LLVM JIT engine for Tarantool's DQL
Mentors: @Korablev77, @tsafin, @igormunkin
- based on the proof-of-concept I was provided, a new LLVM JIT infrastructure using the LLVM 12 C API was developed
- LLVM JIT compilation of constant literals, column reference and aggregate column expressions evaluation was implemented
- LLVM JIT compilation of the simplest case of aggregate function evaluation loops (without group-by and with several other constraints) was implemented
- prepared branch, introducing new LLVM JIT infrastructure, passes the test-suite completely, except for one test
- TCP-H benchmarks prove the LLVM JIT engine I developed gives a huge performance gain on certain types of queries (e.g., Q19)
I started working on this project in May by pulling the proof-of-concept branch I was provided, and studying the LLVM JIT engine prototype developed by my mentor, @Korablev77, 3 years go. The first challenge I faced was building this branch and rebasing it to the current master branch. The patches I made to resolve merge conflicts and to build Tarantool afterwards let me get the first grasp of Tarantool internals.
Since the proof-of-concept branch was not tested at the time it was developed, the first thing I needed to do was learn how to use Tarantool's test-suite and how to run individual tests out of the test-suite for debugging. As I started testing the proof-of-concept branch, it turned out that it was failing even on select 1; queries. Obviously, I decided to take a minimal subset of expression evaluation, constant literals, and start from debugging it.
As I finished fixing bugs for integer literals, they passed the test-suite and I started working on string literals, I realized that, basically, the LLVM JIT compiled code was supposed to emulate VDBE opcodes and the compilation process steps were supposed to closely resemble the VDBE bytecode emission steps (including stuff like updating virtual registers cache), which the current LLVM JIT engine did not do. Also, the current solution seemed unnecessarily overcomplicated to me (e.g., it supported two different LLVM JIT implementations, ORC and MCJIT; it used a general approach to compile expression evaluation, aggregate function evaluation and WHERE conditions evaluation), I did not like its design (e.g., it had separate compilation and execution contexts, which led to resource ownership being transferred unnecessarily), and, last but not least, it used the outdated LLVM 7 C API, and the LLVM 12 C API introduced significant changes, including a new ORCv2 API. That is why I decided to start working on the LLVM JIT engine from scratch.
As I finished implementing constant literal expressions evaluation, started working on column reference expression and experimented with emitted LLVM IR optimization, it came to me that I was facing the following problem: in order to inline auxiliary functions (wrappers around VDBE opcodes) called from LLVM JIT compiled code, their implementation needs to be included into the LLVM Module in which callback functions are built. Inlining is crucial for efficient LLVM JIT compilation, as it allows performing various IR optimizations, based on the dynamic