diff --git a/_assets/blog/2021-08-sharks/notebook.jl b/_assets/blog/2021-08-sharks/notebook.jl
index 4c25b18d6c..3bf7e6b6b5 100644
--- a/_assets/blog/2021-08-sharks/notebook.jl
+++ b/_assets/blog/2021-08-sharks/notebook.jl
@@ -81,7 +81,7 @@ end
# ╔═╡ d830e69e-f085-495e-be2c-8ea44582fa20
md"""
Looking at [videos of swimming dogfish](https://youtu.be/nMa6lD2CQVI?t=200), we can see a couple general features
- - The motion of the front half of the body has a small amplitude (around 20% of the tail). This sets the amplitude evelope for the traveling wave.
+ - The motion of the front half of the body has a small amplitude (around 20% of the tail). This sets the amplitude envelope for the traveling wave.
"""
# ╔═╡ c2b7a082-c05d-41bb-af4c-eb23f6a331bf
@@ -264,7 +264,7 @@ We can learn a lot from this simple plot. For example, the side-to-side force ha
This simple model is a great start and it opens up a ton of avenues for improving the shark simulation and suggesting research questions:
- The instantaneous net forces should be zero in a free swimming body! We could add reaction motions to our model to achieve this. Would the model shark swim in a straight line if we did this, or is a control-loop needed?
- Real sharks are 3D (gasp!). While we could easily extend this approach using 2D splines, it will take much longer to simulate. Is there a way use GPUs to accelerate the simulations without completely changing the solver?
- - If we were going to make a bio-inspired robot of this shark, we will have constraints on the shape and motion and powering available. Can we use this framework to help optimize our robotic within it's contraints?
+ - If we were going to make a bio-inspired robot of this shark, we will have constraints on the shape and motion and powering available. Can we use this framework to help optimize our robotic within it's constraints?
Below you can find links to all the packages used in this notebook. Happy Simulating!
diff --git a/_assets/blog/moredots/More-Dots.ipynb b/_assets/blog/moredots/More-Dots.ipynb
index 1f03195e9f..02b0b93c6c 100644
--- a/_assets/blog/moredots/More-Dots.ipynb
+++ b/_assets/blog/moredots/More-Dots.ipynb
@@ -248,7 +248,7 @@
"source": [
"function vec_prealloc!(X, TWELVE_TEMP_ARRAYS)\n",
" T1,T2,T3,T4,T5,T6,T7,T8,T9,T10,T11,T12 = TWELVE_TEMP_ARRAYS\n",
- " \n",
+ "\n",
" # evaluate T7 = 2X.^2 + 6X.^3 - sqrt.(X):\n",
" T1 .= X.^2\n",
" T2 .= 2 .* T1\n",
@@ -257,14 +257,14 @@
" T5 .= T2 .+ T4\n",
" T6 .= sqrt.(X)\n",
" T7 .= T5 .- T6\n",
- " \n",
+ "\n",
" # evaluate T12 = f(T7):\n",
" T8 .= T7.^2\n",
" T9 .= 3 .* T8\n",
" T10 .= 5 .* T7\n",
" T11 .= T9 .+ T10\n",
" T12 .= T11 .+ 2\n",
- " \n",
+ "\n",
" # store result in X\n",
" X .= T12\n",
" return X\n",
@@ -488,7 +488,7 @@
"\n",
"* Even if you eliminate the cost of allocation and garbage collection, in the pre-allocated version of the traditionally vectorized code (`vec_pre`), it is still much slower than the devectorized code. This is especially true for very small vectors (due to the cost of setting up all of the little loops) and very large vectors (which don't fit into cache, and hence the cache misses induced by the non-fused loops are expensive).\n",
"\n",
- "* The new-style \"dot-vectorized code\" (`newvec`) is mostly within 10% of the cost of the devectorized loop. The worst case is that of length-1 arrays, where the overhead of the `broadcast` bookkeeping is noticable, but even then it is only a 30% penalty."
+ "* The new-style \"dot-vectorized code\" (`newvec`) is mostly within 10% of the cost of the devectorized loop. The worst case is that of length-1 arrays, where the overhead of the `broadcast` bookkeeping is noticeable, but even then it is only a 30% penalty."
]
},
{
diff --git a/_rss/head.xml b/_rss/head.xml
index 4c9f62b128..36e53ba941 100644
--- a/_rss/head.xml
+++ b/_rss/head.xml
@@ -8,7 +8,7 @@ For instance 'website_url' or 'website_description'.
Notes:
* namespaces (xmlns): https://validator.w3.org/feed/docs/howto/declare_namespaces.html
* best practices: https://www.rssboard.org/rss-profile
-* fd2rss convers markdown to html and fixes or removes relative links
+* fd2rss converts markdown to html and fixes or removes relative links
* fd_rss_feed_url is built out of {website_url}/{rss_file}.xml, you can change the
rss_file variable in your config file if you want to use something different than 'feed'
-->
diff --git a/blog/2013/04/distributed-numerical-optimization.md b/blog/2013/04/distributed-numerical-optimization.md
index da117e90a4..2a40bcb923 100644
--- a/blog/2013/04/distributed-numerical-optimization.md
+++ b/blog/2013/04/distributed-numerical-optimization.md
@@ -2,7 +2,7 @@
@def rss = """ Distributed Numerical Optimization | This post walks through the parallel computing functionality of Julia... """
@def published = "5 April 2013"
@def title = "Distributed Numerical Optimization"
-@def authors = """Miles Lubin"""
+@def authors = """Miles Lubin"""
@def hascode = true
@def hasmath = true
@@ -134,7 +134,7 @@ macro creates a [task](https://docs.julialang.org/en/latest/manual/control-flow/
on the *master process* (e.g. process 1). Each task feeds work to a
corresponding worker; the call `remotecall_fetch(p, f, lst[idx])` function
calls `f` on process `p` and returns the result when finished. Tasks are
-uninterruptable and only surrender control at specific points such as
+uninterruptible and only surrender control at specific points such as
`remotecall_fetch`. Tasks cannot directly modify variables from the enclosing
scope, but the same effect can be achieved by using the `next_idx` function to
access and mutate `i`. *The task idiom functions in place of using a loop to
diff --git a/blog/2013/05/graphical-user-interfaces-part1.md b/blog/2013/05/graphical-user-interfaces-part1.md
index f2dbaea3a3..a88a90fb3e 100644
--- a/blog/2013/05/graphical-user-interfaces-part1.md
+++ b/blog/2013/05/graphical-user-interfaces-part1.md
@@ -2,7 +2,7 @@
@def rss = """ Building GUIs with Julia, Tk, and Cairo, Part I | This is the first of two blog posts designed to walk users through the process of creating GUIs in Julia.... """
@def published = "23 May 2013"
@def title = "Building GUIs with Julia, Tk, and Cairo, Part I"
-@def authors = """ Timothy E. Holy"""
+@def authors = """ Timothy E. Holy"""
@def hascode = true
This is the first of two blog posts designed to walk users through the process of creating GUIs in Julia.
@@ -354,7 +354,7 @@ bind(ctrls.playback, "command", path -> playt(-1, ctrls, state, showframe)
```
The `path` input is generated by Tk/Tcl, but we don't have to use it.
-Instead, we use anonymous functions to pass the arguments relavant to this particular GUI instantiation.
+Instead, we use anonymous functions to pass the arguments relevant to this particular GUI instantiation.
Note that these two buttons share `state`; that means that any changes made by one callback will have impact on the other.
#### Placing the buttons in the frame (layout management)
diff --git a/blog/2013/09/fast-numeric.md b/blog/2013/09/fast-numeric.md
index 5da4de1d9c..488d4f6877 100644
--- a/blog/2013/09/fast-numeric.md
+++ b/blog/2013/09/fast-numeric.md
@@ -2,7 +2,7 @@
@def rss = """ Fast Numeric Computation in Julia | Working on numerical problems daily, I have always dreamt of a language that provides an elegant interface while allowing me to write codes that run blazingly fast on large data sets. Julia is a language that turns this dream into a reality.... """
@def published = "4 September 2013"
@def title = "Fast Numeric Computation in Julia"
-@def authors = """Dahua Lin"""
+@def authors = """Dahua Lin"""
@def hascode = true
@@ -74,7 +74,7 @@ for i = 1:length(x)
end
```
-This version finishes the computation in one pass, without introducing any temporary arrays. Moreover, if `r` is pre-allocated, one can even omit the statment that creates `r`. The [*Devectorize.jl*](https://github.com/lindahua/Devectorize.jl) package provides a macro ``@devec`` that can automatically translate vectorized expressions into loops:
+This version finishes the computation in one pass, without introducing any temporary arrays. Moreover, if `r` is pre-allocated, one can even omit the statement that creates `r`. The [*Devectorize.jl*](https://github.com/lindahua/Devectorize.jl) package provides a macro ``@devec`` that can automatically translate vectorized expressions into loops:
```julia
using Devectorize
@@ -147,7 +147,7 @@ for i = 1:m
end
```
-The loop here accesses the elements row-by-row, as `a[i,1], a[i,2], ..., a[i,n]`. The interval between these elements is `m`. Intuitively, it jumps at the stride of length `m` from the begining of each row to the end in each inner loop, and then jumps back to the begining of next row. This is not very efficient, especially when `m` is large.
+The loop here accesses the elements row-by-row, as `a[i,1], a[i,2], ..., a[i,n]`. The interval between these elements is `m`. Intuitively, it jumps at the stride of length `m` from the beginning of each row to the end in each inner loop, and then jumps back to the beginning of next row. This is not very efficient, especially when `m` is large.
This procedure can be made much more cache-friendly by changing the order of computation:
diff --git a/blog/2015/10/compose3d-threejs.md b/blog/2015/10/compose3d-threejs.md
index 68fc3448d0..0ccc2f65c0 100644
--- a/blog/2015/10/compose3d-threejs.md
+++ b/blog/2015/10/compose3d-threejs.md
@@ -2,7 +2,7 @@
@def rss = """ JSoC 2015 project: Interactive 3D Graphics in the Browser with Compose3D | Over the last three months, I've been working on Compose3D (https://github.com/rohitvarkey/Compose3D.jl),... """
@def published = "20 October 2015"
@def title = "JSoC 2015 project: Interactive 3D Graphics in the Browser with Compose3D"
-@def authors = """Rohit Varkey Thankachan"""
+@def authors = """Rohit Varkey Thankachan"""
@def hascode = true
@@ -48,7 +48,7 @@ helping performance.
On the other hand, web components introduced issues with IJulia notebooks regarding serving the files required by
ThreeJS. I'm still working on finding a good solution for this problem, but for now, a hack gets ThreeJS working in
-IJulia, albiet with some limitations.
+IJulia, albeit with some limitations.
### Drawing stuff!
diff --git a/blog/2016/02/iteration.md b/blog/2016/02/iteration.md
index e2f7b99a66..2f44bbe538 100644
--- a/blog/2016/02/iteration.md
+++ b/blog/2016/02/iteration.md
@@ -300,7 +300,7 @@ end
Obviously, this simple implementation skips all relevant error
checking. However, here the main point I wish to explore is that the
allocation of `B` turns out to be
-[non-inferrable](https://docs.julialang.org/en/latest/manual/faq/#man-type-stability-1):
+[non-inferable](https://docs.julialang.org/en/latest/manual/faq/#man-type-stability-1):
`sz` is a `Vector{Int}`, the length (number of elements) of a specific
`Vector{Int}` is not encoded by the type itself, and therefore the
dimensionality of `B` cannot be inferred.
@@ -312,7 +312,7 @@ result:
B = Array{eltype(A)}(undef, sz...)::Array{eltype(A),ndims(A)}
```
-or by using an implementation that *is* inferrable:
+or by using an implementation that *is* inferable:
```
function sumalongdims(A, dims)
@@ -464,7 +464,7 @@ julia> Tuple(I) .+ 1
If desired you can package this back up in a `CartesianIndex`, or just
use it directly (with splatting) for indexing.
The compiler optimizes all these operations away, so there is no actual
-"cost" to constucting objects in this way.
+"cost" to constructing objects in this way.
Why is iteration disallowed? One reason is to support the following:
diff --git a/blog/2016/03/arrays-iteration.md b/blog/2016/03/arrays-iteration.md
index 43854707bd..7a38ba19df 100644
--- a/blog/2016/03/arrays-iteration.md
+++ b/blog/2016/03/arrays-iteration.md
@@ -2,7 +2,7 @@
@def rss = """ Generalizing AbstractArrays: opportunities and challenges | Somewhat unusually, this blog post is future-looking: it mostly... """
@def published = "27 March 2016"
@def title = "Generalizing AbstractArrays: opportunities and challenges"
-@def authors = """ Tim Holy"""
+@def authors = """ Tim Holy"""
@def hascode = true
@@ -362,7 +362,7 @@ These examples suggest a formalization of `AbstractArray`:
Resolving these conflicting demands is not easy. One approach might be
to decree that some of these array types simply can't be supported
with generic code. It is possible that this is the right
-strategy. Alternatively, one can attept to devise an array API that
+strategy. Alternatively, one can attempt to devise an array API that
handles all of these types (and hopefully more).
In GitHub issue
diff --git a/blog/2016/04/biojulia2016.md b/blog/2016/04/biojulia2016.md
index 2f4d67bcb3..9901850c90 100644
--- a/blog/2016/04/biojulia2016.md
+++ b/blog/2016/04/biojulia2016.md
@@ -2,7 +2,7 @@
@def rss = """ BioJulia Project in 2016 | I am pleased to announce that the next phase of BioJulia is starting! In the next several months, I'm going to implement many crucial features for bioinformatics that will motivate you to use Julia and BioJulia libraries in your work. But before going to the details of the project, let me briefly int... """
@def published = "30 April 2016"
@def title = "BioJulia Project in 2016"
-@def authors = "Kenta Sato"
+@def authors = "Kenta Sato"
I am pleased to announce that the next phase of BioJulia is starting! In the next several months, I'm going to implement many crucial features for bioinformatics that will motivate you to use Julia and BioJulia libraries in your work. But before going to the details of the project, let me briefly introduce you what the BioJulia project is. This project is supported by the Moore Foundation and the Julia project.
diff --git a/blog/2016/08/GSoC2016-Graft.md b/blog/2016/08/GSoC2016-Graft.md
index 69885e3cae..a1b1ddbe8d 100644
--- a/blog/2016/08/GSoC2016-Graft.md
+++ b/blog/2016/08/GSoC2016-Graft.md
@@ -74,7 +74,7 @@ Dict(
)
```
-Cleary, using labels internally is a very bad idea. Any sort of data access would set off multiple dictionary look-ups. Instead, if a bidirectional map
+Clearly, using labels internally is a very bad idea. Any sort of data access would set off multiple dictionary look-ups. Instead, if a bidirectional map
could be used to translate labels into vertex identifiers and back, the number of dictionary lookups could be reduced to one. The data would also be better structured for query processing.
```
diff --git a/blog/2016/08/announcing-support-for-complex-domain-linear-programs-in-Convex.jl.md b/blog/2016/08/announcing-support-for-complex-domain-linear-programs-in-Convex.jl.md
index 11aaf40b1a..fe61a5fcd9 100644
--- a/blog/2016/08/announcing-support-for-complex-domain-linear-programs-in-Convex.jl.md
+++ b/blog/2016/08/announcing-support-for-complex-domain-linear-programs-in-Convex.jl.md
@@ -2,7 +2,7 @@
@def rss = """ Announcing support for complex-domain linear programs in Convex.jl | I am pleased to announce the support for complex-domain linear programs (LPs) in Convex.jl. As one of the *Google Summer of Code* students under *The Julia Language*, I had proposed to implement the support for complex semidefinite programming. In the first phase of project, I started by tackling the... """
@def published = "17 August 2016"
@def title = "Announcing support for complex-domain linear programs in Convex.jl"
-@def authors = "Ayush Pandey"
+@def authors = "Ayush Pandey"
@def hascode = true
@@ -69,7 +69,7 @@ x1== xr.value + im*xi.value # should return true
List of all the affine atoms are as follows:
-1. addition, substraction, multiplication, division
+1. addition, subtraction, multiplication, division
2. indexing and slicing
3. k-th diagonal of a matrix
4. construct diagonal matrix
diff --git a/blog/2017/01/moredots.md b/blog/2017/01/moredots.md
index fe2ff39235..cdba231d10 100644
--- a/blog/2017/01/moredots.md
+++ b/blog/2017/01/moredots.md
@@ -2,7 +2,7 @@
@def rss = """ More Dots: Syntactic Loop Fusion in Julia | After a lengthy design process (https://github.com/JuliaLang/julia/issues/8450) and preliminary foundations in Julia 0.5 (/blog/2016-10-11-julia-0.5-highlights#vectorized_function_calls), Julia 0.6 includes new facilities for writing code in the "vectorized"... """
@def published = "21 January 2017"
@def title = "More Dots: Syntactic Loop Fusion in Julia"
-@def authors = """ Steven G. Johnson"""
+@def authors = """ Steven G. Johnson"""
@def hascode = true
@@ -73,7 +73,7 @@ tasks (e.g. string processing).
To explore this question (also discussed
[in this blog post](https://www.johnmyleswhite.com/notebook/2013/12/22/the-relationship-between-vectorized-and-devectorized-code/)), let's begin by rewriting the code above in a more traditional vectorized style, without
so many dots, such as you might use in Julia 0.4 or in other languages
-(most famously Matlab, Python/Numpy, or R).
+(most famously Matlab, Python/Numpy, or R).
```julia
X = f(2 * X.^2 + 6 * X.^3 - sqrt(X))
@@ -126,7 +126,7 @@ allowing you to *combine arrays and scalars or arrays of different shapes/dimens
has its own unique capabilities.)
From the standpoint of the programmer, this adds a certain amount of
clarity because it indicates explicitly when an elementwise operation
-is occuring. From the standpoint of the compiler, dot-call syntax
+is occurring. From the standpoint of the compiler, dot-call syntax
enables the *syntactic loop fusion* optimization described in more detail
below, which we think is an overwhelming advantage of this style.
@@ -528,8 +528,8 @@ julia> s = ["The QUICK Brown", "fox jumped", "over the LAZY dog."];
julia> s .= replace.(lowercase.(s), r"\s+", "-")
3-element Array{String,1}:
- "the-quick-brown"
- "fox-jumped"
+ "the-quick-brown"
+ "fox-jumped"
"over-the-lazy-dog."
```
diff --git a/blog/2017/03/piday.md b/blog/2017/03/piday.md
index 89702e5d4f..78e0bd5bf4 100644
--- a/blog/2017/03/piday.md
+++ b/blog/2017/03/piday.md
@@ -2,7 +2,7 @@
@def rss = """ Some fun with π in Julia | !pi (/assets/blog/2017-03-14-piday/pi.png) ^credit ... """
@def published = "14 March 2017"
@def title = "Some fun with Π in Julia"
-@def authors = "Simon Byrne, Luis Benet and David Sanders"
+@def authors = "Simon Byrne, Luis Benet and David Sanders"
@def hasmath = true
@def hascode = true
@@ -258,7 +258,7 @@ The idea is to split $S$ up into two parts, $S = S_N + T_N$, where
$ S_N := \sum_{n=1}^N \frac{1}{n^2}$ contains the first $N$ terms,
and $T_N := S - S_N = \sum_{n=N+1}^\infty \frac{1}{n^2}$ contains the rest (an infinite number of terms).
-We will evalute $S_N$ numerically, and use the following analytical bound for $T_N$:
+We will evaluate $S_N$ numerically, and use the following analytical bound for $T_N$:
$$\frac{1}{N+1} \le T_N \le \frac{1}{N}$$.
@@ -590,16 +590,16 @@ end
intervals = make_intervals()
10-element Array{ValidatedNumerics.Interval{Float64},1}:
- Interval(0.0, 0.2)
- Interval(0.19999999999999998, 0.4)
+ Interval(0.0, 0.2)
+ Interval(0.19999999999999998, 0.4)
Interval(0.39999999999999997, 0.6000000000000001)
- Interval(0.6, 0.8)
- Interval(0.7999999999999999, 1.0)
- Interval(1.0, 1.2000000000000002)
- Interval(1.2, 1.4000000000000001)
- Interval(1.4, 1.6)
- Interval(1.5999999999999999, 1.8)
- Interval(1.7999999999999998, 2.0)
+ Interval(0.6, 0.8)
+ Interval(0.7999999999999999, 1.0)
+ Interval(1.0, 1.2000000000000002)
+ Interval(1.2, 1.4000000000000001)
+ Interval(1.4, 1.6)
+ Interval(1.5999999999999999, 1.8)
+ Interval(1.7999999999999998, 2.0)
```
Given one of those intervals, we evaluate the function of interest:
diff --git a/blog/2017/08/native-julia-implementations-of-iterative-solvers-for-numerical-linear-algebra.md b/blog/2017/08/native-julia-implementations-of-iterative-solvers-for-numerical-linear-algebra.md
index 54256b8402..d7db9070a2 100644
--- a/blog/2017/08/native-julia-implementations-of-iterative-solvers-for-numerical-linear-algebra.md
+++ b/blog/2017/08/native-julia-implementations-of-iterative-solvers-for-numerical-linear-algebra.md
@@ -2,7 +2,7 @@
@def rss = """ GSoC 2017: Implementing iterative solvers for numerical linear algebra | The central part of my GSoC project is about implementing the Jacobi-Davidson method natively in Julia, available in JacobiDavidson.jl (https://github.com/haampie/JacobiDavidson.jl). This method computes a few approximate solutions of the eigenvalue problem Ax = lambda Bx for large and sparse mat... """
@def published = "23 August 2017"
@def title = "GSoC 2017: Implementing iterative solvers for numerical linear algebra"
-@def authors = "Harmen Stoppels, Andreas Noack"
+@def authors = "Harmen Stoppels, Andreas Noack"
@def hasmath = true
@def hascode = true
@@ -112,7 +112,7 @@ It does not yet detect 50003, but that might happen when `pairs` is increased a

-It's not easy to construct a preconditioner this good for any given problem, but usually people tend to know what works well in specific classes of problems. If no specific preconditioner is availabe, you can always try a general one such as ILU. The next section illustrates that.
+It's not easy to construct a preconditioner this good for any given problem, but usually people tend to know what works well in specific classes of problems. If no specific preconditioner is available, you can always try a general one such as ILU. The next section illustrates that.
