the ActionConfig (used by all Actions: Push, Pull, Move, Remove, Execute);
+
the Requests (used by the Pull)
+
the Data Tags (if implemented for the specific Adapter, they are used by: Push, Pull, Move, Remove)
+
+
ActionConfig
+
The ActionConfig is an object type used to specify any kind of Configuration that might be used by the Adapter Actions.
+
This means that it can contain configurations that are specific to certain Actions (e.g. only to the Push, only to the Pull), and that a certain Push might be activated with a different Push ActionConfig than another one. This makes the ActionConfig different from the Adapter Settings (which are static global settings).
+
The base ActionConfig provides some configurations that are available to all Toolkits (you can find more info about those in the code itself).
+
You can inherit from the base ActionConfig to specify your own in your Toolkit. For example, if you are in the SpeckleToolkit, you will be able to find:
+- SpecklePushConfig: inherits from ActionConfig
+- SpecklePullConfig: inherits from ActionConfig
+
this allows some data to be specified when Pushing/Pulling.
+
ActionConfig is an input to all Adapter methods, so you can reference configurations in any method you might want to override.
+
+
Requests
+
Requests are an input to the Pull adapter Action.
+
They were formerly called Queries and are exactly that: Queries. You can specify a Request to do a variety of things that always involve Pulling data in from an external application or platform. For example:
+- you can Request the results of an FE analysis from a connected FEM software,
+- specify a GetRequest when using the HTTP_Toolkit to download some data from an online RESTFul Endpoint
+- query a connected Database, for example when using Mongo_Toolkit.
+
Requests can be defined in Toolkits to be working specifically with it.
+
You can find some requests that are compatible with all Toolkits in the base BHoM object model.
+An example of those is the FilterRequest.
+
The FilterRequest is a common type of request that basically requests objects by some specified type. See FilterRequest.
+
In general, however, Requests can range from simple filters to define the object you want to be sent, to elaborated ones where you are asking the external tool to run a series of complex data manipulation and calculation before sending you the result.
+
+
Additional note: batch requests
+
For the case of complex queries that need to be executed batched together without returning intermediate results, you can use a BatchRequest.
+
Additional note: Mongo requests
+
For those that use Mongo already, you might have noticed how much faster and convenient it is to let the database do the work for you instead doing that in Grasshopper. It also speeds up the data transfer in cases where the result is small in bytes but involves a lot of data to be calculated.
+
+
+
Data Tags
+
When objects are pushed, it is important to have a way to know which objects needs to be Updated, the new ones to be Created, and the old ones to be Deleted.
+
If the number of objects changes between pushes, you cannot rely on unique identifiers to match the objects one-to-one. The problem is especially clear when you are pushing less objects than the last push.
+
Attaching a unique tag to all the objects being pushed as a group is a lightweight and flexible way to find those objects later.
+
+
For those using D3.js, this is similar to attaching a class to html elements. For those using Mongo or Flux, this is similar to the concept of key.
+
+
Tags in practice
+
At the moment, each external software will likely require a different solution to attach the tags to the objects.
+
If the software doesn't provide any solution to store the tag attached to the objects (e.g., like Groups), we could make use of another appropriate field to store the tag, for example the Name field that is quite commonly found.
+
In case you need to use the Name field of the external object model, the format we are using for that is (example for an object with three tags):
+
Name __Tags__:tag1_/_tag2_/_tag3
+
+
For an in depth explanation on how tags are used and what you should be implementing for them to work, read the Push section of our Adapter Actions page; in particular, look at the practical example.
After covering the basics in Introduction to BHoM_Adapter, this page explains the Adapter Actions more in detail, including their underlying mechanism.
+
After reading this you should be all set to develop your own BHoM Toolkit! 🚀
As we saw before, the Adapter Actions are backed by what we call CRUD methods. Let's see what that means.
+
The CRUD paradigm
+
A very common paradigm that describes all the possible action types is CRUD. This paradigm says that, regardless of the connection being made, the connector actions can be always categorised as:
+* Create = add new entries
+* Read = retrieve, search, or view existing entries
+* Update = edit existing entries
+* Delete = deactivate, or remove existing entries
+
Some initial considerations:
+
+
+
Read and Delete are quite self-explanatory; regardless of the context, they are usually quite straightforward to implement.
+
+
+
Create and Update, on the other hand, can sometimes overlap, depending on the interface we have at our disposal (generally, the external software API can be limiting in that regard).
+
+
+
Exposing directly these methods would make the User Experience quite complicated. Imagine having to split the various objects composing your model into the objects that need to be Created, the ones that needs to be Updated, and so on. Not nice.
+
+
+
We need something simpler from an UI perspective, while retaining the advantages of CRUD - namely, their limited scope makes them simple to implement.
+
The answer is the Adapter Actions: they take care of calling the CRUD methods in the most appropriate way for both the user and the developer.
+
An example: the Push Action
+
Let's consider for example the case where we are pushing BHoM objects from Grasshopper to an external software.
+The first time those objects are Pushed, we expect them to be Created in the external software.
+The following times, we expect the existing objects to be Updated with the parameters specified in the new ones.
+
+
In detail: Why the "Actions-CRUD" paradigm?
+
This paradigm allows us to extend the capabilities of the CRUD methods alone, while keeping the User Experience as simple as possible; it does so mainly through the Push. The Push, in fact, can take care for the user of doing Create or Update or Delete when most appropriate – based on the objects that have been Read from the external model.
+
The rest of the Adapter Actions mostly have a 1:1 correspondence with the backing CRUD methods; for example, Pull calls Read, but its scope can be expanded to do something in addition to only Reading. This way, Read is "action-agnostic", and can be used from other Adapter Actions (most notably, the Push). You write Read once, and you can use it in two different actions!
+
Side note: Why using five different Actions (Push, Pull, Move, Remove, Execute)...
+
... and not something simpler, like "Export" and "Import"?
+... or just exposing the CRUD methods?
+The reason is that the methods available to the user need to cover all possible use cases, while being simple to use.
+We could have limited the Adapter Actions to only Push and Pull – that does in fact correspond to Export and Import, and are the most commonly used – but that would have left out some of the functionality that you can obtain with the CRUD methods (for example, the Deletion).
+
On the other hand, exposing directly the CRUD methods would not satisfy the criteria of simplicity of use for the User.
+Imagine having to Read an external model, then having manually to divide the objects in the ones to be Updated, the ones to be Deleted, then separately calling Create for the new ones you just added... Not really simple! The Push takes care of that instead.
+
Side note: Other advantages of the "Actions-CRUD" paradigm
+
We've explained how this paradigm allows us to cover all possible use cases while being simple from an User perspective. In addition, it allows us to:
+1) ensure consistency across the many, different implementations of the BHoM_Adapter in different Toolkits and contexts, therefore:
+2) ensuring consistency from the User perspective (all UIs have the same Adapter Actions, backed by different CRUD methods)
+3) maximise code scalability
+4) Ease of development – learn once, implement everywhere
+
+
CRUD methods: details and implementation
+
The paragraphs that follow down below are dedicated to explaining the relationship between the CRUD methods and the Adapter Actions.
+
For first time developers, this is not essential – you just need to assume that the CRUD methods are called by the Adapter Actions when appropriate.
+You may now want to jump to our guide to build a BHoM Toolkit.
+
+
You will read more about the CRUD methods and how you should implement them in their dedicated page that you should read after the BHoM_Toolkit page.
This method exports the objects using different combinations of the CRUD methods as appropriate, depending on the PushType input.
+
+
Let's see again how we described the Push mechanism in the previous page:
+
+
The Push takes the input objects and:
+ - if they don't exist in the external model yet, they are created brand new;
+ - if they exist in the external model, they will be updated (edited);
+ - under some particular circumstances and for specific software, if some objects in the external software are deemed to be "old", the Push will delete those.
+
+
The determination of the object status (new, old or edited) is done through a "Venn Diagram" mechanism:
+
+
The Venn Diagram is a BHoM object class that can be created with any Comparer that you might have for the objects. It compares the objects with the given rule (the Comparer) and returns the objects belonging to one of two groups, and the intersection (objects belonging to both groups).
+
During the Push, the two sets of objects being compared are the objects currently being pushed, or objectsToPush, and the ones that have been read from the external model, or existingObjects.
+
This is the reason why the first CRUD method that the Push will attempt to invoke is Read. The Push is an export, but you need to check what objects exist in the external model first if you want do decide what and how to export.
+
+
Additional note: custom Comparers
+
Once the existingObjects are at hand, it's easy to compare them with the objectsToPush through the Venn Diagram. Even if no specific comparer for the object has been written, the base C# IEqualityComparer will suffice to tell the two apart. If you want to have some specific way of comparing two objects (for example, if you think that two overlapping columns should be deemed the same no matter what their Name property is), then you should define specific comparer for that type. You can see how to do that in the next page dedicated to the BHoM_Toolkit.
+
+
A practical example
+
Now, let's think that we are pushing two columns: column A_new and column B_new; and that the external model has already two columns somewhere, column B_old and column C_old. B_new and B_old are located in the same position in the model space, they have all the same properties except the Name property.
+
We activate the Push.
+
First, the external model is read. The existingObjects list now includes the two existing columns B_old and C_old.
+
Then a VennDiagram is invoked to compare the existingObjects with the objectsToPush (which are the two pushed columns A_new and B_new).
+
1) The object being pushed is new.
+
There is no existing object in the external model that corresponds to one of the columns being pushed. Easy peasy: Push will call Create this column for this category of objects. A_new is Created.
+
2) The object being pushed is deemed the same of one in the external model.
+
What does "deemed the same" means?
+
It means that the Comparer has evaluated them to be the same. This does not exclude that there might be some property of the objects that the Comparer is deliberately skipping to compare.
+
For example, we might have a Comparer that says:
+
+
two overlapping columns should be deemed the same no matter what their Name property is.
+
+
If so, columns B_new and B_old are deemed the same.
+
But then, we need to update the Name property of the column in the external model, with the most up-to-date Name from the object being pushed.
+
Hence, we call Update for this category of objects.
+B_new is passed to the Update method.
+
3) Remaining existing objects that are not among the objects being pushed.
+
What to do with this category of objects? What to do with C_old?
+
An easy answer would be "let's Delete 'em!", probably. However, if we simply did that, then we would force the user to always input, in the objectsToPush, also all the objects that do not need to be Deleted.
+
Which is what we ask the user to do anyway, but to a lesser scale.
+Our approach is not to do anything to these objects, unless tags have been used.
+
We assume that if the User wants the Delete method to be called for this category of objects, then the existing objects must have been pushed with a tag attached. If the tag of the objects being Pushed is the same of the existing objects, we deem those objects to be effectively old, calling Delete for them.
+
Let's imagine that our column C_old was originally pushed with the attached tag "basementColumns".
+If I'm currently pushing columns with the same tag "basementColumns", it means that I'm pushing the whole set of columns that should exist in the basement. Therefore, C_old is Deleted.
+
Overlapping objects with multiple tags
+
Let's say that I push a set of columns with the tag "basementColumns". Everything that those bars need to be fully defined – what we call the Dependant Objects, e.g. the bar end nodes (points), the bar section property, the bar material, etc. – will be pushed together with it, and with the same tag attached.
+
Let's then say I then push another set of bars corresponding to an adjacent part of the building with the tag "groundFloorColumns".
+
It could be that a column with the tag "basementColumns" has an endpoint that overlaps with the endpoint of another column tagged "groundFloorColumns". That endpoint is going to have two tags: basementColumns groundFloorColumns.
+
The overlapping elements will end up with two tags on them: "basementColumns" and "groundFloorColumns".
+
Later, I do another push of columns tagged with the tag groundFloorColumns.
+Some objects come up as existing only in the external model and not among those being pushed.
+Since a tag is being used and checks out, I should be deleting all these objects.
+However, the overlapping endpoint should not be deleted; simply, groundFloorColumns should be removed from its tags.
+
We then call the IUpdateTags method for these objects (no call to Delete).
+That is a method that should be implemented in the Toolkit and whose only scope is to update the tags. Its implementation is left to the developer, but some examples can be seen in some of the existing adapters (GSA_Adapter).
+
A full diagram for 1), 2) and 3)
+
This diagram summarises what we've been saying so far for the Push.
+
+
Complete flow diagram of the Push (advanced)
+
Since an image is worth a thousand words, we provide a complete flow diagram of the Push below. If you click on the image you can download it.
+
This is really an advanced read that you might need only if you want to get into the nitty-gritty of the Push mechanism.
This Action has a more 1:1 correspondence with the backing CRUD method: it is essentially a simple call to Read that grabs all the objects corresponding to the specified IRequest (which is, essentially, simply a query).
+There is some additional logic related to technicalities, for instance how we deal with different IRequests and different object types (IBHoMObject vs IObjects vs IResults, etc).
Note that the method returns a list of object, because the pulled objects must not necessarily be limited to BHoM objects (you can import any other class/type, also from different Object Models).
+
Move
+
Move performs a Pull and then a Push.
+
+
It's greatly helpful in converting a model from a software to another without having to load all the data in the UI (i.e., doing separately a Pull and then a Push), which would prove too computationally heavy for larger models.
The Execute method provides a way to ask your software to do things that are not covered by the other methods. A few possible cases are asking the tool to run some calculations, print a report, save,... A dictionary of parameters is also provided if needed. In the case of print for example, it might be the folder where the file needs to be saved and the name given to the file.
+
The method returns true if the command was executed successfully.
An adapter can be implemented in order to add conversion features from BHoM to another software, and vice versa.
+
An adapter should be added to a dedicated Toolkit repository. See the page dedicated to the The BHoM Toolkit to learn how to set up a Toolkit, which can then contain an Adapter.
The main Adapter file sits in the root of the Adapter project and must have a name in the format SoftwareNameAdapter.cs.
+
The content of this file should be limited to the following items:
+- The constructor of the Adapter. You should always have only one constructor for your Adapter.
+You may add input parameters to the constructor: these will appear in any UI when an user tries to create it.
+The constructor should define some or all of the Adapter properties:
+ - the Adapter Settings;
+ - the Adapter Dependency Types;
+ - the Adapter Comparers;
+ - the AdapterIdName;
+ - any other protected/private property as needed.
+- A few protected/private fields (methods or variables) that you might need share between all the Adapter files (given that the Adapter is a partial class, so you may share variables across different files). Please limit this to the essential.
+
The Adapter Actions
+
Overriding the Adapter Actions
+
If you want, you can override one or more of the Adapter Actions. This can be useful for quick development.
In order to reuse the existing logic embedded in the Adapter Actions, you should not override them. This requires the implementation of CRUD methods which will be called by the Actions. Continue reading to learn more.
+
The Adapter Settings
+
The Adapter settings are general settings that can be used by the Adapter Actions and/or the CRUD methods.
+
You can define them as you want; just consider that the settings are supposed to stay the same across any instance of the same adapter, i.e. the Adapter Settings are global static settings valid for all instances of your Toolkit Adapter. In other words, these settings are independent of what Action your Toolkit is doing (unlike the ActionConfig). If you want to create settings that affect a specific action, implement an ActionConfig instead.
+
The base BHoM_Adapter code gives you extensive explanation/descriptions/comments about the Adapter Settings.
+
Implement the CRUD methods
+
The CRUD folder should contain all the needed CRUD methods.
Here we will cover a convention that we use in the code organisation: the CRUD "interface methods".
+
In the template, you can see how for all CRUD method there is an interface method called ICreate, IRead, etc.
+
These interface methods are the ones called by the adapter. You can then create as many CRUD methods as you want, even one per each object type that you need to create. The interface method is the one that will be called as appropriate by the Adapter Actions. From there, you can dispatch to the other CRUD methods of the same type that you might have created.
The the statement CreateObject((obj as dynamic)) does what is called dynamic dispatching. It calls automatically other Create methods (called CreateObject - all overloading each other) that take different object types as input.
+
Additional methods and properties
+
The mapping from the Adapter Actions to the CRUD methods does need some help from the developer of the Toolkit.
+
This is generally done through additional methods and properties that need to be implemented or populated by the developer.
+
+
Pushing of dependant objects
+
Merging objects deemed to be the same
+
Merging incoming objects with objects already existing in the model
+
Applying an software specific 'id' to the objects being pushed
+
+
Dependency types
+
This is an important concept:
+
+
BHoM does not define a relationship chain between most Object Types.
+
+
This is because our Object Model aims to be as abstract and context-free as possible, so it can be applied to all possible cases.
+
If we were to define a relationship between all types, things would be more complicated than they already are. A typical scenario is the following.
+Some FE analysis software define Loads (e.g. weight) as independent properties, that can be Created first and then applied to some objects (for example, to a beam).
+Others require you to first define the object owning the Load (e.g. a beam), and then define the Load to be applied to it (the weight).
+
We can't have a generalised relationship between the beams and the loads, because not all external software packages agree on that. We should pick one. So instead, we pick none.
+
+
Note: optional feature
+
You can also avoid creating a relationship chain at all - if you are fine with exporting a flat collection of objects. You can activate/deactivate this Adapter feature by configure the Setting: m_AdapterSettings.HandleDependencies to true or false. If you enable this, you must implement DependencyTypes as explained below.
+
+
Dependency types in practice
+
We solve this situation by defining the DependencyTypes property:
+
+This is a property of the single Adapter – that is, it can be different for different software connections.
+
The Toolkit developer should populate this accordingly to the inter-relationships that the BHoMObject hold in the perspective of the external software.
+
The Dictionary key is the Type for which you want to define the Dependencies; the value is a List of Types that are the dependencies.
In the same way that the BHoM Object model cannot define all possible relationships between the object types, it is also not possible to collect all possible ways of comparing the object with each other. Some software might want to compare two objects in a way, some in another.
+
+
Note: optional feature
+
You can also avoid creating a default comparers - if you are fine for the BHoM to use the default C# IEqualityComparer.
+
+
Adapter Comparers in practice
+
By default, if no specific Comparer is defined in the Toolkit, the Adapter uses the IEqualityComparers to compare the objects.
This page gives examples and outlines the general common behaviour of the adapters communicating with structural engineering software.
+
To get an general introduction to how the adapters are working, and how to implement a new one please see the set of wiki pages starting from Introduction to the BHoM Adapter.
+
Specific Structural Engineering adapters
+
For information regarding software specific adapter features, known issues and object relation tables, please see their toolkit wikis:
Please see the samples for examples of how to push elements to a software using the adapters.
+
Pushing and pulling loads
+
The objects assigned to the loads need to have been in the software. The reason for this is that the objects need to have been tagged with a CustomData representing their identifier in the software. To achieve this you can
+
+
First push all the elements, then in a separate step pull them out again and sort out which elements that are applicable to be loaded. (Recomended workflow)
+
Use the objects output of the PushComponent. That adapter will have made sure that all objects coming out from the adapter will have been assigned with the correct tags.
+
+
Please see the samples for examples of how to push elements to a software using the adapters.
As we have seen, the CRUD methods are the support methods for the Adapter Actions. They are the methods that have to be implemented in the specific Toolkits and that differentiate one Toolkit from another.
+
Their scope has to be well defined, as explained below.
+
Note that the Base Adapter is constellated with comments (example) that can greatly help you out.
Create must take care only of Creating, or exporting, the objects.
+Anything else is out of its scope.
+
For example, a logic that takes care of checking whether some object already exists in the External model – and, based on that, decides whether to export or not – cannot sit in the Create method, but has rather to be included in the Push.
+This very case (checking existing object) is already covered by the Push logic.
+
The main point is: keep the Create simple. It will be called when appropriate by the Push.
+
The Create method in practice
+
The Create method scope should in general be limited to this:
+- calling some conversion from BHoM to the object model of the specific software and a
+- Use the external software API to export the objects.
+
If no API calls are necessary to convert the objects, the best practice is to do this conversion in a ToSoftwareName file that extends the public static class Convert. See the GSA_Toolkit for an example of this.
+
If API calls are required for the conversion, it's best to include the conversion process directly in the Create method. See Robot_Toolkit for an example of this.
+
In the Toolkit template, you will find some methods to get you started for creating BH.oM.Structure.Element.Bar objects.
+
AssignNextFreeId
+
This is a method for returning a free index that can be used in the creation process.
+
Important method to implement to get pushing of dependant properties working correctly. Some more info given in the Toolkit template.
+
Read
+
The read method is responsible for reading the external model and returning all objects that respect some rule (or, simply, all of them).
The Read method scope should in general be specular to the Create:
+- Use the external software API to import the objects.
+- Call some conversion from the object model of the specific software to the BHoM object model.
+
Like for the Create, if no API calls are necessary to convert the objects, the best practice is to do this conversion in a FromSoftwareName file that extends the public static class Convert. See the GSA_Toolkit for an example of this.
+
Otherwise, if API calls are required for the conversion, it's best to include the conversion process directly in the Read method. See Robot_Toolkit for an example of this.
+
Update
+
The Update has to take care of copying properties from from a new version of an object (typically, the one currently being Pushed) to an old version of an object (typically, the one that has been Read from the external model).
If you have implemented your custom object Comparers and Dependency objects, then the CRUD method Update will be called for any objects deemed to already exist in the model.
+
Unlike the Create, Delete and Read, this method already exposes a simple implementation in the base Adapter, which may be enough for your purposes: it calls Delete and then Create.
+
This is not exactly what Update should be – it should really be an "edit" without deletion, actually – but this base implementation can be useful in the first stages of a Toolkit development.
+
This base implementation can always be overridden at the Toolkit level for a more appropriate one instead.
+
Delete
+
The Update has to take care of deleting an object from an external model.
+The Delete is called by these Adapter Actions: the Remove and the Push. See the Adapter Actions page for more info.
+
The Delete method in practice
+
Deletion of objects with tag
+
By default, an object with multiple tags on it will not be deleted; it only will get that tag removed from itself.
+
This guaranties that elements created by other people/teams will not be damaged by your delete.
As shown in the Structure of the BHoM framework, an adapter is the part of BHoM responsible to convert and send-receive data (import/export) with external software (e.g. Robot, Revit, etc.).
+
In brief:
+
+
An Adapter connects the BHoM to an external software.
+
Every Adapter offers different functionality, which we call Adapter Actions (for example, Push, which means exporting from BHoM, and Pull, which means importing to BHoM).
+
Different Adapters exist, one per each Software (e.g. Robot), or format (e.g. XML), to which BHoM can be converted.
+
+
Create an Adapter component or formula
+
Depending on the UI Software you are using, you can create an Adapter component (in Grasshopper, or formula if you are in Excel) like this:
+
+
Adapter component
+
+
+
+
+
Select the Adapter component:
+
+
Right click on centre of the component, then select an an Adapter from the menu (or use the text box to search):
+
+
A component gets created. See the inputs and follow the instructions of your chosen adapter to use it.