data from the query, instruction combining. Actually, there is a straightforward solution to this problem: instead of calling auxiliary functions, manually generating LLVM IR for the VDBE opcodes they wrap. But this approach tends to be error prone and labor intensive. Besides, what can generate LLVM IR better than clang... And this is where the clang compiler comes in to play: we take the advantage of the fact it can emit LLVM bitcode from source files, which can then be embedded and parsed into an LLVM Module at runtime. My first naive and simple approach was to fill up a file with the implementations of all the auxiliary functions referenced in LLVM JIT compiled code and add attribute always_inline to all of them. This actually turned out to work, but resulted in a significant performance degrade. Obviously, the LLVM module containing all the implementations was huge, but I expected that only the symbols (the callbacks for the bytecode I replace) and the symbols they reference are compiled by LLJIT. But I addressed this question to LLVM JIT developers, and my assumption turned out to be wrong:
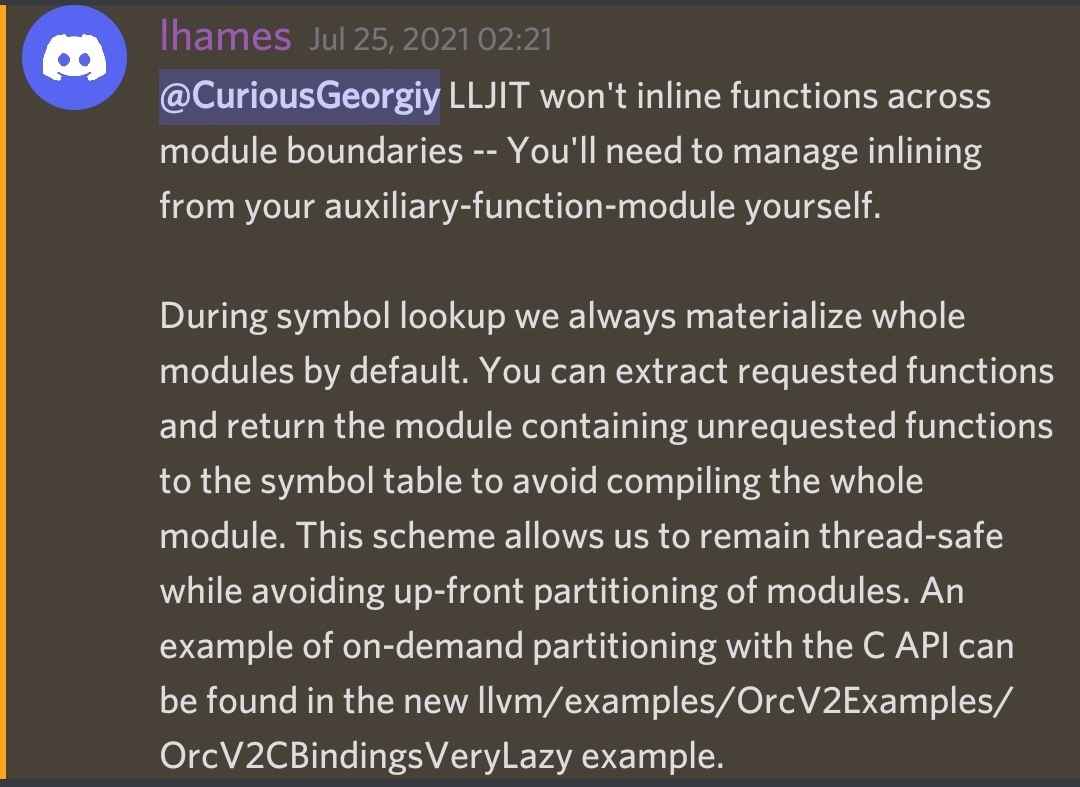
As Lang Hames (LLVM JIT maintainer) was referencing the opportunities for inlining of the upcoming LLVM 13 C API, it was decided to leave inlining for future work, as it would require spending time transitioning to the new API version and stick to the initial approach of simply referencing functions in LLVM JIT compiled code.
Implementation of column reference expressions evaluation was actually the first time I had to stick out of the code from the proof-of-concept branch and explore the Tarantool SQL codebase to find the places I needed to patch in order for the code generated to work: the problem was that that at query runtime it turned out that the table and column numbers used were invalid. I found that. actually, these numbers (for OP_Column opcodes) may get changed in a final scan at the end of VDBE bytecode generation for WHERE loops, and that for VDBE coroutines all OP_Column opcodes also get changed to OP_Copy opcodes. It meant that I, in turn, needed to patch the LLVM IR I generated to fit this: this meant patching individual 'store' instructions (changing the values stored accordingly) and replacing blocks of code doing OP_Column work to code doing OP_Copy work.
This was the last piece of work I had enough time left to do. The idea was to patch Tarantool SQL's sqlSelect to add a point where, instead of generating VDBE bytecode for a loop with updateAccumulator and sqlWhereEnd, directly compile aggregate function evaluation loops consisting of pushing aggregate function arguments, executing aggregate functions step and updating accumulator columns stored in AggInfo->aCol. By replacing this repeatedly executed bytecode loop with an LLVM JIT compiled callback, I expected to gain a serious performance increase. The things I had to do was: study sqlSelect code and determine the place needed to be patched; determining constraints in order to simplify the loops, considered to be compiled, enough for me to implement with the amount of time I had left; implementing LLVM IR generation for the loops.