### ILU example
As an example of how ILU can be used we generate a non-symmetric, banded matrix having a structure that typically arises in finite differences schemes of three-dimensional problems:
diff --git a/blog/2017/09/Hamiltonian-Indirect-Inference.md b/blog/2017/09/Hamiltonian-Indirect-Inference.md
index 943f35cfb9..eeb94cfa84 100644
--- a/blog/2017/09/Hamiltonian-Indirect-Inference.md
+++ b/blog/2017/09/Hamiltonian-Indirect-Inference.md
@@ -2,7 +2,7 @@
@def rss = """ GSoC 2017 Project: Hamiltonian Indirect Inference | This is a writeup of my project for the Google Summer of Code 2017. The... """
@def published = "19 September 2017"
@def title = "GSoC 2017 Project: Hamiltonian Indirect Inference"
-@def authors = "Dorisz Albrecht"
+@def authors = "Dorisz Albrecht"
@def hasmath = true
@def hascode = true
@@ -50,7 +50,7 @@ The novelty of this project was to find a way to fit every component together in
After the second stage, I coded economic models for the [DynamicHMC.jl](https://github.com/tpapp/DynamicHMC.jl). The Stochastic Volatility model is one of them. In the following section, I will go through the set up.
-The continuous-time version of the Ornstein-Ulenbeck Stochastic - volatiltiy model describes how the return at time t has mean zero and its volatility is governed by a continuous-time Ornstein-Ulenbeck process of its variance. The big fluctuation of the value of a financial product imply a varying volatility process. That is why we need stochastic elements in the model. As we can access data only in discrete time, it is natural to take the discretization of the model.
+The continuous-time version of the Ornstein-Ulenbeck Stochastic - volatility model describes how the return at time t has mean zero and its volatility is governed by a continuous-time Ornstein-Ulenbeck process of its variance. The big fluctuation of the value of a financial product imply a varying volatility process. That is why we need stochastic elements in the model. As we can access data only in discrete time, it is natural to take the discretization of the model.
The discrete-time version of the Ornstein-Ulenbeck Stochastic - volatility model:
diff --git a/blog/2017/09/gsoc-derivative_operators.md b/blog/2017/09/gsoc-derivative_operators.md
index 95ab17aaf7..11bfa482fb 100644
--- a/blog/2017/09/gsoc-derivative_operators.md
+++ b/blog/2017/09/gsoc-derivative_operators.md
@@ -2,12 +2,12 @@
@def rss = """ GSoC 2017: Efficient Discretizations of PDE Operators | This project is an attempt towards building a PDE solver for JuliaDiffEq using the Finite Difference Method (https://en.wikipedia.org/wiki/Finite_difference_method)(FDM) approach. We take up the FDM approach instead of FEM (https://en.wikipedia.org/wiki/Finite_element_method) and FVM (https://en.w... """
@def published = "6 September 2017"
@def title = "GSoC 2017: Efficient Discretizations of PDE Operators"
-@def authors = """Shivin Srivastava, Christopher Rackauckas"""
+@def authors = """Shivin Srivastava, Christopher Rackauckas"""
@def hasmath = true
@def hascode = true
-This project is an attempt towards building a PDE solver for JuliaDiffEq using the [Finite Difference Method](https://en.wikipedia.org/wiki/Finite_difference_method)(FDM) approach. We take up the FDM approach instead of [FEM](https://en.wikipedia.org/wiki/Finite_element_method) and [FVM](https://en.wikipedia.org/wiki/Finite_volume_method) as there are many toolboxes which already exist for FEM and FVM but not for FDM. Also, there are many use cases where the geometry of the problem is simple enough to be solved by FDM methods which are much faster due to their being able to avoid the bottleneck step of matrix multiplication by using Linear transformations to mimic the effect of a matrix multiplication. Since matrix multiplication basically transforms a vector element to a weighted sum of the neighbouring elements, this can be easily acheived using a special function which acts on the vector in optimal $\mathcal{O}(n)$ time.
+This project is an attempt towards building a PDE solver for JuliaDiffEq using the [Finite Difference Method](https://en.wikipedia.org/wiki/Finite_difference_method)(FDM) approach. We take up the FDM approach instead of [FEM](https://en.wikipedia.org/wiki/Finite_element_method) and [FVM](https://en.wikipedia.org/wiki/Finite_volume_method) as there are many toolboxes which already exist for FEM and FVM but not for FDM. Also, there are many use cases where the geometry of the problem is simple enough to be solved by FDM methods which are much faster due to their being able to avoid the bottleneck step of matrix multiplication by using Linear transformations to mimic the effect of a matrix multiplication. Since matrix multiplication basically transforms a vector element to a weighted sum of the neighbouring elements, this can be easily achieved using a special function which acts on the vector in optimal $\mathcal{O}(n)$ time.
The result is a new package called [DiffEqOperators.jl](https://github.com/SciML/DiffEqOperators.jl) which creates efficient discretizations of partial differential operators thereby converting PDEs to ODEs which can be solved efficiently by existing ODE solvers. The `DerivativeOperator` is based on central differencing schemes of approximating derivatives at a point whereas the `UpwindOperators` are based on one-sided differencing schemes where the solution is typically a wave moving in a particular direction. The package also supports a variety of boundary conditions like [Dirichlet](https://en.wikipedia.org/wiki/Dirichlet_boundary_condition), [Neumann](https://en.wikipedia.org/wiki/Neumann_boundary_condition), [Periodic](https://en.wikipedia.org/wiki/Periodic_boundary_conditions) and the [Robin](https://en.wikipedia.org/wiki/Robin_boundary_condition) [boundary condition](https://en.wikipedia.org/wiki/Boundary_value_problem).
@@ -90,11 +90,11 @@ julia> A = DerivativeOperator{Float64}(4,2,1.0,10,:Dirichlet0,:Dirichlet0)
julia> A.stencil_coefs
7-element SVector{7,Float64}:
-0.166667
- 2.0
- -6.5
+ 2.0
+ -6.5
9.33333
- -6.5
- 2.0
+ -6.5
+ 2.0
-0.166667
```
@@ -103,15 +103,15 @@ If we want to apply the operator as a matrix multiplication (sparse or dense) we
```
julia> full(A)
10×10 Array{Float64,2}:
- 9.33333 -6.5 2.0 … 0.0 0.0 0.0
--6.5 9.33333 -6.5 0.0 0.0 0.0
- 2.0 -6.5 9.33333 0.0 0.0 0.0
--0.166667 2.0 -6.5 0.0 0.0 0.0
- 0.0 -0.166667 2.0 -0.166667 0.0 0.0
- 0.0 0.0 -0.166667 … 2.0 -0.166667 0.0
+ 9.33333 -6.5 2.0 … 0.0 0.0 0.0
+-6.5 9.33333 -6.5 0.0 0.0 0.0
+ 2.0 -6.5 9.33333 0.0 0.0 0.0
+-0.166667 2.0 -6.5 0.0 0.0 0.0
+ 0.0 -0.166667 2.0 -0.166667 0.0 0.0
+ 0.0 0.0 -0.166667 … 2.0 -0.166667 0.0
0.0 0.0 0.0 -6.5 2.0 -0.166667
- 0.0 0.0 0.0 9.33333 -6.5 2.0
- 0.0 0.0 0.0 -6.5 9.33333 -6.5
+ 0.0 0.0 0.0 9.33333 -6.5 2.0
+ 0.0 0.0 0.0 -6.5 9.33333 -6.5
0.0 0.0 0.0 2.0 -6.5 9.33333
julia> sparse(A)
@@ -201,7 +201,7 @@ Although vanilla `DerivativeOperators` and the `UpwindOperators` form the major
We are also working on the Robin boundary conditions for `DerivativeOperators` which are currently not as accurate as they [should](https://gist.github.com/shivin9/124ed1e5ea96792fc8666e0caf32715c) be.
-Another avenue for work is the lazy implementations of `expm` and `expmv` for `DerivativeOperators`.
+Another avenue for work is the lazy implementations of `expm` and `expmv` for `DerivativeOperators`.
## Acknowledgments
diff --git a/blog/2018/06/missing.md b/blog/2018/06/missing.md
index b66efc3013..5a9540fb47 100644
--- a/blog/2018/06/missing.md
+++ b/blog/2018/06/missing.md
@@ -2,7 +2,7 @@
@def rss = """ First-Class Statistical Missing Values Support in Julia 0.7 | The 0.7 release of Julia will soon introduce first-class support for statistical... """
@def published = "19 June 2018"
@def title = "First-Class Statistical Missing Values Support in Julia 0.7"
-@def authors = """ Milan Bouchet-Valat"""
+@def authors = """ Milan Bouchet-Valat"""
@def hascode = true
The 0.7 release of Julia will soon introduce first-class support for statistical
@@ -260,7 +260,7 @@ to represent missing values[^jmw]. `Nullable` suffered from several issues:
- `Array{Nullable{T}}` objects used a sub-optimal memory layout where `T` values
and the associated `Bool` indicator were stored side-by-side, which wastes
- space due to aligment constraints and is not the most efficient for processing.
+ space due to alignment constraints and is not the most efficient for processing.
Therefore, specialized array types like
[`NullableArray`](https://github.com/JuliaStats/NullableArrays.jl) had to be used
(similar to `DataArray`).
diff --git a/blog/2018/08/GSoC-Final-Summary.md b/blog/2018/08/GSoC-Final-Summary.md
index 0fe51e4d2b..8d6971d8f9 100644
--- a/blog/2018/08/GSoC-Final-Summary.md
+++ b/blog/2018/08/GSoC-Final-Summary.md
@@ -2,7 +2,7 @@
@def rss = """ GSoC 2018: Reinforcement Learning and Generative models using Flux | In this post I'm going to briefly summarize about the machine learning models I have worked on during this summer for GSoC. I worked towards enriching model zoo of Flux.jl (https://github.com/FluxML), a machine learning library written in Julia (https://github.com/JuliaLang/julia). My project cover... """
@def published = "6 August 2018"
@def title = "GSoC 2018: Reinforcement Learning and Generative models using Flux"
-@def authors = """ Tejan Karmali"""
+@def authors = """ Tejan Karmali"""
Hello, world!
@@ -20,7 +20,7 @@ In the process, I could achieve most of my targets. I had to skip a few of them,
[Flux-baselines](https://github.com/tejank10/Flux-baselines) is a collection of various Deep Reinforcement Learning models. This includes Deep Q Networks, Actor-Critic and DDPG.
-Basic structure of an RL probem is as folowd: There is an environment, let's say game of pong is our environment. The environment may contain many ojects which interact with each other. In pong there are 3 objects: a ball and 2 paddles. The environment has a *state*. It is the current situation present in the environment in terms of various features of the objects in it. These features could be position, velocity, color etc. pertaining to the objects in the it. An actions needs to be chosed to play a move in the environment and obtain the next state. Actions will be chosen till the game ends. An RL model basically finds the actions that needs to be chosen.
+Basic structure of an RL problem is as folows: There is an environment, let's say game of pong is our environment. The environment may contain many objects which interact with each other. In pong there are 3 objects: a ball and 2 paddles. The environment has a *state*. It is the current situation present in the environment in terms of various features of the objects in it. These features could be position, velocity, color etc. pertaining to the objects in the it. An actions needs to be chosed to play a move in the environment and obtain the next state. Actions will be chosen till the game ends. An RL model basically finds the actions that needs to be chosen.
Over past few years, deep q learning has gained lot of popularity. After the paper by Deep Mind about the Human level control sing reinforcement learning, there was no looking back. It combined the advanced in RL as well as deep learning to get an AI player which had superhuman performance. I made the basic [DQN](https://github.com/tejank10/Flux-baselines/blob/master/dqn/dqn.jl) and [Double DQN](https://github.com/tejank10/Flux-baselines/blob/master/dqn/double-dqn.jl) during the pre-GSoC phase, followed by [Duel DQN](https://github.com/tejank10/Flux-baselines/blob/master/dqn/duel-dqn.jl) in the first week on GSoC.
@@ -82,7 +82,7 @@ For more info in the AlphaGo.jl refer to the [blog post](https://tejank10.github
[Generative Adversarial Networks](https://github.com/tejank10/model-zoo/tree/GAN/vision/mnist)
-GANs have been extremely suceessful in learning the underlying representation of any data. By doing so, it can reproduce some fake data. For example the GANs trained on MNIST Human handwritten digits dataset can produce some fake images which look very similar to those in the MNIST. These neural nets have great application in image editing. It can remove certain features from the image, add some new ones; depending on the dataset. The GANs contain of two networks: generator and discriminator. Generator's objective os to generate fake images awhereas the discriminator's objective is to differentiate between the fake images generted by thhe generator and the real images in the dataset.
+GANs have been extremely suceessful in learning the underlying representation of any data. By doing so, it can reproduce some fake data. For example the GANs trained on MNIST Human handwritten digits dataset can produce some fake images which look very similar to those in the MNIST. These neural nets have great application in image editing. It can remove certain features from the image, add some new ones; depending on the dataset. The GANs contain of two networks: generator and discriminator. Generator's objective os to generate fake images awhereas the discriminator's objective is to differentiate between the fake images generated by the generator and the real images in the dataset.
~~~
@@ -94,7 +94,7 @@ GANs have been extremely suceessful in learning the underlying representation of
LSGAN DCGAN WGAN MADE
~~~
-#### Targets acheived
+#### Targets achieved
1. [`ConvTranspose` layer](https://github.com/FluxML/Flux.jl/pull/311)
2. [DCGAN](https://github.com/tejank10/model-zoo/blob/GAN/vision/mnist/dcgan.jl)
diff --git a/blog/2018/08/adding-newer-features-and-speeding-up-convolutions-in-flux.md b/blog/2018/08/adding-newer-features-and-speeding-up-convolutions-in-flux.md
index 8cdb23ac63..559f5704fa 100644
--- a/blog/2018/08/adding-newer-features-and-speeding-up-convolutions-in-flux.md
+++ b/blog/2018/08/adding-newer-features-and-speeding-up-convolutions-in-flux.md
@@ -2,7 +2,7 @@
@def rss = """ GSoC 2018: Adding Newer Features and Speeding up Convolutions in Flux | Over the summer I have been working at improving the Computer Vision capabilities of Flux. My specific line of work was to __add newer models to the Flux model-zoo__, __implement some new features__ and also __improve the speed of the previous layers__. Specifically, I achieved a __18-fold__ speed up... """
@def published = "13 August 2018"
@def title = "GSoC 2018: Adding Newer Features and Speeding up Convolutions in Flux"
-@def authors = """Avik Pal"""
+@def authors = """Avik Pal"""
@def hascode = true
Over the summer I have been working at improving the Computer Vision capabilities of Flux. My specific line of work was to __add newer models to the Flux model-zoo__, __implement some new features__ and also __improve the speed of the previous layers__. Specifically, I achieved a __18-fold__ speed up for the __Convolutions__ and around __3-fold__ for __BatchNorm__.
@@ -113,7 +113,7 @@ Here's a small demo of the package
### FastStyleTransfer.jl
-This is the implementation of the paper __[Perceptual Losses for Real-Time Style Transfer and Super-Resolution](https://arxiv.org/pdf/1603.08155)__. There are some obvious deviations from the paper. We used the best layer implementations that were currently available in Flux. As for the exact architecture it is still in developement. We provide three pre-trained models with this package. The API has been kept as simple as possible.
+This is the implementation of the paper __[Perceptual Losses for Real-Time Style Transfer and Super-Resolution](https://arxiv.org/pdf/1603.08155)__. There are some obvious deviations from the paper. We used the best layer implementations that were currently available in Flux. As for the exact architecture it is still in development. We provide three pre-trained models with this package. The API has been kept as simple as possible.
Below is a small example of style transfer on MonaLisa
diff --git a/blog/2018/08/union-splitting.md b/blog/2018/08/union-splitting.md
index 15c1c8fe90..0edbe1066d 100644
--- a/blog/2018/08/union-splitting.md
+++ b/blog/2018/08/union-splitting.md
@@ -2,7 +2,7 @@
@def rss = """ Union-splitting: what it is, and why you should care | Among those who follow Julia's development closely, one of the (many) new features causing great excitement is something called "Union-splitting."... """
@def published = "9 August 2018"
@def title = "Union-splitting: what it is, and why you should care"
-@def authors = """Tim Holy"""
+@def authors = """Tim Holy"""
@def hascode = true
Among those who follow Julia's development closely, one of the (many) new features causing great excitement is something called "Union-splitting."
@@ -67,7 +67,7 @@ Worse, if you forgot to check, and `function2` didn't error when you passed it 0
That is far worse than getting an error, because it's much harder to track down where wrong results come from.
In Julia 0.7 and 1.0, Milan Bouchet-Valat rewrote all of our `find*` functions, of which one change (among many) was that `findfirst` now returns `nothing` when it fails to find the requested value.
-Unlike the old approach of returning 0, this return value is truly unambigous and robust against generalizations of indexing where 0 might be a perfectly valid array index.
+Unlike the old approach of returning 0, this return value is truly unambiguous and robust against generalizations of indexing where 0 might be a perfectly valid array index.
It also gives you more reliable code, because if you forget to check, really there's not much you can do with `nothing` that doesn't trigger a (very welcome) error.
And thanks to Union-splitting, it doesn't cause any kind of performance penalty whatsoever.
diff --git a/blog/2019/02/light-graphs.md b/blog/2019/02/light-graphs.md
index ff78cd3131..b5635c57c8 100644
--- a/blog/2019/02/light-graphs.md
+++ b/blog/2019/02/light-graphs.md
@@ -2,7 +2,7 @@
@def rss = """ GSoC 2018 - Parallel Implementations of Graph Analysis Algorithms | This blog briefly summarises my GSoC 2018 project (Parallel Graph Development (https://summerofcode.withgoogle.com/archive/2018/projects/5193483178475520/)) and the results achieved. For a detailed description, please refer to my GSoC blog (https://sohamtamba.github.io/GSoC).... """
@def published = "3 February 2019"
@def title = "GSoC 2018 - Parallel Implementations of Graph Analysis Algorithms"
-@def authors = """Soham Tamba"""
+@def authors = """Soham Tamba"""
This blog briefly summarises my GSoC 2018 project ([Parallel Graph Development](https://summerofcode.withgoogle.com/archive/2018/projects/5193483178475520/)) and the results achieved. For a detailed description, please refer to my [GSoC blog](https://sohamtamba.github.io/GSoC).
@@ -101,7 +101,7 @@ The following branches have been merged into LightGraphs master:
- [Parallel Random Heuristics](https://github.com/SohamTamba/LightGraphs.jl/tree/genrate_reduce)
- [Karger Minimum Cut](https://github.com/SohamTamba/LightGraphs.jl/tree/Karger_min_cut)
- [Multi-threaded Centrality Measures](https://github.com/SohamTamba/LightGraphs.jl/tree/Threaded_Centrality)
- 1. Betweeness Centrality
+ 1. Betweenness Centrality
2. Closeness Centrality
3. Stress Centrality
diff --git a/blog/2019/06/diffeqbot.md b/blog/2019/06/diffeqbot.md
index 71a2115c67..78594222c7 100644
--- a/blog/2019/06/diffeqbot.md
+++ b/blog/2019/06/diffeqbot.md
@@ -2,7 +2,7 @@
@def rss = """ Hello @DiffEqBot | Hi! Today we all got a new member to the DiffEq family. Say hi to our own DiffEqBot (https://github.com/DiffEqBot) - A bot which helps run benchmarks and compares with the current master of a given package. It also generates and stores the Reports generated in a repository (https://github.com/DiffE... """
@def published = "18 June 2019"
@def title = "Hello @DiffEqBot"
-@def authors = """Kanav Gupta"""
+@def authors = """Kanav Gupta"""
@def hascode = true
Hi! Today we all got a new member to the DiffEq family. Say hi to our own [DiffEqBot](https://github.com/DiffEqBot) - A bot which helps run benchmarks and compares with the current master of a given package. It also generates and stores the Reports generated in a [repository](https://github.com/DiffEqBot/Reports). What's special about this is that it is completely stateless (no databases involved at all, just juggling between repositories!) and it has no exposed public URLs. Even though highly inspired by Nanosoldier, this has a completely unique workflow.
@@ -25,7 +25,7 @@ Right now, `DIAGRAMS` cannot be a recursive dictionary, i.e. an element of the d
## How does DiffEqBot work internally?
-DiffEqBot works by jumping accross many repositories and it has been all possible due to awesome APIs both GitHub and Gitlab has provided us with! I will explain the workflow of DiffEqBot in the steps it take to get a particular job done -
+DiffEqBot works by jumping across many repositories and it has been all possible due to awesome APIs both GitHub and Gitlab has provided us with! I will explain the workflow of DiffEqBot in the steps it take to get a particular job done -
1. You make a comment on the pull request to run the benchmarks. With the help of GitHub webhooks, `comment` event is posted on a Heroku app. You get the repository's name and pull request number where this comment is made. It makes sure all the sanity checks, like if the person can run benchmarks or not, or the repository is registered or not etc.
@@ -35,7 +35,7 @@ DiffEqBot works by jumping accross many repositories and it has been all possibl

-3. Here comes the tricky part. We have a seperate dedicated Gitlab private repository called `BenchmarkingRepo` which is basically an empty repository, but plays an important role which would be explained now. DiffEqBot checks out a branch with name formatted as `REPONAME-PR` and generates a Gitlab CI configuration script (`.gitlab-ci.yml`) and makes a commit on this branch. What this configuration does is, pull the PR where the request is made, run the benchmarks, and post the results back to the bot. Basically the script is -
+3. Here comes the tricky part. We have a separate dedicated Gitlab private repository called `BenchmarkingRepo` which is basically an empty repository, but plays an important role which would be explained now. DiffEqBot checks out a branch with name formatted as `REPONAME-PR` and generates a Gitlab CI configuration script (`.gitlab-ci.yml`) and makes a commit on this branch. What this configuration does is, pull the PR where the request is made, run the benchmarks, and post the results back to the bot. Basically the script is -
```yaml
main:
@@ -60,7 +60,7 @@ failed_job:

-5. In the `some_script_to_run_becnhmarks.jl` file, we make a request back to DiffEqBot along with the report in JSON format in the end. When this happens, DiffEqBot makes a commit on the Reports repository on GitHub submitting the markdown script.
+5. In the `some_script_to_run_benchmarks.jl` file, we make a request back to DiffEqBot along with the report in JSON format in the end. When this happens, DiffEqBot makes a commit on the Reports repository on GitHub submitting the markdown script.