+
+
+
+
+
+
Select an adapter from the menu:
+
+
A formula gets created in the active cell. See the inputs and follow the instructions of your chosen adapter to use it.
+
+
+
+
+
+
+
Adapter actions
+
The Adapter Actions are the way to communicate with an external software via an Adapter.
+
Adapter Actions are BHoM components that you connect to a specific Adapter (e.g. Robot Adapter). Like any other BHoM component, are always look the same no matter what User Interface program you are using (Grasshopper, Excel, Dynamo...). In Grasshopper, there will be a component representing each action; in Dynamo, a node for each of them; in Excel, a formula will let you use them. You can find the Adapter Actions in the Adapter subcategory:
+
+
Adapter Actions
+
+
+
+
+
+
Select an Actions from the "Adapter" category, e.g. Push:
+
+
+
+
The selected action is instantiated as a component to which an adapter can be connected. You will need to specify also the objects and possibly other inputs; keep reading.
+
+
+
+
+
+
+
+
Select an Actions from the "Adapter" category, e.g. Push:
+
+
+
+
The selected action is instantiated as a formula to which an adapter can be connected. You will need to specify also the objects and possibly other inputs; keep reading.
+
+
+
+
+
+
+
+
Example usage: use Robot Adapter to Push (export) a BHoM model to Robot
+
Before looking at the Adapter Actions in more detail, see the following illustrative example of a Push to Robot.
+
+
Note
+
Although the Adapter actions always look the same, remember that each adapter may behave differently. Some adapters expect that you will use the Push with specific BHoM objects. For example, you can not push Architectural Rooms objects (BH.oM.Architecture.Room) to a Structural Adapter like RobotAdapter.
The following is a brief overview, more than enough for any user.
+A more in-detail explanation, for developers and/or curious users, is left in the next page of this wiki.
+
The first thing to understand is that the Adapter Actions do different things depending on the software they are targeting.
+In fact, the first input to any Adapter Action is always an Adapter, which targets a specific external software or platform. The first input Adapter is common to all Actions.
+
The last input to any Adapter action is an active Boolean, that can be True or False. If you insert the value True, the Action will be activated and it will do its thing. False, and it will sit comfortably not doing anything.
+
Push and Pull
+
The most commonly used actions are the Push and the Pull. You can think of Push and Pull as Export and Import: they are your "portal" towards external software.
+Again, taking Grasshopper UI as an example, they look like this (but they always have the same inputs and outputs, even if you are using Excel or Dynamo):
+
+
Push
+
The Push takes the input objects and:
+ - if they don't exist in the external model yet, they are created brand new;
+ - if they exist in the external model, they will be updated (edited);
+ - under some particular circumstances and for specific software, if some objects in the external software are deemed to be "old", the Push will delete those.
+
This method functionality varies widely depending on the software we are targeting. For example, it could do a thing as simple as simply writing a text representation of the input objects (like in the case of the File_Adapter) to taking care of object deletion and update (GSA_Adapter).
+
In the most complete case, the Push takes care of many different things when activated: ID assignment, avoiding object duplication, distinguishing which object needs updating versus to be exported brand new, etc.
+
Pull
+
The Pull simply grabs all the objects in the external model that satisfy the specified request (which simply is a query).
+
If no request is specified, depending on the attached adapter, it might be that all the objects of the connected model will be input, or simply nothing will be pulled. You can read more about the requests in the Adapter Actions - advanced parameters section.
+
Now, let's see the remaining "more advanced" Adapter Actions.
+
Move, Remove and Execute
+
Slightly more advanced Actions. Again taking Grasshopper as our UI of choice, they look like this:
+
+
Let's see what they do:
+
+
+
Move: This will copy objects over from a source connected software to another target software. It basically does a Pull and then a Push, without flooding the UI memory with the model you are transferring (which would happen if you were to manually Pull the objects, and then input them into a Push – between the two actions, they would have to be stored in the UI).
+
+
+
Remove: This will delete all the objects that match a specific request (essentially, a query). You can read more about the requests in the Adapter Actions - advanced parameters section.
+
+
+
Execute: This is used to ask the external software to execute a specific command such as Run analysis, for example. Different adapters have different compatible commands: try searching the CTRL+SHIFT+B menu for "[yourSoftwareName] Command" to see if there is any available one.
+
+
+
Adapter Actions advanced parameters
+
You might have noticed that the Adapter Actions take some other particular input parameters that need to be explained: the Requests, the ActionConfig, and the Tags.
+
Their understanding is not essential to grasp the overall mechanics; however you can find their explanation in the Adapter Actions - Advanced parameters section of the wiki.
+
Wrap-up
+
The Adapter Actions have been designed using particular criteria that are explained in the next Wiki pages.
+
Most users might be satisfied with knowing that they have been developed like this so they can cover all possible use cases, while retaining ease of use.
+
Try some of the Samples and you should be good to go! 🚀
+
If you are a developer 🤖
+
The BHoM_Adapter is one of the base repositories, with one main Project called BHoM_Adapter.
+That one is the base BHoM_Adapter. The base BHoM_Adapter includes a series of methods that are common to all software connections. Specific Adapter implementations are included in what we call the Toolkits. The base BHoM_Adapter is an abstract class that is implemented in each Toolkit's Adapter implementation. A Toolkit's Adapter extends the base BHoM_Adapter.
+
We will see how to create a Toolkit later; however consider that, in general, a Toolkit is simply a Visual Studio solution that can contain one or more of the following:
+- A BHoM_Adapter project, that allows to implement the connection with an external software.
+- A BHoM_Engine project, that should contain the Engine methods specific to your Toolkit.
+- A BHoM_oM project, that should contain any oM class (types) specific to your Toolkit.
+
When you want to contribute to the BHoM and create a new software connection, you will not need to implement the Adapter Actions, at least in most of the cases.
+If you need to, however, you can override them (more details on that in last page of this Wiki, where we explain how to implement an Adapter in a new BHoM Toolkit).
+
So what is it that you need to implement?
+
The answer is: the so called CRUD Methods. We will see them in the next page.
BHoM_Engine methods are always included into a static class.
+
Different static classes define specific scopes for the methods they contain. There are 5 different static classes:
+- Create - instantiate new objects
+- Modify - modify existing objects
+- Query - get properties from existing objects
+- Compute - perform calculation given an existing object and/or some parameters
+- Convert - transform an existing object into a different type
+- External - reflects methods from external libraries
+
Create
+
+
Returns a new object of the given class.
+
Method is the name of the class being created.
+
+
Bar bar = Create.Bar(line);
+
Therefore the definition of the BHoMObject in the BHoM.dll should not contain any constructors (not even an empty default).
+With the exception of objects that implement IImmutable. See explanation of explicitly immutable BHoM Objects somewhere else. Later.
+
Object Initialiser syntax can be used with BHoM.dll only
+e.g.
+
Circle circ = new Circle { Centre = new Point { X = 10 } };
+
Grid grd = new Grid { Curves = new List<ICurve> { circ } };
+
Modify
+
+
Returns a new version of the same object type as modified.
+
Although immutability is enforced throughout - this namespace is for any method that would be destructive for the object being operated on.
Modify is not actually the correct term/tense now as we are immutable! But immutability is intrinsic in the strategy for the whole BHoM now so in the interest of clarity at both code and UI level Modify as a term is being used. Answers on a postcard for a better word!
+
Query
+
+
Returns a derived property or objects or a simple boolean query (without modifying the information)
+
Although immutability is enforced throughout - this namespace is for any method that wouldNOTbe destructive for the object being operated on.
+
Simply use the Noun, or Verb or prefix with Is
+
+
.Area.Mass.Distance.DotProduct
+
.Clone Could be interpreted as noun or verb, so works.
+
.Intersect
+
.IsPlanar.IsEqual.IsValid.IsClosed
+
In the case of explicitly immutable BHoM objects (see IImmutable), using this notation for derived properties will match notation of Readonly Properties also, which is neat.
+
Compute
+
+
For computationally more intensive methods, iterative processes and/or solvers etc.
+
+
.EquilibriumPosition
+.TextFromSpeech
+.Integrate
+
+
Or for modifying methods that would be destructive for the object being operated on but returns a different return type, or count of objects in a List.
+
+
.Split
+
There will potentially be grey areas between methods being classed as Query or Compute, however in general it should be clear using the above guidelines and the distinction is important to ensure code is easily discoverable from both as an end user.
+
Convert
+
+
Returns a new type of object.
+
Method has the prefix of To or From
+
+
.ToJson()
+.ToSVGString()
+
All convert methods must therefore be in a Convert Namespace within an _Engine project, thus separating this simple functionally from the _Adaptor project, in any software toolkits also.
+
External
+
+
Contains a Constructors method, which returns a List<ConstructorInfo> that will be automatically reflected
+
Contains a Methods method, which returns a List<MethodInfo> that will be automatically reflected
+
Can contain any other method within the constraints presented below.
+
+
For methods whose signature or return type includes one or more schemas that are not sourced from either the BH.oM or the System namespaces.
+
Exceptions
+
Keep GetGeometry and SetGeometery as method names - these perhaps to be still treated slightly differently through new IGeometrical interface? Discuss.
+
Also allow an additional Objects Namespace where Engine code requires local class definitions for which there are good reasons to not promote to an _oM
This page describes the view quality conventions that are used within the BHoM.
+The description is intended to be a non-technical guide and provide universal access to understanding the methods of calculation of different view quality metrics. Links to the relevant methods are provided for those who wish to view the C# implementation.
Hudson and Westlake. Simulating human visual experience in stadiums. Proceedings of the Symposium on Simulation for Architecture & Urban Design. Society for Computer Simulation International, (2015).
we can see the BHoM object as a list of properties and their default values;
+
in the same way, the BHoM Engine can be seen as a big collection of functions.
+
+
Repo Structure
+
The BH.Engine repository is structured to reflect this strategy. The Visual Studio Solution contains several different Projects:
+
+
+
Each of those projects takes care of a different type of functionality. The "main" project however is the BHoM_Engine project: this contains everything that allows for basic direct processing of BHoM objects. The other projects are designed around a set of algorithms focused on a specific area such as geometry, form finding, model laundry or even a given discipline such as structure.
+
+
Why so many projects?
+
The main reason why the BHoM Engine is split in so many projects is to allow for a large number of people to be able to work simultaneously on different parts of the code.
+Keep in mind that every time a file is added, deleted or even moved, this changes the project file itself. Consequentially, submitting code to GitHub can become really painful when multiple people have modified the same files.
+Splitting code per project therefore limits the need to coordinate changes to the level of each focus group.
+
+
Another benefit will be visible when we get to the "Toolkit" level: having different project makes it easier to manage Namespaces and make certain functionalities "extendable" in other parts of the code, such as in Toolkits.
+
Folder structure
+
If we look inside each Engine project, we can see that there are some folders. Those folders help categorize the code into specific actions.
+
There are five possible action types that correspond to five different folder names: Compute, Convert, Create, Modify, and Query.
+
Let's consider the Geometry_Engine project; we can see that it contains all of those folders:
+
+
Those five action names should be the same in all projects; however it's not mandatory that an Engine project should have all of them.
+
Each folder contains C# files; those files must be named as the target of this action.
+
Engine method types
+
In order to sort methods and organise them, 5 different categories of Engine methods exist. All methods will fall into one of these categories.
+
+
Create: methods that instantiate a new object. Remember that the Objects are simple classes defined with no constructor (unless they must be IImmutable -- the only exception where constructors are allowed). You can define any number of methods that create the same objects via any combination of input parameters.
+
Modify: methods that modify an object. Generally, the modify method should have a return type that is of the same type of its first argument. This is to state that the method effectively returns a modified copy of the input object.
+
Query: methods that return some derived value from the input object. A derived value is something that is not found among the defining properties of the object, but that can be inferred from them. For example, the length of a Line object, if the Line itself is defined only by its start and end point.
+
Convert: methods that transform the input object into another type that has similar, or equivalent, meaning. For example, converting a BHoM Structural Bar into a Robot Bar.
+
Compute: methods that perform some computational or I/O heavy functionality, or which do not fall into any other of the previous categories.
+
+
If you are in doubt, try finding another file that does a similar thing in another project, and see where that is placed.
+
For example, in the Geometry_Engine project there is a Query folder that contains, among others, a Length.cs file. This file contains methods that take care of Querying the Length for geometric objects. Consider that another equally named Length.cs file might be present in the Query folder of other Engine projects; this is the case, for example, of the Structure_Engine project, where the file contains method to compute the link of Bars (structural objects).
+
File Structure
+
The file is structured in a slightly unusual way for people used to classic object-oriented programming, so let's look at an example. The following is an extract from the ClosestPoint.cs file of the Geometry_Engine project.
The Namespace always starts with BH.Engine followed by the project name (without the suffix "__Engine_", obviously).
+
+
+
The file should contain one and only one class, named like the containing folder. For example, any C# file contained in the "Query" folder will contain only one class called Query.
+
+
+
Consequently, the name of the file itself will not correspond to the name of the class, as it is usually recommended in Object Oriented Programming. The file name will generally only reflect the name of the methods defined in it.
+
+
+
Note that the class is declared as a partial class. Also note that the class is declared as static.
+
+
+
+
Static and partial
+
The last point might be a bit cryptic for those that are not fluent in C#. Here is a brief explanation that should be enough to move on the next topics.
+
static means that the content of the class is available without the need to create (instantiate) an object of that class. However, that requires that all the functions contained in the class are declared static as well.
+
On the other hand, partial means that the full content of that class can be spread between multiple files.
+
Having the engine action classes declared as static and partial helps us simplifying the structure of the code and expose only the relevant bits to the average contributors.
+
+
Class Structure
+
Fluent C# users should have no problem understanding the structure of Engine classes.
+
For those that want to get stuck without too many technical details, here are a few instructions on how to edit the action classes.
+
+
Inside the class, create a function for each type of object you want to be able to handle. Notice that all the methods have the same name and possibly additional parameters, the only difference is the type of the first argument and possibly the return type.
+
Write this in front of the first argument of each function. This will for example allow to call the methods shown above using the dot . notation. For example, if you have an instance of an Arc type called myArc, you will be able to do myArc.ClosestPoint(refPoint). This way of defining functions is called Extension Methods and will be better explained below.
+
If you find yourself typing the same code for multiple functions (or even inside the same function), you can still create private static methods. Just make sure you place them in a separate private section (use same 3 line comment) after the public methods. In rare cases, you might also want to have your own private data structure for convenience. If that data structure will never be used elsewhere, just define it at the end of the class.
+
+
namespaceBH.Engine.Geometry
+{
+publicstaticpartialclassModify
+{
+/***************************************************/
+/**** Public Methods ****/
+/***************************************************/
+
+publicstaticMeshMergeVertices(thisMeshmesh,doubletolerance=0.001)//TODO: use the point matrix {...}
+
+
+/***************************************************/
+/**** Private Methods ****/
+/***************************************************/
+
+privatestaticvoidSetFaceIndex(List<Face>faces,intfrom,intto){...}
+
+
+/***************************************************/
+/**** Private Definitions ****/
+/***************************************************/
+
+privatestructVertexIndex{...}
+}
+}
+
+
+
Advanced topics
+
While you might be able to write code in the BHoM Engine for a time without needing more than what has been explained so far, you should try to read the rest of the page.
+The concepts presented below are a bit more advanced; if you follow them, however, you will be able to provide a better experience to those using your code. Knowing what Polymorphism is and what the C# dynamic type is will also likely get you out of problematic situations, especially when you are using code from people that have not read the rest of this page.
+
+
Extension Methods
+
A concept that is very useful in order to improve the use of your methods is the concept of extension methods. You can see on the example code below that we get the bounding box of a set of mesh vertices (i.e. a List of Points) by calling mesh.Vertices.Bounds(). Obviously, the List class doesn't have a Bounds method defined in it. The same goes for the BHoM objects; they even don't contain any method at all. The definition of the Bound method is actually in the BHoM Engine. In order for any BHoM objects (and even a List) to be able to call self.Bounds(), we use extension methods. Those are basically injecting functionality into an object from the outside. Let's look into how they work:
Notice how each method has a this in front of their first parameter. This is all that is needed for a static method to become an extension method. Note that we can still calculate the bounding box of a geometry by calling BH.Engine.Geometry.Query.Bounds(geom) instead of geom.Bounds() but this is far more cumbersome.
+
To be complete, we should also mention that we could simply call Query.Bounds(geom) as long as using BH.Engine.Geometry is defined at the top of the file.
+
Polymorphism
+
While not completely necessary to be able to write methods for the BHoM Engine, Polymorphism is still a very important concept to understand. Consider the case where we have a list of objects and we want to calculate the bounding box of each of them. We want to be able to call Bounds() on each of those object without having to know what they are. More concretely, let's consider we want to calculate the bounding box of a polycurve. In order to do so, we need to first calculate the bounding box of each of its sub-curve but we don't know their type other that it is a form of curve (i.e. line, arc, nurbs curve,...). Note that ICurve is the interface common to all the curves.
Polymorphism, as defined by Wikipedia, is the provision of a single interface to entities of different types. This means that if we had a method Bounds(ICurve curve) defined somewhere, thanks to polymorphism, we could pass it any type of curve that inherits from the interface ICurve.
+
The other way around doesn't work though. If you have a series of methods implementing Bounds() for every possible ICurve, you cannot call Bounds(ICurve curve) and expect it to work since C# has no way of making sure that all the objects inheriting from ICurve will have the corresponding method. In order to ask C# to trust you on this one, you use the keyword dynamic as shown on the example above. This tells C# to figure out the real type of the ICurve during execution and call the corresponding method.
+
Polymorphic Extension Methods
+
Alright. Let's summarize what we have learnt from the last two sections:
+
+
+
Using method overloading (all methods of the same name taking different input types), we don't need a different name for each argument type. So for example, calling Bounds(obj) will always work as long as there is a Bounds methods accepting the type of obj as first argument.
+
+
+
Thanks to extension methods, we can choose to call a method like Bound by either calling Query.Bounds(obj) or obj.Bounds().
+
+
+
Thanks to the dynamic type, we can call a method providing an interface type that has not been explicitly covered by a method definition. For example, We can call Bounds on an ICurve even if Bounds(ICurve) is not defined.
+
+
+
Great! We are still missing one case though: what if we want to call obj.Bounds() when obj is an ICurve? So on the example of the PolyCurve provided above, what if we wanted to replace
+
box+=Bounds(curves[i]asdynamic);
+
+with
+
box+=curves[i].Bounds();
+
+
But why? We have a perfectly valid way to call Bounds on an ICurve already with the first solution. Why the need for another way? Same thing as for the extention methods: it is more compact and being able to have auto-completion after the dot is very convenient when you don't know/remember the methods available.
+
So if you want to be really nice to the people using your methods, there is a solution for you:
If you add this code at the end of your class, this code will now work:
+
ICurvecurve=...;
+curve.IBounds();
+
+
Two comments on that:
+- We used IBHoMGeometry here because every geometry implements Bounds, not just the ICurves. ICurve being a IBHoMGeometry, it will get access to IBounds(). (Read the section on polymorphism again if that is not clear to you why). In the case of a method X only supporting curves such as StartPoint for example, our interface method will simply be StartPoint(ICurve).
+- The "I" in front of IBounds() is VERY IMPORTANT. If you simply call that method Bounds, it will have same name as the other methods with specific type. Say you call this method with a geometry that doesn't have a corresponding Bounds method implemented so the only one match is Bounds(IBHoMGeometry). In that case, Bounds(IBHoMGeometry) will call itself after the conversion to dynamic. You therefore end up with an infinite loop of the method calling itself.
+
PS: before anyone asks, using ((dynamic)curve).Bounds(); is not an option. Not only it crashes at run-time (dynamic and extension methods are not supported together in C#), it will not provides you with the auto completion you are looking for since the real type cannot be know statically.
+
Fallback Methods
+
But what if we do not have a method implemented for every type that that can be dynamically called by IBounds? That is what private fallback methods are for. In general fallback methods are used for handling unexpected behaviours of main method. In this case it should log an error with a proper message (see Handling Exceptional Events for more information) and return null or NaN.
+
namespaceBH.Engine.Geometry
+{
+publicstaticpartialclassQuery
+{
+...
+
+/***************************************************/
+/**** Private Methods - Fallback ****/
+/***************************************************/
+
+privatestaticBoundingBoxBounds(IGeometrygeometry)
+{
+Reflection.Compute.RecordError($"Bounds is not implemented for IGeometry of type: {geometry.GetType().Name}.");
+returnnull;
+}
+
+/***************************************************/
+
+...
+}
+}
+
+
Being private and having an interface as the input prevents it from being accidentally called. It will be triggerd only if IBounds() couldn't find a proper method for the input type.
+
Additional comment:
+- At this moment BHoM does not handle nullable booleans. This means it is impossible to return null from a bool method. In such cases fallback methods can throw [NotImplementedException].
+
What About Execution Speed ?
+
For the most experienced developers among you, some might worried about execution speed of this solution. Indeed, we are not only using extension methods but also the conversion to a dynamic object. This approach means that every method call of objects represented by an interface is actually translated into two (call to the public polymorphic methods and then to the private specific one).
+
Thankfully, tests have shown that efficiency lost is minimal even for the smallest functions. Even a method that calculates the length of a vector (1 square root, 3 multiplications and 2 additions) is running at about 75% of the speed, which is perfectly acceptable. As soon as the method become bigger, the difference becomes negligible. Even a method as light as calculating the length of a short polyline doesn't show more than a few % in speed difference.
+
+
RunExtensionMethod Pattern
+
The concept of polymorphic extension methods explained above has one serious limitation: it works only if all methods aimed to be called by the dynamically cast object are contained within one class. That is not the case e.g. for Geometry method, which is divided into a series of Query classes spread across discipline-specific namespaces: BH.Engine.Structure, BH.Engine.Geometry etc. To enable IGeometry method, a special pattern based on RunExtensionMethod needs to be applied:
+
namespaceBH.Engine.Spatial
+{
+publicstaticpartialclassQuery
+{
+/******************************************/
+/**** IElement0D ****/
+/******************************************/
+
+[Description("Queries the defining geometrical object which all spatial operations will act on.")]
+[Input("element0D", "The IElement0D to get the defining geometry from.")]
+[Output("point", "The IElement0Ds base geometrical point object.")]
+publicstaticPointIGeometry(thisIElement0Delement0D)
+{
+returnReflection.Compute.RunExtensionMethod(element0D,"Geometry")asPoint;
+}
+
+/******************************************/
+}
+}
+
+
RunExtensionMethod method is a Reflection-based mechanism that runs the extension method relevant to type of the argument, regardless the class in which that actual method is implemented. In the case above, IGeometry method belongs to BH.Engine.Spatial.Query class, while e.g. the method for BH.oM.Geometry.Point (which implements IElement0D interface) would be in BH.Engine.Geometry.Query - thanks to calling RunExtensionMethod instead of dynamic casting it can be called successfully. The next code snippet shows the same mechanism for methods with more than one input argument (in this case being an IElement0D to be modified and a Point to overwrite the geometry of the former).