Example query:
SELECT COUNT(*)+1 FROM test1;Example aggregate function evaluation loop compiled without LLVM JIT engine:
VDBE Program Listing:
103> 0 Init 0 11 0 00 Start at 11
103> 1 Null 0 1 1 00 r[1..1]=NULL
103> 2 IteratorOpen 1 0 0 space<name=TEST1> 00 index id = 0, space ptr = space<name=TEST1> or reg[0]; pk_unnamed_TEST1_1
103> 3 Explain 0 0 0 SCAN TABLE TEST1 (~1048576 rows) 00
103> 4 Rewind 1 7 2 0 00
103> 5 AggStep0 0 0 1 COUNT(-1) 00 accum=r[1] step(r[0])
103> 6 Next 1 5 0 01
103> 7 AggFinal 1 0 0 COUNT(-1) 00 accum=r[1] N=0
103> 8 Add 4 1 2 00 r[2]=r[4]+r[1]
103> 9 ResultRow 2 1 0 00 output=r[2]
103> 10 Halt 0 0 0 00
103> 11 Integer 1 4 0 00 r[4]=1
103> 12 Goto 0 1 0 00
Example aggregate function evaluation loop compiled with LLVM JIT engine:
VDBE Program Listing:
103> 0 Init 0 10 0 00 Start at 10
103> 1 Null 0 1 1 00 r[1..1]=NULL
103> 2 IteratorOpen 1 0 0 space<name=TEST1> 00 index id = 0, space ptr = space<name=TEST1> or reg[0]; pk_unnamed_TEST1_1
103> 3 Explain 0 0 0 SCAN TABLE TEST1 (~1048576 rows) 00
103> 4 Rewind 1 6 2 0 00
103> 5 ExecJITCallback 0 0 0 00 Callback for aggregate function evaluation loop
103> 6 AggFinal 1 0 0 COUNT(-1) 00 accum=r[1] N=0
103> 7 Add 4 1 2 00 r[2]=r[4]+r[1]
103> 8 ResultRow 2 1 0 00 output=r[2]
103> 9 Halt 0 0 0 00
103> 10 Integer 1 4 0 00 r[4]=1
103> 11 Goto 0 1 0 00
The final part of the project was to run SQL benchmarks. I was able to run the TCP-H benchmarks, and, unfortunately, unable to run the TCP-C benchmarks, as they turned out to be outdated and not working with the current version of Tarantool.
It should be noted that the following benchmarks count not only execution time, but also compilation time: originally, the LLVM JIT engine was planned to be used for PREPARE statements, thus working as an AOT compiler.

To start with, commentary why on some queries Tarantool performs a little bit worse with the LLVM JIT engine enabled required. We should take into account that, while, currently, not all types of expressions can be compiled: analysis of whether an expression list can be compiled is required. Thus, if an expression list is eventually not LLVM JIT compiled and we fall back to VDBE bytecode generation, we still spend time analyzing. If we consider the compilation time remark above, it becomes obvious why actually the LLVM JIT engine does degrade Tarantool's performance.
What do these queries have in common? A bunch of WHERE clauses with column references and constant literals! This is where LLVM JIT compilation proves to be worthy and give fascinating results.
Apparently, most of the queries (notably, except for Q17 and Q19) in the TCP-H benchmarks pass complex expressions as arguments to aggregate functions: I did not have enough time to implement binary operation expressions compilation, hence almost none of the aggregate function evaluation loops get LLVM JIT compiled here.
According to TCP-H benchmarks, LLVM JIT compilation of expressions evaluation proves to be extremely efficient for increasing performance of analytical queries: almost two-fold performance increase was gained for Q19.
- debugging last left behind failing test
- providing more useful diagnostic information from the LLVM JIT infrastructure
- shutdown of LLVM
- dealing with error handling inside LLVM (memory allocation errors are treated as fatal, rather than OOM)
- code pends to be reviewed
- implementation of all types of expressions evaluation compilation
- implementation of inlining for auxiliary functions (wrapping VDBE opcodes)
- research and implementation of a wider set of aggregate function evaluation loops
- research and implementation of
WHEREconditions evaluation - research and implementation of more efficient tuple deforming