@@ -112,7 +112,7 @@ All the configuration of DiffEqBot is done through a file `config.json` in the H
* `github_app.bot_endpoint` - Github App interacts with the Heroku app by a webhook. This is the endpoint where the app should make requests.
* `gitlab_account.benchmarking_repo_id` - Project ID of the BenchmarkingRepo on Gitlab
* `gitlab_account.access_token` - Gitlab Personal Access token of Bot account with repo:write rights.
-* `github_accout.access_token` - Github Personal access token with `public_repo` scope. You can directly generate this [here](https://github.com/settings/tokens/new?description=DiffEqBot&scopes=public_repo).
+* `github_account.access_token` - Github Personal access token with `public_repo` scope. You can directly generate this [here](https://github.com/settings/tokens/new?description=DiffEqBot&scopes=public_repo).
## Access Control and Security
@@ -123,4 +123,4 @@ We have for now given access to only certain members of the organization. We cal
## Shortcomings and Road ahead
-I absolutely love this new member of our community. But it still has several shortcomings. As seen above, due to security concerns, we have allowed only certain members of the organization access to run the benchmarks. Also, we have a basic frontend ready for display of reports, but an even more better design is welcome! We might also need more commands for DiffEqBot than just `runbenchmarks` and `abort`. All these extra features would be a cherry on top. I also plan to make it open source and maintain a proper documentation so that other communities can also deploy this for thier uses and maybe help in its development too!
+I absolutely love this new member of our community. But it still has several shortcomings. As seen above, due to security concerns, we have allowed only certain members of the organization access to run the benchmarks. Also, we have a basic frontend ready for display of reports, but an even more better design is welcome! We might also need more commands for DiffEqBot than just `runbenchmarks` and `abort`. All these extra features would be a cherry on top. I also plan to make it open source and maintain a proper documentation so that other communities can also deploy this for their uses and maybe help in its development too!
diff --git a/blog/2019/09/profilers.md b/blog/2019/09/profilers.md
index 8b2cece1aa..45ba4fda5b 100644
--- a/blog/2019/09/profilers.md
+++ b/blog/2019/09/profilers.md
@@ -2,7 +2,7 @@
@def rss = """ Profiling tools are awesome. They let us see what actually is affecting our program performance. Profiling tools also are terrible. They lie to us and give us confusing information. They also have some surprisingly new developments: [brendangregg's often cloned flamegraphs tool](http://www.brendangregg.com/flamegraphs.html) was created in 2011! So here I will be investigating some ways to make our profile reports better; and looking at ways in which they commonly break, to raise awareness of those artifacts in the reports. """
@def published = "16 September 2019"
@def title = "Profiling tool wins and woes"
-@def authors = """Jameson Nash"""
+@def authors = """Jameson Nash"""
@def hascode=true
Profiling tools are awesome. They let us see what actually is affecting our program performance. Profiling tools also are terrible. They lie to us and give us confusing information. They also have some surprisingly new developments: [brendangregg's often cloned flamegraphs tool](http://www.brendangregg.com/flamegraphs.html) was created in 2011! So here I will be investigating some ways to make our profile reports better; and looking at ways in which they commonly break, to raise awareness of those artifacts in the reports.
@@ -385,7 +385,7 @@ julia> Profile.print(format=:tree, recur=:flat)
Total snapshots: 629
```
-I think this looks cool, and vaguely even shows how I would conceptualize the functions in my head. This is availble right now only on [my jn/profile-recurflat](https://github.com/JuliaLang/julia/tree/jn/profile-recurflat) branch, but should be a PR soon, and show up in the JuliaLang v1.4 release.
+I think this looks cool, and vaguely even shows how I would conceptualize the functions in my head. This is available right now only on [my jn/profile-recurflat](https://github.com/JuliaLang/julia/tree/jn/profile-recurflat) branch, but should be a PR soon, and show up in the JuliaLang v1.4 release.
## Final thoughts
diff --git a/blog/2020/08/invalidations.md b/blog/2020/08/invalidations.md
index 1664f28e6f..0327dae666 100644
--- a/blog/2020/08/invalidations.md
+++ b/blog/2020/08/invalidations.md
@@ -111,7 +111,7 @@ To improve performance, it checks (as efficiently as possible at runtime) whethe
and if so calls the method it knows.
In this case, `f` just returns a constant, so when applicable the compiler even hard-wires in the return value for you.
-However, the compiler also acknowledges the possiblity that `container[1]` *won't* be an `Int`.
+However, the compiler also acknowledges the possibility that `container[1]` *won't* be an `Int`.
That allows the above code to throw a MethodError:
```julia-repl
@@ -365,7 +365,7 @@ and so loading the SIMD package triggers invalidation of everything that depends
As is usually the case, there are several ways to fix this: we could drop the `::Tuple` in the definition of `struct CallWaitMsg`, because there's no need to call `convert` if the object is already known to have the correct type (which would be `Any` if we dropped the field type-specification, and `Any` is not restrictive). Alternatively, we could keep the `::Tuple` in the type-specification, and use external knowledge that we have and assert that `args` is *already* a `Tuple` in `deserialize_msg` where it calls `CallWaitMsg`, thus informing Julia that it can afford to skip the call to `convert`.
This is intended only as a taste of what's involved in fixing invalidations; more extensive descriptions are available in [SnoopCompile's documentation](https://timholy.github.io/SnoopCompile.jl/stable/snoopr/) and the [video](https://www.youtube.com/watch?v=7VbXbI6OmYo).
-But it also conveys an important point: most invalidations come from poorly-inferred code, so by fixing invalidations you're often improving quality in other ways. Julia's [performance tips] page has a wealth of good advice about avoiding non-inferrable code, and in particular cases (where you might know more about the types than inference is able to determine on its own) you can help inference by adding type-assertions.
+But it also conveys an important point: most invalidations come from poorly-inferred code, so by fixing invalidations you're often improving quality in other ways. Julia's [performance tips] page has a wealth of good advice about avoiding non-inferable code, and in particular cases (where you might know more about the types than inference is able to determine on its own) you can help inference by adding type-assertions.
Again, some of the recently-merged "latency" pull requests to Julia might serve as instructive examples.
## Summary
diff --git a/blog/2020/09/juliacon-2020-open-source-bof-follow-up.md b/blog/2020/09/juliacon-2020-open-source-bof-follow-up.md
index d7ff2210b4..9a059a0b7b 100644
--- a/blog/2020/09/juliacon-2020-open-source-bof-follow-up.md
+++ b/blog/2020/09/juliacon-2020-open-source-bof-follow-up.md
@@ -66,7 +66,7 @@ One difficulty reported during the BoF was getting organizational approval to re
#### Open Sourcing Packages That Previously Used Internal CI/CD
-One important element of successful open-source projects is that CI logs should generally be available to all contributors. This can be a burdensome criteria to meet if a previously closed-source package utilized internal CI/CD pipelines with nicer properties than publicly available CI pipelines. In some instances, certain flavors of this problem can be solved with better tooling, e.g. self-hosted (but publically accessible) package registries can vendor open-sourced packages just as nicely as Julia's General Registry, but might leverage custom CI/CD for pre-registration checks.
+One important element of successful open-source projects is that CI logs should generally be available to all contributors. This can be a burdensome criteria to meet if a previously closed-source package utilized internal CI/CD pipelines with nicer properties than publicly available CI pipelines. In some instances, certain flavors of this problem can be solved with better tooling, e.g. self-hosted (but publicly accessible) package registries can vendor open-sourced packages just as nicely as Julia's General Registry, but might leverage custom CI/CD for pre-registration checks.
#### Open Source Efforts Could Reveal Strategic Intent
diff --git a/blog/2021/01/precompile_tutorial.md b/blog/2021/01/precompile_tutorial.md
index 293491b86b..23f100b95a 100644
--- a/blog/2021/01/precompile_tutorial.md
+++ b/blog/2021/01/precompile_tutorial.md
@@ -663,8 +663,8 @@ precompile(dopush, ())
then the `MethodInstance` for `push!(::Vector{SCDType}, ::SCDType)` will be added to the package through the backedge to `dopush` (which you do own).
-This was an artifical example, but in more typical cases this happens organically through the functionality of your package.
-But again, this works only for inferrable calls.
+This was an artificial example, but in more typical cases this happens organically through the functionality of your package.
+But again, this works only for inferable calls.
@@
[package mode]: https://julialang.github.io/Pkg.jl/v1/getting-started/#Basic-Usage
diff --git a/blog/2021/01/snoopi_deep.md b/blog/2021/01/snoopi_deep.md
index b1bdab5ef5..44a722fe8d 100644
--- a/blog/2021/01/snoopi_deep.md
+++ b/blog/2021/01/snoopi_deep.md
@@ -9,7 +9,7 @@ In the [first post](https://julialang.org/blog/2021/01/precompile_tutorial/), we
We also pointed out that precompilation is closely tied to *type inference*:
- precompilation allows you to cache the results of type inference, thus saving time when you start using methods defined in the package
-- caching becomes more effective when a higher proportion of calls are made with inferrable argument types (i.e., type-inference "succeeds"). Successful inference introduces links, in the form of `MethodInstance` backedges, that permit the entire call graph to be cached.
+- caching becomes more effective when a higher proportion of calls are made with inferable argument types (i.e., type-inference "succeeds"). Successful inference introduces links, in the form of `MethodInstance` backedges, that permit the entire call graph to be cached.
As a consequence, anyone interested in precompilation needs to pay attention to type inference: how much time does it account for, where is it spending its time, and what can be done to improve caching?
Julia itself provides the internal infrastructure needed to "spy" on inference, and the user-space utilities are in the [SnoopCompile] package.
diff --git a/blog/2021/03/julia-1.6-highlights.md b/blog/2021/03/julia-1.6-highlights.md
index 266c48d91e..ee56216740 100644
--- a/blog/2021/03/julia-1.6-highlights.md
+++ b/blog/2021/03/julia-1.6-highlights.md
@@ -255,7 +255,7 @@ possible. By limiting the number of backedges and data structures, as well as
centralizing the template pieces of code that each JLL package uses, we are
able to not only vastly improve load times, but improve compile times as well!
As an added bonus, improvements to JLL package APIs can now be made directly in
-`JLLWappers.jl` without needing to re-deploy hundreds of JLLs. Because these
+`JLLWrappers.jl` without needing to re-deploy hundreds of JLLs. Because these
JLL packages only define a thin wrapper around simple, lightweight functions
that load libraries and return paths and such, they do not benefit from the
heavy optimization that most Julia code undergoes. One final piece of the
diff --git a/blog/2021/08/sharks.md b/blog/2021/08/sharks.md
index 6d39212eec..387402c385 100644
--- a/blog/2021/08/sharks.md
+++ b/blog/2021/08/sharks.md
@@ -270,7 +270,7 @@ For example, the side-to-side force has the same frequency as the swimming motio
This simple model is a great start and it opens up a ton of avenues for improving the shark simulation and suggesting research questions:
- The instantaneous net forces should be zero in a free swimming body! We could add reaction motions to our model to achieve this. Would the model shark swim in a straight line if we did this, or is a control-loop needed?
- Real sharks are 3D (gasp!). While we could easily extend this approach using 2D splines, it will take much longer to simulate. Is there a way use GPUs to accelerate the simulations without completely changing the solver?
- - If we were going to make a bio-inspired robot of this shark, we will have constraints on the shape and motion and powering available. Can we use this framework to help optimize our robotic within it's contraints?
+ - If we were going to make a bio-inspired robot of this shark, we will have constraints on the shape and motion and powering available. Can we use this framework to help optimize our robotic within it's constraints?
Below you can find links to all the packages used in this notebook. Happy Simulating!
diff --git a/blog/2021/11/julia-1.7-highlights.md b/blog/2021/11/julia-1.7-highlights.md
index f79a61da19..eb73daecdd 100644
--- a/blog/2021/11/julia-1.7-highlights.md
+++ b/blog/2021/11/julia-1.7-highlights.md
@@ -398,7 +398,7 @@ julia (v1.6)> @btime reshape([1; 2; 3; 4], (1, 2, 1, 2)); # fast, but intent les
65.884 ns (2 allocations: 192 bytes)
```
-This is a substantial improvement in performance for this basic operation, and the differential improves greatly as more dimensions become invovled.
+This is a substantial improvement in performance for this basic operation, and the differential improves greatly as more dimensions become involved.
For ease of reading a larger array expression, line breaks are of course tolerated:
```julia-repl
diff --git a/blog/2021/12/dtable-performance-assessment.md b/blog/2021/12/dtable-performance-assessment.md
index 5d63c65334..4a8b1514f2 100644
--- a/blog/2021/12/dtable-performance-assessment.md
+++ b/blog/2021/12/dtable-performance-assessment.md
@@ -45,7 +45,7 @@ The `DTable` aims to excel in two areas:
- parallelization of data processing
- out-of-core processing (will be available through future `Dagger.jl` upgrades)
-The goal is to become competitive with similiar tools, such as `Dask` or `Spark`, so that Julia users can solve and scale their problems within Julia.
+The goal is to become competitive with similar tools, such as `Dask` or `Spark`, so that Julia users can solve and scale their problems within Julia.
By leveraging the composability of the Julia data ecosystem, we can reuse a lot of existing functionality in order to achieve the above goals, and continue improving the solution in the future instead of just creating another monolithic solution.
@@ -134,7 +134,7 @@ DTable command: `map(row -> (r = row.a1 + 1,), d)`
As the set of values is limited, a simple filter expression was chosen, which filters out approximately half of the records (command below).
-In this scenario, the parallelization and partitioning overhead doesn't pay off as well as both `DTable` and `Dask` are noticably slower than `DataFrames.jl`.
+In this scenario, the parallelization and partitioning overhead doesn't pay off as well as both `DTable` and `Dask` are noticeably slower than `DataFrames.jl`.
When it comes to the comparison of these two implementations, the performance looks very similiar with `Dask` being on average 1.6 times faster than the `DTable`.
The scaling of the `DTable` allows it to catch up to `DataFrames` at the largest data size. It's possible that this behavior may continue at larger data sizes and eventually provide a speedup versus `DataFrames` after some threshold.
@@ -203,7 +203,7 @@ DTable command: `Dagger.groupby(d, :a1)`
## Grouped reduction (single column)
Mimicking the success of reduction benchmarks, the `DTable` is again performing better here than the direct competition.
-For the single column reductions, it's an average ~20.2 times speedup over `Dask`, and their scaling behavior looks very similiar.
+For the single column reductions, it's an average ~20.2 times speedup over `Dask`, and their scaling behavior looks very similar.
Contrary to the standard reduction benchmarks, the `DTable` doesn't offer a speedup compared to `DataFrames.jl` across all the data sizes.
It looks like the current algorithm has a significant overhead that can be observed as a lower bound to the performance at smaller data sizes.
@@ -217,7 +217,7 @@ DTable command: `r = reduce(fit!, g, cols=[:a2], init=Mean())`
## Grouped reduction (all columns)
-The results for the all-columns reduction look very similiar to single-column.
+The results for the all-columns reduction look very similar to single-column.
The `DTable` managed to offer an average ~22.3 times speeup over `Dask`.
Again, the `DTable` is heavily falling behind `DataFrames.jl` on smaller data sizes due to the significant entry overhead acting as a lower performance bound at smaller data sizes.
@@ -253,7 +253,7 @@ We hope to include all the necessary fixes in future patches to Julia 1.7.
The `DTable` has successfully passed the proof-of-concept stage and is currently under active development as a part of the `Dagger.jl` package.
-This early performance assessment has confirmed that the `DTable` has the potential to become a competetive tool for processing tabular data.
+This early performance assessment has confirmed that the `DTable` has the potential to become a competitive tool for processing tabular data.
It managed to perform significantly better than direct competition (`Dask`) in 6 out of 7 presented benchmarks and in the remaining one it doesn't fall too far behind.
While this looks promising there's still a lot of work ahead in order to make the `DTable` feature-rich and even faster, so keep an eye out for future updates on the project.
diff --git a/blog/2022/02/10years.md b/blog/2022/02/10years.md
index 052dce1cbd..256c1c326f 100644
--- a/blog/2022/02/10years.md
+++ b/blog/2022/02/10years.md
@@ -218,7 +218,7 @@ Even more exciting than the software itself was the vibrant open source communit
## Francesco Martinuzzi [(@MartinuzziFrancesco)](https://github.com/MartinuzziFrancesco)
-I encountered Julia when I was looking for an alternative to Python to use for my master thesis. At the time I was mainly a Fortran user, as many physics students still are, and Python felt unbelievably slow. I stumbled into Julia almost by chance in looking for something in beetween these two languages. What most amazes me about the language is not the technical feats in itself, but it is how much Julia and its community are intertwined. Coming from a world in which code is handed down from supervisor to student, with little to no explanation or comments, this was something I valued incredibly.
+I encountered Julia when I was looking for an alternative to Python to use for my master thesis. At the time I was mainly a Fortran user, as many physics students still are, and Python felt unbelievably slow. I stumbled into Julia almost by chance in looking for something in between these two languages. What most amazes me about the language is not the technical feats in itself, but it is how much Julia and its community are intertwined. Coming from a world in which code is handed down from supervisor to student, with little to no explanation or comments, this was something I valued incredibly.
I was lucky enough to start contributing to the [SciML](https://sciml.ai/) organization in the summer of 2020 as part of the [Google Summer of Code](https://summerofcode.withgoogle.com/) program working on [ReservoirComputing.jl](https://github.com/SciML/ReservoirComputing.jl). This also was the start of my personal journey into contributing to open source software, and the Julia language made that an incredibly easy transition.
@@ -447,7 +447,7 @@ From the first time I heard about Julia in Alan’s office in 2011, Julia has br
## Panagiotis Georgakopoulos [(@pankgeorg)](https://github.com/pankgeorg)
-I was introduced to Julia by the MIT - Computational Thinking course. That was start of the quarantine era and I was cruising online resources to understand scientific computing a bit more. Coming from the front-end world of computing, I found Julia amazing because of its unique integration with HTML through Pluto. I started contributing to the Pluto.jl project - initially by fixing some CSS, then some React and finally diving deeper into Pluto's internals. Pluto's appearance in the Julia ecosystem is no accident; Julia is _so_ friendly when it comes to `show`ing stuff in HTML. Alongside its speed, which enables lag-free interaction, Julia creates the perfect environment for interactive programming and I feel glad and priviledged to be part of the journey!
+I was introduced to Julia by the MIT - Computational Thinking course. That was start of the quarantine era and I was cruising online resources to understand scientific computing a bit more. Coming from the front-end world of computing, I found Julia amazing because of its unique integration with HTML through Pluto. I started contributing to the Pluto.jl project - initially by fixing some CSS, then some React and finally diving deeper into Pluto's internals. Pluto's appearance in the Julia ecosystem is no accident; Julia is _so_ friendly when it comes to `show`ing stuff in HTML. Alongside its speed, which enables lag-free interaction, Julia creates the perfect environment for interactive programming and I feel glad and privileged to be part of the journey!
## Huda Nassar [(@nassarhuda)](https://github.com/nassarhuda)
@@ -683,7 +683,7 @@ I had my first experience with Julia in Spring 2019, while in 18.06 (Linear Alge
My first encounter with the Julia language happened in fall of 2014. At the time I was quite young, but enthused by Computational Science, I was using primarily Python and R for these two tasks. I had worked on several projects with peers where we would hit the " Two Language Problem," and it got to be really frustrating. I was the only member of the team who could write C, and Cython wasn't really helping our problem as much as one might expect. Back then, tools like Numba and remote Python interpretation were not even close to where they are now, and I was looking for more information on getting Python to run faster when I stumbled across a Julia forum post. I was intrigued by the syntax, and since picking up Julia on that day, it has become my favorite programming language. I was able to solve our problem in Julia, rather than C, and I was able to call our Python code when needed via PyCall.jl. It ended up working perfectly, so I used it for projects with these sorts of problems each time they came into fruition. The language just kept doing fantastic, and then all of the changes that kept coming to the language were all just so great. Now the language has a venerable ecosystem to go along with it, so things have only gotten better.
-## Elisabeth Roesch [(@ElisabethRoesch)](https://github.com/ElisabethRoesch)
+## Elisabeth Roesch [(@ElisabethRoesch)](https://github.com/ElisabethRoesch)
As a systems biologist, I form part of a very interdisciplinary field. I work in teams of biologists, mathematicians, computer scientists and more. Leveraging expertise of multiple domains is key for many hard problems in the field. One key aspect I consider when choosing my programming language is how it enables collaborations. A focus of Julia’s language design is abstraction and its implied modularity and composability. The effect that this design emphasis has on my day to day work of collaborating with other researchers is hard to describe in only a few words. Simple, yet clear syntax as well as elegant technical features, such as multiple dispatch, solve the expression problem and make it convenient to reuse, adapt and extend existing code of collaborators. Additionally, exploiting Julia’s rich package ecosystems is made easy, too.
Second, Julia is fast. In the biological sciences, the amount of data at our fingertips is growing rapidly. Software that scales well is of great importance. In order to built sophisticated models that learn large biological systems using big data, I need a level of performance that languages such as R, Python or MATLAB cannot deliver. Two-language approaches, where code is translated into a faster language as a second stage of a project, are popular but also inherently inefficient and can be a source of mistakes and inaccuracy. Julia solves this two-language problem. Due to its easy syntax, Julia gives me a convenient environment for prototyping and algorithm design as well as production ready, high performance code for data-heavy work.
@@ -691,7 +691,7 @@ Third, I use Julia because it is free, open source and because of its community.
## Leandro Martínez [(@lmiq)](https://github.com/m3g)
-I am a computational chemist, and I first heard about Julia in 2015, during a lecture given by a fellow mathematician to an audience largely made up of Fortran programmers (me included). I recall him attempting to persuade us that annotating types with 'local x::Int' or something similar was conceivable and that, as a result, one could do what we used to do in Fortran, namely declare all variables and all types (now that I think I probably misunderstood what he wanted to explain). As a result, I and others felt that there was no compelling reason to learn Julia, because we would get roughly the same results as we did with Fortran, except for plotting libraries and other things, which others were already doing with other tools. After Julia reached 1.0, I decided to take another look at it and began attempting to translate some of my unmaintainable Fortran code to Julia and make it a distributable package. At the time, I had never considered, or even heard of, immutability, assignment and mutation, stack and heap, or SIMD. It's astonishing, and sometimes even embarrassing, that the language's creators, developers of highly complicated core features, massive packages, and academic giants from many disciplines get to answer some of the most basic queries there. I was able to produce better software for my own research by engaging in the community, and I had the pleasure of being invited to speak on molecular simulations in Julia at conferences I never expected to attend. At this moment, I recognize and appreciate my earlier hesitation to adopt Julia: To fully appreciate the language's capabilities, some programming knowledge is required, which does not come necessarily from using Fortran or Python, even for many years. The diversity of notions, from high level to low level, that one is exposed to by programming in Julia is unparalleled, and it leads to this diversified community in which everyone can understand and aid each other. Programming is now a lot more enjoyable. I am grateful to the developer community for believing in this project long before I did, and for their assistance over the past three years of learning and collaboration.