+
namespaceBH.Engine.Spatial
+{
+publicstaticpartialclassModify
+{
+/******************************************/
+/**** IElement0D ****/
+/******************************************/
+
+[Description("Modifies the geometry of a IElement0D to be the provided point's. The IElement0Ds other properties are unaffected.")]
+[Input("element0D", "The IElement0D to modify the geometry of.")]
+[Input("point", "The new point geometry for the IElement0D.")]
+[Output("element0D", "A IElement0D with the properties of 'element0D' and the location of 'point'.")]
+publicstaticIElement0DISetGeometry(thisIElement0Delement0D,Pointpoint)
+{
+returnReflection.Compute.RunExtensionMethod(element0D,"SetGeometry",newobject[]{point})asIElement0D;
+}
+
+/******************************************/
+}
+}
+
+
Naturally, in order to enable the use of RunExtensionMethod pattern by a given type, a correctly named extension method taking argument of such type needs to be implemented.
For an user perspective on the UIs, you might be looking for Using the BHoM.
+
Supported UIs
+
The UI layer has been designed so that it will automatically pick everything implemented in the BHoM, the Engines and the Adapters without the need to change anything on the code of the UI.
+
Here's what the menu looks like in Grasshopper. The number of component there doesn't have to change when more functionality is added to the rest of the code:
+
+
When dropped on the cavas, most of those components will have no input and no output. They will be converted to their final form once you have selected what they need to be in their menu:
+
+
You can get more information on how to use one of the BHoM UI on this page.
+
Automatic rendering of a BHoMObject
+
BHoMObjects are rich objects, which may or may not contain a geometry representation.
+If a geometry representation can be extracted, either from one of its properties, or as a result of their manipulation, it can be used to automatically render the object in the GUIs. The only action to enable that, is to create a Query.Geometry method, whose only parameter is the object you want to display, and place it in the Engine namespace that corresponds to the oM of the object. The method has to return an IGeometry or one of its assignable types.
+
For example, let's assume I want to automatically display a BH.oM.Structure.Elements.Bar. I'd do as follows:
+1. Go into the correspondent Engine - i.e. BH.Engine.Structure
+1. Go into the Query folder - i.e. BH.Engine.Structure.Query
+1. If it does not exist yet, create a Geometry.cs file
+1. Add an extension method name Geometry, whose only parameter is the object you want to display:
+
publicstaticLineGeometry(thisBH.oM.Structure.Elements.Barbar)
+{
+// Extract your geometry
+returncalculatedGeoemtry
+}
+
+
Creating a new UI
+
Most of the functionality required by every UI has already been ported to the BHoM_UI repository or to the Engine (when used in more than the UIs). This makes the creation of a new UI a lot less cumbersome but this is still by no mean a small task. I would recommend to reach out to those that have already worked on UI (check the contributors of those repos) before you start writing a new UI from scratch.
This page describes the Units conventions for the BHoM.
+
General philosophy: use SI!
+
The BHoM framework adheres as much as possible to the conventions of the SI system.
+
Any Engine method must operate in SI to avoid complexity of Unit Conversions inside calculations.
+Conversion to and from SI is the responsibility of the Converts inside the Adapters.
+
When some units (derived or not) are not explicitly covered by this Wiki page, it is generally safe to assume that measures expressed in SI units will not be converted by the BHoM.
+
+
Mass: kilograms [kg]
+
Length: meters [m]
+
Force: Newtons [N]
+
Moments: [N*m]
+
Stress/Pressure: [N/m²]
+
Spring constraints: [N/m]
+
Rotational constraints: [N*m/rad]
+
Temperature: [K]
+
+
Localisation toolkit
+
The Localisation_Toolkit provides support for conversion between SI and other units systems.
+
Quantity attributes
+
BHoM object properties can be decorated with a Quantity Attribute to define (in SI) what unity the property should be considered in.
+This is to be applied only to properties that are of a primitive numerical type, e.g. int, double, etc.
The IImmutable interface makes an object unmodifiable after it was instantiated. In order to modify an IImmutable object, a new object with the desired properties needs to be instantiated, where all the properties that are required to stay the same should be copied from the old object.
+
IImmutable should be implemented:
+
a) if objects instantiated from a class should not be modifiable, by design, in some or all of its properties;
+b) if objects contain properties that are non-orthogonal.
+
Whilst reason (a) is self-explanatory, (b) is due to a specific problem that non-orthogonal properties expose.
+
As a reminder, a class with ortogonal properties is a class whose properties all contain information that cannot be derived from other properties. Orthogonality is a software design principle for writing components in a way that changing one component doesn’t affect other components. For example, an orthogonal "Column" class may define a Start Point and an End Point as separate properties, but then it cannot define a third property called “Line” which goes between a start point and an end point, as it would be redundant: modifying the start or end point would require to modify the Line property too. For this reason, class with non-orthogonal properties should implement the IImmutable interface, because the consistency of its properties can be guaranteed only when the class is instantiated.
+
How to implement it
+
To implement the IImmutable interface, you need to make two actions:
+
+
Inherit from it: i.e. public class YourObject : IImmutable
+
The properties you want to be immutable must be public, get only, and contain a default value. i.e. public string Title { get; } = ""
+
All the properties that are not immutable, can follow the usual BHoM conventions, public, get and set, and have a default value
+
It must implement only one constructor, whose parameters are types of all the immutable properties of the object.
+
+
For an example, you can check the BH.oM.Structure.SectionProperties.SteelSection from the Structure_oM:
+Steel Section example
Extension methods required for the IElement interface
+
The following points outlines the use of the dimensional interfaces as well as extension methods required to be implemented by them for them to function correctly in the Spatial_Engine methods.
+
Please note that for classes that implement any of the following analytical interfaces, an default implementation already exists in the Analytical_Engine and for those classes an implementation is only needed if any extra action needs to be taken for that particular case. The analytical interfaces with default support are:
+
+
+
+
Analytical Interface
+
Dimensional interface implemented
+
+
+
+
+
INode
+
IElement0D
+
+
+
ILink<TNode>
+
IElement1D
+
+
+
IEdge
+
IElement1D
+
+
+
IOpening<TEdge>
+
IElement2D
+
+
+
IPanel<TEdge, TOpening>
+
IElement2D
+
+
+
+
Please note that the default implementations do not cover the mass interface IElementM.
+
+
+
If the BHoM class implements an IElement interface corresponding with its geometrical representation:
+
+
+
+
Interface
+
Implementing classes
+
+
+
+
+
IElement0D
+
Classes which can be represented by Point (e.g. nodes)
+
+
+
IElement1D
+
Classes which can be represented by ICurve (e.g. bars)
+
+
+
IElement2D
+
Classes which can be represented by a planar set of closed ICurves (e.g. planar building panels)
+
+
+
IElementM
+
Classes which is containing matter in the form of a material and a volume
+
+
+
+
+
+
It needs to have the following methods implemented in it's oM-specific Engine:
+
+
+
+
Interface
+
Required methods
+
Optional methods
+
When
+
+
+
+
+
IElement0D
+
Geometry()
SetGeometry(Point point)
HasMergeablePropertiesWith(IElement0D)
+
+
+
+
+
IElement1D
+
Geometry()
SetGeometry(ICurve curve)
HasMergeablePropertiesWith(IElement1D)
+
Elements0D()
SetElements0D( List<IElement0D> newElements0D)
NewElement0D(Point point)
+
IElement1D which endpoints are defined by IElement0D
Spatial_Engine contains a default Transform method for all IElementXDs. This implementation only covers the transformation of the base geometry, and does not handle any additional parameters, such as local orientations of the element. For an object that contains this additional layer of information, a object specific Transform method must be implemented.
+
Geometry_oM is the core library, on which all engineering BHoM objects are based. It provides a common foundation that allows to store and represent spatial information about any type of object in any scale: building elements, their properties and others, both physical and abstract.
The code is divided into a few thematic domains, each stored in a separate folder:
+- Coordinate System
+- Curve
+- Interface
+- Math
+- Mesh
+- Misc
+- SettingOut
+- ShapeProfiles
+- Solid
+- Surface
+- Vector
+
All classes belong to one namespace (BH.oM.Geometry) with one exception of Coordinate Systems, which live under BH.oM.Geometry.CoordinateSystem.
+All methods referring to the geometry belong to BH.Engine.Geometry namespace.
+
Interfaces
+
Two separate families of interfaces coexist in Geometry_oM. First of them organizes the classes within the namespace:
+
+
+
+
Interface
+
Implementing classes
+
+
+
+
+
IGeometry
+
All classes within the namespace
+
+
+
ICurve
+
Curve classes
+
+
+
ISurface
+
Surface classes
+
+
+
+
The other extends the applicability of the geometry-related methods to all objects, which spatial characteristics are represented by a certain geometry type:
+
+
+
+
Interface
+
Implementing classes
+
+
+
+
+
IElement0D
+
All classes represented by Point
+
+
+
IElement1D
+
All classes represented by ICurve
+
+
+
IElement2D
+
All classes represented by a planar set of closed ICurves (e.g. building panels)
+
+
+
IElement3D
+
All classes represented by a closed volume (e.g. room spaces) - not implemented yet
+
+
+
+
Tolerances
+
There is a range of constants representing default tolerances depending on the tolerance type and scale of the model:
+
+
+
+
Scale
+
Value
+
+
+
+
+
Micro
+
1e-9
+
+
+
Meso
+
1e-6
+
+
+
Macro
+
1e-3
+
+
+
Angle
+
1e-6
+
+
+
+
Conversion to proprietary software packages
+
While being pulled/pushed through the Adapters, the BHoM geometry is converted to relevant geometry format used by each software package.
At the current stage, Geometry_oM bears a few limitations:
+- Nurbs are not supported (although there is a framework for them in place)
+- 3-dimensional objects (curved surfaces, volumes etc.) are not supported with a few exceptions
+- Boolean operations on regions contain a few bugs
This page covers Structural and Geometrical conventions for the BHoM framework.
+
1D-elements
+
Coordinate system
+
The following local coordinate system is adopted for 1D-elements e.g. beams, columns etc:
+
+
+
x-axis along the centre line of the element from start to end
+
z-axis as the normal direction of the element
+
y-axis transverse to the normal
+
+
Linear elements
+
For non-vertical members the local z is aligned with the global z and rotated with the orientation angle around the local x.
+
For vertical members the local y is aligned with the global y and rotated with the orientation angle around the local x.
+
A bar is vertical if its projected length to the horizontal plane is less than 0.0001, i.e. a tolerance of 0.1mm on verticality.
+
Curved planar elements
+
For curved elements the local z is aligned with the normal of the plane that the curve fits in and rotated around the curve axis with the orientation angle.
+
Section property nomenclature
+
Area - Area of the section property
+Iy - Second moment of area, major axis
+Iz - Second moment of area, minor axis
+Wel,y - Elastic bending capacity, major axis
+Wel,z - Elastic bending capacity, minor axis
+Wpl,y - Plastic bending capacity, major axis
+Wpl,z - Plastic bending capacity, minor axis
+Rg,y - Radius of gyration, major axis
+Rg,z - Radius of gyration, minor axis
+
Vz - Distance centre to top fibre
+Vp,z - Distance centre to bottom fibre
+Vy - Distance centre to rightmost fibre
+Vp,y - Distance centre to leftmost fibre
+As,z - Shear area, major axis
+As,y - Shear area, minor axis
+
Signs of section forces
+
The directions for the section forces in a cut of a beam can be seen in the image below:
+
+
This is:
+* Normal force positive along the local x-axis
+* Shear forces positive along the local y and z-axes
+* Bending moments positive around the local axis by using the right hand rule
The torsional moment follows the Right-hand rule convention.
+
+
+
+
Bar offsets
+
Bar offsets specify a local vector from the bars node to where the bar is calculated from, with a rigid link between the Node object and the analysis bars end point.
+
Hence:
+* a BHoM bars nodes are where it attaches to other nodes,
+* offsets are specified in the local coordinate system and is a translation from the node,
+* local x = bar.Tangent();
+* local z = bar.Normal();
+* node + offset is where the bar node is analytically
+* the space between is a rigid link
It is here outlined how BHoM calculates shear area for a section
+Shear Area formula used for calculation:
+
+And A(x) is defined as all the points less than x within the region A.
+
Moment of inertia is know and hence the denominator will be the focus.
+
+
Sy for an area can be calculated for a region by its bounding curves with Greens Therom:
+
+which for line segments is:
+
+
And while calculating this for the entire region as line segments is easy, we want to have the regions size as a variable of x.
+So we make some assumptions about the region we are evaluating.
+* Its upper edge is always on the X-axis
+* No overhangs
+
i.e. its thickness at any x is defined by its lower edge,
+achieved by using WetBlanketIntegration()
+Example:
+
+
We will then calculate the solution for each line segment from left to right.
+This is important as Sy is dependent on everything to the left of it.
+
We then split the solution for Sy into three parts:
+* S0, The partial solution for every previous line, i.e. sum until current
+* The current line segment with variable t
+* A closing line segment with variable t, connects the end of the current line segment to the X-axis
+
Closing along the X-axis is not needed as the horizontal solution is always zero.
+Visual representation of the area it works on:
+
+
We will now want to define all variables in relation to t
+
+
And then plug everything into the integral
+
+
To summarise the practical proccess
+
+
The region will be converted to the right format by WetBlanketInterpetation()
+
The integral is evaluated for the first line segment and added to the results sum
+
The S0 value for the first line segment is calculated and added to the S_0 sum
+
step 2 and 3 repeats for every line except the last
+
The squared Moment of inertia is then divided by the result
In general, most classes defined in BHoM are a BHoM object, except particular cases.
+Among these exceptions, you can find Geometry and Result types.
+The reason for this is both conceptual and to aid performance. Geometries and Results are not "objects" in the strict sense of the term. In addition, separating those types from actual BHoMObject objects greatly helps with performance down the line.
+
Inheritance from BHoMObject
+
Note that the name of a class in a new object definition is followed by : BHoMObject. This is to say that this object inherits from BHoMObject. This is important if you want your new class to benefit from the properties and functionalities a BHoM object provides.
+
Here is a part of the BHoMObject class definition:
As you can see, the BHoMObject only contains a set of properties.
+
As for any other class in the BHoM framework, we try to keep behaviour (functions, methods) and properties separated. Minor exceptions to this separation are seldom made for for practical efficiency and technical reasons.
+The functionalities of the BHoMObject, as well as of the other BHoM framework types, are defined in the BHoM_Engine.
+
Everything is an IObject
+
As we said before, not everything is an BHoMObject: exceptions are Geometry and Results objects.
+
However, in order to easily identify all the types coming from the BHoM framework, a basic type, or interface, is needed.
+
That's why everything is defined to be an IObject at its root. All BHoM objects will always be an IObject, as BHoMObject is itself inheriting from IObject. Everything else will be too through the chain of interfaces.
+
Let's have a look at one of the Geometry objects, Pipe. As you can see, it inherits from ISurface, one of the base Geometry types.
Properties correspond to the information you need to define your object (to the exception of the properties the BHoMObject class already provides). A few things to keep in mind when you create those:
+
+
All properties must be public and have a public get and set methods, written {get; set;}. (This means that readonly properties are not directly allowed - see paragraph below "Immutable Objects" if you want to know more).
+
Make sure you provide a default value X for your properties by using = X; at the end of their definition; If a properties is too complex to be defined that way, simply set it to null (write = null; at the end).
+
+
As objects grow in complexity, it is useful to think in terms of splitting an object's properties into categories:
+1. Object Defining properties. The minimal required information you need to construct the full object.
+These should generally be the properties of the objects defined in the BHoM
+
+
+
Derived properties.
+Any property that could be calculated from the other properties. These should generally be handled by the BHoM_Engine using extension methods. This choice allows to calculate and obtain those properties only when needed; however, it also mean that you will have to write an explicit "get" method that users will be able to access through the dot . accessor.
+
+
+
Software specific properties such as Software IDs, etc. To ensure that the BHoM is software agnostic, we resorted to store this information in a dynamic (not statically typed) way. That's why we're using a Dictionary (list of key-value pairs) property of the BHoMObject called CustomData.
+For example, the ID assigned to an object for a certain software will be stored as a value of the Key softwareName_id.
+
+
+
Results from analysis. These are to be generally stored as a completely different set of classes, as you can have thousands of results per object.
+
+
+
As an example between Defining and Derived properties for geometry:
+A line is defined by two points. These two points are properties of the line (category 1).
+A line can also have a length, but as that can be derived from the points, this instead sits in the BHoM_Engine as a method called "Length()" (category 2).
+This structure makes sure that on update of the points, the length will also be updated ensuring compatibility of properties at all times.
+
Defining Constructors and Local Methods
+
Important: To the exception of Immutable Objects, BHoM objects should never have a constructor. In general, there should be no method defined in the class either (see Casting methods). So, ultimately, a BHoM object is really nothing more than a list of properties and their default values. Objects will be created either by using an Object Initialiser or via a Create method from the Engine.
+
Anything that manipulates data should generally be in the BHoM Engine. That being said, there are rare occasions where you will see a local method written directly in the object definition. Those methods are generally created there for optimisation reasons or because of the constraints of C# and are therefore the exception, not the rule.
+
For those of you coming from object oriented programming, it might seems quite unnatural to take functionality outside a class as much as possible. There is a few reasons why we have gone that direction:
+
+
Properties of an object are unlikely to change frequently and it is reasonable to expect a list of properties to converge quickly to a final solution, never to be touched again. The methods, on the other hand are always growing, improving or being debugged. Keeping them in more isolated packages will reduce the impact of their change.
+
We want as many people to be able to contribute as possible. While not everyone will be able to write complex algorithms, we expect every engineer to be able to define what properties should be found in an object he/she is using regularly. By separating the complexity levels in different repos, people are enabled to participate by focusing on the part they are comfortable with.
+
Some of the contributors to the BHoM might wish to keep a few methods and algorithms related to a BHoM object private. By limiting the BHoM to object definitions, we are making it easier to share the object models without being forced to share anything else. Do not worry though, the Engine already contains plenty of useful methods and is constantly growing.
+
+
The main disadvantage is that the hierarchical structure of the repositories makes mandatory to update/rebuild any other repository that comes down. For example, any change to the BHoM repository means there is large ripple effect on nearly every other repository.
+
Namespace and Folder Structure
+
+
BHoM objects are organised as shown in the image below. All analytical objects are stored in their respective discipline project (e.g. Structure, Environment,...).
+
A Common project is user for objects shared between disciplines.
+
The inter-disciplinary representation is expressed through physical objects (stored in the Physical folder).
+
Finally, the BHoM and Geometry folders contain core objects and geometry definitions respectively.
+
+
+
+
+Example view of the BHoM solution
+
+
Namespaces have to match the folder structure.
+
In the rare case where folders are more than 3 levels deep, the namespaces are allowed to stop there. For example, the BH.oM.Structure.Results folder contains subfolders. Objects defined in those subfolders are allowed to use the namespace BH.oM.Structure.Results instead of BH.oM.Structure.Results.SubFolder.
+
+
Immutable Objects
+
Warning: This is more advanced feature and not necessary in 99% of the case so you can safely skip this.
+
For some rare objects, it would be problematic to keep only the Defining properties. That is generally the case if the Derived properties are very expensive to compute. In that case, those objects should inherit from the IImutable interface. This is explicitly stating that the properties of those objects should not be modified as it would create inconsistencies within the object. In that case, the properties that are overlapping would only have a { get; } accessor instead of the usual { get; set; }. Here's an example of such a class (with some skipped section highlighted as ...)
Apart from the use of { get; } instead of { get; set; }, you will notice that IImmutable objects will have to define their own constructors inside the class. This is because Object Initialiser do not work on properties without a set so we cannot simply define the constructors in the Engine as we usually do.
+
Casting Methods
+
Warning: This is more advanced feature and not necessary in 99% of the case so you can safely skip this.
+
It is convenient for some objects to be able to be casted from something else. For Example, a geometrical Point could be casted from a Vector or a structural Node could be casted from a Point. This is especially useful inside a user interface. Here's an example where this case is relevant:
+As you can see, we can skip the step of creating a Node since it would only need the Point anyway.
+
Unfortunately, C# doesn't allow to define this outside the class so we have no choice but to do it in the BHoM. Be mindful that this is only relevant when an object could be created from a single other element so this only apply in unique cases and shouldn't be defined in every class.
The Buildings and Habitats object Model (BHoM) is designed to be compatible with both visual flow-based programming (e.g. Grasshopper, Excel, Dynamo) and with proper programming (e.g. coding in C#).
+
This is to integrate well in the workflow of any professional in the AEC industry, regardless of their level of computational proficiency: BHoM is a platform for combining the efforts of the professional programmer with those of any enthusiastic scripter/computational designer/engineer/architect, all in the same ecosystem.
+
The basic architecture
+
The Buildings and Habitats object Model is organised as four distinct categories of code: object Model, Engine, Adapter and User Interface.
+
+
1. The object model [oM] is nothing more than structured data - a collection of schemas.
+
The oM is defined as naturally type strong C# classes, but comprising of only simple public Get Set Properties, with all methods excluded from the class definition including even the requirement for default constructors.1
+Ultimately, they are very close to C type structures with the added benefit of inheritance and polymorphism that a C# class provides.
+
+
+
2. The Engine is nothing more than data manipulators - a structured collection of components/methods.
+
All functionality is provided to the base types through extension methods in the Engine and organised as static methods within public static partial classes.
+Immutability is enforced on inputs of each method to enable translation to flow based programming environment.
+
+
+
3. A common protocol for adaptors enables a single interface irrespective of the external software dealing with.
+
IO and CRUD concepts are combined to enable convenient Push-Pull visual programming UI with CRUD functions interfacing with the external application.
+Crucially, the abstract BHoM_Adapter enables centralized handling of complex data merging so that creators of new adapters can focus on what makes their adapter different, reusing what is common and has already been solved
+
+
+
4. The UI exposes code directly. Same terminology. Complete transparency.
+
By leveraging dynamic binding – mostly leveraging C#'s Reflection – all objects, engine methods, adapters are exposed in the same way on any User Interface. BHoM functionality looks the same whether you use it from a programming script, a Grasshopper script, an Excel spreadsheet, or any other interface that can expose C#.
+
+
+
The approach to coding
+
The above code structure therefore enables flexibility, extensibility, transparency and readability.
+
+
A. Open, flexible data schemas
+
The base object class provides a CustomData Dictionary allowing dynamic assignment of any data type to any object. To the extent that a CustomObject is defined as an Empty Object.
