 上采样统计的区间个数,默认是64。
HistQuantizer参数: - **quant_bits(int): ** - 量化比特数,默认是8。 - **bins(int): ** - 指定统计的区间个数,默认是1024。 - **upsample_bins(int): ** - 上采样统计的区间个数,默认是64。 - **hist_percent(float): ** - 采样百分比,默认是0.99999。
AbsmaxQuantizer参数: - **quant_bits(int): ** - 量化比特数,默认是8。
示例代码:
from paddleslim import PTQ
ptq = PTQ()如果想要更改离线量化默认配置,可以给PTQ()传入dict,例如下面所示:
from paddleslim import PTQ
ptq_config = {'activation_quantizer': 'HistQuantizer', 'upsample_bins': 127, 'hist_percent': 0.999}
ptq = PTQ(**ptq_config).. py:method:: quantize(model, fuse=False, fuse_list=None)对模型进行离线量化的处理,插入量化-反量化节点。
参数:
- model(paddle.nn.Layer) - 一个paddle Layer的实例,需要包含支持量化的算子,如:Conv, Linear。
- fuse(bool) - 是否对模型进行fuse融合,默认是False。
- fuse_list(list) - 如果对模型进行fuse融合,需要在fuse_list中添加需要fuse的层,默认是None。
示例代码:
如果需要对模型进行fuse融合,可根据如下方式增加`fuse_list`,目前支持`Conv2D`和`BatchNorm2D`的融合,fuse后的模型更小,推理可能更快,精度持平或可能降低。
- fuse_list = []
- for name, layer in fp32_model.named_sublayers():
- if isinstance(layer, nn.Conv2D):
- fuse_list.append([name])
- if isinstance(layer, nn.BatchNorm2D):
- fuse_list[count].append(name)
quant_model = ptq.quantize(fp32_model, fuse=True, fuse_list=fuse_list)
.. py:method:: save_quantized_model(model, path, input_spec=None)将指定的动态图量化模型导出为静态图预测模型,用于预测部署。
量化预测模型可以使用`VisualDL`软件打开,进行可视化查看。该量化预测模型和普通FP32预测模型一样,可以使用PaddleLite和PaddleInference加载预测,具体请参考`推理部署`章节。
参数:
- model(paddle.nn.Layer) - 量化训练结束,需要导出的量化模型,该模型由`quantize`接口产出。
- path(str) - 导出的量化预测模型保存的路径,导出后在该路径下可以找到`model`和`params`文件。
- input_spec(list[InputSpec|Tensor], Optional) - 描述存储模型forward方法的输入,可以通过InputSpec或者示例Tensor进行描述。如果为 None ,所有原 Layer forward方法的输入变量将都会被配置为存储模型的输入变量。默认为 None。
示例:
import paddle from paddleslim import PTQ from paddle.vision.models import mobilenet_v1 fp32_model = mobilenet_v1(pretrained=True) ptq = PTQ() quant_model = ptq.quantize(fp32_model) ptq.save_quantized_model( quant_model, './quant_model', input_spec=[paddle.static.InputSpec(shape=[None, 3, 224, 224], dtype='float32')])
动态离线量化接口请参考`quant_post_dynamic`API。