+I am a computational chemist, and I first heard about Julia in 2015, during a lecture given by a fellow mathematician to an audience largely made up of Fortran programmers (me included). I recall him attempting to persuade us that annotating types with 'local x::Int' or something similar was conceivable and that, as a result, one could do what we used to do in Fortran, namely declare all variables and all types (now that I think I probably misunderstood what he wanted to explain). As a result, I and others felt that there was no compelling reason to learn Julia, because we would get roughly the same results as we did with Fortran, except for plotting libraries and other things, which others were already doing with other tools. After Julia reached 1.0, I decided to take another look at it and began attempting to translate some of my unmaintainable Fortran code to Julia and make it a distributable package. At the time, I had never considered, or even heard of, immutability, assignment and mutation, stack and heap, or SIMD. It's astonishing, and sometimes even embarrassing, that the language's creators, developers of highly complicated core features, massive packages, and academic giants from many disciplines get to answer some of the most basic queries there. I was able to produce better software for my own research by engaging in the community, and I had the pleasure of being invited to speak on molecular simulations in Julia at conferences I never expected to attend. At this moment, I recognize and appreciate my earlier hesitation to adopt Julia: To fully appreciate the language's capabilities, some programming knowledge is required, which does not come necessarily from using Fortran or Python, even for many years. The diversity of notions, from high level to low level, that one is exposed to by programming in Julia is unparalleled, and it leads to this diversified community in which everyone can understand and aid each other. Programming is now a lot more enjoyable. I am grateful to the developer community for believing in this project long before I did, and for their assistance over the past three years of learning and collaboration.
## Miguel Raz Guzmán Macedo [(@miguelraz)](https://github.com/miguelraz)
I am a physics undergraduate student at UNAM, in Mexico City. I was very fortunate that some classmates recommended I take David Sanders Computational Physics course, because Julia was the bee's knees and it was the future. I reluctantly signed up because I had heard other professors say that only Fortran was worth anyone's time, but David's lectures and Jupyter notebook demos sold me. At some point I stumbled upon the [julialang.org](julialang.org) links and somehow landed in the Julia Gitter. I met Scott, Chris and Seth, and they answered a bunch of my newbie questions about Julia and I just kept coming back I guess. What really electrified me about Julia was that at some point Stefan or Jeff responded directly to one of my Discourse posts without calling me an idiot and explained some Julia esoterica with great calm (which was *not* my average internet forum experience). That moment felt like lightning in a bottle: The creators of a programming language just hang out? And answer your questions? Online? For free??? That still seems to be a bit of a revolutionary openness to knowledge sharing. I eventually wanted to try and contribute to the language, so I thought the best way to do it was by signing up to the github notifications to the JuliaLang repository. Something strange kept happening - the usual suspects would contribute cool code, but almost every day at midnight this amazing hero of a coder would just answer a swath of PRs and commits and have all theses benchmarks and PRs at the ready. "Who on God's green earth can code like this!??" Their name, I came to find out, was the `nanosoldier`, an automated bot that runs precooked benchmarking scripts - not, unfortunately, an intrepid Australian hero coder I had idolized. And that's how I came to Julia and it's wonderful people. For everything, dear Julians, thank you. Gracias.
diff --git a/blog/2022/04/simple-chains.md b/blog/2022/04/simple-chains.md
index de988cd7a5..9496921f80 100644
--- a/blog/2022/04/simple-chains.md
+++ b/blog/2022/04/simple-chains.md
@@ -26,13 +26,13 @@ This [SciML methodology](https://sciml.ai/roadmap/) has been shown across many d
~~~
-For more details on the software and methods, [see our paper on Universal Differential Equations for Scientific Machine Learning](https://arxiv.org/abs/2001.04385).
+For more details on the software and methods, [see our paper on Universal Differential Equations for Scientific Machine Learning](https://arxiv.org/abs/2001.04385).
The unique aspects of how neural networks are used in these contexts make them rife for performance improvements through specialization. Specifically, in the context of machine learning, one normally relies on the following assumption: the neural networks are large enough that the O(n^3) cost of matrix-matrix multiplication (or other kernels like convolutions) dominates the the runtime. This is essentially the guiding principle behind most of the mechanics of a machine learning library:
1. Matrix-matrix multiplication scales cubicly while memory allocations scale linearly, so attempting to mutate vectors with non-allocating operations is not a high priority. Just use `A*x`.
2. Focus on accelerating GPU kernels to be as fast as possible! Since these large matrix-matrix operations will be fastest on GPUs and are the bottleneck, performance benchmarks will essentially just be a measurement of how fast these specific kernels are.
-3. When doing reverse-mode automatic differentiation (backpropagation), feel free to copy values to memory. Memory allocations will be hidden by the larger kernel calls.
+3. When doing reverse-mode automatic differentiation (backpropagation), feel free to copy values to memory. Memory allocations will be hidden by the larger kernel calls.
4. Also, feel free to write a "tape" for generating backpropagation. The tape does add the cost of essentially building a dictionary during the forward pass, but that will be hidden by the larger kernel calls.
Do these assumptions actually hold in our case? And if they don't, can we focus on these aspects to draw more performance out for our use cases?
@@ -88,7 +88,7 @@ savefig("microopts_blas3.png")
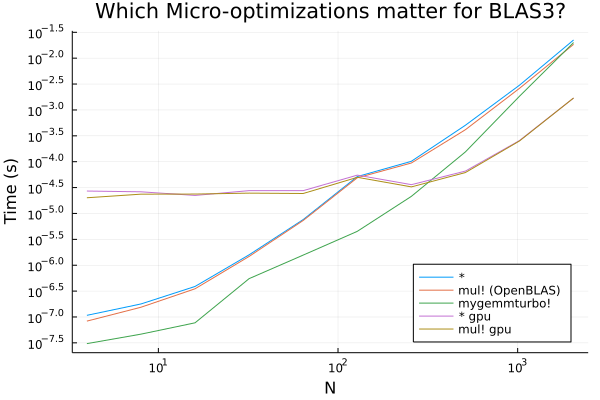
-When we get to larger matrix-matrix operations, such as 100x100 * 100x100, we can effectively write off any overheads due to memory allocations. But we definitely see that there is a potential for some fairly significant performance gains in the lower end! Notice too that these gains are realized by using the pure-Julia LoopVectorization.jl as the standard BLAS tools tend to have extra threading overhead in this region (again, not optimizing as much in this region).
+When we get to larger matrix-matrix operations, such as 100x100 * 100x100, we can effectively write off any overheads due to memory allocations. But we definitely see that there is a potential for some fairly significant performance gains in the lower end! Notice too that these gains are realized by using the pure-Julia LoopVectorization.jl as the standard BLAS tools tend to have extra threading overhead in this region (again, not optimizing as much in this region).
If you have been riding the GPU gospel without looking into the details then this plot may be a shocker! However, GPUs are designed as dumb slow chips with many cores, and thus they are only effective on very parallel operations, such as large matrix-matrix multiplications. It is from this point that assumption (2) is derived for large network operations. But again, in the case of small networks such GPU kernels will be outperformed by well-designed CPU kernels due to the lack of parallel opportunities.
@@ -141,7 +141,7 @@ savefig("microopts_blas2.png")
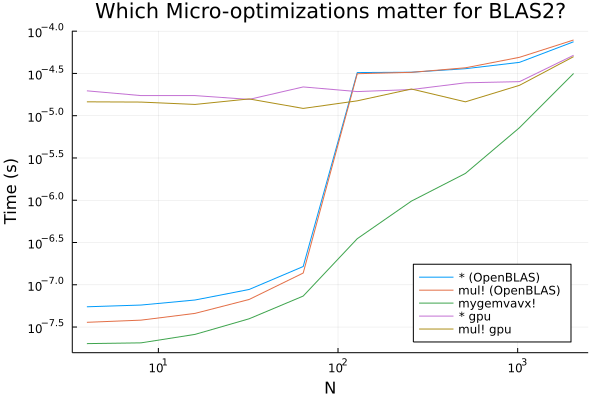
-And remember, the basic operations of a neural network are `sigma.(W*x .+ b)`, and thus there's also an O(n) element-wise operation. As you would guess, this operation becomes more significant as n gets smaller while requiring even more consideration for memory operations.
+And remember, the basic operations of a neural network are `sigma.(W*x .+ b)`, and thus there's also an O(n) element-wise operation. As you would guess, this operation becomes more significant as n gets smaller while requiring even more consideration for memory operations.
```julia
using LinearAlgebra, BenchmarkTools, CUDA, LoopVectorization
@@ -215,7 +215,7 @@ y = σ.(r)
zbar = v .* σbar
Wbar = zbar * x'
bbar = zbar
-xbar = W' * zbar
+xbar = W' * zbar
```
and now cached:
@@ -435,7 +435,7 @@ vs SimpleChains.jl with 16 threads:
└ test = 0.20991518f0
```
-or 10x performace improvement, and on 36 × Intel(R) Core(TM) i9-10980XE CPU @ 3.00GHz we saw for Jax:
+or 10x performance improvement, and on 36 × Intel(R) Core(TM) i9-10980XE CPU @ 3.00GHz we saw for Jax:
```
Initial Train Loss: 6.4232
@@ -759,7 +759,7 @@ Note that smaller batch sizes improve accuracy per epoch, and batch sizes were s
Latency before the first epoch begins training is problematic, but SimpleChains.jl is fast once compiled.
Post-compilation, the 10980XE was competitive with Flux using an A100 GPU, and about 35% faster than the V100.
-The 1165G7, a laptop CPU featuring AVX512, was competitive, handily trouncing any of the competing machine learning libraries when
+The 1165G7, a laptop CPU featuring AVX512, was competitive, handily trouncing any of the competing machine learning libraries when
they were run on far beefier CPUs, and even beat PyTorch on both the V100 and A100. Again, we stress that this test case followed the more typical machine learning
uses and thus was able to use batching to even make GPUs viable: for many use cases of SimpleChains.jl this is not the case and thus
the difference is even larger.
diff --git a/blog/2023/04/julia-1.9-highlights.md b/blog/2023/04/julia-1.9-highlights.md
index 7df5778a05..39b135c421 100644
--- a/blog/2023/04/julia-1.9-highlights.md
+++ b/blog/2023/04/julia-1.9-highlights.md
@@ -156,7 +156,7 @@ This feature was introduced in [#45369]( https://github.com/JuliaLang/julia/pull
*Lilith Hafner*
-The default sorting algorithm has been upgraded to a more adaptive sorting algorithm that is always stable and often has state of the art performance. For simple types and orders—`BitInteger`, `IEEEFloat`, and `Char` sorted in default or reverse order—we use a radix sort that has linear runtime with respect to input size. This effect is especially pronounced for `Float16`s which recieved a 3x-50x speedup over 1.8.
+The default sorting algorithm has been upgraded to a more adaptive sorting algorithm that is always stable and often has state of the art performance. For simple types and orders—`BitInteger`, `IEEEFloat`, and `Char` sorted in default or reverse order—we use a radix sort that has linear runtime with respect to input size. This effect is especially pronounced for `Float16`s which received a 3x-50x speedup over 1.8.
For other types, the default sorting algorithm has been changed to the internal `ScratchQuickSort` in most cases, which is stable and generally faster than `QuickSort`, although it does allocate memory. For situations where memory efficiency is crucial, you can override these new defaults by specifying `alg=QuickSort`.
diff --git a/community/working-groups.md b/community/working-groups.md
index 49f4be8b72..8c947a731b 100644
--- a/community/working-groups.md
+++ b/community/working-groups.md
@@ -58,9 +58,9 @@ Each of these groups is organized around a common area of interest with a commun
### See also
- [GitHub organizations][github-orgs]
-- [Community events calendar][commmunity-events-calendar]
+- [Community events calendar][community-events-calendar]
-[commmunity-events-calendar]: /community/#events
+[community-events-calendar]: /community/#events
[github-orgs]: /community/organizations/
[slack]: /slack
[zulip]: https://julialang.zulipchat.com/
diff --git a/diversity/index.md b/diversity/index.md
index 4a56416392..334382bae4 100644
--- a/diversity/index.md
+++ b/diversity/index.md
@@ -1,6 +1,6 @@
# Diversity
-As a [NumFocus supported project](https://numfocus.org), we abide by their [Code of Conduct and Diversity Statment](https://numfocus.org/code-of-conduct):
+As a [NumFocus supported project](https://numfocus.org), we abide by their [Code of Conduct and Diversity Statement](https://numfocus.org/code-of-conduct):
> NumFOCUS welcomes and encourages participation in our community by people of all backgrounds and identities. We are committed to promoting and sustaining a culture that values mutual respect, tolerance, and learning, and we work together as a community to help each other live out these values.
> We have created this diversity statement because we believe that a diverse community is stronger, more vibrant, and produces better software and better science. A diverse community where people treat each other with respect has more potential contributors, more sources for ideas, and fewer shared assumptions that might hinder development or research.
@@ -17,4 +17,4 @@ Find out more about our ideas for [future initiatives](/diversity/ideas/)
Find out more about our [past initiatives](/diversity/past/)
-__We would like to give a special thank you to all of the Julia Community members working tirelessly on these various Diversity and Inclusion initiates. These individuals are taking time away from their technical work in order to help promote a more inclusive and equitable community, and for that, we are in their debt.__
+__We would like to give a special thank you to all of the Julia Community members working tirelessly on these various Diversity and Inclusion initiates. These individuals are taking time away from their technical work in order to help promote a more inclusive and equitable community, and for that, we are in their debt.__
diff --git a/index.html b/index.html
index d7c8823b63..0aa9a20b70 100644
--- a/index.html
+++ b/index.html
@@ -221,7 +221,7 @@
generalized linear models, decision trees, and clustering.
Flux.jl and Knet.jl are powerful packages for Deep Learning.
Packages such as Metalhead, ObjectDetector, and TextAnalysis.jl provide ready to use pre-trained models for common tasks.
- AlphaZero.jl provides a high peformance implementation of the reinforcement learning algorithms from AlphaZero. Turing.jl is a best in class package for probabilistic programming.
+ AlphaZero.jl provides a high performance implementation of the reinforcement learning algorithms from AlphaZero. Turing.jl is a best in class package for probabilistic programming.
diff --git a/jsoc/gsoc/loopopt.md b/jsoc/gsoc/loopopt.md
index be088f7fb8..a1c5442915 100644
--- a/jsoc/gsoc/loopopt.md
+++ b/jsoc/gsoc/loopopt.md
@@ -14,7 +14,7 @@ Open projects on this effort include:
**Difficulty**: Hard.
**Description**: In order to be able to use LoopModels from Julia, we must be able to apply a custom pass pipeline.
-This is likely something other packages will want to be able to do in the future, and something some packages ([Enzyme.jl](https://github.com/wsmoses/Enzyme.jl)) do already. In this project, your aim will be to create a package that provides infrastructure others can
+This is likely something other packages will want to be able to do in the future, and something some packages ([Enzyme.jl](https://github.com/wsmoses/Enzyme.jl)) do already. In this project, your aim will be to create a package that provides infrastructure others can
depend on to simplify applying custom pass pipelines.
**Expected Results**: Register a package that allows applying custom LLVM pass pipelines to Julia code.
@@ -26,7 +26,7 @@ depend on to simplify applying custom pass pipelines.
## Developing Loop Models (350 hours):
**Difficulty**: Medium.
-**Description**: This is open ended, with many potential projects here. These range from using [Presburger arithmetic](https://dl.acm.org/doi/10.1145/3485539) to [support decidable polyhedral modeling](https://lirias.kuleuven.be/retrieve/361209), working on canonicalizations to handle more kinds of loops frequently encountered from Julia (e.g. from `CartesianIndicies`), modeling the costs of different schedules, to efficiently searching the iteration space and find the fastest way to evaluate a loop nest. We can discuss your interests and find a task you'll enjoy and make substantive contributions to.
+**Description**: This is open ended, with many potential projects here. These range from using [Presburger arithmetic](https://dl.acm.org/doi/10.1145/3485539) to [support decidable polyhedral modeling](https://lirias.kuleuven.be/retrieve/361209), working on canonicalizations to handle more kinds of loops frequently encountered from Julia (e.g. from `CartesianIndices`), modeling the costs of different schedules, to efficiently searching the iteration space and find the fastest way to evaluate a loop nest. We can discuss your interests and find a task you'll enjoy and make substantive contributions to.
**Expected Results**: Help develop some aspect of the loop modeling and/or optimization.
diff --git a/jsoc/gsoc/tables.md b/jsoc/gsoc/tables.md
index 80385477c3..7e8c68fbad 100644
--- a/jsoc/gsoc/tables.md
+++ b/jsoc/gsoc/tables.md
@@ -1,13 +1,13 @@
# Tabular Data – Summer of Code
-## Implement Flashfill in Julia
+## Implement Flashfill in Julia
**Difficulty**: Medium
**Duration**: 350 hours
-*FlashFill* is mechanism for creating data manipulation pipelines using programming by example (PBE). As an example see this [implementation in Microsoft Excel](https://support.microsoft.com/en-us/office/using-flash-fill-in-excel-3f9bcf1e-db93-4890-94a0-1578341f73f7). We want a version of Flashfill that can work against Julia tabular data structures, such as DataFrames and Tables.jl.
+*FlashFill* is mechanism for creating data manipulation pipelines using programming by example (PBE). As an example see this [implementation in Microsoft Excel](https://support.microsoft.com/en-us/office/using-flash-fill-in-excel-3f9bcf1e-db93-4890-94a0-1578341f73f7). We want a version of Flashfill that can work against Julia tabular data structures, such as DataFrames and Tables.jl.
**Resources**:
@@tight-list
@@ -27,9 +27,9 @@
**Difficulty**: Medium
-**Duration**: 175 hours
+**Duration**: 175 hours
-[Apache Parquet](https://parquet.apache.org/) is a binary data format for tabular data. It has features for compression and memory-mapping of datasets on disk. A decent implementation of Parquet in Julia is likely to be highly performant. It will be useful as a standard format for distributing tabular data in a binary format. There exists a Parquet.jl package that has a Parquet reader and a writer. It currently conforms to the Julia Tabular file IO interface at a very basic level. It needs more work to add support for critical elements that would make Parquet.jl usable for fast large scale parallel data processing. Each of these goals can be targetted as a single, short duration (175 hrs) project.
+[Apache Parquet](https://parquet.apache.org/) is a binary data format for tabular data. It has features for compression and memory-mapping of datasets on disk. A decent implementation of Parquet in Julia is likely to be highly performant. It will be useful as a standard format for distributing tabular data in a binary format. There exists a Parquet.jl package that has a Parquet reader and a writer. It currently conforms to the Julia Tabular file IO interface at a very basic level. It needs more work to add support for critical elements that would make Parquet.jl usable for fast large scale parallel data processing. Each of these goals can be targeted as a single, short duration (175 hrs) project.
@@tight-list
* Lazy loading and support for out-of-core processing, with Arrow.jl and Tables.jl integration. Improved usability and performance of Parquet reader and writer for large files.
* Reading from and writing data on to cloud data stores, including support for partitioned data.
@@ -54,7 +54,7 @@
**Difficulty**: Hard
-**Duration**: 175 hours
+**Duration**: 175 hours
[DataFrames.jl](https://github.com/JuliaData/DataFrames.jl) is one of the more popular implementations of tabular data type for Julia. One of the features it supports is data frame joining. However, more work is needed to improve this functionality. The specific targets for this project are (a final list of targets included in the scope of the project can be decided later).
@@tight-list
diff --git a/jsoc/gsoc/turing.md b/jsoc/gsoc/turing.md
index 6a4d4c8337..dcb3eebb50 100644
--- a/jsoc/gsoc/turing.md
+++ b/jsoc/gsoc/turing.md
@@ -31,11 +31,11 @@ Best practices: all models must be checked to be differentiable with all Turing-
Most samplers in Turing.jl implements the AbstractMCMC.jl interface, allowing a unified way for the user to interact with the samplers.
The interface of AbstractMCMC.jl is currently very bare-bones and does not lend itself nicely to interoperability between samplers.
-For example, it’s completely valid to compose to MCMC kernels, e.g. taking one step using the RWMH from AdvancedMH.jl, followed by taking one step using NUTS from AdvancedHMC.jl.
+For example, it’s completely valid to compose to MCMC kernels, e.g. taking one step using the RWMH from AdvancedMH.jl, followed by taking one step using NUTS from AdvancedHMC.jl.
Unfortunately, implementing such a composition requires explicitly defining conversions between the state returned from RWMH and the state returned from NUTS, and conversion of state from NUTS to state of RWMH.
Doing this for one such sampler-pair is generally very easy to do, but once you have to do this for N samplers, suddenly the amount of work needed to be done becomes insurmountable.
-One way to deal alleviate this issue would be to add a simple interface for interacting with the states of the samplers, e.g. a method for getting the current values in the state, a method for setting the current values in the state, in addition to a set of glue-methods which can be overriden in the specific case where more information can be shared between the states.
+One way to deal alleviate this issue would be to add a simple interface for interacting with the states of the samplers, e.g. a method for getting the current values in the state, a method for setting the current values in the state, in addition to a set of glue-methods which can be overridden in the specific case where more information can be shared between the states.