+Default definitions for common objects can be curated and collectively agreed upon, however all are inherently flexible and extendible.
+
+
+
B. Ease of extensibility of functionality too
+
By structuring the code almost exclusively as extension methods in the Engine this enables new functionality to be added to existing objects without the requirement for derived types or indeed modification or recompilation of the base object.
+This naturally opens the door wide to distributed development and customisation of new functionality on top of any existing base objects.
+
+
+
and finally, as highlighted, the above architecture and code design principles place mass participation and co-creation as central.
+
+
C. Transparency in code
+
The source code architecture, principles and terminologies are all open, exposed and reflected as a common language across the visual and text based environments as described.
+This is paramount for a seamless transition from a visual UI to code and vice versa with huge benefits to the developer in debugging and the designer in prototyping and well as a teaching aid to the lower level concepts behind the UI.
+
+
+
D. Human readable data
+
All objects natively serialisable based on JSON being compatible with MongoDB and standard data format for the web.
+
+
+
A shift from data encapsulation
+
Despite being one of the pillars of OOP, data encapsulation has been systematically eliminated in favor of a solution more transparent and more closely related to visual programming. This translates into a few interesting side-effects:
+
A. Node <--> Code correspondence
+
Since objects have no private members and functionality is represented as a collection of individual static methods, the conversion between code and visual programming nodes becomes a straight-forward exercise.
+
+
+
B. Shallow hierarchies
+
Most objects inherit directly from the BHoMObject class and polymorphism is expressed mainly through interfaces. This is made possible without duplication of code thanks to the lack of encapsulation and an engine designed around extension methods.
+
+
+
C. Orthogonal properties
+
+
With all object properties public, it is paramount for those to be independent from each other. This also means the objects are crafted with the minimal required information needed to construct them. All derived properties are exposed as methods in the engine.
1 By exception IImmutable objects are allowed where calculation of derived properties in the engine requires lazy computation.
+Section Profile is a good example
+
In addition some explicit casting and operator overrides etc. are also included in the BHoM definitions of some limited base objects.
+Node is a good example
The programming code of BHoM is hosted under a GitHub organisation: https://github.com/BHoM.
+
The organisation hosts long list of things called Repositories. Most of them will have a name finishing with "_Toolkit". Foundational repositories are instead called BHoM, BHoM_Engine, BHoM_Adapter, BHoM_UI, among others. The Toolkits are the things that host the actual code, with specific terminologies (object Models, oMs), functionalities (Engines) and translators (Adapters).
+
+
Before we discuss in more details what is a repository and what it contains, let's take a step back and look at the different categories of code/functionality we can find inside them.
+
The 4 categories of code
+
If you ever have created your own tool or script, you must must have been exposed to the two dual aspects of computation: data and functionality. In excel, data would be the value of your cells and functionality would be the formulas or VB scripts. In Grasshopper and Dynamo, the functionality is made by the components, and the data is stored within parameters.
+
Data is generally representing specific concepts. For example, Grasshopper and Dynamo provide definitions for Points, Lines, etc., which are geometrical concepts. There are however a lot of objects that we manipulate regularly as engineers that are not defined out of the box in any of those programs. So our first category of code will focus on that: providing a list of properties that fully define each type of object we use. For example, we can all agree that a point would have three properties (X,Y, and Z) each representing to position of the point along one axis. This applies similarly to agree on the definitions of elements such as walls, spaces, speakers,...
+
Manipulators are the bespoke scripts, algorithms, equations, ... that we had to write ourselves to provide calculations not readily available. As engineers we have all had some of those custom made solutions lying around on our computer. Here we simply provide a central place to collect and store them in an organised way so we can all benefit from it.
+
The two categories above are called respectively oM (stands for object model) and Engine. They are all we need to extent our internal computational capability. That being said, we have no intention to reinvent the wheel by replacing external software like Revit, Robot, Tas, IES,... We are also keen to keep using the user interfaces that we already know like Excel, Grasshopper and Dynamo. We are therefore adding two more categories to our central code. Adapters to allow the exchange of data between our internal code and external softwares. UI plugins to typical programs like Grasshopper and Dynamo that expose all our code directly.
+
+
In summary, the 4 categories of code, you will find among those repositories are:
+
+
+
oM: Definitions of the data we manipulate (e.g. Beam, Wall, Speaker,…)
+
+
+
Engine: Our own custom tools, algorithms, data exploration & manipulation.
+
+
+
Adapters: Connections between the BHoM and engineering tools such as Revit, GSA, Tas, IES,... This is where BHoM objects are translated to and from the proprietary representation used in each of those tools.
+
+
+
UI: Expose the BHoM functionality through user interfaces such as Grasshopper, Dynamo and Excel.
+
+
+
Dependency chain
+
+
The concept of a toolkit
+
The BHoM is designed to be extendable. We want anyone to be able to create a set of tools relevant to a specific task (e.g. linking to another external software, providing a set of discipline specific functionality, ...). This is where the repository come in. They are independent units of development with their own team of developers responsible for maintaining the code in the long run. We call them toolkits.
+
Internally, they will all follow the same conventions about the 4 categories of code defined above. To get slightly more into details regarding how that code is structure, let's talk for a second about how those different parts of the code are related to each other.
+
+
+
oM: You could see this as our base specialised vocabulary. It doesn't depend on anything else but everything else will rely on the definitions it contains.
+
+
+
Engine: Depends only on the oM. Since this is an internal engine, it doesn't have to be aware of any external software or UI.
+
+
+
Adapters: The adapter will depend on the oM for the objects definitions and on the engine for the conversion methods
+
+
+
UI: Depends on everything else since it will expose all the functionality above to the UI.
+
+
+
Here's what it looks like in a diagram. To be concise, we will refer to this diagram as the diamond in the future.
+
+
Be aware that most of the toolkits will not implement all four categories. Let's look at a few user cases:
+
+
+
Adapter_Toolkit: E.g. Revit_Toolkit, TAS_Toolkit, GSA_Toolkit,… In there, you will very likely only implement the Adapter category (for the link with the external software) and the Engine category (for the conversion).
+
+
+
UI_Toolkit: E.g. Grasshopper_UI, Excel_UI,... In all likelihood, you will only have to worry about the UI category. You might create and Engine for calculations only relevant to that UI but, most of the time, you'll find it is not needed.
+
+
+
ProjectType_Toolkit: CableNetDesign_Toolkit, SportVenueEvent_Toolkit,… Focus on providing addition functionality specific to a project type. Provides addition object definitions in the oM and algorithms in the Engine. Nothing on the adapter or UI side is needed.
+
+
+
You will find more details on the specific code structure and conventions to follow for each category in the Further reading section but this is probably enough detail for now.
+
Core repositories
+
So, what about the few repositories that don't end with _Toolkit then? Understandably, there is also a large collection of code that will be useful in multiple toolkits. All the code that fits that description will be stored in one of the Core repositories. You will find there is one repository for each category of code.
+
"But, but, why do you have an exploded diamond instead of a single repo for your core?? It would make things more consistent!" That is a valid point but the code in the Core is much larger than any toolkit. Repositories are used to distribute responsibilities between teams of people and to facilitate semi-isolated development. By splitting each category into its own repository, we enable focused sprints with a smaller risk of people stepping on each other's toes.
+
Note that, while toolkits will always depend on the core, the core should never depend on a toolkit. The toolkits are also fairly independent sets of code so there should be very few dependencies between them.
+
+
Further Reading
+
Now that you have a global view of the way the code and the repositories are organised, you might wonder how that translate into you actually writing code either on the core or on a toolkit. Here's where you can find more details on the way each category of code is structured and the conventions you need to follow:
Make sure all instances of Rhino, Excel and Revit are closed before running the BHoM installer.
+
Run the BHoM installer. The installer does not require administrative privileges. If asked for permission, just click OK and proceed.
+
Check if BHoM was correctly installed:
+
+
+
Check if BHoM is correctly installed
+
+
+
+
Open Grasshopper and verify that the BHoM tab is present.
+
+
Click in any empty spot, then press CTRL+Shift+B. This should open up the BHoM menu.
+Try typing something there, like "Point". You should see a list of components.
+
+
+
+
Open Excel and verify if the BHoM tab is present:
+
+
Click on any cell, then press CTRL+Shift+B. This should open up the BHoM menu.
+Try typing something there, like "Point". You should see a list of components.
+
+
+
+
+
+
Installation troubleshooting / FAQ
+
Can't install – Error writing to file XXX: Verify you have access
+
If you get an error such as:
+
+
This can happen on Windows multi-user machines where a previous user had installed an old version of BHoM, and the current user that is trying to install it for himself does not have admin rights.
+
The solution is to delete the C:\ProgramData\BHoM folder.
+Unfortunately, if you don't have admin rights, the only way is to ask your Administrator to delete it.
+
Once the folder has been deleted, any user (also without admin rights) will be able to install BHoM correctly.
+
Developers and contributors 🤖
+
Developers, general contributors, as well as those who need a special version of a toolkit, may need to compile the source code themselves.
+Please read Getting started for developers for more info.
+
+
Alpha installer
+
We have a CI/CD pipeline that produces Daily alpha versions of the installer.
+
At the moment, we don't currently publish Alpha installers due to some techincal issues.
+Please get in touch with us, for example opening a GitHub discussion, if you'd like us to proritize them being published again.
+You can also ask a member of the team to share an alpha installer, if required for some particular development exercise.
+
The Alpha installer includes the most up-to-date changes present on each repository develop branch (or, in absence of that, the main branch).
+Testing before merging to develop (or main) is always conducted, so a good level of stability can always be expected, although integration tests are limited on this stage.
+Certain features may be subject to modifications or corrections until they become permanet features after the beta release.
Create a new software Toolkit using the BHoM Toolkit Template
+
Create a new Toolkit repository
+
Use the template repository to create a new repository. See the readme there.
+
Implement the oM
+
The oM should contain property-only classes that make the schema for your Toolkit. All functionality should be placed in the Engine.
+Functionality that is specific to a class should be defined in the Engine as an extension method.
For this introduction, we will be using Grasshopper as a model but be aware that the same general principles will apply to other UIs (Dynamo, Excel, ...) too.
+
The UI layer has been designed so that it will automatically pick everything implemented in the BHoM, the Engines and the Adapters without the need to change anything on the code of the UI. This means that, instead of having one component for every single piece of functionality, it will group them under common components. This way, the number of component there doesn't have to change when more functionality is added to the rest of the code. Here's what it looks like in Grasshopper:
+
+
In a few words, the oM section is for creating object, the Engine section is for manipulating objects, using them to derive information, or running some form of calculation, and the Adapter section is for exchanging data with external softwares.
+
Key Concept
+
In order to explain how most of those components work, let's start with the Create BHoM Object that can be found in the oM section:
+
+
As you can see, you first drop a dummy component on the canvas that has no input nor output. You then select in its menu what you want it to be to turn it into its final form.
+
The principle is exactly the same for the Compute, Convert, Modify, and Query components in the Engine section as well as for the Create Adapter and Create Query components in the Adapter section. Here's the example for the Create and Create Adapter components:
+
+
+
Search Menus
+
Notice that there are a couple more ways to create the final component you need:
+
+
Use the search menu from the component:
+
+
+
+
Use the Ctrl+Shift+B shortcut and then do a search from that menu
+
+
+
If you want to search for something that include a series of words, just separate them by a space like done above.
+
Create Custom Objects
+
We have seen how to Create BHoM objects using the Create BHoMObject component. There will be situations where you need a type of object that is not part of the BHoM (yet?). For this, we have the CustomObject component:
+
+
This component allows you to define your own objects with a custom set of properties. You will notice that the Component start with two inputs: Name and Tags. This is because a CustomObject is also a BHoMObject and every BHoMObject has a property for Name and a property for Tags. IF you don't want to use those two, just remove them.
+
Usually, that component is automatically figuring out the type of each property based on the data plugged in its inputs. There might be times when it got it wrong. For that reason, you can always specify manually the type of each input from its context menu. This is especially useful when the input is a list. In that case, just tick the box for List to tell Grasshopper you want that list as a single input instead of one value in the list per object.
+
+
Alternative Ways to Create Known Types of Objects
+
The CreateObject component provides a series of recommended ways to create known objects. Those correspond to the methods defined in the Create section of the BHoM_Engine. There might be rare cases where you cannot find a constructor that suits your needs. In that situation, you can use the CreateCustom component to define your own way to build a known object, just select the type of object you want to create from the contextual menu and select your own inputs. Inputs that are not properties of the object will be stored in CustomData.
+
+
Other Types of Objects
+
Sometimes, you will find a component requiring an input that is not a BHoM object and not something you can create in Grasshopper either. The Enum, Type and Dictionary components are exactly there to cover those situations. One case you will probably encounter soon is when using the FilterQuery component from the Adapter section.
+
+
The Dictionary and Enum work from the same principle: you select their final form from their menu.
+
The Enum component has a slightly different form though:
+
+
The Data component shown above is allowing you to select data from one of our static databases. Its output type will therefore vary based on the data you select. Those will generally be a BHoM object though.
+
Engine components
+
The 4 components on the left correspond to the 4 categories of methods you can find in the Engine: Compute, Convert, Modify, and Query (Create being in the oM section).
+
The 3 components in the middle are for extracting or updating properties of BHoM objects. The one you will probably use most of the time is the Explode component:
+
+
The last two components are for converting any BHoM object to and from JSON. This stand for JavaScript Object Notation. This is the langage we use when we represent BHoM objects as string. Unless you see straight away how those components can be of used to you, you can safely ignore them.
+
Adapter components
+
We have already mentioned the Create Adapter and the Create Query components from the right part of the Adapter section. The 6 components on the left part correspond to the 6 operations provided by the interface of every BHoM adapter: Push, Pull, UpdateProperty, Delete, Excecute and Move. Most likely than not, you will generally use the Push and Pull components so we'll show how those two work here.
+
+
Here we have the Socket adapter to send data across and get it back. Obviously, you would use sockets to send data between two different UIs or computers instead of just within Grasshopper but this example is just to show how the Push and Pull components are working.
+
Things to Remember
+
While we have shown quite a few things here, the main thing to remember is that most of the components in our UIs require you to select something from their menu before they switch to their final state. You can do that by either navigation the menu tree or using the search box. Those menu trees are organised exactly the same way has the code you will find on GitHub. You can also use Ctrl+Shift+B to create the final component directly.
+
On top of that concept, remember the CustomObject and Explode components. They are a very convenient way to pack and unpack groups of data.
+
From there, the best way to learn how to use those tools is to play with them in your UI of choice or to browse the documentation provided on the Wiki of each repository.
The variety of AEC (Architecture, Engineering and Construction) commercial software does not always provide solutions to all needs, especially when it comes to collaborating with many people. We frequently encounter particular problems that require some special functionality not offered by any specific software, and we feel the need to implement it ourselves via, for example, custom scripts, or spreadsheets, or macros.
+
BHoM proposes a central Object Model, which is a schema (in other words, a dictionary of terms) on which functionality can be built. By agreeing on common terminology, the output of a script created by one person can easily be used as the input for another script.
+
So, at its core, the BHoM contains a collection of object definitions that we all agree on. The definitions are created by the same domain experts that use them everyday (e.g. Structural Engineers, Electrical Engineers, Architects...), and they are categorised per discipline (e.g. Structure, Architecture, ...). Each definition is simply a list of properties that an object should have (e.g. wall, beam, speaker, panel,...). We call this collection of definitions the object Models (oMs).
+
By extension, the BHoM (Building and Habitats object Model) is the collection of these object Models and the functionality built on top of them.
+
Linking Software
+
Across the AEC industry, regardless of our discipline, we have to work with multiple softwares during the course of any given project. Since there is rarely a simple solution to transfer the data from one software to another, we usually end up either doing it manually each time or writing some bespoke script to automate the transfer. Things get even more complex when we work across disciplines and with other collaborators. When the number of software to deal with becomes more than just a few, this one-to-one translation solution quickly becomes intractable.
+
This is where the BHoM comes in. Thanks to the central common language, it is possible to interoperate between many different programs. Instead of creating translators between every possible pair of applications, you just have to write one single translator between BHoM and a target software, to then connect to all the others.
+
We call those translators Adapters.
+
+
Linking functionality
+
Most often, AEC industry experts create ad-hoc functions and tools when the need arises. Common examples are large, complex spreadsheets, VBA macros for Excel, but also small and large User Interface programs written in C#, Python or other tools.
+
In such a large sector, most problems you encounter are likely to have been solved before by someone in your organisation, or outside. What frequently happens is that the wheel gets reinvented. Additionally, when a script is created, it often exists in isolation, and is used only by a small group of people.
+
Let's take the example of a user wanting to create some functionality in an Excel macro. This has several issues:
+
+
+
Maintanability issues. Frequently, only the original creator of a Macro knows how to develop or maintain it. If they are not around and a problem arises, the Macro is often just thrown away.
+
+
+
Shareability issues. For example, if the creator of a Macro that performs some function in a spreadsheet wants to share this functionality with one of their clients, they end up sharing the spreadsheet with the Macro in it, effectively sharing the source code (the fruit of their hard work), which could end up being copied.
+
+
+
Scalability issues. Macros are hard to scale. If you need to add more features or more complex functionality in a Macro, the code soon becomes unmanageable.
+
+
+
Collaboration issues. Collaborating on the code written in a Macro is a mess. Only one person can work on it at the same time. In order to merge the work of different people into a same Macro spreadsheet, either a library is created, or copy-paste is required.
+
+
+
BHoM proposes to create a common library of functionality in Engines, which are simply tidy collections of functions. Like Adapters, Engines can be stored in Toolkits, which are simply GitHub repositories. GitHub repositories make it easy to share and collaborate on code (or not share, if privacy is chosen). BHoM makes it very easy to expose any functionality written in an Engine to Excel, Grasshopper, or other interfaces.
+
Thanks to the BHoM being exposed in various UIs such as Grasshopper and Excel, you don't even need to know how to write code to use the functionality created by other people.
+
+
Linking people
+
By sharing terminology, functionality, and connectivity to software, BHoM allows us to shift the attention from "connecting data" to "connecting people together"!
+
BHoM also embraces Open Source as a practice: there is infinite value in opening up development efforts to the larger AEC community. Sharing effort pays big time!
All of the repositories within the BHoM organisation contain only curated and strongly controlled code.
+The aim is to provide a coherent set of tools that are all compatible with each other. As well as clear and robust quality control, review and testing procedures - enabling release across a wider part of the practice.
Following the clarification of the best location for different code above - instructions on how to create a new BHoM Repo with the correct settings:
+
+
+
Name the Repo SoftwareNameOrFocus _Toolkit. It will always end in Toolkit see explaination here
+
+
+
Make sure the Public option is selected.
+
+
+
Under Settings -> Options. Ensure only Rebase merging is enabled
+
+
+
+
+
+
Add a Team under Collaborators and teams
+
+
+
Under Branches. Set the main Branch as protected with the following settings (click edit on the right-hand side of the listed main branch)
+
+
+
+
+
If you don't have a team for that repo yet, you can create it here. Make sure the team has the same name as the repo and that you have added the repo into its list of repositories with the the "Write" access level. Now you should be able to link it in the branch setup page above.
+
+
Initial Content
+
TODO: provide details about:
+- Readme file
+- License file
+- gitignore file
+- VS template
This documentation is simply a set of Markdown documents, stored and organised in the Documentation repository.
+The markdown documents are then automatically mapped to a web page every time a Push to the main branch of the Documentation repository is done. See below for technical details on how this is achieved.
+
Depending on your account permissions, you should be able to commit directly to main, or a Pull Request will be required to perform the changes.
+
Minor modifications
+
For small modifications, you can click the pencil ✏️ icon on the top-right of the page. This will bring you to the Github Markdown editor.
+
Avoid this for non-minor changes. Limit this approach to e.g. correcting typos, rephrasing sentences for clarity, adding short sentences, fixing URLs.
Navigate to the docs folder, and edit a markdown file or add new markdown files.
+
+
The enhanced markdown
+
The documentation markdown can incorporate non-markdown content. You can embed:
+
+
+
HTML blocks with embedded functionality, e.g. (click on details to see!):
+
+
+
+
+
+
+
+
+
+
Latex/Mathjax, e.g. \(f(x) = x^2\) (enclose the formula between single $ for inline and double $$ for block).
+
+
+
+
Tip
+
Many more features are available to spice up the look of the documentation and help you convey information.
+See the available customisations of Material for Mkdocs: setup and Markdocs extra elements.
+
+
Using a text editor to edit the documentation
+
We recommend using either Visual Studio Code or Markdown Monster to edit the documentation.
If you want to add a page, just add an new markdown document.
+
The first H1 header (#) of the page will be taken as the title of the corresponding webpage.
+
Each header will be reflected in the navigation menu on the right hand side of the page.
+
Linking to other documentation pages
+
Recommended way
+
Links to other documentation pages should be relative URLs (starting with a /) where the first slash must be followed with the documentation folder. Some examples:
+
+
To link to the Introduction to BHoM_Adapter page, you can provide this link: /documentation/BHoM_Adapter/Introduction-to-the-BHoM_Adapter.
+
To link to the IsValidDataset page, you can provide this link: /documentation/DevOps/Code%20Compliance%20and%20CI/Compliance%20Checks/IsValidDataset.
+
+
+
Note
+
This way of providing URL to pages is required because MkDocs reflects the markdown files starting from the root documentation.
+
+
+
Tip
+
If using Visual Studio Code, enable Error Reporting on Markdown files and Link Validation in settings. VS Code will then check the validity of local links and cross referencing across your Markdown files, flagging warnings where links are invalid. VS Code Link Validation
+
+
Alternative (not recommended)
+
If you are editing a specific nested page you can also use URLs relative to the current page. Some examples:
+- To link to the Getting started for developers page, relative to this current page (Editing-the-documentation), you can provide: ../Getting-started-for-developers.
+
Folders
+
Folders behave as groups for sub-pages and are reflected into the left menu of the website.
+
A folder may contain one markdown file called index.md; if it exists, that file is taken to be the first page of the folder when viewed from the website.
+
For information on how to sort the pages, see below.
+
Previewing the website before pushing to the repository
+
You may want to preview how your markdown documents will appear in the automatically-generated website. In order to do this, you can use mkdocs from command line.
+
You need to:
+
+
Have Python and PIP installed on your machine. Install mkdocs by running
+
pip install mkdocs
+
+
You will also need to ensure you have the MkDocs extensions and plugins that we are utilising installed. These can also be installed using pip by running the following:
+
Navigate to your locally cloned documentation repository folder.
+
In that location, invoke from command line:
+python -m mkdocs serve
+
+
Mkdocs should spin up a local server and you should be able to connect to http://localhost:8000/ in your browser to display the documentation website. Any change to your local file will be hot-reloaded into the webpage.
+
Website configurations
+
As mentioned, the Markdown documents are transformed into a proper web page thanks to mkdocs every time a Push to the main branch of the documentation repository is done.
+
The web page can be configured by configuring mkdocs and related dependencies.
You just need to add a .pages text file in the specific folder where you want to sort out your pages. For an example, see the .pages file in the docs folder.
As a general rule, the icons are stored in the BHoM_UI repository. All other UIs will then use those directly so there is no need for each UI to create its own icons.
+
Specific Toolkit Icons
+
TODO
+
Software Specific Guidelines
+
+
Grasshopper icons are 24x24px png files and follow David Ruttens Guidelines.
+A recommended workflow is to export a 24x24px png from Inkscape with a 20x20px vector inside it and then use Gimp to add a dropshadow.
Tasks to be completed before migration to public organisation.
+To be carried out/reviewed by the Repository Owner:
+
Licencing and copyright
+
+
Ensure repository has valid licence file.
+ BHoM defaults to LGPL v3 https://github.com/BHoM/BHoM/blob/master/LICENSE.
+ Repositories can naturally be licenced differently, but by exception only and through coordination with BHoM Organisation Administrators. In addition this will also require modifications to the repo's copyright headers in every code file.
+
All code files must have a valid BHoM copyright header compatible with licencing (see point above)
+ See here for the default https://github.com/BHoM/BHoM/blob/master/COPYRIGHT_HEADER.txt
Pull Requests are the primary mechanism of resolving issues and deploying new code to users. They provide us an opportunity to review and reflect on the proposed changes and ensure they meet the criteria of the issue and the broader agenda without introducing any major concerns with bugs or broken functionality.
+
Pull Requests should be seen as a collaborative process during the review stage. Raising a pull request is not a guarantee that proposed changes will be deployed to the main branch, but changes can only be deployed via a pull request mechanism.
+
Raising a Pull Request
+
A pull request can be raised at any stage of the development cycle, either as draft, WIP (Work In Progress) or as ready for review depending on the state of the proposed changes. A pull request can be reviewed at any time by anybody, but it is good practice to request a review from key individuals working in that area (for example, a DevOps reviewer when making changes to the core, or a geometry reviewer if making changes to the Geometry oM/Engine).
+
A raised pull request should have the following features within it - these are provided as headings in the pull request template to complete when raising the pull request:
+
+
Clear identification of any dependant pull requests that this work is relying on to operate - for example, if your work in a toolkit depends on a change in BHoM_Engine, then in the toolkit pull request there should be a clear link to the BHoM_Engine at the top of your toolkit pull request
+
Linked issues that are being resolved by this pull request - where there are multiple pull requests in a series, at least one of them needs to be referencing an issue that clearly outlines what needs to change in the code. The pull request should aim to solve just the issue outlined. One pull request can resolve several issues at once if needed
+
Test scripts - either reference to data-driven unit-tests (which BHoMBot will then run) or links to test scripts built in a BHoM suitable UI, or reference to the issue which may contain test scripts when the issue was raised.
Additional comments - anything extra you feel will help the reviewers in reviewing your pull request
+
+
Categorising a Pull Request
+
All pull requests should set a label defining the type of pull request, this is to categorise pull requests when producing the change log.
+
Pull Request activity
+
A pull request is a mark of coding resource that was used to try to solve a given issue (or issues). As such, it should be viewed that a pull request is aiming to deploy that code to the main branch (pending review) unless it is a speculative piece of work looking at possible options for a given idea. However, due to the pace of change within the BHoM ecosystem, a pull request can be difficult to deploy if it is left for too long. By rule of thumb, a pull request should aim to be deployed within one sprint of time (raised, reviewed, amended per review, and deployed), to avoid hanging work that isn't deployable.
+
To keep our review requirements focused on the latest workload, each milestone will have a Pull Request closure day if deemed necessary by DevOps.
+
Stale Pull requests
+
Pull requests which have not had any activity in 3 months are deemed to have gone stale.
+
Pull requests which have not had any activity in 6 months will be closed to avoid drawing review resource if no activity has happened. Activity can be defined as committing code to the pull request, commenting on the pull request (even if just with an update stating the work is still desired but there's a lack of resource to close it out currently) or any activity which shows up on the pull request within the time period examined.
Open issues are reviewed weekly and the most critical ones are assigned to
+specific people as part of their weekly tasks. That task of resolving an issue
+is called a sprint. If you need more information on how those issues are being
+created, check this
+page.
+
A person in charge of that issue will then create a new branch, write the code
+necessary to solve that issue (with potentially multiple commits on that
+branch) and then submit a pull request to merge that branch back to the
+main development branch. This pull request will be reviewed by other developers
+and the code on that branch will potentially be edited to match everyone's
+satisfaction. The pull request will then be approved and the branch will be
+merged with the main one. For more detailed explanations on the process, check
+this short guide
Overview of important steps to successful coding in the BHoM
+
A. Preparatory work
+
Preparatory work is mandatory. Before doing anything review the activity in relevant repos and speak to team
+ working in similar areas of the code. You can not start working on any part
+ of the code before you have checked that there are no Pull Requests open for the Project or for the
+ entire repo you want to modify. See naming
+ convention
+
If the above steps are not fulfilled, coordinate with the person
+ working on that branch. Either work on the same branch if possible,
+ expanding the pull request to cover more issues (make sure you link all
+ issues in the conversation of the pull request), or work
+ locally
+ on your machine until the other branch is merged.
+ 1. If you choose to work on the same pull request, make sure any
+ conversation being done is done publicly on Github to ease to process of
+ the reviewers.
+ 2. If Urgent and you cannot coordinate
+ work locally, but do not branch yet
Push each individual Commit - keeping commits as specific and frequent
+ as possible. Always review what files you are committing. And make sure your
+ sprint is not drifting from the original issue.
Issues are used to keep track of all the requests for bug fixing, new features,... They can be created inside each repository and optionally assigned to a specific person.
On github, go the the repository that needs modifications and select the Issues tab.
+
+
+
Click on the green New Issue button on the top right corner.
+
+
+
+
+
+
Fill in the title. The name should be Description or ProjectName - Description depending on whether the issue needs changes in the entire repo or in a specific Visual studio project. If you don't know which one it is, just use the repository name.
+
+
+
and fill in the description. This is using markdown so you can format your message like you would a wiki page. You can also attached files simply by dropping them in the message area.
+
+
+
Please be specific as you can with both the title description and the body text to give others as much information and context around your proposed issue.
+
+
+
If you are not already a BHoM Collaborator or part of the Organisation, then you are good to go. Press Submit New Issue. A collaborator already with write access will pick up the issue and Label/Assign.
+
+
+
Collaborator Issue flagging and assignment
+
+
+
As a collaborator or maintainer with write access - it is important to assign labels, as well as assignees if at all possible, for issues as you create them - as well as new issues created by others outside of the organisation to assist with triaging
+
+
+
If you already know who is going to handle that issue, you can assign it to that person by using Assignees on the right side of the screen. Otherwise, just leave it blank.
+
+
+
Make sure you select a Label to specify the type of issue you have (more about this on the next section).
+
+
+
If you request is linked to a very specific deadline, you can also pick a Milestone from the list.
+
+
+
+
Choose a Label
+
The two main categories of labels are feature and bug. Features are for requesting functionality that doesn't exist yet. If there is similar functionality already but not matching 100% what you need (e.g. missing inputs or outputs you would need), this is also a feature request. Bug is for when that functionality exists but provides an incorrect result or crashes.
+
For both of those categories, we have 3 levels of importance:
+
+
Critical: It is simply impossible to continue without either that feature or fixing that bug. No workaround exists using alternative methods or a quick self-made script.
+
Regular: This is slowing down progress. There is a workaround but it is not exactly ideal.
+
Minor: You noticed a missing feature or a bug but it doesn't stop/slow you in your current work.
+
+
+
Outside of those two main groups, 4 more labels are provided:
+
+
Compliance: This is for people working directly within the code. You found some code that doesn't follow th rules we have in place for how the code should be structured and would like this to be fixed.
+
Question: When you don't have anything specific you need to be changed but would like some clarification on a specific point or would like to start a debate.
+
Test_script: You have created some new functionality and would like it to have its own set of automatic testing scripts to make sure it is regularly checked. Notice that you have to raise the issue where the test scripts will be written, NOT where the code to be tested is.
+
Documentation: You find the documentation about a specific part of the code lacking. As for the test_script label, you need to raise the issue in the repository where the documentation is going to be created.
This documentation will be focused on the use of Git Bash.
+
The first step is to create a space on your computer where you want all your local files to be stored. Now you want to create different repositories (repos) in this folder. Do this by opening up git bash and using git clone (web address). A good list of repos for getting started can be found here.
+
Pushing code changes to GitHub
+
Before getting started it is recommended to read through this first.
You create a new branch with git checkout -b (name of the branch). Make sure that you are on develop when creating a new branch to prevent branches created from other branches.
+It is now time for you to do the changes you wish to do. When you are satisfied with everything it is time make a commit. You should always rebuild the code to make sure that it compiles, and if needed test out the code before pushing it to GitHub.
+
Start by running git status which will show you, in red, all of the files that has been changed. If everything looks alright use git add . which adds all of the files to the commit. If you wish to only add selected files you can use git add (name of the file) for the files you wish to include.
+
Once the files are added it can be a good idea to double-check using git status again, and the included files should now be showed in green instead of red.
+Then it is time to use commit these changes with git commit -m ("message"). Keep in mind that this message will be shown on GitHub along the commit so a somewhat brief explanation of what is included in the commit can be a good idea.
+
Finally it is time to actually push the commit to GitHub with git push origin (branch name). It is now possible to create a pull request on GitHub.
+If you were to need to make any more changes before the PR is merged just make sure you are on your branch for that feature, (no need to create a new branch) and do the necessary changes and then start the push process again, starting with git status and git add ..
+
Avoiding conflicts
+
In order to avoid conflicts when creating pull requests make sure that the repository you are working on is up to date.
+Make sure you are on the develop branch by using git checkout develop
+Start off by using git fetch origin which gets updates from other repositories and then git pull origin (branch name) to update your code from others.
To keep things organised and avoid stepping on each other's toes, we are relying on the GitHub Project SCRUM Board. The Project SCRUM Board is the way we communicate, the tool we use to have a bigger picture of what is happening, and the way you will keep records of your work into the BHoM.
+Since the the Project SCRUM Board is fully automatised, it is read-only and represents a view on what is happening across all the BHoM repositories.
+
.
+
Each card that you see there corresponds to an issue raised in one of the repos. From the moment it is created to the time when that issue has been completely resolved, the corresponding cards, i.e. the issue card and the associated pull-request card, will go through the different columns of this board.
+
Creating a Card
+
The best way to create a card is to create an issue in the corresponding repository and add it to "SCRUM Development Board Planning" project. The card will automatically appear in the most appropriate column.
+
Although this is not recommended, if you want to create the card from the project board itself, see the GitHub's help page Adding issues and pull requests to a project board. Be mindful that when you convert the card to issue, it should follow the guidelines described in Submitting an Issue
+
SCRUM Board Columns
+
Priority this Sprint
+
This column contains only issue cards. Once an issue has been assigned to a person as part of his/her tasks for the week, the card can be added to the "SCRUM Development Board Planning" project. This action will place the card - an issue card - into the "Priority this Sprint" column automatically. If the card/issue was not assigned to anyone at that time, it will then be assigned to that person. You can see who has been assigned the issue by looking at the avatar at the bottom right of the card.
+
In Progress
+
This column contains only pull request cards. A card is in this column when a person starts working on the corresponding issue. New pull requests that are added to the "SCRUM Development Board Planning" project will automatically appear here. Normally, only one card per person should be in that column at a time.
+
+
+
Cards in that column are also locking the repository or the project it targets. This means that nobody is allowed to start editing code in that repository while a card is in the In Progress or Review in Progress column. This also means that you can only add a card in that column if there is not already a card locking the same repository. Coordinate with the card's owner if this is the case.
+
Review in Progress
+
This column contains only pull request cards. Once the pull request has been reviewed, and a reviewer requested a change, the automation will move the card from the In Progress column into this one.
+
Reviewer approved
+
This column contains only pull request cards. Once the changes in the pull request have been accepted by the minimum number of reviewers required, it will be moved into this column. When a pull request is in this column, it is ready to be merged, unless a label do-not-merge is on it.
+
Completed
+
Once the pull request has been merged into the master branch and the issue closed, the card is moved the the Completed column where it will be discussed in the next planning call. Notice that, once an issue is closed, the logo at the top left of the card has turn red. The Completed column is the only one that should have cards in that state.
Posting test files in GitHub Issues and Pull Requests (PR) is important, because they allow to reproduce the problem you may have or the feature being implemented.
+
Please remember that there are also other means of testing the code (e.g. code Unit tests; automated Data-driven equality unit tests), so some PRs may not expose any test file. However, if you only know how to reproduce your issue or wanted feature via a script (e.g. a Grasshopper script), or if you think that the PR/issue would benefit from it, then you should post it in the body of your issue (or PR, where applicable).
+
How to post a test file
+
+
Create your test script (e.g. in Grasshopper).
+
Save your test script in a file.
+
Zip your test script file.
+
Drag and drop the test script file in the body of the GitHub issue or PR.
+
+
Large test files
+
The zipped test file must be less than 50 MB (GitHub size limit), and in general should be less than 10 MB.
+If your test file is larger than that, it means that you've embedded (internalised) too much testing data. You should simplify the test script to use the minimal amount of data necessary to reproduce the problem.
+If your test script purposedly targets a large model, then the script should only hold a reference to such model (e.g. a link to it) and the model should be uploaded via another file hosting service.
The BHoM is released as a complete package, with the individual BHoM libraries and its toolkits all versioned together. This is to ensure ease of tracking compatibility across the number of dependant repositories.
+
BHoM versions are therefore named using the following convention: major.minor.α/β.increment
+
Major version
+
A major version denotes some fundamental change in the BHoM framework. Targeted approximately yearly.
+
Minor version
+
Minor versions denote the more frequently planned development cycles and the release of new features/issues, as per individual development road maps and SCRUM planning. Targeted every couple of months/quarterly.
+
Alpha releases
+
The live current state of all the master branches are compiled as an alpha release. This is automatically kept up to date for each successful merging of a PR or PR cluster.
+Each alpha release will therefore have a major and minor version number according to the current development cycle, followed by an alpha and an incremented release number for each occurrence,
+i.e. major.minor.α.increment.
+
Beta releases
+
At the end of a successful development cycle a new beta version will be released
+i.e. major.minor.β.0.
+
A new minor development cycle will therefore then start.
+
Hotfixes to beta releases are made only in exceptional circumstances.
+That is if and only if a critical issue is found and it is deemed necessary to include in the previous minor version, in advance of the release of the current cycle. If this happens, the last digit of the beta release will be incremented, i.e. major.minor.β.1 etc.
+
Example development and release sequence
+
Example table of a sequence of releases over a number of development cycles:
The change log is made by aggregating the notes from Pull Requests for each repository within the organisation. They are available here
+
Pull requests
+
To simplify the managing of the changelog it is best practice to note what has changed at the time of a pull request. The change log will be generated from the title and body of the pull request using the PULL_REQUEST_TEMPLATE.
+
The Pull Request Title should state, in a simple sentence, what the Pull Request is changing. For toolkits, this should not include the toolkit title, however, for multi-project repositories it should. For example:
+
A Pull Request raised on the XML Toolkit to update Space Type will simply have the title of:
+
+
Update Space Type
+
+
Whereas a Pull Request on the BHoM_Engine to update the Environment Engine panel query will have the title of:
+
+
Environment_Engine: Update panel query to use names
+
+
If the changes are greater than a single sentence can describe, then in the Changelog section, describe the changes in a bulleted list.
+The bullet points are required and no other information other than brief definition of changes should be made in this section. The Additional Comments section is then for any additional information or more verbose context.
+
For example:
+
### Changelog
+
+- `Query.Tangent()` Query method added in the `Structure_Engine` for `Bar` class
+
+
The entries made here will be mined for the next release and added to the changelog in one go.
+
Pull requests must also have a label defining their type - either feature, bug fix, test script, documentation, compliance, or other approved type of pull request. This is to aid categorisation of pull requests for the change log. Where a pull request might span multiple types (for example, a pull request adding a new feature and fixing a bug in the same work), then multiple type labels may be applied.
This check will trigger all checks available to BHoMBot to be queued for the pull request. BHoMBot will confirm what checks are being triggered when the command is run.
This check will confirm the branch name for the pull request matches the guidelines.
+
If the check is unsuccessful, it will remind you of the conventions for next time. Following the conventions on branch naming is very important for CI processes.
This check will confirm the cs files changed within a pull request are compliant to the guidelines for code files. This check will run only the compliance checks that have the Compliance Type of code in the table on the linked page.
+
If the check is unsuccessful, you can trigger BHoMBot to make certain fixes for you. This can be accessed by viewing the details of the check and clicking the Fix button to trigger the process on the pull request.
+
If you believe the check has failed erroneously, you can request dispensation from the CI/CD team. This can be accessed by viewing the details of the check and clicking the Request Dispensation button to trigger the process on the pull request. The CI/CD team will review the failures and weigh up the options on progressing the pull request. Dispensation may not always be granted, but this will be a discussion between the pull request collaborators and the CI/CD team.
This check will trigger all compliance checks available to BHoMBot to be queued for the pull request. BHoMBot will confirm what compliance checks are being triggered when the command is run.
This check will confirm the cs files changed within a pull request are compliant to the guidelines for having valid copyright on their code files. This check will run only the compliance checks that have the Compliance Type of copyright in the table on the linked page.
+
If the check is unsuccessful, you can trigger BHoMBot to make certain fixes for you. This can be accessed by viewing the details of the check and clicking the Fix button to trigger the process on the pull request.
+
If you believe the check has failed erroneously, you can request dispensation from the CI/CD team. This can be accessed by viewing the details of the check and clicking the Request Dispensation button to trigger the process on the pull request. The CI/CD team will review the failures and weigh up the options on progressing the pull request. Dispensation may not always be granted, but this will be a discussion between the pull request collaborators and the CI/CD team.
This check will confirm the pull request will compile successfully on its own. This check is operated by both BHoMBot (all repositories) and Azure DevOps (selected repositories).
+
The check will clone the repository associated to the pull request, then clone the repositories listed in that repositories dependencies.txt file and build them in the order listed in that file. The pull request will then be built last.
+
Providing the compilation is successful, the check will return a pass. If the pull request cannot compile then it will return an error. BHoMBot will list the errors as annotations, while Azure needs to be reviewed to ascertain the errors.
+
+
Trigger commands:
+
BHoMBot
+
+
@BHoMBot check core
+
+
Azure DevOps>/azp run <Your_Toolkit>.CheckCore
+
(where <Your_Toolkit> is the name of your repository).
This check will confirm the json files changed within a pull request are compliant to the dataset guidelines for dataset files. This check will run only the compliance checks that have the Compliance Type of dataset in the table on the linked page.
+
If the check is unsuccessful, you can trigger BHoMBot to make certain fixes for you. This can be accessed by viewing the details of the check and clicking the Fix button to trigger the process on the pull request.
+
If you believe the check has failed erroneously, you can request dispensation from the CI/CD team. This can be accessed by viewing the details of the check and clicking the Request Dispensation button to trigger the process on the pull request. The CI/CD team will review the failures and weigh up the options on progressing the pull request. Dispensation may not always be granted, but this will be a discussion between the pull request collaborators and the CI/CD team.
This check will confirm the cs files changed within a pull request are compliant to the documentation guidelines for code files. This check will run only the compliance checks that have the Compliance Type of documentation in the table on the linked page.
+
If the check is unsuccessful, you can trigger BHoMBot to make certain fixes for you. This can be accessed by viewing the details of the check and clicking the Fix button to trigger the process on the pull request.
+
If you believe the check has failed erroneously, you can request dispensation from the CI/CD team. This can be accessed by viewing the details of the check and clicking the Request Dispensation button to trigger the process on the pull request. The CI/CD team will review the failures and weigh up the options on progressing the pull request. Dispensation may not always be granted, but this will be a discussion between the pull request collaborators and the CI/CD team.
The Check-Installer pipeline answers the question of:
+
+
If this pull request is merged to develop or main, could we build a deployable installer from it?
+
+
This checks all of the repositories included within the BHoM_Installer against the branch of the pull request of the toolkit being checked, and ensures all repositories included within the installer are built successfully. Any problems are then identified early and able to be handled appropriately.
+
If any part of the installer fails to build successfully then a failed check will be returned to the pull request.
+
For BHoMBot, if you have dependant pull requests linked as part of a series, running the check on one pull request will trigger a check result (success or failure depending on the outcome) to all pull requests in the series, as they will have all been tested when requested.
+
+
Trigger commands:
+
BHoMBot
+
+
@BHoMBot check installer
+
+
+
Arguments
+
-quick - if this flag is provided, then only the code changed by the pull request and its immediate dependencies (upstream) will be compiled. If not provided, the default of compiling all the code in the installer will be used instead.
This check will confirm the changes proposed by the pull request do not negatively impact the results of Null Handling tests.
+
The check will clone the repository associated to the pull request, and its dependencies listed within the dependencies.txt file, and compile all of them to get the relevant DLLs. Once the DLLs are generated, the Null Handling test will generate against the master branches of those repositories. Following that result, the DLLs will be regenerated against the branch of the pull request and generate a second result to compare with.
+
If the two results come back equal (i.e. there is no change to Null Handling presented by your pull request) then this will report back as a pass.
+
If the errors of your branch report less Null Handling errors than the master result, AND any errors in your branch report exist on the master result, this will be deemed to be an improvement and will report back as a pass.
+
If the errors of your branch are less than those of the master result, but the errors on your branch result do not exist on the master result, this will be deemed to be a failure as your pull request(s) are resulting in new Null Handling errors.
+
If the errors of your branch are more than the errors of the master result then this is also deemed to be a failure as your pull request(s) are increasing the number of Null Handling errors.
This check will confirm the csproj files changed within a pull request are compliant to the guidelines for project files.
+
If the check is unsuccessful, you can trigger BHoMBot to make the fixes for you. This can be accessed by viewing the details of the check and clicking the Fix button to trigger the process on the pull request.
This check will confirm the pull request is ready to merge based on the following conditions.