As an example of some ongoing work that attempts to take a step in this direction is: https://github.com/TuringLang/AbstractMCMC.jl/pull/86
diff --git a/learning/classes.md b/learning/classes.md
index 7e8b1883a1..52a7c34eed 100644
--- a/learning/classes.md
+++ b/learning/classes.md
@@ -53,7 +53,7 @@ If you know of other classes using Julia for teaching, please consider [updating
* IIT Indore
* [ApplNLA](https://github.com/ivanslapnicar/GIAN-Applied-NLA-Course), Modern Applications of Numerical Linear Algebra (Prof. [Ivan Slapnicar](http://marjan.fesb.hr/~slap/)), June 2016
* Instituto Tecnológico Autónomo de México (ITAM), Mexico City, Mexico
- * COM 15112 - Paralell and Cloud Computing (Cómputo paralelo y en la nube) (Dr. José Octavio Gutiérrez García)
+ * COM 15112 - Parallel and Cloud Computing (Cómputo paralelo y en la nube) (Dr. José Octavio Gutiérrez García)
* Iowa State University
* [STAT 590F](https://github.com/heike/stat590f), Topics in Statistical Computing: Julia Seminar (Prof. Heike Hofmann), Fall 2014
* Kathmandu University
 @@ -94,7 +94,7 @@ GANs have been extremely suceessful in learning the underlying representation of
LSGAN DCGAN WGAN MADE
~~~
-#### Targets acheived
+#### Targets achieved
1. [`ConvTranspose` layer](https://github.com/FluxML/Flux.jl/pull/311)
2. [DCGAN](https://github.com/tejank10/model-zoo/blob/GAN/vision/mnist/dcgan.jl)
diff --git a/blog/2018/08/adding-newer-features-and-speeding-up-convolutions-in-flux.md b/blog/2018/08/adding-newer-features-and-speeding-up-convolutions-in-flux.md
index 8cdb23ac63..559f5704fa 100644
--- a/blog/2018/08/adding-newer-features-and-speeding-up-convolutions-in-flux.md
+++ b/blog/2018/08/adding-newer-features-and-speeding-up-convolutions-in-flux.md
@@ -2,7 +2,7 @@
@def rss = """ GSoC 2018: Adding Newer Features and Speeding up Convolutions in Flux | Over the summer I have been working at improving the Computer Vision capabilities of Flux. My specific line of work was to __add newer models to the Flux model-zoo__, __implement some new features__ and also __improve the speed of the previous layers__. Specifically, I achieved a __18-fold__ speed up... """
@def published = "13 August 2018"
@def title = "GSoC 2018: Adding Newer Features and Speeding up Convolutions in Flux"
-@def authors = """Avik Pal"""
+@def authors = """Avik Pal"""
@def hascode = true
Over the summer I have been working at improving the Computer Vision capabilities of Flux. My specific line of work was to __add newer models to the Flux model-zoo__, __implement some new features__ and also __improve the speed of the previous layers__. Specifically, I achieved a __18-fold__ speed up for the __Convolutions__ and around __3-fold__ for __BatchNorm__.
@@ -113,7 +113,7 @@ Here's a small demo of the package
### FastStyleTransfer.jl
-This is the implementation of the paper __[Perceptual Losses for Real-Time Style Transfer and Super-Resolution](https://arxiv.org/pdf/1603.08155)__. There are some obvious deviations from the paper. We used the best layer implementations that were currently available in Flux. As for the exact architecture it is still in developement. We provide three pre-trained models with this package. The API has been kept as simple as possible.
+This is the implementation of the paper __[Perceptual Losses for Real-Time Style Transfer and Super-Resolution](https://arxiv.org/pdf/1603.08155)__. There are some obvious deviations from the paper. We used the best layer implementations that were currently available in Flux. As for the exact architecture it is still in development. We provide three pre-trained models with this package. The API has been kept as simple as possible.
Below is a small example of style transfer on MonaLisa
diff --git a/blog/2018/08/union-splitting.md b/blog/2018/08/union-splitting.md
index 15c1c8fe90..0edbe1066d 100644
--- a/blog/2018/08/union-splitting.md
+++ b/blog/2018/08/union-splitting.md
@@ -2,7 +2,7 @@
@def rss = """ Union-splitting: what it is, and why you should care | Among those who follow Julia's development closely, one of the (many) new features causing great excitement is something called "Union-splitting."... """
@def published = "9 August 2018"
@def title = "Union-splitting: what it is, and why you should care"
-@def authors = """Tim Holy"""
+@def authors = """Tim Holy"""
@def hascode = true
Among those who follow Julia's development closely, one of the (many) new features causing great excitement is something called "Union-splitting."
@@ -67,7 +67,7 @@ Worse, if you forgot to check, and `function2` didn't error when you passed it 0
That is far worse than getting an error, because it's much harder to track down where wrong results come from.
In Julia 0.7 and 1.0, Milan Bouchet-Valat rewrote all of our `find*` functions, of which one change (among many) was that `findfirst` now returns `nothing` when it fails to find the requested value.
-Unlike the old approach of returning 0, this return value is truly unambigous and robust against generalizations of indexing where 0 might be a perfectly valid array index.
+Unlike the old approach of returning 0, this return value is truly unambiguous and robust against generalizations of indexing where 0 might be a perfectly valid array index.
It also gives you more reliable code, because if you forget to check, really there's not much you can do with `nothing` that doesn't trigger a (very welcome) error.
And thanks to Union-splitting, it doesn't cause any kind of performance penalty whatsoever.
diff --git a/blog/2019/02/light-graphs.md b/blog/2019/02/light-graphs.md
index ff78cd3131..b5635c57c8 100644
--- a/blog/2019/02/light-graphs.md
+++ b/blog/2019/02/light-graphs.md
@@ -2,7 +2,7 @@
@def rss = """ GSoC 2018 - Parallel Implementations of Graph Analysis Algorithms | This blog briefly summarises my GSoC 2018 project (Parallel Graph Development (https://summerofcode.withgoogle.com/archive/2018/projects/5193483178475520/)) and the results achieved. For a detailed description, please refer to my GSoC blog (https://sohamtamba.github.io/GSoC).... """
@def published = "3 February 2019"
@def title = "GSoC 2018 - Parallel Implementations of Graph Analysis Algorithms"
-@def authors = """Soham Tamba"""
+@def authors = """Soham Tamba"""
This blog briefly summarises my GSoC 2018 project ([Parallel Graph Development](https://summerofcode.withgoogle.com/archive/2018/projects/5193483178475520/)) and the results achieved. For a detailed description, please refer to my [GSoC blog](https://sohamtamba.github.io/GSoC).
@@ -101,7 +101,7 @@ The following branches have been merged into LightGraphs master:
- [Parallel Random Heuristics](https://github.com/SohamTamba/LightGraphs.jl/tree/genrate_reduce)
- [Karger Minimum Cut](https://github.com/SohamTamba/LightGraphs.jl/tree/Karger_min_cut)
- [Multi-threaded Centrality Measures](https://github.com/SohamTamba/LightGraphs.jl/tree/Threaded_Centrality)
- 1. Betweeness Centrality
+ 1. Betweenness Centrality
2. Closeness Centrality
3. Stress Centrality
diff --git a/blog/2019/06/diffeqbot.md b/blog/2019/06/diffeqbot.md
index 71a2115c67..78594222c7 100644
--- a/blog/2019/06/diffeqbot.md
+++ b/blog/2019/06/diffeqbot.md
@@ -2,7 +2,7 @@
@def rss = """ Hello @DiffEqBot | Hi! Today we all got a new member to the DiffEq family. Say hi to our own DiffEqBot (https://github.com/DiffEqBot) - A bot which helps run benchmarks and compares with the current master of a given package. It also generates and stores the Reports generated in a repository (https://github.com/DiffE... """
@def published = "18 June 2019"
@def title = "Hello @DiffEqBot"
-@def authors = """Kanav Gupta"""
+@def authors = """Kanav Gupta"""
@def hascode = true
Hi! Today we all got a new member to the DiffEq family. Say hi to our own [DiffEqBot](https://github.com/DiffEqBot) - A bot which helps run benchmarks and compares with the current master of a given package. It also generates and stores the Reports generated in a [repository](https://github.com/DiffEqBot/Reports). What's special about this is that it is completely stateless (no databases involved at all, just juggling between repositories!) and it has no exposed public URLs. Even though highly inspired by Nanosoldier, this has a completely unique workflow.
@@ -25,7 +25,7 @@ Right now, `DIAGRAMS` cannot be a recursive dictionary, i.e. an element of the d
## How does DiffEqBot work internally?
-DiffEqBot works by jumping accross many repositories and it has been all possible due to awesome APIs both GitHub and Gitlab has provided us with! I will explain the workflow of DiffEqBot in the steps it take to get a particular job done -
+DiffEqBot works by jumping across many repositories and it has been all possible due to awesome APIs both GitHub and Gitlab has provided us with! I will explain the workflow of DiffEqBot in the steps it take to get a particular job done -
1. You make a comment on the pull request to run the benchmarks. With the help of GitHub webhooks, `comment` event is posted on a Heroku app. You get the repository's name and pull request number where this comment is made. It makes sure all the sanity checks, like if the person can run benchmarks or not, or the repository is registered or not etc.
@@ -35,7 +35,7 @@ DiffEqBot works by jumping accross many repositories and it has been all possibl

-3. Here comes the tricky part. We have a seperate dedicated Gitlab private repository called `BenchmarkingRepo` which is basically an empty repository, but plays an important role which would be explained now. DiffEqBot checks out a branch with name formatted as `REPONAME-PR` and generates a Gitlab CI configuration script (`.gitlab-ci.yml`) and makes a commit on this branch. What this configuration does is, pull the PR where the request is made, run the benchmarks, and post the results back to the bot. Basically the script is -
+3. Here comes the tricky part. We have a separate dedicated Gitlab private repository called `BenchmarkingRepo` which is basically an empty repository, but plays an important role which would be explained now. DiffEqBot checks out a branch with name formatted as `REPONAME-PR` and generates a Gitlab CI configuration script (`.gitlab-ci.yml`) and makes a commit on this branch. What this configuration does is, pull the PR where the request is made, run the benchmarks, and post the results back to the bot. Basically the script is -
```yaml
main:
@@ -60,7 +60,7 @@ failed_job:

-5. In the `some_script_to_run_becnhmarks.jl` file, we make a request back to DiffEqBot along with the report in JSON format in the end. When this happens, DiffEqBot makes a commit on the Reports repository on GitHub submitting the markdown script.
+5. In the `some_script_to_run_benchmarks.jl` file, we make a request back to DiffEqBot along with the report in JSON format in the end. When this happens, DiffEqBot makes a commit on the Reports repository on GitHub submitting the markdown script.

@@ -112,7 +112,7 @@ All the configuration of DiffEqBot is done through a file `config.json` in the H
* `github_app.bot_endpoint` - Github App interacts with the Heroku app by a webhook. This is the endpoint where the app should make requests.
* `gitlab_account.benchmarking_repo_id` - Project ID of the BenchmarkingRepo on Gitlab
* `gitlab_account.access_token` - Gitlab Personal Access token of Bot account with repo:write rights.
-* `github_accout.access_token` - Github Personal access token with `public_repo` scope. You can directly generate this [here](https://github.com/settings/tokens/new?description=DiffEqBot&scopes=public_repo).
+* `github_account.access_token` - Github Personal access token with `public_repo` scope. You can directly generate this [here](https://github.com/settings/tokens/new?description=DiffEqBot&scopes=public_repo).
## Access Control and Security
@@ -123,4 +123,4 @@ We have for now given access to only certain members of the organization. We cal
## Shortcomings and Road ahead
-I absolutely love this new member of our community. But it still has several shortcomings. As seen above, due to security concerns, we have allowed only certain members of the organization access to run the benchmarks. Also, we have a basic frontend ready for display of reports, but an even more better design is welcome! We might also need more commands for DiffEqBot than just `runbenchmarks` and `abort`. All these extra features would be a cherry on top. I also plan to make it open source and maintain a proper documentation so that other communities can also deploy this for thier uses and maybe help in its development too!
+I absolutely love this new member of our community. But it still has several shortcomings. As seen above, due to security concerns, we have allowed only certain members of the organization access to run the benchmarks. Also, we have a basic frontend ready for display of reports, but an even more better design is welcome! We might also need more commands for DiffEqBot than just `runbenchmarks` and `abort`. All these extra features would be a cherry on top. I also plan to make it open source and maintain a proper documentation so that other communities can also deploy this for their uses and maybe help in its development too!
diff --git a/blog/2019/09/profilers.md b/blog/2019/09/profilers.md
index 8b2cece1aa..45ba4fda5b 100644
--- a/blog/2019/09/profilers.md
+++ b/blog/2019/09/profilers.md
@@ -2,7 +2,7 @@
@def rss = """ Profiling tools are awesome. They let us see what actually is affecting our program performance. Profiling tools also are terrible. They lie to us and give us confusing information. They also have some surprisingly new developments: [brendangregg's often cloned flamegraphs tool](http://www.brendangregg.com/flamegraphs.html) was created in 2011! So here I will be investigating some ways to make our profile reports better; and looking at ways in which they commonly break, to raise awareness of those artifacts in the reports. """
@def published = "16 September 2019"
@def title = "Profiling tool wins and woes"
-@def authors = """Jameson Nash"""
+@def authors = """Jameson Nash"""
@def hascode=true
Profiling tools are awesome. They let us see what actually is affecting our program performance. Profiling tools also are terrible. They lie to us and give us confusing information. They also have some surprisingly new developments: [brendangregg's often cloned flamegraphs tool](http://www.brendangregg.com/flamegraphs.html) was created in 2011! So here I will be investigating some ways to make our profile reports better; and looking at ways in which they commonly break, to raise awareness of those artifacts in the reports.
@@ -385,7 +385,7 @@ julia> Profile.print(format=:tree, recur=:flat)
Total snapshots: 629
```
-I think this looks cool, and vaguely even shows how I would conceptualize the functions in my head. This is availble right now only on [my jn/profile-recurflat](https://github.com/JuliaLang/julia/tree/jn/profile-recurflat) branch, but should be a PR soon, and show up in the JuliaLang v1.4 release.
+I think this looks cool, and vaguely even shows how I would conceptualize the functions in my head. This is available right now only on [my jn/profile-recurflat](https://github.com/JuliaLang/julia/tree/jn/profile-recurflat) branch, but should be a PR soon, and show up in the JuliaLang v1.4 release.
## Final thoughts
diff --git a/blog/2020/08/invalidations.md b/blog/2020/08/invalidations.md
index 1664f28e6f..0327dae666 100644
--- a/blog/2020/08/invalidations.md
+++ b/blog/2020/08/invalidations.md
@@ -111,7 +111,7 @@ To improve performance, it checks (as efficiently as possible at runtime) whethe
and if so calls the method it knows.
In this case, `f` just returns a constant, so when applicable the compiler even hard-wires in the return value for you.
-However, the compiler also acknowledges the possiblity that `container[1]` *won't* be an `Int`.
+However, the compiler also acknowledges the possibility that `container[1]` *won't* be an `Int`.
That allows the above code to throw a MethodError:
```julia-repl
@@ -365,7 +365,7 @@ and so loading the SIMD package triggers invalidation of everything that depends
As is usually the case, there are several ways to fix this: we could drop the `::Tuple` in the definition of `struct CallWaitMsg`, because there's no need to call `convert` if the object is already known to have the correct type (which would be `Any` if we dropped the field type-specification, and `Any` is not restrictive). Alternatively, we could keep the `::Tuple` in the type-specification, and use external knowledge that we have and assert that `args` is *already* a `Tuple` in `deserialize_msg` where it calls `CallWaitMsg`, thus informing Julia that it can afford to skip the call to `convert`.
This is intended only as a taste of what's involved in fixing invalidations; more extensive descriptions are available in [SnoopCompile's documentation](https://timholy.github.io/SnoopCompile.jl/stable/snoopr/) and the [video](https://www.youtube.com/watch?v=7VbXbI6OmYo).
-But it also conveys an important point: most invalidations come from poorly-inferred code, so by fixing invalidations you're often improving quality in other ways. Julia's [performance tips] page has a wealth of good advice about avoiding non-inferrable code, and in particular cases (where you might know more about the types than inference is able to determine on its own) you can help inference by adding type-assertions.
+But it also conveys an important point: most invalidations come from poorly-inferred code, so by fixing invalidations you're often improving quality in other ways. Julia's [performance tips] page has a wealth of good advice about avoiding non-inferable code, and in particular cases (where you might know more about the types than inference is able to determine on its own) you can help inference by adding type-assertions.
Again, some of the recently-merged "latency" pull requests to Julia might serve as instructive examples.
## Summary
diff --git a/blog/2020/09/juliacon-2020-open-source-bof-follow-up.md b/blog/2020/09/juliacon-2020-open-source-bof-follow-up.md
index d7ff2210b4..9a059a0b7b 100644
--- a/blog/2020/09/juliacon-2020-open-source-bof-follow-up.md
+++ b/blog/2020/09/juliacon-2020-open-source-bof-follow-up.md
@@ -66,7 +66,7 @@ One difficulty reported during the BoF was getting organizational approval to re
#### Open Sourcing Packages That Previously Used Internal CI/CD
-One important element of successful open-source projects is that CI logs should generally be available to all contributors. This can be a burdensome criteria to meet if a previously closed-source package utilized internal CI/CD pipelines with nicer properties than publicly available CI pipelines. In some instances, certain flavors of this problem can be solved with better tooling, e.g. self-hosted (but publically accessible) package registries can vendor open-sourced packages just as nicely as Julia's General Registry, but might leverage custom CI/CD for pre-registration checks.
+One important element of successful open-source projects is that CI logs should generally be available to all contributors. This can be a burdensome criteria to meet if a previously closed-source package utilized internal CI/CD pipelines with nicer properties than publicly available CI pipelines. In some instances, certain flavors of this problem can be solved with better tooling, e.g. self-hosted (but publicly accessible) package registries can vendor open-sourced packages just as nicely as Julia's General Registry, but might leverage custom CI/CD for pre-registration checks.
#### Open Source Efforts Could Reveal Strategic Intent
diff --git a/blog/2021/01/precompile_tutorial.md b/blog/2021/01/precompile_tutorial.md
index 293491b86b..23f100b95a 100644
--- a/blog/2021/01/precompile_tutorial.md
+++ b/blog/2021/01/precompile_tutorial.md
@@ -663,8 +663,8 @@ precompile(dopush, ())
then the `MethodInstance` for `push!(::Vector{SCDType}, ::SCDType)` will be added to the package through the backedge to `dopush` (which you do own).
-This was an artifical example, but in more typical cases this happens organically through the functionality of your package.
-But again, this works only for inferrable calls.
+This was an artificial example, but in more typical cases this happens organically through the functionality of your package.
+But again, this works only for inferable calls.
@@
[package mode]: https://julialang.github.io/Pkg.jl/v1/getting-started/#Basic-Usage
diff --git a/blog/2021/01/snoopi_deep.md b/blog/2021/01/snoopi_deep.md
index b1bdab5ef5..44a722fe8d 100644
--- a/blog/2021/01/snoopi_deep.md
+++ b/blog/2021/01/snoopi_deep.md
@@ -9,7 +9,7 @@ In the [first post](https://julialang.org/blog/2021/01/precompile_tutorial/), we
We also pointed out that precompilation is closely tied to *type inference*:
- precompilation allows you to cache the results of type inference, thus saving time when you start using methods defined in the package
-- caching becomes more effective when a higher proportion of calls are made with inferrable argument types (i.e., type-inference "succeeds"). Successful inference introduces links, in the form of `MethodInstance` backedges, that permit the entire call graph to be cached.
+- caching becomes more effective when a higher proportion of calls are made with inferable argument types (i.e., type-inference "succeeds"). Successful inference introduces links, in the form of `MethodInstance` backedges, that permit the entire call graph to be cached.
As a consequence, anyone interested in precompilation needs to pay attention to type inference: how much time does it account for, where is it spending its time, and what can be done to improve caching?
Julia itself provides the internal infrastructure needed to "spy" on inference, and the user-space utilities are in the [SnoopCompile] package.
diff --git a/blog/2021/03/julia-1.6-highlights.md b/blog/2021/03/julia-1.6-highlights.md
index 266c48d91e..ee56216740 100644
--- a/blog/2021/03/julia-1.6-highlights.md
+++ b/blog/2021/03/julia-1.6-highlights.md
@@ -255,7 +255,7 @@ possible. By limiting the number of backedges and data structures, as well as
centralizing the template pieces of code that each JLL package uses, we are
able to not only vastly improve load times, but improve compile times as well!
As an added bonus, improvements to JLL package APIs can now be made directly in
-`JLLWappers.jl` without needing to re-deploy hundreds of JLLs. Because these
+`JLLWrappers.jl` without needing to re-deploy hundreds of JLLs. Because these
JLL packages only define a thin wrapper around simple, lightweight functions
that load libraries and return paths and such, they do not benefit from the
heavy optimization that most Julia code undergoes. One final piece of the
diff --git a/blog/2021/08/sharks.md b/blog/2021/08/sharks.md
index 6d39212eec..387402c385 100644
--- a/blog/2021/08/sharks.md
+++ b/blog/2021/08/sharks.md
@@ -270,7 +270,7 @@ For example, the side-to-side force has the same frequency as the swimming motio
This simple model is a great start and it opens up a ton of avenues for improving the shark simulation and suggesting research questions:
- The instantaneous net forces should be zero in a free swimming body! We could add reaction motions to our model to achieve this. Would the model shark swim in a straight line if we did this, or is a control-loop needed?
- Real sharks are 3D (gasp!). While we could easily extend this approach using 2D splines, it will take much longer to simulate. Is there a way use GPUs to accelerate the simulations without completely changing the solver?
- - If we were going to make a bio-inspired robot of this shark, we will have constraints on the shape and motion and powering available. Can we use this framework to help optimize our robotic within it's contraints?
+ - If we were going to make a bio-inspired robot of this shark, we will have constraints on the shape and motion and powering available. Can we use this framework to help optimize our robotic within it's constraints?
Below you can find links to all the packages used in this notebook. Happy Simulating!
diff --git a/blog/2021/11/julia-1.7-highlights.md b/blog/2021/11/julia-1.7-highlights.md
index f79a61da19..eb73daecdd 100644
--- a/blog/2021/11/julia-1.7-highlights.md
+++ b/blog/2021/11/julia-1.7-highlights.md
@@ -398,7 +398,7 @@ julia (v1.6)> @btime reshape([1; 2; 3; 4], (1, 2, 1, 2)); # fast, but intent les
65.884 ns (2 allocations: 192 bytes)
```
-This is a substantial improvement in performance for this basic operation, and the differential improves greatly as more dimensions become invovled.
+This is a substantial improvement in performance for this basic operation, and the differential improves greatly as more dimensions become involved.
For ease of reading a larger array expression, line breaks are of course tolerated:
```julia-repl
diff --git a/blog/2021/12/dtable-performance-assessment.md b/blog/2021/12/dtable-performance-assessment.md
index 5d63c65334..4a8b1514f2 100644
--- a/blog/2021/12/dtable-performance-assessment.md
+++ b/blog/2021/12/dtable-performance-assessment.md
@@ -45,7 +45,7 @@ The `DTable` aims to excel in two areas:
- parallelization of data processing
- out-of-core processing (will be available through future `Dagger.jl` upgrades)
-The goal is to become competitive with similiar tools, such as `Dask` or `Spark`, so that Julia users can solve and scale their problems within Julia.
+The goal is to become competitive with similar tools, such as `Dask` or `Spark`, so that Julia users can solve and scale their problems within Julia.
By leveraging the composability of the Julia data ecosystem, we can reuse a lot of existing functionality in order to achieve the above goals, and continue improving the solution in the future instead of just creating another monolithic solution.
@@ -134,7 +134,7 @@ DTable command: `map(row -> (r = row.a1 + 1,), d)`
As the set of values is limited, a simple filter expression was chosen, which filters out approximately half of the records (command below).
-In this scenario, the parallelization and partitioning overhead doesn't pay off as well as both `DTable` and `Dask` are noticably slower than `DataFrames.jl`.
+In this scenario, the parallelization and partitioning overhead doesn't pay off as well as both `DTable` and `Dask` are noticeably slower than `DataFrames.jl`.
When it comes to the comparison of these two implementations, the performance looks very similiar with `Dask` being on average 1.6 times faster than the `DTable`.
The scaling of the `DTable` allows it to catch up to `DataFrames` at the largest data size. It's possible that this behavior may continue at larger data sizes and eventually provide a speedup versus `DataFrames` after some threshold.
@@ -203,7 +203,7 @@ DTable command: `Dagger.groupby(d, :a1)`
## Grouped reduction (single column)
Mimicking the success of reduction benchmarks, the `DTable` is again performing better here than the direct competition.
-For the single column reductions, it's an average ~20.2 times speedup over `Dask`, and their scaling behavior looks very similiar.
+For the single column reductions, it's an average ~20.2 times speedup over `Dask`, and their scaling behavior looks very similar.
Contrary to the standard reduction benchmarks, the `DTable` doesn't offer a speedup compared to `DataFrames.jl` across all the data sizes.
It looks like the current algorithm has a significant overhead that can be observed as a lower bound to the performance at smaller data sizes.
@@ -217,7 +217,7 @@ DTable command: `r = reduce(fit!, g, cols=[:a2], init=Mean())`
## Grouped reduction (all columns)
-The results for the all-columns reduction look very similiar to single-column.
+The results for the all-columns reduction look very similar to single-column.
The `DTable` managed to offer an average ~22.3 times speeup over `Dask`.
Again, the `DTable` is heavily falling behind `DataFrames.jl` on smaller data sizes due to the significant entry overhead acting as a lower performance bound at smaller data sizes.
@@ -253,7 +253,7 @@ We hope to include all the necessary fixes in future patches to Julia 1.7.
The `DTable` has successfully passed the proof-of-concept stage and is currently under active development as a part of the `Dagger.jl` package.
-This early performance assessment has confirmed that the `DTable` has the potential to become a competetive tool for processing tabular data.
+This early performance assessment has confirmed that the `DTable` has the potential to become a competitive tool for processing tabular data.
It managed to perform significantly better than direct competition (`Dask`) in 6 out of 7 presented benchmarks and in the remaining one it doesn't fall too far behind.
While this looks promising there's still a lot of work ahead in order to make the `DTable` feature-rich and even faster, so keep an eye out for future updates on the project.
diff --git a/blog/2022/02/10years.md b/blog/2022/02/10years.md
index 052dce1cbd..256c1c326f 100644
--- a/blog/2022/02/10years.md
+++ b/blog/2022/02/10years.md
@@ -218,7 +218,7 @@ Even more exciting than the software itself was the vibrant open source communit
## Francesco Martinuzzi [(@MartinuzziFrancesco)](https://github.com/MartinuzziFrancesco)
-I encountered Julia when I was looking for an alternative to Python to use for my master thesis. At the time I was mainly a Fortran user, as many physics students still are, and Python felt unbelievably slow. I stumbled into Julia almost by chance in looking for something in beetween these two languages. What most amazes me about the language is not the technical feats in itself, but it is how much Julia and its community are intertwined. Coming from a world in which code is handed down from supervisor to student, with little to no explanation or comments, this was something I valued incredibly.
+I encountered Julia when I was looking for an alternative to Python to use for my master thesis. At the time I was mainly a Fortran user, as many physics students still are, and Python felt unbelievably slow. I stumbled into Julia almost by chance in looking for something in between these two languages. What most amazes me about the language is not the technical feats in itself, but it is how much Julia and its community are intertwined. Coming from a world in which code is handed down from supervisor to student, with little to no explanation or comments, this was something I valued incredibly.
I was lucky enough to start contributing to the [SciML](https://sciml.ai/) organization in the summer of 2020 as part of the [Google Summer of Code](https://summerofcode.withgoogle.com/) program working on [ReservoirComputing.jl](https://github.com/SciML/ReservoirComputing.jl). This also was the start of my personal journey into contributing to open source software, and the Julia language made that an incredibly easy transition.
@@ -447,7 +447,7 @@ From the first time I heard about Julia in Alan’s office in 2011, Julia has br
## Panagiotis Georgakopoulos [(@pankgeorg)](https://github.com/pankgeorg)
-I was introduced to Julia by the MIT - Computational Thinking course. That was start of the quarantine era and I was cruising online resources to understand scientific computing a bit more. Coming from the front-end world of computing, I found Julia amazing because of its unique integration with HTML through Pluto. I started contributing to the Pluto.jl project - initially by fixing some CSS, then some React and finally diving deeper into Pluto's internals. Pluto's appearance in the Julia ecosystem is no accident; Julia is _so_ friendly when it comes to `show`ing stuff in HTML. Alongside its speed, which enables lag-free interaction, Julia creates the perfect environment for interactive programming and I feel glad and priviledged to be part of the journey!
+I was introduced to Julia by the MIT - Computational Thinking course. That was start of the quarantine era and I was cruising online resources to understand scientific computing a bit more. Coming from the front-end world of computing, I found Julia amazing because of its unique integration with HTML through Pluto. I started contributing to the Pluto.jl project - initially by fixing some CSS, then some React and finally diving deeper into Pluto's internals. Pluto's appearance in the Julia ecosystem is no accident; Julia is _so_ friendly when it comes to `show`ing stuff in HTML. Alongside its speed, which enables lag-free interaction, Julia creates the perfect environment for interactive programming and I feel glad and privileged to be part of the journey!
## Huda Nassar [(@nassarhuda)](https://github.com/nassarhuda)
@@ -683,7 +683,7 @@ I had my first experience with Julia in Spring 2019, while in 18.06 (Linear Alge
My first encounter with the Julia language happened in fall of 2014. At the time I was quite young, but enthused by Computational Science, I was using primarily Python and R for these two tasks. I had worked on several projects with peers where we would hit the " Two Language Problem," and it got to be really frustrating. I was the only member of the team who could write C, and Cython wasn't really helping our problem as much as one might expect. Back then, tools like Numba and remote Python interpretation were not even close to where they are now, and I was looking for more information on getting Python to run faster when I stumbled across a Julia forum post. I was intrigued by the syntax, and since picking up Julia on that day, it has become my favorite programming language. I was able to solve our problem in Julia, rather than C, and I was able to call our Python code when needed via PyCall.jl. It ended up working perfectly, so I used it for projects with these sorts of problems each time they came into fruition. The language just kept doing fantastic, and then all of the changes that kept coming to the language were all just so great. Now the language has a venerable ecosystem to go along with it, so things have only gotten better.
-## Elisabeth Roesch [(@ElisabethRoesch)](https://github.com/ElisabethRoesch)
+## Elisabeth Roesch [(@ElisabethRoesch)](https://github.com/ElisabethRoesch)
As a systems biologist, I form part of a very interdisciplinary field. I work in teams of biologists, mathematicians, computer scientists and more. Leveraging expertise of multiple domains is key for many hard problems in the field. One key aspect I consider when choosing my programming language is how it enables collaborations. A focus of Julia’s language design is abstraction and its implied modularity and composability. The effect that this design emphasis has on my day to day work of collaborating with other researchers is hard to describe in only a few words. Simple, yet clear syntax as well as elegant technical features, such as multiple dispatch, solve the expression problem and make it convenient to reuse, adapt and extend existing code of collaborators. Additionally, exploiting Julia’s rich package ecosystems is made easy, too.
Second, Julia is fast. In the biological sciences, the amount of data at our fingertips is growing rapidly. Software that scales well is of great importance. In order to built sophisticated models that learn large biological systems using big data, I need a level of performance that languages such as R, Python or MATLAB cannot deliver. Two-language approaches, where code is translated into a faster language as a second stage of a project, are popular but also inherently inefficient and can be a source of mistakes and inaccuracy. Julia solves this two-language problem. Due to its easy syntax, Julia gives me a convenient environment for prototyping and algorithm design as well as production ready, high performance code for data-heavy work.
@@ -691,7 +691,7 @@ Third, I use Julia because it is free, open source and because of its community.
## Leandro Martínez [(@lmiq)](https://github.com/m3g)
-I am a computational chemist, and I first heard about Julia in 2015, during a lecture given by a fellow mathematician to an audience largely made up of Fortran programmers (me included). I recall him attempting to persuade us that annotating types with 'local x::Int' or something similar was conceivable and that, as a result, one could do what we used to do in Fortran, namely declare all variables and all types (now that I think I probably misunderstood what he wanted to explain). As a result, I and others felt that there was no compelling reason to learn Julia, because we would get roughly the same results as we did with Fortran, except for plotting libraries and other things, which others were already doing with other tools. After Julia reached 1.0, I decided to take another look at it and began attempting to translate some of my unmaintainable Fortran code to Julia and make it a distributable package. At the time, I had never considered, or even heard of, immutability, assignment and mutation, stack and heap, or SIMD. It's astonishing, and sometimes even embarrassing, that the language's creators, developers of highly complicated core features, massive packages, and academic giants from many disciplines get to answer some of the most basic queries there. I was able to produce better software for my own research by engaging in the community, and I had the pleasure of being invited to speak on molecular simulations in Julia at conferences I never expected to attend. At this moment, I recognize and appreciate my earlier hesitation to adopt Julia: To fully appreciate the language's capabilities, some programming knowledge is required, which does not come necessarily from using Fortran or Python, even for many years. The diversity of notions, from high level to low level, that one is exposed to by programming in Julia is unparalleled, and it leads to this diversified community in which everyone can understand and aid each other. Programming is now a lot more enjoyable. I am grateful to the developer community for believing in this project long before I did, and for their assistance over the past three years of learning and collaboration.
+I am a computational chemist, and I first heard about Julia in 2015, during a lecture given by a fellow mathematician to an audience largely made up of Fortran programmers (me included). I recall him attempting to persuade us that annotating types with 'local x::Int' or something similar was conceivable and that, as a result, one could do what we used to do in Fortran, namely declare all variables and all types (now that I think I probably misunderstood what he wanted to explain). As a result, I and others felt that there was no compelling reason to learn Julia, because we would get roughly the same results as we did with Fortran, except for plotting libraries and other things, which others were already doing with other tools. After Julia reached 1.0, I decided to take another look at it and began attempting to translate some of my unmaintainable Fortran code to Julia and make it a distributable package. At the time, I had never considered, or even heard of, immutability, assignment and mutation, stack and heap, or SIMD. It's astonishing, and sometimes even embarrassing, that the language's creators, developers of highly complicated core features, massive packages, and academic giants from many disciplines get to answer some of the most basic queries there. I was able to produce better software for my own research by engaging in the community, and I had the pleasure of being invited to speak on molecular simulations in Julia at conferences I never expected to attend. At this moment, I recognize and appreciate my earlier hesitation to adopt Julia: To fully appreciate the language's capabilities, some programming knowledge is required, which does not come necessarily from using Fortran or Python, even for many years. The diversity of notions, from high level to low level, that one is exposed to by programming in Julia is unparalleled, and it leads to this diversified community in which everyone can understand and aid each other. Programming is now a lot more enjoyable. I am grateful to the developer community for believing in this project long before I did, and for their assistance over the past three years of learning and collaboration.
## Miguel Raz Guzmán Macedo [(@miguelraz)](https://github.com/miguelraz)
I am a physics undergraduate student at UNAM, in Mexico City. I was very fortunate that some classmates recommended I take David Sanders Computational Physics course, because Julia was the bee's knees and it was the future. I reluctantly signed up because I had heard other professors say that only Fortran was worth anyone's time, but David's lectures and Jupyter notebook demos sold me. At some point I stumbled upon the [julialang.org](julialang.org) links and somehow landed in the Julia Gitter. I met Scott, Chris and Seth, and they answered a bunch of my newbie questions about Julia and I just kept coming back I guess. What really electrified me about Julia was that at some point Stefan or Jeff responded directly to one of my Discourse posts without calling me an idiot and explained some Julia esoterica with great calm (which was *not* my average internet forum experience). That moment felt like lightning in a bottle: The creators of a programming language just hang out? And answer your questions? Online? For free??? That still seems to be a bit of a revolutionary openness to knowledge sharing. I eventually wanted to try and contribute to the language, so I thought the best way to do it was by signing up to the github notifications to the JuliaLang repository. Something strange kept happening - the usual suspects would contribute cool code, but almost every day at midnight this amazing hero of a coder would just answer a swath of PRs and commits and have all theses benchmarks and PRs at the ready. "Who on God's green earth can code like this!??" Their name, I came to find out, was the `nanosoldier`, an automated bot that runs precooked benchmarking scripts - not, unfortunately, an intrepid Australian hero coder I had idolized. And that's how I came to Julia and it's wonderful people. For everything, dear Julians, thank you. Gracias.
diff --git a/blog/2022/04/simple-chains.md b/blog/2022/04/simple-chains.md
index de988cd7a5..9496921f80 100644
--- a/blog/2022/04/simple-chains.md
+++ b/blog/2022/04/simple-chains.md
@@ -26,13 +26,13 @@ This [SciML methodology](https://sciml.ai/roadmap/) has been shown across many d
~~~
-For more details on the software and methods, [see our paper on Universal Differential Equations for Scientific Machine Learning](https://arxiv.org/abs/2001.04385).
+For more details on the software and methods, [see our paper on Universal Differential Equations for Scientific Machine Learning](https://arxiv.org/abs/2001.04385).
The unique aspects of how neural networks are used in these contexts make them rife for performance improvements through specialization. Specifically, in the context of machine learning, one normally relies on the following assumption: the neural networks are large enough that the O(n^3) cost of matrix-matrix multiplication (or other kernels like convolutions) dominates the the runtime. This is essentially the guiding principle behind most of the mechanics of a machine learning library:
1. Matrix-matrix multiplication scales cubicly while memory allocations scale linearly, so attempting to mutate vectors with non-allocating operations is not a high priority. Just use `A*x`.
2. Focus on accelerating GPU kernels to be as fast as possible! Since these large matrix-matrix operations will be fastest on GPUs and are the bottleneck, performance benchmarks will essentially just be a measurement of how fast these specific kernels are.
-3. When doing reverse-mode automatic differentiation (backpropagation), feel free to copy values to memory. Memory allocations will be hidden by the larger kernel calls.
+3. When doing reverse-mode automatic differentiation (backpropagation), feel free to copy values to memory. Memory allocations will be hidden by the larger kernel calls.
4. Also, feel free to write a "tape" for generating backpropagation. The tape does add the cost of essentially building a dictionary during the forward pass, but that will be hidden by the larger kernel calls.
Do these assumptions actually hold in our case? And if they don't, can we focus on these aspects to draw more performance out for our use cases?
@@ -88,7 +88,7 @@ savefig("microopts_blas3.png")

-When we get to larger matrix-matrix operations, such as 100x100 * 100x100, we can effectively write off any overheads due to memory allocations. But we definitely see that there is a potential for some fairly significant performance gains in the lower end! Notice too that these gains are realized by using the pure-Julia LoopVectorization.jl as the standard BLAS tools tend to have extra threading overhead in this region (again, not optimizing as much in this region).
+When we get to larger matrix-matrix operations, such as 100x100 * 100x100, we can effectively write off any overheads due to memory allocations. But we definitely see that there is a potential for some fairly significant performance gains in the lower end! Notice too that these gains are realized by using the pure-Julia LoopVectorization.jl as the standard BLAS tools tend to have extra threading overhead in this region (again, not optimizing as much in this region).
If you have been riding the GPU gospel without looking into the details then this plot may be a shocker! However, GPUs are designed as dumb slow chips with many cores, and thus they are only effective on very parallel operations, such as large matrix-matrix multiplications. It is from this point that assumption (2) is derived for large network operations. But again, in the case of small networks such GPU kernels will be outperformed by well-designed CPU kernels due to the lack of parallel opportunities.
@@ -141,7 +141,7 @@ savefig("microopts_blas2.png")

-And remember, the basic operations of a neural network are `sigma.(W*x .+ b)`, and thus there's also an O(n) element-wise operation. As you would guess, this operation becomes more significant as n gets smaller while requiring even more consideration for memory operations.
+And remember, the basic operations of a neural network are `sigma.(W*x .+ b)`, and thus there's also an O(n) element-wise operation. As you would guess, this operation becomes more significant as n gets smaller while requiring even more consideration for memory operations.
```julia
using LinearAlgebra, BenchmarkTools, CUDA, LoopVectorization
@@ -215,7 +215,7 @@ y = σ.(r)
zbar = v .* σbar
Wbar = zbar * x'
bbar = zbar
-xbar = W' * zbar
+xbar = W' * zbar
```
and now cached:
@@ -435,7 +435,7 @@ vs SimpleChains.jl with 16 threads:
└ test = 0.20991518f0
```
-or 10x performace improvement, and on 36 × Intel(R) Core(TM) i9-10980XE CPU @ 3.00GHz we saw for Jax:
+or 10x performance improvement, and on 36 × Intel(R) Core(TM) i9-10980XE CPU @ 3.00GHz we saw for Jax:
```
Initial Train Loss: 6.4232
@@ -759,7 +759,7 @@ Note that smaller batch sizes improve accuracy per epoch, and batch sizes were s
Latency before the first epoch begins training is problematic, but SimpleChains.jl is fast once compiled.
Post-compilation, the 10980XE was competitive with Flux using an A100 GPU, and about 35% faster than the V100.
-The 1165G7, a laptop CPU featuring AVX512, was competitive, handily trouncing any of the competing machine learning libraries when
+The 1165G7, a laptop CPU featuring AVX512, was competitive, handily trouncing any of the competing machine learning libraries when
they were run on far beefier CPUs, and even beat PyTorch on both the V100 and A100. Again, we stress that this test case followed the more typical machine learning
uses and thus was able to use batching to even make GPUs viable: for many use cases of SimpleChains.jl this is not the case and thus
the difference is even larger.
diff --git a/blog/2023/04/julia-1.9-highlights.md b/blog/2023/04/julia-1.9-highlights.md
index 7df5778a05..39b135c421 100644
--- a/blog/2023/04/julia-1.9-highlights.md
+++ b/blog/2023/04/julia-1.9-highlights.md
@@ -156,7 +156,7 @@ This feature was introduced in [#45369]( https://github.com/JuliaLang/julia/pull
*Lilith Hafner*
-The default sorting algorithm has been upgraded to a more adaptive sorting algorithm that is always stable and often has state of the art performance. For simple types and orders—`BitInteger`, `IEEEFloat`, and `Char` sorted in default or reverse order—we use a radix sort that has linear runtime with respect to input size. This effect is especially pronounced for `Float16`s which recieved a 3x-50x speedup over 1.8.
+The default sorting algorithm has been upgraded to a more adaptive sorting algorithm that is always stable and often has state of the art performance. For simple types and orders—`BitInteger`, `IEEEFloat`, and `Char` sorted in default or reverse order—we use a radix sort that has linear runtime with respect to input size. This effect is especially pronounced for `Float16`s which received a 3x-50x speedup over 1.8.
For other types, the default sorting algorithm has been changed to the internal `ScratchQuickSort` in most cases, which is stable and generally faster than `QuickSort`, although it does allocate memory. For situations where memory efficiency is crucial, you can override these new defaults by specifying `alg=QuickSort`.
diff --git a/community/working-groups.md b/community/working-groups.md
index 49f4be8b72..8c947a731b 100644
--- a/community/working-groups.md
+++ b/community/working-groups.md
@@ -58,9 +58,9 @@ Each of these groups is organized around a common area of interest with a commun
### See also
- [GitHub organizations][github-orgs]
-- [Community events calendar][commmunity-events-calendar]
+- [Community events calendar][community-events-calendar]
-[commmunity-events-calendar]: /community/#events
+[community-events-calendar]: /community/#events
[github-orgs]: /community/organizations/
[slack]: /slack
[zulip]: https://julialang.zulipchat.com/
diff --git a/diversity/index.md b/diversity/index.md
index 4a56416392..334382bae4 100644
--- a/diversity/index.md
+++ b/diversity/index.md
@@ -1,6 +1,6 @@
# Diversity
-As a [NumFocus supported project](https://numfocus.org), we abide by their [Code of Conduct and Diversity Statment](https://numfocus.org/code-of-conduct):
+As a [NumFocus supported project](https://numfocus.org), we abide by their [Code of Conduct and Diversity Statement](https://numfocus.org/code-of-conduct):
> NumFOCUS welcomes and encourages participation in our community by people of all backgrounds and identities. We are committed to promoting and sustaining a culture that values mutual respect, tolerance, and learning, and we work together as a community to help each other live out these values.
> We have created this diversity statement because we believe that a diverse community is stronger, more vibrant, and produces better software and better science. A diverse community where people treat each other with respect has more potential contributors, more sources for ideas, and fewer shared assumptions that might hinder development or research.