+
+
Any requested changes have been addressed (changed to an approving review) or dismissed
+
The pull request does not have a status:do-not-merge label
+
The pull request has suitable labels for the change log - labels should be starting with type: to denote the type of pull request
+
The pull request has at least one approving review
+
The pull request has passed check-core and check-installer from BHoMBot
+
+
This check is done for all pull requests that are linked in a series. If any of the pull requests are not ready, then the check will report that none of them are ready. This is to protect against merging pull requests in a series that may be dependent on each other accidently, where one pull request is ready to merge but another is not. This protects the installer builds (where check-installer reports a pass to all pull requests because the changes are ok, but if one of the pull requests then isn't merged it will fail to build the installer later) as well.
This check will trigger all required checks available to BHoMBot to be queued for the pull request. BHoMBot will confirm what required checks are being triggered when the command is run.
This check will confirm the changes proposed by the pull request do not negatively impact the results of serialisation tests.
+
The check will clone the repository associated to the pull request, and its dependencies listed within the dependencies.txt file, and compile all of them to get the relevant DLLs. Once the DLLs are generated, the serialisation test will generate against the master branches of those repositories. Following that result, the DLLs will be regenerated against the branch of the pull request and generate a second result to compare with.
+
If the two results come back equal (i.e. there is no change to serialisation presented by your pull request) then this will report back as a pass.
+
If the errors of your branch report less serialisation errors than the master result, AND any errors in your branch report exist on the master result, this will be deemed to be an improvement and will report back as a pass.
+
If the errors of your branch are less than those of the master result, but the errors on your branch result do not exist on the master result, this will be deemed to be a failure as your pull request(s) are resulting in new serialisation errors.
+
If the errors of your branch are more than the errors of the master result then this is also deemed to be a failure as your pull request(s) are increasing the number of serialisation errors.
This check will confirm the unit tests set up within a .ci/Datasets folder on a repository run successfully using the Unit Test framework.
+
The check will clone the repository associated to the pull request, and its dependencies listed within the dependencies.txt file, and compile all of them to get the relevant DLLs. Once the DLLs are generated, the unit tests will then run and compare the serialised results against the results coming out from the pull request.
+
The result of a unit test check may require further investigation and interpretation by a human reviewer.
+
If the check passes, then the unit tests serialised and the results from the pull request match exactly.
+
If the check fails, then it means the check found differences between the serialised results, and the new results. This is where investigation may be needed, as some differences may be failures (where the pull request is negatively impacting the result), but some differences may be improvements (where the pull request is making outcomes better compared to the serialised results which are made against a version of master that the toolkit leads are happy with).
+
If the check fails, but is providing better results and a human review agrees that the pull request is improving the standard, then it is recommended to update the unit tests against master after merging the pull request as soon as possible to ensure that version of results are stored for future pull requests. Unit tests can be updated on the pull request itself if agreed by the toolkit lead.
This check will confirm the changes proposed by the pull request do not negatively impact the results of versioning tests.
+
The check will clone all the repositories in the BHoM_Installer and compile all of them to get the relevant DLLs. Once the DLLs are generated, the versioning test will generate against the master branches of those repositories. Following that result, the DLLs will be regenerated against the branch of the pull request and generate a second result to compare with.
+
If the two results come back equal (i.e. there is no change to versioning presented by your pull request) then this will report back as a pass.
+
If the errors of your branch report less versioning errors than the master result, AND any errors in your branch report exist on the master result, this will be deemed to be an improvement and will report back as a pass.
+
If the errors of your branch are less than those of the master result, but the errors on your branch result do not exist on the master result, this will be deemed to be a failure as your pull request(s) are resulting in new versioning errors.
+
If the errors of your branch are more than the errors of the master result then this is also deemed to be a failure as your pull request(s) are increasing the number of versioning errors.
+
+
Trigger commands:
+
BHoMBot
+
+
@BHoMBot check versioning
+
+
+
Arguments
+
-force - if provided, this will force the versioning check to run even if it could be bypassed. If no .cs files have been changed by the pull request, it will bypass the versioning check to save time (as only changes to .cs files typically introduce versioning issues). Use this flag to force versioning to be checked regardless of whether .cs files have changed.
+
-quick - if provided, this will only compile the code in the request pull request and any immediate upstream dependencies. Without this flag, all the code in the installer is compiled to then check versioning against.
This section is only valid for projects utilising the old-style CSProject files, where an AssemblyInfo.cs file is present. If an AssemblyInfo.cs file is not present, then the compliance of this information can be found here.
+
Each DLL should have suitable assembly information to support automated processes and confirming the version of the code which the DLL was built against. This includes these three items:
+
+
<AssemblyVersion>
+
<AssemblyFileVersion>
+
<AssemblyDescription>
+
+
The AssemblyVersion should be set to the major version for the annual development cycle. This is set by DevOps, and will typically be a 4-digit number where the first number is the major version for the year, followed by three 0's - e.g. 5.0.0.0 for the 2022 development calendar (note, development calendars are based on release schedules as outlined by DevOps, not any other calendar system).
+
The AssemblyFileVersion should be set to the current development milestone, which is the major version followed by the milestone, followed by two 0's - e.g. 5.3.0.0 for the development milestone running from June-September 2022.
+
The AssemblyDescription attribute should contain the full link to the repository where the DLL is stored, e.g. https://github.com/BHoM/Test_Toolkit for DLLs where the code resides in Test_Toolkit.
+
At the start of each milestone, BHoMBot will automatically uptick the AssemblyVersion and AssemblyFileVersion as appropriate, and set the AssemblyDescription if it was not previously set. However, if you add a new project during a milestone, BHoMBot will flag these items as incompliant if they have not been resolved prior to running the project-compliance check. These items can be fixed by BHoMBot if you request BHoMBot to fix the project information.
The AttributeHasEndingPunctuation check ensures that an attribute providing documentation (input, descriptionoutput or multioutput) ends with a suitable piece of punctuation. See the check method for the current accepted list.
+
This check is useful for helping provide delineation between the documentation you provide as the developer, and the documentation provided automatically on components within the UI.
The EngineClassMatchesFilePath check looks at whether the the class of the engine method matches based on its file path.
+
For example, Compute class files should sit within the file path Your_Toolkit/Toolkit_Engine/Compute and not within Your_Toolkit/Toolkit_Engine/Query. This check ensures the class name is correct based on the file name.
+
Files contained within an Engines Objects folder are exempt from this check (e.g. files with the file path Your_Toolkit/Toolkit_Engine/Objects/Foo.cs will be exempt).
The HasDescriptionAttribute check ensures that a method has a Description attribute explaining what the method is doing for users.
+
You can add a Description attribute with the following syntax sitting above the method:
+
[Description("Your description here")]
+
If you have not used any attributes in your file previously, you may need to add the following usings:
+
using BH.oM.Base.Attributes;
+
using System.ComponentModel;
+
+
Description authoring guidelines
+
We should be aiming for all properties, objects and methods to have a description. With only the very simplest of self explanatory properties to not require a description by exception - and indeed only where the below guidelines can not be reasonably satisfied.
+
So what makes a good description?
+
+
A description must impart additional useful information beyond the property name, object and namespace.
+
Further to a definition, the description is an opportunity to include usage guidance, tips or additional context.
+
The description is a place you can include synonyms etc. to help clarify for others in different regions/domains, being inclusive as possible.
+
Also don't forget the addition of a Quantity Attribute can be used now, appropriate for Doubles and Vectors.
The HasOneConstructor check ensures that all BHoM objects that do have a constructor (and are allowed to do so by implementing the IImmutable interface) only contains one constructor with parameters.
+
Objects which implement a constructor are permitted to also implement a parameterless constructor, but only if this is necessary.
+
Objects which implement more than one constructor taking parameters will be flagged as failing this check.
+
More information
+
More information on the use of IImmutable interface within the BHoM can be found here.
The HasPublicGet check ensures that object properties have public get accessors. A property of a BHoM object which does not have a public get accessor will fail this check.
+
For example, the following object definition will fail this check, because the get accessor does not exist.
+
public double MyDouble { set; }
+
This property will pass as a compliant property.
+
public double MyDouble { get; set; } = 0.0
+
This check is only operating on oM based objects. Objects within an Objects folder of an Engine (Engine/Objects) or Adapters are exempt from this check.
The HasSingleClass check ensures there is only one class declaration per cs file. This is designed to make the code easy to find and understand by people coming into BHoM for the first time.
+
For example, a class which looks like the below, would be invalid and fail this check. There should only be one class declaration per file.
+
namesapce BH.Engine.Test
+{
+ public static partial class Query
+ {
+ }
+
+ public static partial class Compute
+ {
+ }
+}
+
The HasUniqueMultiOutputAttributes check ensures that a method returning a type of Output<t, ..., tn> has a matching number of MultiOutput attributes that have unique indexes.
+
For example, a method returning Output<Panel, Opening> would require 2 uniquely indexed MultiOutput attributes to document both the Panel and the Opening.
+
If the method looked like the below, while containing 2 MultiOutput attributes, would fail this check, because the index for both outputs cannot be 0.
The HasUniqueOutputAttribute check ensures that there is only one Output or MultiOutput attribute per method. This is to avoid confusion caused by multiple Output or MultiOutput attributes unnecessarily.
The HasValidConstructor check ensures that any BHoM object which implements a constructor with parameters contains all of the parameters it requires to satisfy the Serialisation requirement.
+
Constructors should only exist on objects implementing the IImmutable interface. Objects with this interface should have properties which are get only (no set accessor). All of these get only properties should be parameters to the constructor, with the parameter name matching the property name following the usual lowercase conventions for parameter names.
+
Consider the following IImmutable object, which does not have a constructor.
+
public class MyObject : BHoMObject, IImmutable
+{
+ public virtual int MyInt { get; }
+ public virtual string MyString { get; }
+ public virtual Point MyPoint { get; set; }
+}
+
+
This object will not correctly deserialise, as it will not be able to adequately set the properties MyInt and MyString. Therefore, a constructor must be provided with the parameter names matching, so the deserialisation can correctly align the deserialised data to the object property.
+
The property MyPoint does not have to be a parameter to the constructor, as it implements a set accessor. This is true for any property, including those inherited from the base BHoMObject.
+
As such, a valid constructor would look like this:
The entire class, in its valid form, would look like this:
+
public class MyObject : BHoMObject, IImmutable
+{
+ public virtual int MyInt { get; }
+ public virtual string MyString { get; }
+ public virtual Point MyPoint { get; set; }
+
+ public MyObject(int myInt, string myString)
+ {
+ //Constructor logic
+ }
+}
+
+
Example of an invalid object
+
If the constructor does not contain input parameters for all of the properties which implement only the get accessor, this will flag as a failure under this check. The following object is therefore incompliant, as only MyInt has a matching input parameter:
+
public class MyObject : BHoMObject, IImmutable
+{
+ public virtual int MyInt { get; }
+ public virtual string MyString { get; }
+ public virtual Point MyPoint { get; set; }
+
+ public MyObject(int myInt)
+ {
+ //Constructor logic
+ }
+}
+
+
More information
+
More information on the use of IImmutable interface within the BHoM can be found here.
The HasValidMultiOutputAttributes check ensures that a method returning a type of Output<t, ..., tn> has a matching number of MultiOutput attributes documenting the returned objects.
+
For example, a method returning Output<Panel, Opening> would require 2 MultiOutput attributes to document both the Panel and the Opening.
The HasValidOutputAttribute check ensures that, if there is a piece of Output documentation is present on a method, that it is of a correct type.
+
MultiOutput documentation should only be used on methods providing multiple outputs using the return type of Output<t1, t2, ..., tn>, while Output documentation should be present on methods returning a single type.
+
For example, the following two methods will fail this check because the documentation does not match the return types.
These methods fail this check because the MultiOutput documentation is on a method returning a single type, while the Output documentation is on a method returning multiple results. For these methods to pass this check, they should look like this:
The HasValidPreviousVersionAttribute check ensures that, if there is a piece of versioning documentation present explaining what the previous version of a method or constructor was, the FromVersion is correct.
+
The FromVersion for a PreviousVersion attribute should be set to the current milestone of development, with PreviousVersion attributes being removed at the end of the milestone in preparation for the next.
+
If a PreviousVersion attribute has not been tidied up, it will be flagged by this check and should be removed in the Pull Request which captures it.
+
If a PreviousVersion attribute has been added in that Pull Request, the FromVersion should match the current development milestone cycle.
This check ensures that if you have set any Input attributes to have UIExposure.Hidden, they are the last parameters in the list of the method.
+
This is because inputs which are being hidden from the UI are likely to be of a lower priority than those being displayed, and should not get higher precedence in the method signature, particularly when displaying the method to users.
+
This is however just a warning, and final say will rest with the relevant maintainers of the repository.
+
An example of the check failing is given below.
+
[Input("environmentObject", "Any object implementing the IEnvironmentObject interface that can have its tilt queried.")]
+[Input("distanceTolerance", "Distance tolerance for calculating discontinuity points, default is set to BH.oM.Geometry.Tolerance.Distance.", UIExposure.Hidden)]
+[Input("angleTolerance", "Angle tolerance for calculating discontinuity points, default is set to the value defined by BH.oM.Geometry.Tolerance.Angle.")]
+public static double SomeMethod(this IEnvironmentObject environmentObject, double distanceTolerance = BH.oM.Geometry.Tolerance.Distance, double angleTolerance = BH.oM.Geometry.Tolerance.Angle)
+{
+ return 0.0;
+}
+
+
In this example, the second Input attribute for distanceTolerance is setting the UIExposure to be Hidden, but the third method parameter, angleTolerance, does not have the same UIExposure (the default being Display). This would flag with this compliance check.
+
To correct this, we can either set angleTolerance to also have a UIExposure.Hidden, or change the tolerances around so that angleTolerance comes before distanceTolerance in the argument list.
The InputAttributesAreInOrder check ensures that any Input or InputFromProperty attributes are in the same order as the input parameters for the given method.
+
This ensures that our documentation is easy to follow for developets.
+
For example, the following methods would fail this check because the input attribute not in the same order as the method input parameters.
+
[Input("hello", "My variable")]
+[Input("goodbye", "Also my variable")]
+public static void HelloWorld(int goodbye, double hello)
+{
+
+}
+
The IsDocumentationURLValid check ensures that, if there is a documentation URL attribute on the code, that the URL provided can link to a valid web resource.
+
If the check cannot load the URL (returning anything other than a 200 HTTP status code), this will return a fail. If the server is unavailable then this will return a fail and the check may need rerunning if external server availability affects the check.
+
This check does not check the validity of the resource, only that the link provided can be used to access a valid web resource.
The IsExtensionMethod check makes sure that an engine method within a query, modify, or convert class is classed as an extension method to the first object type. Extension methods are made by using the this keyword prior to the declaration of the first input parameter. If a method does not take any inputs to operate, then it is exempt from this check.
+
For example, the following method declaration will fail this check, because it is missing the this keyword before the first object:
Methods within the Compute and Create classes are exempt from this check.
+
Files contained within an Engines Objects folder are exempt from this check (e.g. files with the file path Your_Toolkit/Toolkit_Engine/Objects/Foo.cs will be exempt).
The IsInputAttributePresent check ensures that an input parameter has a matching Input or InputFromProperty attribute explaining what the input is required for users.
+
You can add an Input attribute with the following syntax sitting above the method:
+
[Input("variableName", "Your description here")]
+
Alternatively, if the methods returning object has a property which contains a description which matches the input parameter, you can use the InputFromProperty attribute with the following syntax:
+
[InputFromProperty("variableName")]
+
Or, if your methods returning object has a property which contains a description which matches the input parameter, but the variable name entering the method is not named the same as the object's property, you can use the InputFromProperty to match the two, like so:
Files contained within an Engines Objects folder are exempt from this check (e.g. files with the file path Your_Toolkit/Toolkit_Engine/Objects/Foo.cs will be exempt).
The IsPublicProperty check ensures that object properties are public using the public modifier.
+
The follow object property would fail this check because the modifier is set to private.
+
private double MyDouble { get; set; } = 0.1;
+
All BHoM object properties should be publicly accessible.
+
This check is only operating on oM based objects. Objects within an Objects folder of an Engine (Engine/Objects) or Adapters are exempt from this check.
The IsStaticClass check ensures class declarations contain the static modifier.
+
The following class declaration would fail because it does not give the static modifier.
+
namespace BH.Engine.Test
+{
+ public partial class Query
+ {
+ }
+}
+
+
Files contained within an Engines Objects folder are exempt from this check (e.g. files with the file path Your_Toolkit/Toolkit_Engine/Objects/Foo.cs will be exempt).
The IsUsingCustomData check highlights whether code written within the BHoM is utilising in any capacity the CustomData variable associated with all BHoMObjects.
+
CustomData is available for volatile data, useful for users within a Visual Programming environment to append data to an object that the object can carry around. However, this data is not designed to be relied upon within the code of toolkits or engines themselves.
+
The use of Fragments is preferred for storing data being pulled from an external source, and would be the most appropriate replacement for CustomData in most instances of the code base. Some exceptions to this do occur however, and are treated on a case-by-case basis by the governance and CI/CD teams. It is advised to avoid using CustomData where ever possible in the first instance.
+
More information on the reasons behind this can be found on this issue documenting the discussion behind this.
The IsValidConvertMethodName check ensures that Convert class methods are named correctly based on the guidance for BHoM development.
+
The guidance, at the time of writing, states that Convert methods should go To their external software, and From their external software, rather than ToBHoM or FromBHoM.
+
For example, this Convert method will fail:
+
public static Span ToBHoM()
+
While this one will pass:
+
public static Span ToSoftware()
+
Naming conventions
+
Although not a strict requirement, it is advised that convert method names reflect the software that the convert is going to or from. This helps make it clear what the external object model is and helps inform users of what to expect when using the convert method.
A create method name should meet the following conditions:
+
+
If the return type matches the method name, the method name must match the filename and sit within the create folder (without any subfolders)
+
e.g. a Panel object can sit within a file with the structure Engine/Create/Panel.cs in a method called Panel
+
+
If the above cannot be done, then:
+ - A sub-folder should be created which matches the return type, the method name must match the file name, and the method name should partially match the return type
+ - e.g. a Panel object can sit within a file with the structure Engine/Create/Panel/EnvironmentPanel.cs in a method called EnvironmentPanel
+ - A level of grouping/nesting is permitted when using the second option to help group create methods appropriately. This nesting is permitted up to two levels before it would become incompliant with the guidelines.
+ - e.g. a Panel object can fit within a file with the structure Engine/Create/PlanarPanels/Panel/EnvironmentPanel.cs or Engine/Create/Panel/PlanarPanels/EnvironmentPanel.cs - here we group the panels by PlanarPanels. Either option is compliant for the check to pass. Any further folders would however be incompliant.
Datasets should be stored as valid BHoM JSON objects within a Dataset folder of a repository/toolkit. Dataset files should contain only one serialised dataset object (from BH.oM.Data.Library.Dataset ).
+
This test will take the JSON file and attempt to deserialise it back to a Dataset object. If the deserialisation fails, the error will be reported.
+
Warnings
+
The check will also interrogate the source information for the dataset and ensure:
+
+
That source information exists
+
That an author has been provided for the source
+
That a title has been provided for the source
+
+
If any of these conditions is not met, a warning will be returned. A warning will not prohibit the Pull Request from being merged, but it may be prudent to address the issues to provide confidence in the source of the dataset.
The IsValidEngineClassName check ensures that any engine class is one of either Create, Compute, Convert, Modify, Query. Any engine file which does not create one of these classes will fail this check.
+
Classes within the Objects folder of engines are not checked against this criteria.
The IsVirtualProperty check ensures that object properties are using the virtual modifier.
+
The follow object property would fail this check because the virtual modifier does not exist.
+
public double MyDouble { get; set; } = 0.1;
+
This property would pass this check because the virtual modifier has been set.
+
public virtual MyDouble { get; set;} = 0.1;
+
All BHoM object properties should be virtual to allow for easy extension.
+
This check is only operating on oM based objects. Objects within an Objects folder of an Engine (Engine/Objects) or Adapters are exempt from this check.
The MethodNameContainsFileName check ensures that method names within Engine files (with the exception of Create methods) at least partially match the file name.
+
For example, a method BHoMTypeList() can exist inside a file TypeList.cs, because the method name contains the file name. However, BHoMTypeCollection() would not be valid as TypeList.cs is not contained within the method name.
The ModifyReturnsDifferentType check ensures that Modify methods return either void or a different type to the first input. Methods returning void will be returning the first input parameter, modified by the method, to the user in a visual programming environment. Further information is available here and here.
+
For example, the following method would fail because the return type is the same as the first input.
+
public static Panel AddOpenings(this Panel panel)
+
Whereas this method will pass because the return type is different from the input type.
+
public static Opening AddOpenings(this Panel panel)
+
And this method will pass because its return type is void and will return the first input object to the user in a visual programming environment.
The ModifyReturnsSameType check ensures that Modify methods return the same type as the first input. This ensures that the modify methods are giving users back the same object type they're putting in.
+
For example, the following method would fail because the return type is not the same as the first input.
+
public static Opening AddOpenings(this Panel panel)
+
Whereas this method will pass because the return type matches the input type.
The ObjectNameMatchesFileName check ensures that object names match the file names provided. This check is for object classes only within an oM. This ensures that objects and code files match 1:1 for people looking for object definitions within oM projects.
The PreviousInputNamesAttributeHasMatchingParameter check ensures that a given PreviousInputNames attribute has a matching input parameter on a method.
+
This ensures that our documentation is accurate and valid for what users might see.
+
For example, the following method would fail this check because the input attribute does not match a given input parameter.
In order to aid people working on BHoM repositories across multiple platforms, and to avoid conflict between BHoM DLLs, project references to other BHoM repositories (for example, the Environment_oM from BHoM itself, or the Environment_Engine from BHoM_Engine) need to be set to a certain path.
+
This path should be to the ProgramData folder in the default drive of the machine. BHoM installs to the location :/ProgramData/BHoM folder, and all project files inside a toolkit have a postbuild event (see below) to copy their DLLs to the :/ProgramData/BHoM/Assemblies folder. By referencing DLLs in this location, it means people can install BHoM using an installer, clone a toolkit and begin developing without needing to clone and build the dependencies.
+
Therefore, DLL references should be set to:
+
$(ProgramData)/BHoM/Assemblies/TheDLL.dll
+
For example, if we want to reference Environment_oM from BHoM, our project reference should look like:
+
$(ProgramData)/BHoM/Assemblies/Environment_oM.dll
+
If the project reference is set to a copy of the Environment_oM DLL from another location, there is a risk that the DLL will be out of date to the main and you could therefore be building on top of an out of date framework.
+
If the project reference is not set to the example above, then this check will highlight that, and provide a suggestion of the path the DLL reference should have.
+
Exemptions
+
References to DLLs within your own solution file should be made as Project References, rather than as DLL references.
+
Copy Local
+
In order to prevent duplicate DLLs, some of which may be out of date, being placed in your repositories Build folder, and risk ending up in your Assesmblies folder run building BHoM_UI, the copy local property for all BHoM references should be set to false.