@@ -17,4 +17,4 @@ Find out more about our ideas for [future initiatives](/diversity/ideas/)
Find out more about our [past initiatives](/diversity/past/)
-__We would like to give a special thank you to all of the Julia Community members working tirelessly on these various Diversity and Inclusion initiates. These individuals are taking time away from their technical work in order to help promote a more inclusive and equitable community, and for that, we are in their debt.__
+__We would like to give a special thank you to all of the Julia Community members working tirelessly on these various Diversity and Inclusion initiates. These individuals are taking time away from their technical work in order to help promote a more inclusive and equitable community, and for that, we are in their debt.__
diff --git a/index.html b/index.html
index d7c8823b63..0aa9a20b70 100644
--- a/index.html
+++ b/index.html
@@ -221,7 +221,7 @@
@@ -94,7 +94,7 @@ GANs have been extremely suceessful in learning the underlying representation of
LSGAN DCGAN WGAN MADE
~~~
-#### Targets acheived
+#### Targets achieved
1. [`ConvTranspose` layer](https://github.com/FluxML/Flux.jl/pull/311)
2. [DCGAN](https://github.com/tejank10/model-zoo/blob/GAN/vision/mnist/dcgan.jl)
diff --git a/blog/2018/08/adding-newer-features-and-speeding-up-convolutions-in-flux.md b/blog/2018/08/adding-newer-features-and-speeding-up-convolutions-in-flux.md
index 8cdb23ac63..559f5704fa 100644
--- a/blog/2018/08/adding-newer-features-and-speeding-up-convolutions-in-flux.md
+++ b/blog/2018/08/adding-newer-features-and-speeding-up-convolutions-in-flux.md
@@ -2,7 +2,7 @@
@def rss = """ GSoC 2018: Adding Newer Features and Speeding up Convolutions in Flux | Over the summer I have been working at improving the Computer Vision capabilities of Flux. My specific line of work was to __add newer models to the Flux model-zoo__, __implement some new features__ and also __improve the speed of the previous layers__. Specifically, I achieved a __18-fold__ speed up... """
@def published = "13 August 2018"
@def title = "GSoC 2018: Adding Newer Features and Speeding up Convolutions in Flux"
-@def authors = """Avik Pal"""
+@def authors = """Avik Pal"""
@def hascode = true
Over the summer I have been working at improving the Computer Vision capabilities of Flux. My specific line of work was to __add newer models to the Flux model-zoo__, __implement some new features__ and also __improve the speed of the previous layers__. Specifically, I achieved a __18-fold__ speed up for the __Convolutions__ and around __3-fold__ for __BatchNorm__.
@@ -113,7 +113,7 @@ Here's a small demo of the package
### FastStyleTransfer.jl
-This is the implementation of the paper __[Perceptual Losses for Real-Time Style Transfer and Super-Resolution](https://arxiv.org/pdf/1603.08155)__. There are some obvious deviations from the paper. We used the best layer implementations that were currently available in Flux. As for the exact architecture it is still in developement. We provide three pre-trained models with this package. The API has been kept as simple as possible.
+This is the implementation of the paper __[Perceptual Losses for Real-Time Style Transfer and Super-Resolution](https://arxiv.org/pdf/1603.08155)__. There are some obvious deviations from the paper. We used the best layer implementations that were currently available in Flux. As for the exact architecture it is still in development. We provide three pre-trained models with this package. The API has been kept as simple as possible.
Below is a small example of style transfer on MonaLisa
diff --git a/blog/2018/08/union-splitting.md b/blog/2018/08/union-splitting.md
index 15c1c8fe90..0edbe1066d 100644
--- a/blog/2018/08/union-splitting.md
+++ b/blog/2018/08/union-splitting.md
@@ -2,7 +2,7 @@
@def rss = """ Union-splitting: what it is, and why you should care | Among those who follow Julia's development closely, one of the (many) new features causing great excitement is something called "Union-splitting."... """
@def published = "9 August 2018"
@def title = "Union-splitting: what it is, and why you should care"
-@def authors = """Tim Holy"""
+@def authors = """Tim Holy"""
@def hascode = true
Among those who follow Julia's development closely, one of the (many) new features causing great excitement is something called "Union-splitting."
@@ -67,7 +67,7 @@ Worse, if you forgot to check, and `function2` didn't error when you passed it 0
That is far worse than getting an error, because it's much harder to track down where wrong results come from.
In Julia 0.7 and 1.0, Milan Bouchet-Valat rewrote all of our `find*` functions, of which one change (among many) was that `findfirst` now returns `nothing` when it fails to find the requested value.
-Unlike the old approach of returning 0, this return value is truly unambigous and robust against generalizations of indexing where 0 might be a perfectly valid array index.
+Unlike the old approach of returning 0, this return value is truly unambiguous and robust against generalizations of indexing where 0 might be a perfectly valid array index.
It also gives you more reliable code, because if you forget to check, really there's not much you can do with `nothing` that doesn't trigger a (very welcome) error.
And thanks to Union-splitting, it doesn't cause any kind of performance penalty whatsoever.
diff --git a/blog/2019/02/light-graphs.md b/blog/2019/02/light-graphs.md
index ff78cd3131..b5635c57c8 100644
--- a/blog/2019/02/light-graphs.md
+++ b/blog/2019/02/light-graphs.md
@@ -2,7 +2,7 @@
@def rss = """ GSoC 2018 - Parallel Implementations of Graph Analysis Algorithms | This blog briefly summarises my GSoC 2018 project (Parallel Graph Development (https://summerofcode.withgoogle.com/archive/2018/projects/5193483178475520/)) and the results achieved. For a detailed description, please refer to my GSoC blog (https://sohamtamba.github.io/GSoC).... """
@def published = "3 February 2019"
@def title = "GSoC 2018 - Parallel Implementations of Graph Analysis Algorithms"
-@def authors = """Soham Tamba"""
+@def authors = """Soham Tamba"""
This blog briefly summarises my GSoC 2018 project ([Parallel Graph Development](https://summerofcode.withgoogle.com/archive/2018/projects/5193483178475520/)) and the results achieved. For a detailed description, please refer to my [GSoC blog](https://sohamtamba.github.io/GSoC).
@@ -101,7 +101,7 @@ The following branches have been merged into LightGraphs master:
- [Parallel Random Heuristics](https://github.com/SohamTamba/LightGraphs.jl/tree/genrate_reduce)
- [Karger Minimum Cut](https://github.com/SohamTamba/LightGraphs.jl/tree/Karger_min_cut)
- [Multi-threaded Centrality Measures](https://github.com/SohamTamba/LightGraphs.jl/tree/Threaded_Centrality)
- 1. Betweeness Centrality
+ 1. Betweenness Centrality
2. Closeness Centrality
3. Stress Centrality
diff --git a/blog/2019/06/diffeqbot.md b/blog/2019/06/diffeqbot.md
index 71a2115c67..78594222c7 100644
--- a/blog/2019/06/diffeqbot.md
+++ b/blog/2019/06/diffeqbot.md
@@ -2,7 +2,7 @@
@def rss = """ Hello @DiffEqBot | Hi! Today we all got a new member to the DiffEq family. Say hi to our own DiffEqBot (https://github.com/DiffEqBot) - A bot which helps run benchmarks and compares with the current master of a given package. It also generates and stores the Reports generated in a repository (https://github.com/DiffE... """
@def published = "18 June 2019"
@def title = "Hello @DiffEqBot"
-@def authors = """Kanav Gupta"""
+@def authors = """Kanav Gupta"""
@def hascode = true
Hi! Today we all got a new member to the DiffEq family. Say hi to our own [DiffEqBot](https://github.com/DiffEqBot) - A bot which helps run benchmarks and compares with the current master of a given package. It also generates and stores the Reports generated in a [repository](https://github.com/DiffEqBot/Reports). What's special about this is that it is completely stateless (no databases involved at all, just juggling between repositories!) and it has no exposed public URLs. Even though highly inspired by Nanosoldier, this has a completely unique workflow.
@@ -25,7 +25,7 @@ Right now, `DIAGRAMS` cannot be a recursive dictionary, i.e. an element of the d
## How does DiffEqBot work internally?
-DiffEqBot works by jumping accross many repositories and it has been all possible due to awesome APIs both GitHub and Gitlab has provided us with! I will explain the workflow of DiffEqBot in the steps it take to get a particular job done -
+DiffEqBot works by jumping across many repositories and it has been all possible due to awesome APIs both GitHub and Gitlab has provided us with! I will explain the workflow of DiffEqBot in the steps it take to get a particular job done -
1. You make a comment on the pull request to run the benchmarks. With the help of GitHub webhooks, `comment` event is posted on a Heroku app. You get the repository's name and pull request number where this comment is made. It makes sure all the sanity checks, like if the person can run benchmarks or not, or the repository is registered or not etc.
@@ -35,7 +35,7 @@ DiffEqBot works by jumping accross many repositories and it has been all possibl

-3. Here comes the tricky part. We have a seperate dedicated Gitlab private repository called `BenchmarkingRepo` which is basically an empty repository, but plays an important role which would be explained now. DiffEqBot checks out a branch with name formatted as `REPONAME-PR` and generates a Gitlab CI configuration script (`.gitlab-ci.yml`) and makes a commit on this branch. What this configuration does is, pull the PR where the request is made, run the benchmarks, and post the results back to the bot. Basically the script is -
+3. Here comes the tricky part. We have a separate dedicated Gitlab private repository called `BenchmarkingRepo` which is basically an empty repository, but plays an important role which would be explained now. DiffEqBot checks out a branch with name formatted as `REPONAME-PR` and generates a Gitlab CI configuration script (`.gitlab-ci.yml`) and makes a commit on this branch. What this configuration does is, pull the PR where the request is made, run the benchmarks, and post the results back to the bot. Basically the script is -
```yaml
main:
@@ -60,7 +60,7 @@ failed_job:

-5. In the `some_script_to_run_becnhmarks.jl` file, we make a request back to DiffEqBot along with the report in JSON format in the end. When this happens, DiffEqBot makes a commit on the Reports repository on GitHub submitting the markdown script.
+5. In the `some_script_to_run_benchmarks.jl` file, we make a request back to DiffEqBot along with the report in JSON format in the end. When this happens, DiffEqBot makes a commit on the Reports repository on GitHub submitting the markdown script.

@@ -112,7 +112,7 @@ All the configuration of DiffEqBot is done through a file `config.json` in the H
* `github_app.bot_endpoint` - Github App interacts with the Heroku app by a webhook. This is the endpoint where the app should make requests.
* `gitlab_account.benchmarking_repo_id` - Project ID of the BenchmarkingRepo on Gitlab
* `gitlab_account.access_token` - Gitlab Personal Access token of Bot account with repo:write rights.
-* `github_accout.access_token` - Github Personal access token with `public_repo` scope. You can directly generate this [here](https://github.com/settings/tokens/new?description=DiffEqBot&scopes=public_repo).
+* `github_account.access_token` - Github Personal access token with `public_repo` scope. You can directly generate this [here](https://github.com/settings/tokens/new?description=DiffEqBot&scopes=public_repo).
## Access Control and Security
@@ -123,4 +123,4 @@ We have for now given access to only certain members of the organization. We cal
## Shortcomings and Road ahead
-I absolutely love this new member of our community. But it still has several shortcomings. As seen above, due to security concerns, we have allowed only certain members of the organization access to run the benchmarks. Also, we have a basic frontend ready for display of reports, but an even more better design is welcome! We might also need more commands for DiffEqBot than just `runbenchmarks` and `abort`. All these extra features would be a cherry on top. I also plan to make it open source and maintain a proper documentation so that other communities can also deploy this for thier uses and maybe help in its development too!
+I absolutely love this new member of our community. But it still has several shortcomings. As seen above, due to security concerns, we have allowed only certain members of the organization access to run the benchmarks. Also, we have a basic frontend ready for display of reports, but an even more better design is welcome! We might also need more commands for DiffEqBot than just `runbenchmarks` and `abort`. All these extra features would be a cherry on top. I also plan to make it open source and maintain a proper documentation so that other communities can also deploy this for their uses and maybe help in its development too!
diff --git a/blog/2019/09/profilers.md b/blog/2019/09/profilers.md
index 8b2cece1aa..45ba4fda5b 100644
--- a/blog/2019/09/profilers.md
+++ b/blog/2019/09/profilers.md
@@ -2,7 +2,7 @@
@def rss = """ Profiling tools are awesome. They let us see what actually is affecting our program performance. Profiling tools also are terrible. They lie to us and give us confusing information. They also have some surprisingly new developments: [brendangregg's often cloned flamegraphs tool](http://www.brendangregg.com/flamegraphs.html) was created in 2011! So here I will be investigating some ways to make our profile reports better; and looking at ways in which they commonly break, to raise awareness of those artifacts in the reports. """
@def published = "16 September 2019"
@def title = "Profiling tool wins and woes"
-@def authors = """Jameson Nash"""
+@def authors = """Jameson Nash"""
@def hascode=true
Profiling tools are awesome. They let us see what actually is affecting our program performance. Profiling tools also are terrible. They lie to us and give us confusing information. They also have some surprisingly new developments: [brendangregg's often cloned flamegraphs tool](http://www.brendangregg.com/flamegraphs.html) was created in 2011! So here I will be investigating some ways to make our profile reports better; and looking at ways in which they commonly break, to raise awareness of those artifacts in the reports.
@@ -385,7 +385,7 @@ julia> Profile.print(format=:tree, recur=:flat)
Total snapshots: 629
```
-I think this looks cool, and vaguely even shows how I would conceptualize the functions in my head. This is availble right now only on [my jn/profile-recurflat](https://github.com/JuliaLang/julia/tree/jn/profile-recurflat) branch, but should be a PR soon, and show up in the JuliaLang v1.4 release.
+I think this looks cool, and vaguely even shows how I would conceptualize the functions in my head. This is available right now only on [my jn/profile-recurflat](https://github.com/JuliaLang/julia/tree/jn/profile-recurflat) branch, but should be a PR soon, and show up in the JuliaLang v1.4 release.
## Final thoughts
diff --git a/blog/2020/08/invalidations.md b/blog/2020/08/invalidations.md
index 1664f28e6f..0327dae666 100644
--- a/blog/2020/08/invalidations.md
+++ b/blog/2020/08/invalidations.md
@@ -111,7 +111,7 @@ To improve performance, it checks (as efficiently as possible at runtime) whethe
and if so calls the method it knows.
In this case, `f` just returns a constant, so when applicable the compiler even hard-wires in the return value for you.
-However, the compiler also acknowledges the possiblity that `container[1]` *won't* be an `Int`.
+However, the compiler also acknowledges the possibility that `container[1]` *won't* be an `Int`.
That allows the above code to throw a MethodError:
```julia-repl
@@ -365,7 +365,7 @@ and so loading the SIMD package triggers invalidation of everything that depends
As is usually the case, there are several ways to fix this: we could drop the `::Tuple` in the definition of `struct CallWaitMsg`, because there's no need to call `convert` if the object is already known to have the correct type (which would be `Any` if we dropped the field type-specification, and `Any` is not restrictive). Alternatively, we could keep the `::Tuple` in the type-specification, and use external knowledge that we have and assert that `args` is *already* a `Tuple` in `deserialize_msg` where it calls `CallWaitMsg`, thus informing Julia that it can afford to skip the call to `convert`.
This is intended only as a taste of what's involved in fixing invalidations; more extensive descriptions are available in [SnoopCompile's documentation](https://timholy.github.io/SnoopCompile.jl/stable/snoopr/) and the [video](https://www.youtube.com/watch?v=7VbXbI6OmYo).
-But it also conveys an important point: most invalidations come from poorly-inferred code, so by fixing invalidations you're often improving quality in other ways. Julia's [performance tips] page has a wealth of good advice about avoiding non-inferrable code, and in particular cases (where you might know more about the types than inference is able to determine on its own) you can help inference by adding type-assertions.
+But it also conveys an important point: most invalidations come from poorly-inferred code, so by fixing invalidations you're often improving quality in other ways. Julia's [performance tips] page has a wealth of good advice about avoiding non-inferable code, and in particular cases (where you might know more about the types than inference is able to determine on its own) you can help inference by adding type-assertions.
Again, some of the recently-merged "latency" pull requests to Julia might serve as instructive examples.
## Summary
diff --git a/blog/2020/09/juliacon-2020-open-source-bof-follow-up.md b/blog/2020/09/juliacon-2020-open-source-bof-follow-up.md
index d7ff2210b4..9a059a0b7b 100644
--- a/blog/2020/09/juliacon-2020-open-source-bof-follow-up.md
+++ b/blog/2020/09/juliacon-2020-open-source-bof-follow-up.md
@@ -66,7 +66,7 @@ One difficulty reported during the BoF was getting organizational approval to re
#### Open Sourcing Packages That Previously Used Internal CI/CD
-One important element of successful open-source projects is that CI logs should generally be available to all contributors. This can be a burdensome criteria to meet if a previously closed-source package utilized internal CI/CD pipelines with nicer properties than publicly available CI pipelines. In some instances, certain flavors of this problem can be solved with better tooling, e.g. self-hosted (but publically accessible) package registries can vendor open-sourced packages just as nicely as Julia's General Registry, but might leverage custom CI/CD for pre-registration checks.
+One important element of successful open-source projects is that CI logs should generally be available to all contributors. This can be a burdensome criteria to meet if a previously closed-source package utilized internal CI/CD pipelines with nicer properties than publicly available CI pipelines. In some instances, certain flavors of this problem can be solved with better tooling, e.g. self-hosted (but publicly accessible) package registries can vendor open-sourced packages just as nicely as Julia's General Registry, but might leverage custom CI/CD for pre-registration checks.
#### Open Source Efforts Could Reveal Strategic Intent
diff --git a/blog/2021/01/precompile_tutorial.md b/blog/2021/01/precompile_tutorial.md
index 293491b86b..23f100b95a 100644
--- a/blog/2021/01/precompile_tutorial.md
+++ b/blog/2021/01/precompile_tutorial.md
@@ -663,8 +663,8 @@ precompile(dopush, ())
then the `MethodInstance` for `push!(::Vector{SCDType}, ::SCDType)` will be added to the package through the backedge to `dopush` (which you do own).
-This was an artifical example, but in more typical cases this happens organically through the functionality of your package.
-But again, this works only for inferrable calls.
+This was an artificial example, but in more typical cases this happens organically through the functionality of your package.
+But again, this works only for inferable calls.
@@
[package mode]: https://julialang.github.io/Pkg.jl/v1/getting-started/#Basic-Usage
diff --git a/blog/2021/01/snoopi_deep.md b/blog/2021/01/snoopi_deep.md
index b1bdab5ef5..44a722fe8d 100644
--- a/blog/2021/01/snoopi_deep.md
+++ b/blog/2021/01/snoopi_deep.md
@@ -9,7 +9,7 @@ In the [first post](https://julialang.org/blog/2021/01/precompile_tutorial/), we
We also pointed out that precompilation is closely tied to *type inference*:
- precompilation allows you to cache the results of type inference, thus saving time when you start using methods defined in the package
-- caching becomes more effective when a higher proportion of calls are made with inferrable argument types (i.e., type-inference "succeeds"). Successful inference introduces links, in the form of `MethodInstance` backedges, that permit the entire call graph to be cached.
+- caching becomes more effective when a higher proportion of calls are made with inferable argument types (i.e., type-inference "succeeds"). Successful inference introduces links, in the form of `MethodInstance` backedges, that permit the entire call graph to be cached.
As a consequence, anyone interested in precompilation needs to pay attention to type inference: how much time does it account for, where is it spending its time, and what can be done to improve caching?
Julia itself provides the internal infrastructure needed to "spy" on inference, and the user-space utilities are in the [SnoopCompile] package.
diff --git a/blog/2021/03/julia-1.6-highlights.md b/blog/2021/03/julia-1.6-highlights.md
index 266c48d91e..ee56216740 100644
--- a/blog/2021/03/julia-1.6-highlights.md
+++ b/blog/2021/03/julia-1.6-highlights.md
@@ -255,7 +255,7 @@ possible. By limiting the number of backedges and data structures, as well as
centralizing the template pieces of code that each JLL package uses, we are
able to not only vastly improve load times, but improve compile times as well!
As an added bonus, improvements to JLL package APIs can now be made directly in
-`JLLWappers.jl` without needing to re-deploy hundreds of JLLs. Because these
+`JLLWrappers.jl` without needing to re-deploy hundreds of JLLs. Because these
JLL packages only define a thin wrapper around simple, lightweight functions
that load libraries and return paths and such, they do not benefit from the
heavy optimization that most Julia code undergoes. One final piece of the
diff --git a/blog/2021/08/sharks.md b/blog/2021/08/sharks.md
index 6d39212eec..387402c385 100644
--- a/blog/2021/08/sharks.md
+++ b/blog/2021/08/sharks.md
@@ -270,7 +270,7 @@ For example, the side-to-side force has the same frequency as the swimming motio
This simple model is a great start and it opens up a ton of avenues for improving the shark simulation and suggesting research questions:
- The instantaneous net forces should be zero in a free swimming body! We could add reaction motions to our model to achieve this. Would the model shark swim in a straight line if we did this, or is a control-loop needed?
- Real sharks are 3D (gasp!). While we could easily extend this approach using 2D splines, it will take much longer to simulate. Is there a way use GPUs to accelerate the simulations without completely changing the solver?
- - If we were going to make a bio-inspired robot of this shark, we will have constraints on the shape and motion and powering available. Can we use this framework to help optimize our robotic within it's contraints?
+ - If we were going to make a bio-inspired robot of this shark, we will have constraints on the shape and motion and powering available. Can we use this framework to help optimize our robotic within it's constraints?
Below you can find links to all the packages used in this notebook. Happy Simulating!
diff --git a/blog/2021/11/julia-1.7-highlights.md b/blog/2021/11/julia-1.7-highlights.md
index f79a61da19..eb73daecdd 100644
--- a/blog/2021/11/julia-1.7-highlights.md
+++ b/blog/2021/11/julia-1.7-highlights.md
@@ -398,7 +398,7 @@ julia (v1.6)> @btime reshape([1; 2; 3; 4], (1, 2, 1, 2)); # fast, but intent les
65.884 ns (2 allocations: 192 bytes)
```
-This is a substantial improvement in performance for this basic operation, and the differential improves greatly as more dimensions become invovled.
+This is a substantial improvement in performance for this basic operation, and the differential improves greatly as more dimensions become involved.
For ease of reading a larger array expression, line breaks are of course tolerated:
```julia-repl
diff --git a/blog/2021/12/dtable-performance-assessment.md b/blog/2021/12/dtable-performance-assessment.md
index 5d63c65334..4a8b1514f2 100644
--- a/blog/2021/12/dtable-performance-assessment.md
+++ b/blog/2021/12/dtable-performance-assessment.md
@@ -45,7 +45,7 @@ The `DTable` aims to excel in two areas:
- parallelization of data processing
- out-of-core processing (will be available through future `Dagger.jl` upgrades)
-The goal is to become competitive with similiar tools, such as `Dask` or `Spark`, so that Julia users can solve and scale their problems within Julia.