+
This check will also ensure this and flag any DLLs which do not have their copy local property set to false.
+
Exemptions
+
References can be set to copy local true if the project file is within the .ci/unit-tests folder path. DLLs referenced for NUnit unit tests require the DLLs to be copied locally and so this is valid.
+
Specific Version
+
In order to prevent DLLs being locked to specific versions, some of which may be out of date, the specific version property for all BHoM references should be set to false.
+
This check will also ensure this and flag any DLLs which do not have their specific version property set to false.
+
Build Folder
+
In order to facilitate the above, a projects output folder should be set to ..\Build\ to put all DLLs from your solution file in the correct folder. The Build folder is where the BHoM_UI looks to take DLLs for the install process when building locally.
+
This check will ensure that all build configurations (including Debug and Release) have their output folder path set to ..\Build\ and flag any instances where this is not correct.
+
Assembly Information
+
This section is only valid for projects utilising the new-style CSProject files, where an AssemblyInfo.cs file is not present. If an AssemblyInfo.cs file is present, then the compliance of this information can be found here.
+
Each DLL should have suitable assembly information to support automated processes and confirming the version of the code which the DLL was built against. This includes these three items:
+
+
<AssemblyVersion>
+
<FileVersion>
+
<Description>
+
+
The AssemblyVersion should be set to the major version for the annual development cycle. This is set by DevOps, and will typically be a 4-digit number where the first number is the major version for the year, followed by three 0's - e.g. 5.0.0.0 for the 2022 development calendar (note, development calendars are based on release schedules as outlined by DevOps, not any other calendar system).
+
The FileVersion should be set to the current development milestone, which is the major version followed by the milestone, followed by two 0's - e.g. 5.3.0.0 for the development milestone running from June-September 2022.
+
The Description attribute should contain the full link to the repository where the DLL is stored, e.g. https://github.com/BHoM/Test_Toolkit for DLLs where the code resides in Test_Toolkit.
+
At the start of each milestone, BHoMBot will automatically uptick the AssemblyVersion and FileVersion as appropriate, and set the Description if it was not previously set. However, if you add a new project during a milestone, BHoMBot will flag these items as incompliant if they have not been resolved prior to running the project-compliance check. These items can be fixed by BHoMBot if you request BHoMBot to fix the project information.
+
PostBuild events
+
In order to facilitate a projects DLL being placed in the ProgramData folder for development testing, each project within a sln file must have its own postbuild event for copying its DLL to the correct location.
If your toolkit relies on external libraries to run, then the relevant project must also provide the suitable postbuild event to copy those DLLs to the ProgramData folder as well.
+
Similarly, if your toolkit has any datasets, then a suitable project within your toolkit must provide the suitable postbuild event to copy the datasets to the C:/ProgramData/BHoM/Datasets folder.
+
BHoMBot is not able to provide any automatic fixes for this compliance item, but will highlight if it detects that it is inaccurate
The PropertyAccessorsHaveNoBody check ensures that object property accessors do not have method bodies included with them.
+
For example, the following object definition will fail this check, because the get accessor has a body.
+
public double MyDouble { get { return 0.1; }; set; }
+
Whereas this property will fail because the set accessor has a body.
+
public double MyDouble { get; set { _val = value; }; }
+
This property will pass as a compliant property.
+
public double MyDouble { get; set; } = 0.0
+
This check is only operating on oM based objects. Objects within an Objects folder of an Engine (Engine/Objects) or Adapters are exempt from this check.
This check ensures that if you have set any Input attributes to have UIExposure.Hidden, they have default values for the parameters.
+
This is because inputs which are being hidden from the UI are unable to be given inputs by users, so suitable defaults must be provided if the input is to be hidden from a UI but accessible within code-use.
+
An example of the check failing is given below.
+
[Input("environmentObject", "Any object implementing the IEnvironmentObject interface that can have its tilt queried.")]
+[Input("distanceTolerance", "Distance tolerance for calculating discontinuity points, default is set to BH.oM.Geometry.Tolerance.Distance.", UIExposure.Hidden)]
+[Input("angleTolerance", "Angle tolerance for calculating discontinuity points, default is set to the value defined by BH.oM.Geometry.Tolerance.Angle.", UIExposure.Hidden)]
+public static double SomeMethod(this IEnvironmentObject environmentObject, double distanceTolerance, double angleTolerance = BH.oM.Geometry.Tolerance.Angle)
+{
+ return 0.0;
+}
+
+
In this example, the second Input for distanceTolerance does not have a default value set, while angleTolerance does.
+
To correct this, we need to give a default value to distanceTolerance, or remove the desire to have UIExposure.Hidden on the input.
Continuous Integration (CI) is the name given to the process of assisting our PR checks and resolving uncertainty in code status.
+
CI checks are built and maintained by the BHoM CI/CD team, but are operated automatically by our CI systems (including, but not limited to, AppVeyor, Azure DevOps and associated bots1).
+
The aim of CI checks is to increase confidence in our code, without unduly hindering our ability to prototype, develop, and extend the BHoM.
+
The pages within this section detail the CI checks we currently have operating, so that everyone can see how the checks are running and help ensure their PRs pass the checks.
The following flags may be provided when requesting a check to request specific behaviour from the bot when running your requested check. One or more flags may be used at any one time - for example to trigger a full, forced, versioning check, you could use the command @BHoMBot check versioning -force -full. All flags are prepended by a dash (-). To see how an argument will affect a check, see the individual check page.
+
+
+
+
Flag
+
Action
+
Example
+
+
+
+
+
-force
+
Requires a check to run even if it could be bypassed. For example, if a pull request does not change any CS or CSProj files, then the Versioning check may not run as it is time intensive. However, if you want to force the check to run, append -force to your request and it will run even if it could be bypassed.
+
@BHoMBot check versioning -force
+
+
+
-quick
+
Requests that the check run in a shortened format if available. For example, the Versioning check can opt to only compile the code in the pull request if no other repositories are depending on the work, allowing for a quicker versioning check compared to the default which will compile all the code used by the installers.
+
@BHoMBot check versioning -quick
+
+
+
+
+
Use of CI checks
+
Not all checks are required on all repositories or on all branches, depending on the lifecycle state of the repository. The table below indicates which checks are required for a given repository state.
+
+
+
+
Check
+
Prototype
+
Alpha
+
Beta (develop)
+
Beta (main)
+
+
+
+
+
Core
+
+
+
+
+
+
+
Installer
+
+
+
+
+
+
+
Project Compliance
+
+
+
+
+
+
+
Code Compliance
+
+
+
+
+
+
+
Documentation Compliance
+
+
+
+
+
+
+
Copyright Compliance
+
+
+
+
+
+
+
Dataset Compliance
+
+
+
+
+
+
+
Branch Compliance
+
+
+
+
+
+
+
Unit Tests
+
+
+
+
+
+
+
Null Handling
+
+
+
+
+
+
+
Serialisation
+
+
+
+
+
+
+
Versioning
+
+
+
+
+
+
+
Ready to Merge
+
+
+
+
+
+
+
+
1 See more notes on our approach to using and interacting with bots and automated processes as part of our Code of Conducts.
Code Compliance is the phrase used to determine how much the code written within the BHoM framework is in line with the rules/regulations/guidelines of BHoM development. The compliance rules have evolved following the initial ethos of BHoM and been carefully refined as BHoM has developed.
+
The core of the rules however remains the same - that the code should be architected in such a way to facilitate, and promote, adoption and collaboration by any engineer using the BHoM. The components they see on the UI, should reflect what they can see in the code, the code should be easy to navigate by those wishing to find information, and the style from toolkit to toolkit should be consistent. All of this allows new members of BHoM to quickly get to grips with the basics, and the ability for multiple people to work on multiple toolkits is enhanced as a result.
+
The rules, regulations, and guidelines set out in this section of the wiki are there to give us reference for writing sustainable, maintainable, and compliant code within the framework of BHoM. They are our standards by which we should all follow.
+
The compliance laid out in the following pages does undergo periodic review by the DevOps team, as styles develop, and the guidance evolves, so if you feel something isn't quite right or is unclear, please feel free to open a discussion.
+
Types of compliance
+
Compliance can be broken into the following categories.
+
+
Code Compliance - this is the compliance of code which is written within the BHoM framework
+
Documentation Compliance - this is the compliance of the documentation that aids users and wraps around code
+
Project Compliance - this is the compliance of the repository, its associated project files, and planning operations
+
+
Compliance results
+
Compliance results can form one of three outcomes.
+
+
Pass - everything is good, compliant, and meets the guidance available
+
Warning - a piece of code is not compliant, but it is deemed not to be so severe as to prevent a PR being merged, but it should be addressed as quick as possible
+
Fail - a piece of code is not compliant, and it is critical to resolve it before the PR is merged
+
+
Toolkit and Discipline Leads are responsible for deciding whether warning results are acceptable on their toolkit on a case-by-case basis.
The primary branch which forms our codebases single source of truth is the main branch across all repositories. Depending on the category of the repository, there may be protections in place for the development of code and merging to main branches. As a repository progresses through its lifecycle from prototype to beta, the level of protections change as appropriate.
+
Creating branches
+
No code should be committed directly to the main branch of any repository, all code should be produced on an independent branch and deployed to main via a Pull Request.
+
If you are using GitHub desktop, you should make sure you are on the correct default (main or develop depending on the repository state - see below) branch and refresh it to ensure you have the latest version on your machine.
+
Then create a new branch by clicking on the Current branch button and select New branch.
+
Make sure to check this page for the guidelines on when to create a branch and when not to.
+
+
You should see that your repository history has now switched to a new branch.
+
+
From there you are ready to work on your code. Any commit that you will do, will be on that new branch.
+
Branch naming convention
+
For all branches where code development is to take place, the following naming convention should be adopted.
+
RepositoryOrProjectName-#X-Description
+
where X is the issue number you are solving.
+
Both the Repository or Project name and the Issue number should refer to the base issue being solved.
+
For example, if you are working in IES Toolkit, aiming to resolve issue 99 (which fixes window placement), the branch name should be IES_Toolkit-#99-FixingWindows.
+
If you're working on a repository with multiple disciplines, such as BHoM_Engine, then you can name the branch after the specific engine you are working on. For example, if you are working in the Environment Engine, aiming to resolve issue 103 (which fixes window creation), the branch name should be Environment_Engine-#103-FixWindowCreation.
+
This branch naming convention is particularly important when producing development installers - BHoMBot will use the name of the branch to calculate where to place installer artefacts which are generated to aid in testing the Pull Request. If the branch is not named in this convention, BHoMBot will be unable to calculate this and you will lose out on CI benefits.
+
Branches in dependant repositories - MUST be named identically
+
For instance if a change in the BHoM will lead to a change needed in some sub-repositories, all of those sub-repositories **MUST get the same branch name**. This is essential for our (CI) process to correctly check changes spanning across multiple repository Pull Requests.
+
For example, if you are adding an object in BHoM, and adding a Query method for that method in BHoM_Engine, both repositories should share the same branch name, such as Environment_oM-#103-AddLightObject - this is to ensure when we run CI checks such as Installer and Versioning, the check can find both Pull Requests and run them together within the bot ecosystem.
+
Prototypes
+
Prototype repositories use only a main branch for their code development. The main branch should be protected to the level that it requires a Pull Request to merge code, however, there is no requirement on Prototype Repositories for a Pull Request to receive a review. The Pull Request can be raised and merged instantly (depending on any required CI checks) without intervention from a reviewer. Reviews are still an option for Prototype repositories should people wish to discuss changes before a merge, but they are not a requirement.
+
There is no automatic deployments of Prototype repositories - the only way for code to be utilised is for it to be built from source or the DLLs shared between users.
+
When creating a new branch for the addition of code to a Prototype repository, branch from an up to date version of the main branch.
+
Alpha State
+
Repositories deployed in an Alpha state use only a main branch for their code development. The main branch should be protected to the level that it requires a Pull Request with at least 1 approving review prior to the code being merged.
+
Once code is merged to the main branch, the code will be deployed via alpha installers and available for more general consumption via Installers. Therefore code which is deployed to main must meet certain CI criteria before being able to merge the Pull Request.
+
When creating a new branch for the addition of code to an Alpha repository, branch from an up to date version of the main branch.
+
Beta State
+
Repositories deployed in a Beta state use both a main branch and a develop branch for their code development. The develop branch is set as the default branch.
+
The main branch continues to serve as the repository's single source of truth and is the branch which is deployed via beta installers at the end of each milestone.
+
The develop branch serves as a staging ground for development of features and larger pieces of work which is deployed via alpha installers.
+
The difference here for Beta repositories is that the main branch should only be updated each milestone with code from the develop branch which has been suitable tested and reviewed and deemed to be fit for purpose for general deployment in the Beta installers available on BHoM.xyz and other platforms. Utilising a different branch for general development (develop) from the Beta deployed branch (main) grants us a degree of control over what is deployed at the end of each milestone and beta.
+
For repositories which are undergoing large portions of work, perhaps large refactors or additional features, targeting new APIs, etc., it may not be suitable to deploy that work to a Beta where the work spans across multiple milestones of development. If this work was deployed to main for Alpha testing, it would then be automatically deployed to Beta at the end of the milestone when it may not be ready. Deploying to develop for Alpha testing then allows us to choose not to deploy that to main at the end of the milestone, allowing the Beta to contain only the deployable code that is up to the adequate standards without hindering development, or requiring Pull Requests to stay open for a lengthy time and take more resource to resolve when the time is right.
+
Additionally, separating the main Beta branch from the develop Alpha branch allows us to patch the Beta for critical bugs during a milestone of development, enabling the release of curated, up to standard code that resolves a specific bug without also deploying code which may be under ongoing development.
+
All Pull Requests for Beta repositories should aim to merge into the develop branch unless authorised by DevOps to merge into the main branch to perform a Beta Patch.
+
When creating a new branch for the addition of code to a Beta repository, you should branch from the branch where the code aims to end up. For example, if you are developing a new feature which will merge into the develop branch, then you must branch from an up to date version of the develop branch. However, if you are providing a bug fix for a Beta Patch, which aims to merge directly into the main branch, then you must branch from an up to date version of the main branch.
+
Branch Protections
+
This table gives an overview of the protections required for each individual type of repository.
+
+
+
+
Protection Setting
+
Prototype
+
Alpha
+
Beta (develop)
+
Beta (main)
+
+
+
+
+
Require a Pull Request before Merging
+
+
+
+
+
+
+
Require Approvals
+
+
+
+
+
+
+
Minimum Number of Approvals
+
N/A
+
1
+
1
+
1
+
+
+
Dismiss stale pull request approvals when new commits are pushed
+
+
+
+
+
+
+
Require review from Code Owners
+
+
+
+
+
+
+
Restrict who can dismiss pull request reviews
+
+
+
+
+
+
+
Allow specified actors to bypass required pull requests
A stale branch is defined as a branch of code which has not had any commit activity in 6 months or longer from the date of the last commit or any discussion via a pull request (regardless of state) in those 6 months. Branches that are deemed to have gone stale may be subject to deletion during repository clean ups that occur during a milestone alongside pull request closures and other spring-cleaning tasks which help keep the code base clean from too much noise.
+
If a branch is required for ongoing work, but does not have a pull request associated to it and has not had commit actiivty within 6 months, may be eligible to remain available if good reason can be provided for doing so. Good reason can be provided via an issue, or reaching out to the DevOps team directly.
Since multiple people may be working on the codebase at the same time please remain aware of other branches on the same repository and keep an eye out for potential conflicts between them, this is especially true of open Pull Requests. If there are changes on parallel branches, and especially ones you know will cause conflicts, there is no substitute to reaching out to the author(s) of those changes and discussing the intent and goals behind yours and theirs and aligning the best way to resolve them. You may find that one of you may be making a change that will actually make the other's goals easier to achieve or even unnecessary and save some work. Someone pausing development may be the best resolution in some cases, in others continuing and dealing with the conflicts later may be, and in others there could be refactoring work that could be done now to save this effort being necessary.
+
Be sure to regularly fetch and check that your branch integrates cleanly with master, if it does not please rectify these conflicts on your branch.
+
Core Contributors are expected to resolve conflicts on their PRs in order to have their PR accepted and merged. Maintainers should expect to assist external contributors with this process or otherwise handle them at merge time. Also see GitHub's about merge conflicts page
+
Never Work on the Same Files
+
The challenge is therefore to make sure that we never have two people modifying the same files in two separate branches. While it is easy to be aware which code file you are modifying, it is very important to understand that there are a few files maintained by Visual Studio that can also be the source of clashes:
+
+
Solution file: This file is modified every time a project is added for example. This means we can never have two people creating a new project in two different branches. If you know you will have to do that, you have to block the entire repository for the duration of your sprint. To block a repo, make sure your issue and card on the SCRUM board follow the naming convention of a repo-level issue.
+
Project file: This file is modified every time you add a file to the project. This happens a lot since you create a file every time you create a new section of code. It will also be modified if you move a file. Because of this, two people are never allowed to work on the same project at the same time. To block the project, make sure your issue and card on the SCRUM board follow the naming convention of a project-level issue.
+
+
FAQ
+
I have to make changes across multiple projects at the same time, what do I do?
+
If it is only two projects, you can simply name your issue and branch with the two project names instead of just one. If this is more than that, you will have to block the entire repository. In that situation, it is frequent that unplanned changes will have to be made in other projects anyway so it is safer to block the whole repository.
+
I am not sure if my code will be limited to a single project. There might be ripple effects. What do I do?
+
In doubt, it is safer to block the whole repository. It is very annoying for everyone else though so only do it if it is clear the side effect of your changes cannot be dealt with in a separate issue/PR. Also make sure you keep your sprint as short as possible so you limit the time you are blocking everyone. One thing to consider is to work only locally until you know for sure the effect your code has so you can create the branch accordingly.
+
My issue is super urgent but someone else is already blocking the project/repository.
+
You can always work locally. Just don't create a branch yet and solve the problem on your machine. Contact the other person blocking you to coordinate. As soon as his/her PR is merged, you can pull the latest changes on your machine and create your pull request.
+
I am creating a branch that will never be merged. Is there a solution for that?
+
Yes, you can use this naming convention instead: NeverMerge-IssueX-Description. As you can see, we have replaced the project or repository name with NeverMerge. This is a very rare case though since 99.9% of the code should be meant to be merged.
Merge teams are set up to deploy code to protected branches (main or develop in most cases) following a successful Pull Request review process.
+
Merge teams are managed by DevOps, and inclusion or exclusion from a team may occur at any time.
+
Merge teams will be reviewed at regular intervals to ensure they are up to date and reflective of the current development needs.
+
Creating a merge team
+
Creation of a merge team should be done when a repository is created, regardless of whether that repository requires Pull Request reviews or not. The merge team should be named the same as the repository they will be collaborators for. Discipline level teams may be created if approved by DevOps to handle multiple repositories, but this should be in addition to a specific merge team for that repository.
+
Adding people to a merge team
+
A request should be made to DevOps to add an individual to a merge team. Merging Pull Requests is a responsible action which results in code being potentially deployed via Alpha or Beta installers. As such, people who are merging Pull Requests need to be competent in discharging this duty. DevOps is responsible for determining whether an individual is competent in this role and can be added to a merge team. The decision of DevOps is final, however, individuals may make future requests to be added to merge teams and previous prohibition will not be a detrimental factor in a subsequent decision. DevOps will ask individuals to prove competency in a manner appropriate at the time of the request, but will include a review of procedures and policies to ensure the individual understands the broader development picture, as well as the associated risks of merging code.
+
Removing people from a merge team
+
Any individual can request to be removed from a merge team and DevOps will action this as soon as is appropriate without question.
+
Discipline Code Leads may request individuals to be removed from a merge team they are responsible for.
+
DevOps may remove any individual from a merge team at any time if appropriate.
+
The DevOps Merge Team
+
The DevOps merge team is a separate team to repository teams, and exists for the purpose of protecting merging to the main branch of repositories included in the Beta. Individuals will only be added to this merge team if they are part of the DevOps team.
It might happen that a Toolkit targeting a specific software will have to reference different assemblies for different versions of the software.
+
For example, this happens for ETABS_Toolkit. We will take it as an example in this page.
+
In ETABS, the various versions of the software have different API assemblies, and the assemblies have different names depending on the software version. For example: ETABS version 2016 has an API assembly named ETABS2016.dll; ETABS version 2017 has one named ETABSv17.dll.
+
For this reason, it's important to set the Build Configuration of the solution in a manner that allows the needed flexibility and maintains scalability.
+
For the sake of semplicity we will refer to this as "versioning" in this wiki page.
+
Guidelines
+
Limit the versioning to the VS Projects that need it
+
For example, ETABS_Toolkit needs to reference the software API (and therefore different versions of it) only in the project ETABS_Adapter.
+
This means that the other projects of the toolkit, namely ETABS_Engine and ETABS_oM, can avoid the problem altogether. No action should be taken on them.
+
If only one VS Project needs versioning, make sure the others projects' Build configuration target the base build.
+
You can set this in Visual Studio Build menu → Configuration Manager.
+
This means that Projects that do not need versioning – in the ETABS example the Engine and the oM – have to:
+- For "Debug-type" builds: target the baseDebug configuration;
+- For "Release-type" builds: terget the baseRelease configuration.
+
The following screenshot shows an example for "Debug-type" build:
+
+
Make sure builds are having clear separate assembly name
+
The assembly name can be set by modifying the Project's .csproj file.
+
+
More info on how to modify the .csproj
+
+This can be done by:
+
+
+
In VS, right click the project in Solution Explorer → Unload Project → right click again → edit .csproj. Edit, save, then right-click again on the project and do Reload Project.
+
+
+
OR by navigating to the project folder and editing the .csproj directly.
+
+
+
+
+
The AssemblyName has to be defined so that it reflects the build version (e.g. 2017, 2018, etc.) and to be consistent with the naming conventions adopted for the specific Toolkit.
+
See the following example for the ETABS as an example:
The BHoM framework makes use of C# Attributes to annotate and explain classes, methods and properties. Attributes used is a combination custom attributes created in the BHoM and the one provided by the core C# libraries.
+
The information provided in the attributes will be used by the UI and help control what is exposed as well as give the end user a better understanding of what your method is supposed to do.
+
To make use of the custom attributes you will need to make sure that your project has a reference to the Base_oM. You will also need to to make sure that the following usings exists in the .cs file you want to use the attributes in:
+
using BH.oM.Base.Attributes;
+using System.ComponentModel;
+
+
The attributes are described below.