+The goal is to become competitive with similar tools, such as `Dask` or `Spark`, so that Julia users can solve and scale their problems within Julia.
By leveraging the composability of the Julia data ecosystem, we can reuse a lot of existing functionality in order to achieve the above goals, and continue improving the solution in the future instead of just creating another monolithic solution.
@@ -134,7 +134,7 @@ DTable command: `map(row -> (r = row.a1 + 1,), d)`
As the set of values is limited, a simple filter expression was chosen, which filters out approximately half of the records (command below).
-In this scenario, the parallelization and partitioning overhead doesn't pay off as well as both `DTable` and `Dask` are noticably slower than `DataFrames.jl`.
+In this scenario, the parallelization and partitioning overhead doesn't pay off as well as both `DTable` and `Dask` are noticeably slower than `DataFrames.jl`.
When it comes to the comparison of these two implementations, the performance looks very similiar with `Dask` being on average 1.6 times faster than the `DTable`.
The scaling of the `DTable` allows it to catch up to `DataFrames` at the largest data size. It's possible that this behavior may continue at larger data sizes and eventually provide a speedup versus `DataFrames` after some threshold.
@@ -203,7 +203,7 @@ DTable command: `Dagger.groupby(d, :a1)`
## Grouped reduction (single column)
Mimicking the success of reduction benchmarks, the `DTable` is again performing better here than the direct competition.
-For the single column reductions, it's an average ~20.2 times speedup over `Dask`, and their scaling behavior looks very similiar.
+For the single column reductions, it's an average ~20.2 times speedup over `Dask`, and their scaling behavior looks very similar.
Contrary to the standard reduction benchmarks, the `DTable` doesn't offer a speedup compared to `DataFrames.jl` across all the data sizes.
It looks like the current algorithm has a significant overhead that can be observed as a lower bound to the performance at smaller data sizes.
@@ -217,7 +217,7 @@ DTable command: `r = reduce(fit!, g, cols=[:a2], init=Mean())`
## Grouped reduction (all columns)
-The results for the all-columns reduction look very similiar to single-column.
+The results for the all-columns reduction look very similar to single-column.
The `DTable` managed to offer an average ~22.3 times speeup over `Dask`.
Again, the `DTable` is heavily falling behind `DataFrames.jl` on smaller data sizes due to the significant entry overhead acting as a lower performance bound at smaller data sizes.
@@ -253,7 +253,7 @@ We hope to include all the necessary fixes in future patches to Julia 1.7.
The `DTable` has successfully passed the proof-of-concept stage and is currently under active development as a part of the `Dagger.jl` package.
-This early performance assessment has confirmed that the `DTable` has the potential to become a competetive tool for processing tabular data.
+This early performance assessment has confirmed that the `DTable` has the potential to become a competitive tool for processing tabular data.
It managed to perform significantly better than direct competition (`Dask`) in 6 out of 7 presented benchmarks and in the remaining one it doesn't fall too far behind.
While this looks promising there's still a lot of work ahead in order to make the `DTable` feature-rich and even faster, so keep an eye out for future updates on the project.
diff --git a/blog/2022/02/10years.md b/blog/2022/02/10years.md
index 052dce1cbd..256c1c326f 100644
--- a/blog/2022/02/10years.md
+++ b/blog/2022/02/10years.md
@@ -218,7 +218,7 @@ Even more exciting than the software itself was the vibrant open source communit
## Francesco Martinuzzi [(@MartinuzziFrancesco)](https://github.com/MartinuzziFrancesco)
-I encountered Julia when I was looking for an alternative to Python to use for my master thesis. At the time I was mainly a Fortran user, as many physics students still are, and Python felt unbelievably slow. I stumbled into Julia almost by chance in looking for something in beetween these two languages. What most amazes me about the language is not the technical feats in itself, but it is how much Julia and its community are intertwined. Coming from a world in which code is handed down from supervisor to student, with little to no explanation or comments, this was something I valued incredibly.
+I encountered Julia when I was looking for an alternative to Python to use for my master thesis. At the time I was mainly a Fortran user, as many physics students still are, and Python felt unbelievably slow. I stumbled into Julia almost by chance in looking for something in between these two languages. What most amazes me about the language is not the technical feats in itself, but it is how much Julia and its community are intertwined. Coming from a world in which code is handed down from supervisor to student, with little to no explanation or comments, this was something I valued incredibly.
I was lucky enough to start contributing to the [SciML](https://sciml.ai/) organization in the summer of 2020 as part of the [Google Summer of Code](https://summerofcode.withgoogle.com/) program working on [ReservoirComputing.jl](https://github.com/SciML/ReservoirComputing.jl). This also was the start of my personal journey into contributing to open source software, and the Julia language made that an incredibly easy transition.
@@ -447,7 +447,7 @@ From the first time I heard about Julia in Alan’s office in 2011, Julia has br
## Panagiotis Georgakopoulos [(@pankgeorg)](https://github.com/pankgeorg)
-I was introduced to Julia by the MIT - Computational Thinking course. That was start of the quarantine era and I was cruising online resources to understand scientific computing a bit more. Coming from the front-end world of computing, I found Julia amazing because of its unique integration with HTML through Pluto. I started contributing to the Pluto.jl project - initially by fixing some CSS, then some React and finally diving deeper into Pluto's internals. Pluto's appearance in the Julia ecosystem is no accident; Julia is _so_ friendly when it comes to `show`ing stuff in HTML. Alongside its speed, which enables lag-free interaction, Julia creates the perfect environment for interactive programming and I feel glad and priviledged to be part of the journey!
+I was introduced to Julia by the MIT - Computational Thinking course. That was start of the quarantine era and I was cruising online resources to understand scientific computing a bit more. Coming from the front-end world of computing, I found Julia amazing because of its unique integration with HTML through Pluto. I started contributing to the Pluto.jl project - initially by fixing some CSS, then some React and finally diving deeper into Pluto's internals. Pluto's appearance in the Julia ecosystem is no accident; Julia is _so_ friendly when it comes to `show`ing stuff in HTML. Alongside its speed, which enables lag-free interaction, Julia creates the perfect environment for interactive programming and I feel glad and privileged to be part of the journey!
## Huda Nassar [(@nassarhuda)](https://github.com/nassarhuda)
@@ -683,7 +683,7 @@ I had my first experience with Julia in Spring 2019, while in 18.06 (Linear Alge
My first encounter with the Julia language happened in fall of 2014. At the time I was quite young, but enthused by Computational Science, I was using primarily Python and R for these two tasks. I had worked on several projects with peers where we would hit the " Two Language Problem," and it got to be really frustrating. I was the only member of the team who could write C, and Cython wasn't really helping our problem as much as one might expect. Back then, tools like Numba and remote Python interpretation were not even close to where they are now, and I was looking for more information on getting Python to run faster when I stumbled across a Julia forum post. I was intrigued by the syntax, and since picking up Julia on that day, it has become my favorite programming language. I was able to solve our problem in Julia, rather than C, and I was able to call our Python code when needed via PyCall.jl. It ended up working perfectly, so I used it for projects with these sorts of problems each time they came into fruition. The language just kept doing fantastic, and then all of the changes that kept coming to the language were all just so great. Now the language has a venerable ecosystem to go along with it, so things have only gotten better.
-## Elisabeth Roesch [(@ElisabethRoesch)](https://github.com/ElisabethRoesch)
+## Elisabeth Roesch [(@ElisabethRoesch)](https://github.com/ElisabethRoesch)
As a systems biologist, I form part of a very interdisciplinary field. I work in teams of biologists, mathematicians, computer scientists and more. Leveraging expertise of multiple domains is key for many hard problems in the field. One key aspect I consider when choosing my programming language is how it enables collaborations. A focus of Julia’s language design is abstraction and its implied modularity and composability. The effect that this design emphasis has on my day to day work of collaborating with other researchers is hard to describe in only a few words. Simple, yet clear syntax as well as elegant technical features, such as multiple dispatch, solve the expression problem and make it convenient to reuse, adapt and extend existing code of collaborators. Additionally, exploiting Julia’s rich package ecosystems is made easy, too.
Second, Julia is fast. In the biological sciences, the amount of data at our fingertips is growing rapidly. Software that scales well is of great importance. In order to built sophisticated models that learn large biological systems using big data, I need a level of performance that languages such as R, Python or MATLAB cannot deliver. Two-language approaches, where code is translated into a faster language as a second stage of a project, are popular but also inherently inefficient and can be a source of mistakes and inaccuracy. Julia solves this two-language problem. Due to its easy syntax, Julia gives me a convenient environment for prototyping and algorithm design as well as production ready, high performance code for data-heavy work.
@@ -691,7 +691,7 @@ Third, I use Julia because it is free, open source and because of its community.
## Leandro Martínez [(@lmiq)](https://github.com/m3g)
-I am a computational chemist, and I first heard about Julia in 2015, during a lecture given by a fellow mathematician to an audience largely made up of Fortran programmers (me included). I recall him attempting to persuade us that annotating types with 'local x::Int' or something similar was conceivable and that, as a result, one could do what we used to do in Fortran, namely declare all variables and all types (now that I think I probably misunderstood what he wanted to explain). As a result, I and others felt that there was no compelling reason to learn Julia, because we would get roughly the same results as we did with Fortran, except for plotting libraries and other things, which others were already doing with other tools. After Julia reached 1.0, I decided to take another look at it and began attempting to translate some of my unmaintainable Fortran code to Julia and make it a distributable package. At the time, I had never considered, or even heard of, immutability, assignment and mutation, stack and heap, or SIMD. It's astonishing, and sometimes even embarrassing, that the language's creators, developers of highly complicated core features, massive packages, and academic giants from many disciplines get to answer some of the most basic queries there. I was able to produce better software for my own research by engaging in the community, and I had the pleasure of being invited to speak on molecular simulations in Julia at conferences I never expected to attend. At this moment, I recognize and appreciate my earlier hesitation to adopt Julia: To fully appreciate the language's capabilities, some programming knowledge is required, which does not come necessarily from using Fortran or Python, even for many years. The diversity of notions, from high level to low level, that one is exposed to by programming in Julia is unparalleled, and it leads to this diversified community in which everyone can understand and aid each other. Programming is now a lot more enjoyable. I am grateful to the developer community for believing in this project long before I did, and for their assistance over the past three years of learning and collaboration.
+I am a computational chemist, and I first heard about Julia in 2015, during a lecture given by a fellow mathematician to an audience largely made up of Fortran programmers (me included). I recall him attempting to persuade us that annotating types with 'local x::Int' or something similar was conceivable and that, as a result, one could do what we used to do in Fortran, namely declare all variables and all types (now that I think I probably misunderstood what he wanted to explain). As a result, I and others felt that there was no compelling reason to learn Julia, because we would get roughly the same results as we did with Fortran, except for plotting libraries and other things, which others were already doing with other tools. After Julia reached 1.0, I decided to take another look at it and began attempting to translate some of my unmaintainable Fortran code to Julia and make it a distributable package. At the time, I had never considered, or even heard of, immutability, assignment and mutation, stack and heap, or SIMD. It's astonishing, and sometimes even embarrassing, that the language's creators, developers of highly complicated core features, massive packages, and academic giants from many disciplines get to answer some of the most basic queries there. I was able to produce better software for my own research by engaging in the community, and I had the pleasure of being invited to speak on molecular simulations in Julia at conferences I never expected to attend. At this moment, I recognize and appreciate my earlier hesitation to adopt Julia: To fully appreciate the language's capabilities, some programming knowledge is required, which does not come necessarily from using Fortran or Python, even for many years. The diversity of notions, from high level to low level, that one is exposed to by programming in Julia is unparalleled, and it leads to this diversified community in which everyone can understand and aid each other. Programming is now a lot more enjoyable. I am grateful to the developer community for believing in this project long before I did, and for their assistance over the past three years of learning and collaboration.
## Miguel Raz Guzmán Macedo [(@miguelraz)](https://github.com/miguelraz)
I am a physics undergraduate student at UNAM, in Mexico City. I was very fortunate that some classmates recommended I take David Sanders Computational Physics course, because Julia was the bee's knees and it was the future. I reluctantly signed up because I had heard other professors say that only Fortran was worth anyone's time, but David's lectures and Jupyter notebook demos sold me. At some point I stumbled upon the [julialang.org](julialang.org) links and somehow landed in the Julia Gitter. I met Scott, Chris and Seth, and they answered a bunch of my newbie questions about Julia and I just kept coming back I guess. What really electrified me about Julia was that at some point Stefan or Jeff responded directly to one of my Discourse posts without calling me an idiot and explained some Julia esoterica with great calm (which was *not* my average internet forum experience). That moment felt like lightning in a bottle: The creators of a programming language just hang out? And answer your questions? Online? For free??? That still seems to be a bit of a revolutionary openness to knowledge sharing. I eventually wanted to try and contribute to the language, so I thought the best way to do it was by signing up to the github notifications to the JuliaLang repository. Something strange kept happening - the usual suspects would contribute cool code, but almost every day at midnight this amazing hero of a coder would just answer a swath of PRs and commits and have all theses benchmarks and PRs at the ready. "Who on God's green earth can code like this!??" Their name, I came to find out, was the `nanosoldier`, an automated bot that runs precooked benchmarking scripts - not, unfortunately, an intrepid Australian hero coder I had idolized. And that's how I came to Julia and it's wonderful people. For everything, dear Julians, thank you. Gracias.
diff --git a/blog/2022/04/simple-chains.md b/blog/2022/04/simple-chains.md
index de988cd7a5..9496921f80 100644
--- a/blog/2022/04/simple-chains.md
+++ b/blog/2022/04/simple-chains.md
@@ -26,13 +26,13 @@ This [SciML methodology](https://sciml.ai/roadmap/) has been shown across many d
~~~
-For more details on the software and methods, [see our paper on Universal Differential Equations for Scientific Machine Learning](https://arxiv.org/abs/2001.04385).
+For more details on the software and methods, [see our paper on Universal Differential Equations for Scientific Machine Learning](https://arxiv.org/abs/2001.04385).
The unique aspects of how neural networks are used in these contexts make them rife for performance improvements through specialization. Specifically, in the context of machine learning, one normally relies on the following assumption: the neural networks are large enough that the O(n^3) cost of matrix-matrix multiplication (or other kernels like convolutions) dominates the the runtime. This is essentially the guiding principle behind most of the mechanics of a machine learning library:
1. Matrix-matrix multiplication scales cubicly while memory allocations scale linearly, so attempting to mutate vectors with non-allocating operations is not a high priority. Just use `A*x`.
2. Focus on accelerating GPU kernels to be as fast as possible! Since these large matrix-matrix operations will be fastest on GPUs and are the bottleneck, performance benchmarks will essentially just be a measurement of how fast these specific kernels are.
-3. When doing reverse-mode automatic differentiation (backpropagation), feel free to copy values to memory. Memory allocations will be hidden by the larger kernel calls.
+3. When doing reverse-mode automatic differentiation (backpropagation), feel free to copy values to memory. Memory allocations will be hidden by the larger kernel calls.
4. Also, feel free to write a "tape" for generating backpropagation. The tape does add the cost of essentially building a dictionary during the forward pass, but that will be hidden by the larger kernel calls.
Do these assumptions actually hold in our case? And if they don't, can we focus on these aspects to draw more performance out for our use cases?
@@ -88,7 +88,7 @@ savefig("microopts_blas3.png")

-When we get to larger matrix-matrix operations, such as 100x100 * 100x100, we can effectively write off any overheads due to memory allocations. But we definitely see that there is a potential for some fairly significant performance gains in the lower end! Notice too that these gains are realized by using the pure-Julia LoopVectorization.jl as the standard BLAS tools tend to have extra threading overhead in this region (again, not optimizing as much in this region).
+When we get to larger matrix-matrix operations, such as 100x100 * 100x100, we can effectively write off any overheads due to memory allocations. But we definitely see that there is a potential for some fairly significant performance gains in the lower end! Notice too that these gains are realized by using the pure-Julia LoopVectorization.jl as the standard BLAS tools tend to have extra threading overhead in this region (again, not optimizing as much in this region).
If you have been riding the GPU gospel without looking into the details then this plot may be a shocker! However, GPUs are designed as dumb slow chips with many cores, and thus they are only effective on very parallel operations, such as large matrix-matrix multiplications. It is from this point that assumption (2) is derived for large network operations. But again, in the case of small networks such GPU kernels will be outperformed by well-designed CPU kernels due to the lack of parallel opportunities.
@@ -141,7 +141,7 @@ savefig("microopts_blas2.png")

-And remember, the basic operations of a neural network are `sigma.(W*x .+ b)`, and thus there's also an O(n) element-wise operation. As you would guess, this operation becomes more significant as n gets smaller while requiring even more consideration for memory operations.
+And remember, the basic operations of a neural network are `sigma.(W*x .+ b)`, and thus there's also an O(n) element-wise operation. As you would guess, this operation becomes more significant as n gets smaller while requiring even more consideration for memory operations.
```julia
using LinearAlgebra, BenchmarkTools, CUDA, LoopVectorization
@@ -215,7 +215,7 @@ y = σ.(r)
zbar = v .* σbar
Wbar = zbar * x'
bbar = zbar
-xbar = W' * zbar
+xbar = W' * zbar
```
and now cached:
@@ -435,7 +435,7 @@ vs SimpleChains.jl with 16 threads:
└ test = 0.20991518f0
```
-or 10x performace improvement, and on 36 × Intel(R) Core(TM) i9-10980XE CPU @ 3.00GHz we saw for Jax:
+or 10x performance improvement, and on 36 × Intel(R) Core(TM) i9-10980XE CPU @ 3.00GHz we saw for Jax:
```
Initial Train Loss: 6.4232
@@ -759,7 +759,7 @@ Note that smaller batch sizes improve accuracy per epoch, and batch sizes were s
Latency before the first epoch begins training is problematic, but SimpleChains.jl is fast once compiled.
Post-compilation, the 10980XE was competitive with Flux using an A100 GPU, and about 35% faster than the V100.
-The 1165G7, a laptop CPU featuring AVX512, was competitive, handily trouncing any of the competing machine learning libraries when
+The 1165G7, a laptop CPU featuring AVX512, was competitive, handily trouncing any of the competing machine learning libraries when
they were run on far beefier CPUs, and even beat PyTorch on both the V100 and A100. Again, we stress that this test case followed the more typical machine learning
uses and thus was able to use batching to even make GPUs viable: for many use cases of SimpleChains.jl this is not the case and thus
the difference is even larger.
diff --git a/blog/2023/04/julia-1.9-highlights.md b/blog/2023/04/julia-1.9-highlights.md
index 7df5778a05..39b135c421 100644
--- a/blog/2023/04/julia-1.9-highlights.md
+++ b/blog/2023/04/julia-1.9-highlights.md
@@ -156,7 +156,7 @@ This feature was introduced in [#45369]( https://github.com/JuliaLang/julia/pull
*Lilith Hafner*
-The default sorting algorithm has been upgraded to a more adaptive sorting algorithm that is always stable and often has state of the art performance. For simple types and orders—`BitInteger`, `IEEEFloat`, and `Char` sorted in default or reverse order—we use a radix sort that has linear runtime with respect to input size. This effect is especially pronounced for `Float16`s which recieved a 3x-50x speedup over 1.8.
+The default sorting algorithm has been upgraded to a more adaptive sorting algorithm that is always stable and often has state of the art performance. For simple types and orders—`BitInteger`, `IEEEFloat`, and `Char` sorted in default or reverse order—we use a radix sort that has linear runtime with respect to input size. This effect is especially pronounced for `Float16`s which received a 3x-50x speedup over 1.8.
For other types, the default sorting algorithm has been changed to the internal `ScratchQuickSort` in most cases, which is stable and generally faster than `QuickSort`, although it does allocate memory. For situations where memory efficiency is crucial, you can override these new defaults by specifying `alg=QuickSort`.
diff --git a/community/working-groups.md b/community/working-groups.md
index 49f4be8b72..8c947a731b 100644
--- a/community/working-groups.md
+++ b/community/working-groups.md
@@ -58,9 +58,9 @@ Each of these groups is organized around a common area of interest with a commun
### See also
- [GitHub organizations][github-orgs]
-- [Community events calendar][commmunity-events-calendar]
+- [Community events calendar][community-events-calendar]
-[commmunity-events-calendar]: /community/#events
+[community-events-calendar]: /community/#events
[github-orgs]: /community/organizations/
[slack]: /slack
[zulip]: https://julialang.zulipchat.com/
diff --git a/diversity/index.md b/diversity/index.md
index 4a56416392..334382bae4 100644
--- a/diversity/index.md
+++ b/diversity/index.md
@@ -1,6 +1,6 @@
# Diversity
-As a [NumFocus supported project](https://numfocus.org), we abide by their [Code of Conduct and Diversity Statment](https://numfocus.org/code-of-conduct):
+As a [NumFocus supported project](https://numfocus.org), we abide by their [Code of Conduct and Diversity Statement](https://numfocus.org/code-of-conduct):
> NumFOCUS welcomes and encourages participation in our community by people of all backgrounds and identities. We are committed to promoting and sustaining a culture that values mutual respect, tolerance, and learning, and we work together as a community to help each other live out these values.
> We have created this diversity statement because we believe that a diverse community is stronger, more vibrant, and produces better software and better science. A diverse community where people treat each other with respect has more potential contributors, more sources for ideas, and fewer shared assumptions that might hinder development or research.
@@ -17,4 +17,4 @@ Find out more about our ideas for [future initiatives](/diversity/ideas/)
Find out more about our [past initiatives](/diversity/past/)
-__We would like to give a special thank you to all of the Julia Community members working tirelessly on these various Diversity and Inclusion initiates. These individuals are taking time away from their technical work in order to help promote a more inclusive and equitable community, and for that, we are in their debt.__
+__We would like to give a special thank you to all of the Julia Community members working tirelessly on these various Diversity and Inclusion initiates. These individuals are taking time away from their technical work in order to help promote a more inclusive and equitable community, and for that, we are in their debt.__
diff --git a/index.html b/index.html
index d7c8823b63..0aa9a20b70 100644
--- a/index.html
+++ b/index.html
@@ -221,7 +221,7 @@