+
Description
+
Only consists of a single string and can be used on a class, method or a property. Used to give a general explanation of what the class/ method or property is doing. You can only add one description to each entity. Example:
+
[Description("Calculates the counterclockwise angle between two vectors in a plane")]
+ public static double Angle(this Vector v1, Vector v2, Plane p)
+ {
+ //....code
+ }
+
+
Description authoring guidelines ✏️
+
We should be aiming for all properties, objects and methods to have a description. With only the very simplest of self explanatory properties to not require a description by exception - and indeed only where the below guidelines can not be reasonably satisfied.
+
So what makes a good description?
+
+
A description must impart additional useful information beyond the property name, object and namespace.
+
Further to a definition, the description is an opportunity to include usage guidance, tips or additional context.
+
The description is a place you can include synonyms etc. to help clarify for others in different regions/domains, being inclusive as possible.
+
Also don't forget the addition of a Quantity Attribute can be used now, appropriate for Doubles and Vectors.
+
+
DisplayText
+
Only consists of a single string and can be used on enums. Used to provide a human-friendly text version of the enum in the UI. Example:
+
public enum Market
+ {
+ Undefined,
+ [DisplayText("Europe ex UK & Ireland")]
+ Europe_ex_UKAndIreland,
+ India,
+ [DisplayText("Middle East")]
+ MiddleEast,
+ [DisplayText("Other UK & Ireland")]
+ Other_UKAndIreland,
+ ...
+ }
+
+
Input
+
Used on methods to describe the input parameters. Consists of two strings, name and description. The name need to correspond to the name of the parameter used in the method and the description is used the explain the methods purpose. Multiple input tags can be used for the same method. Examples:
+
[Input("obj", "Object to be converted")]
+ public static string ToJson(this object obj)
+ {
+ //....code
+ }
+
+
[Input("externalBoundary", "The outer boundary curve of the surface. Needs to be closed and planar")]
+ [Input("internalBoundaries", "Optional internal boundary curves descibing any openings inside the external. All internal edges need to be closed and co-planar with the external edge")]
+ public static PlanarSurface PlanarSurface(ICurve externalBoundary, List<ICurve> internalBoundaries = null)
+ {
+ //....code
+ }
+
+
Output
+
Used on methods to describe the resulting return object. Consists of two strings, name and description. The name will be used by the UIs to name the result of the method and the description will help explain the returned object. You can only add one output to each method. Example:
+
[Output("List", "Filtered list containing only objects assignable from the provided type")]
+ public static List<object> FilterByType(this IEnumerable<object> list, Type type)
+ {
+ //....code
+ }
+
+
NotImplemented
+
Used on methods that are not yet implemented. Method with this tag will not be exposed in the UIs. Example:
+
[NotImplemented]
+ public static double Length(this NurbsCurve curve)
+ {
+ throw new NotImplementedException();
+ }
+
+
PreviousVersion
+
The previous version attribute helps with code versioning of methods when a method has been changed in terms of name, namespace or input parameters. Example of how to use it see Method versioning
+
Replaced
+
Used on a method that is being replaced by another method and is to be deleted in coming versions while no automatic versioning is possible. This attribute should only be used when Versioning is impossible! This attribute will hide the method from the method tree in the UIs as long as the FromVersion property is lower or equal to the assembly file version and thereby make it impossible to create any new instances of the method. Any existing scripts will still work and reference the method. To read more about method deprecation strategy please see here.
+
The deprecated attribute has four properties:
+
+
string Description - Description as to why the method is being replaced.
+
Version FromVersion - Which version was this method replaced. Here you generally only have to specify the first two digits, for example 2.3.
+
Type ReplaceingType - Where can you find any replacing method (if it exists)
+
string ReplacingMethod - What is the name of the replacing method (if it exists)
+
+
Example:
+
[Replaced(new Version(2,3), "Replaced with CurveIntersections.", null, "CurveIntersections")]
+ public static List<Point> CurvePlanarIntersections(this Arc curve1, Circle curve2, double tolerance = Tolerance.Distance)
+ {
+ //....code
+ }
+
+
ToBeRemoved
+
Attribute only to tag a class or method that is to be removed. This attribute should only be used when Versioning is impossible! This attribute will hide the method from the method tree in the UIs as long as the FromVersion property is lower or equal to the assembly file version and thereby make it impossible to create any new instances of the method.
However, to attain a higher level of clarity and transparency, BHoM code also adheres to additional customised rules and style guidelines.
+
Additional conventions
+
BHoM code also adheres to customised rules and style guidelines. These are in place for several reasons, mainly:
+
+
to make easier to read and contribute to the codebase;
+
to ensure the functionality can be correctly exposed to the UIs;
+
to organise functionality and classes in a tidy, easy-to-find manner.
+
+
Access modifiers
+
Access modifiers specify the accessibility level of type and type members. They denote whether a type or member can be used by other code in the same assembly, and in other assemblies.
+
+
In line with BHoM's focus on clarity and transparency, we generally use the public access modifier, which allows a type or member to be accessed by any other code in the same assembly or other assembly that reference it.
+
When absolutely necessary, we use the private access modifier to limit the access of a type or member to only code in the same class.
+
Although C# provides many access modifiers, we limit our use to the two mentioned above.
+
+
Filenames, objects and methods
+
+
A .cs file can contain only 1 (one) class, and there is no concept as a Helper or Utils class.
+
For oM objects the name of the .cs file is the Name (excluding the namespace) of the Object (class), e.g. the Line class is in the Line.cs file.
+
For engine methods, a file can only contain methods whose name start or end with the name of their file file, e.g. Flip(Line line) and Flip(Arc arc) are in the same file Flip.cs, and FilterPanels and FilterOpenings can both reside inside a Filter.cs file.
+
+
Folders and namespaces
+
Namespaces and the folder structure that contains the .cs files have a close relationship. To define the correct folder structure helps keeping the relationship with the namespaces. This, in turn enables additional functionalities, such as deriving the web address of the source code of a method.
+
For a Class, an Attribute, an Enum, and an Interface, the folder structure respects the following rules:
+
+
+
If a file is in a sub folder, the namespace of the entity must follow: if Bar is in a sub folder Elements, its namespace must suffix the Elements word BH.oM.Structure.Elements.
+
+
+
An Enum must be in a separate folder Enums. Although, the namespace remains unchanged, and does not follow - i.e. Enums is appended as suffix. For example BarFEAType is in the sub folder Elements, and it is an enum. Its namespace respects A., so it contains the Elements word, but does not contain the Enum word: BH.oM.Structure.Elements. At the same time, since it is an Enum it is in an Enums folder.
+
+
+
The same rule as B. applies to:
+
+
Attribute => Attributes
+
Interface => Interfaces
+
+
Enum ordering
+
The order an Enum is written is the order in which it is displayed in the UI dropdown options. This order is therefore important to the UX of using the Enum within a workflow. The order should therefore follow one of the following conventions. There may be occasions when an Enum order does not follow the conventions below. These occasions should be clearly documented with the reasons why a different convention has been followed.
+
Alphabetical
+
The order of the Enum should be alphabetical (following British-English spelling conventions) in ascending order (i.e. A-z).
+
Caveat for Undefined
+
If your Enum option has an Undefined option to denote a default unset option, then this should go as the first option at the top of the Enum.
The order of the Enum can be in a logical order instead where this makes more sense than alphabetical. An example of such an Enum might be one that records the size of an object. In this case, the options might be:
+
ExtraSmall
+Small
+Normal
+Large
+ExtraLarge
+
+
This order for the Enum makes logical sense and provides a good UX where users will have context from the name of the Enum that the order might be different to alphabetical (e.g. the name might be UnitSize).
+
Yoda condition
+
For conditional statements, the variable expression should be placed in front of the constant expression. When this order is reversed, it is referred to as a "Yoda condition". For readability, we avoid using Yoda conditions in our code base. An example of both is given below.
+
stringstr="hello world"
+
+if(str=="BHoM"){/* … */}//most common convention - preferred for BHoM development
+
+elseif("BHoM"==str){/* … */}//Yoda style, as the constant "BHoM" precedes the string variable
+
You can record events in the Log by using
+- BH.Engine.Base.Compute.RecordError(string message)
+- BH.Engine.Base.Compute.RecordWarning(string message)
+- BH.Engine.Base.Compute.RecordNote(string message)
+
You can access all event logged since the UI was started by calling BH.Engine.Base.Query.AllEvents().
+
Dealing with errors
+
Things don't always run according to plan. Two typical situations can occur:
+- The input value your method received are invalid or insufficient to generate the output.
+- The methods you call inside your method are failing
+
In either case, you are generally left with a few choices:
+- throw an exception,
+- return a null value,
+- return a dummy value.
+
The first option stops the execution of the code completely while the other two allows things to continue but with the risk of the problem remaining unnoticed. A lot of times, none of those options are satisfactory. Let's take a simple example:
If DoSomething() throws an exception, this method will fail and pass on the exception. This might be the desired behaviour but we might also want to return all the successful results and just ignore the failing ones. In that case, we could write:
There are 3 levels of event you can record:
+- Error: RecordError()
+- Warning: RecordWarning()
+- Note: RecordNote()
+
In Grasshopper, they will look like this:
+
+
So the UI components will automatically expose all the events that occurred during their execution.
+
So when should I use each type of event?
+
Besides fatal errors, RecordError() should be used in cases when we are not able to return any result for the provided input:
+
publicstaticPointCentroid(thisPolyCurvecurve,doubletolerance)
+{
+if(!curve.IsClosed(tolerance))
+{
+Base.Compute.RecordError("Input curve is not closed. Cannot calculate centroid.");
+returnnull;
+}
+[...]
+}
+
+Note that errors most often go with returning null (or .NaN in case of doubles).
+
RecordWarning() is for all kind of situations when the result is possible to compute, but we cannot ensure if it is 100% correct. It is also suitable if provided object has been modified in not certainly desired way:
+
publicstaticVectorNormal(thisPolyCurvecurve,doubletolerance)
+{
+if(curve.IsSelfIntersecting(tolerance))
+Base.Compute.RecordWarning("Input curve is self-intersecting. Resulting normal vector might be flipped.");
+
+[...]
+}
+
+
At last RecordNote() is meant for the cases when everything run correctly but there is still some info that we would like to communicate to the end user:
+
publicoverrideList<object>Push([...])
+{
+[...]
+if(pushConfig==null)
+{
+BH.Engine.Base.Compute.RecordNote("Revit Push Config has not been specified. Default Revit Push Config is used.");
+pushConfig=newRevitPushConfig();
+}
+[...]
+}
+
+
As one can see, there is no very strict convention on when to use each level of event. However, these examples should illustrate their intended purpose.
+
Accessing All Events Since the Start
+
If you want to get the list of all the events that occurred since you started your script/program, you can use BH.Engine.Reflection.Query.AllEvents(). In Grasshopper, it will look something like this:
+
+
As you can see, events are also BHoM object that you can explode as any other typical BHoM object.
+
What About Exceptions?
+
Does that mean that we should stop using exception? No!
+
If your method ends up in a situation where it could not return any meaningful output, it should still throw an exception. Any method that catches an exception, on the other hand, should ALWAYS record something in the Log to make the user aware of what happened.
Null Handling is the practice of protecting against null inputs to methods within the engines and adapters.
+
Null inputs can throw errors that are unhelpful to the user, typically a object is not set to an instance of an object exception, which does not provide the user with much information on how to resolve this problem within their chosen UI.
+
As such, it is good practice to ensure all of the inputs to a method are valid before trying to run operations on them. Take the following method as an example.
+
public static string GetName(BH.oM.Environment.Elements.Panel panel)
+{
+ string name = "";
+ name += panel.Name + " ";
+ name += panel.Construction.Name;
+ return name;
+}
+
+
If panel is null, then the line name += panel.Name + " "; will throw a NullReferenceException as you cannot get the Name property of an object with no data associated to it (null). This may then confuse the user. Therefore, we should check whether the panel is null and tell the user before using it.
+
public static string GetName(BH.oM.Environment.Elements.Panel panel)
+{
+ if(panel == null)
+ {
+ BH.Engine.Reflection.Compute.RecordError("Panel cannot be null when querying the name. The panel should have data associated to it and be a valid instantiation of the object."); //Suitable error message that helps the user understand what's going on
+ return ""; //A suitable return - you could `return null;` here instead if needed
+ }
+
+ string name = "";
+ name += panel.Name + " ";
+ name += panel.Construction.Name;
+ return name;
+}
+
+
The return from a null check should be appropriate for the return object type. For complex objects (e.g. a BHoM object return type, such as a Panel or Bar), returning null should be appropriate, as empty objects (such as return new Panel();) will likely cause more problems down the line if the object is not null, but has no data. For primitive types (e.g. string, int) then returning a suitable default is appropriate, such as an empty string (""). For numbers (int, double, etc.), returning a number should be carefully considered. 0 may be a valid response to the method that the downstream workflow will rely on, so consider returning negative numbers (e.g. -1) instead, or numbers outside the realm of reality for the equation (such as 1e10 or -1e10 for large and small numbers respectively). The same is for bool return types, consider what true or false may imply further down the line and return the appropriate response. For collections, empty collections are appropriate.
+
The final decision for what the return should be will reside with the relevant toolkit lead, who should take into consideration the expected use cases and user stories.
+
The error message should also convey to the user which bit of the data is null and what they need to fix it. Consider the above example, the panel may not be null but the Construction property might be. Therefore panel.Construction.Name will also throw a NullReferenceException.
+
IsNull
+
For complex objects, with multiple properties to check, you may wish to implement an IsNull check query method, which takes the object and checks all of the nested data to check if any of it is null and returns a true or false and an error message if anything was null. An example of this can be seen in the Structure_Engine IsNull method which checks objects and their complex properties. This is useful for areas where the entire object must have valid data, but may not be appropriate for other instances. It is toolkit lead and developer discretion as to which way null checks should be handled in a given method.
+
Cheat Sheet
+
The following cheat sheet can be used as a guideline for what should be the default return type if a null check has failed for different types. This is not the definitive list, and many occasions may do something different with suitable justification. But if in doubt, the following can be used and would be accepted in 99 cases out of 100.
+
+
+
+
Return type
+
Return value
+
+
+
+
+
int, decimal
+
-1 or 0 - whichever is the most appropriate downstream
+
+
+
double
+
double.NaN or -1 or 0 - whichever is the most appropriate downstream
+
+
+
float
+
float.Nan or -1 or 0 - whichever is the most appropriate downstream
+
+
+
string
+
"" or null - whichever is the most appropriate downstream
+
+
+
bool
+
false or true - whichever is the most appropriate downstream (will depend on what the method is doing, e.g. a query for HasConstruction could return false appropriately because a null object cannot have a construction)
+
+
+
List or other IEnumerable
+
Empty list (new List<object>();) or null
+
+
+
Complex object (e.g. a BHoMObject such as Panel or Bar
Visual studio template files have been set up to help guide and simplify the development process of the BHoM.
+
The currently available templates are:
+
+
Toolkit Template. You can use this to create a scaffolded Visual Studio solution ready for the development of a Toolkit. It includes an Adapter, an Engine and an oM project templates.
+
Engine method templates. They make it faster to to add new Engine methods to an Engine project.
+
+
Toolkit template
+
For more guidance on how to use the Toolkit template, please see Toolkit Template.
+
Engine method templates - add them to Visual Studio
+
To get visual studio to detect the templates follow these steps:
Place the files in the visual studio templates folder. This will generally be:
+
C:\Users\ USERNAME \OneDrive\Documents\ VISUAL STUDIO VERSION \Templates\ProjectTemplates\Visual C# for any project template like the BHoM Adapter Template.
+
C:\Users\ USERNAME \OneDrive\Documents\ VISUAL STUDIO VERSION \Templates\ItemTemplates\Visual C# for any item template like Engine method templates.
+
Restart visual studio.
+
+
When you choose New Project from the visual studio menu all project templates should now show up there and when adding a new item to an existing project should now mean all the item templates should show up.
+
Known Issues
+
If template is used to add a method by right clicking on a folder, an extra the folder name will be added. This will in many cases be wrong and conflict with the class name. Issues have been raised to improve the templates further going forward. In the meantime, please check the namespace of added methods.
What does it mean when a piece of code is locked? How do I lock code?
+
A piece of code is locked when it is being developed by someone else.
+You can check if some code is locked if its related issue is mentioned in the “In Progress” or “In Review” column of the BHoM Project Board.
+
You shouldn't touch code that is locked, until the current task ends or is archived.
+If you urgently need that some new code to be pushed into the main stream - an important bug fix for example - reach out to the person assigned to the issue that is locking the code and speak to her/him.
I am using Windows 10. Is anything different for me ?
+
If you are using a computer which runs on windows 10, you might find that when you reference dlls in a project, the path of those will be pointing to your OneDrive folder. This will obviously lead to the issue that the code will not compile for other people.
+
+
If this id the case, re-referencing the dlls might not solve the issue and then you will have to manually edit that in the project folder. You do this by opening the project file (.csproj) in a text-editor and you will find some of the dlls being referenced as
+
+
which you will have to replace by
+
+
Note that the path in visual studio will still be pointing to your OneDrive, but now the referencing will not create issues for others.
+Do NOT FORGET TO COMMIT this changes!
BHoM has several ways to cover developed functionality with Tests. An automated strategy for covering possible regression (i.e. loss of functionality erroneously introduced by code changes) can be done with "Data driven tests".
+
Data driven tests are simply a way to take a "snapshot" of the input and output of a specific method. The input and output are stored in a dataset, together with the name of the method used to produce the output from the input. This data can be then used to automatically trigger the method at a later time, or periodically, to check that the method has not been broken e.g. with side-effects of other code changes elsewhere.
+
To record the test data, you simply need to run a target Engine method with some specific input data. The input data and the ouput of the method, together with the method name, will be recorded. When the data-driven test will be run, it will simply call again the method in question with the stored input data, and compare it with the output data. This way, it is possible to check that Engine methods keep behaving reliably.
To store data for tests, you can use the Test_Toolkit and the Unit Test component.
+
+
Procedure
+
+
Compile the Test_Toolkit - it contains some useful methods that are not shipped in the BHoM installer.
+
Drop a Unit Test component in a script.
+
Right click the component. Use the search field to find and select method you want to store test data for. Once done, the component Unit test will transform into a UT:MethodName component.
+ For example, if you want to test the method called BaseTypes(), type and select its name. The component will transform into a UT:BaseType component. See screenshot below.
+ This component will have as many input as the selected method. What it will do is simply run the selected method with any provided input data.
+
Produce some input test data for the method. This data is simply some objects that the method can take as an input. Don't just do random objects: think about what kind of test data an user may want to input to the test, and about particular "edge" situations you want to make sure that work. The input data should cover as many input combinations and "particular inputs" as it makes sense to, in order to have good test coverage.
+
Connect the test data to the Unit Test component. The component will execute the target method with the provided data, and it will return one or more Unit Test objects, which contain the input and outputs related to the method execution.
+
At this point, we will want to store the Unit Test objects as a json somewhere where the automation can find them, so future testing can be done automatically. Our place of choice is the .ci folder of the repository where the method being tested can be found.
+ In order to do this easily and reliably, you can use the Test_Toolkit's StoreUnitTests function. Please refer to the screenshot below.
+ The StoreUnitTests function will save the test data in the .ci folder of the repository.
BHoM allows to create tests of several types. We mainly distinguish between Unit/Functional Tests and Data-Driven Tests. This section explains in detail how to write Unit/Functional Tests for BHoM in Visual Studio. For Data-Driven Tests, please refer to their page; among other things, in this page you will also find a section dedicated to their comparison.
BHoM operates a separation between tests and functionality/object models. This is achieved by placing the tests in a different solution from the main repository solution.
+
In this page, we will make an example where we want to create tests for the Robot_Toolkit.
+
Create a new unit-tests directory
+
To add a new test solution, please create a new unit-tests folder in the Toolkit's .ci directory, e.g.:
+
+
If a .ci folder does not exist in your Toolkit yet, create that first.
+
Create a new test solution
+
You can create a new Test solution in Visual Studio from the File menu as shown below.
+
+
Search for NUnit in the search bar and select it:
+
+
Make sure that you have "create new solution" and "place solution and project in the same directory" toggled on.
+
Please name the new test solution with the same name as the main toolkit plus the suffix _Tests. For example, for Robot_Toolkit, the new test solution will be called Robot_Toolkit_Tests.
+
+
This will create a new solution with a dummy NUnit test project in it. For example, if we are setting up the Robot_Toolkit_Tests for the first time, we will end up with this:
+
+
Add the existing Toolkit projects to the Test solution
+
In order to reference the main Toolkit projects, you can add "Existing projects" to the test solution. This will allow debugging the Toolkit code while running the unit tests.
+
Right-click the solution name in the Solution Explorer and do "Add existing project":
+
+
Navigate to the Toolkit's repository and select the Toolkit's oM project, if it exists:
+
+
This will add the Toolkit's oM project to the Test solution.
+
Repeat for all the Toolkit's projects, e.g. the Engine and Adapter ones, if they exist. In the example for the Robot_Toolkit, you will end up with this:
+
+
Add a Solution Configuration for more efficient testing
+
After adding the Toolkit's existing projects to the Test solution, you can add a new "Test" Solution Configuration that can be used when running tests.
+
Doing this allows to avoid time-consuming situations, like when you need to close software that locks the centralised assemblies (e.g. Rhino Grasshopper, Excel) whenever you want to compile or run Unit Tests. This is because BHoM relies on post-Build Events to copy assemblies in the ProgramData/BHoM folder, and if a software locks them, the project cannot build successfully.
+
Go in the Configuration Manager as below:
+
+
Then select "New":
+
+
And do the following:
+
+
This will create a new Solution Configuration called "Test". Make sure it's always selected when running tests from the Test solution:
+
+
In order to get the benefits from this, we will need to edit the Post-build events of every non-test project in the Toolkit (in our example for the Robot_Toolkit, these are only 3: the Robot_oM, the Robot_Engine, and the Robot_Adapter). Let's take the example of Robot_oM. The post-build events can be accessed by right-clicking the project, selecting Properties, then looking for "Post-build Events".
+
+
The post build events should look something like this:
+
This instructs the MSBuild process to copy the compiled assembly to the BHoM central folder, from where they can be loaded by e.g. UIs like Grasshopper. We do not want this copy process to happen when we are only testing via NUnit. Therefore, we can modify the post build event by replacing it with:
+
if not "$(ConfigurationName)" == "Test" (xcopy "$(TargetDir)$(TargetFileName)" "C:\ProgramData\BHoM\Assemblies" /Y)
+
+
This means that the post-build event is going to be triggered only when the Solution Configuration is not set to "Test".
+
+
Solution Configuration
+
Make sure that the Solution Configuration is always set to "Test" when you are in the Test solution (e.g. GitHub/Robot_Toolkit/.ci/unit-tests/Robot_Toolkit_Tests.sln) and not selected when you are in the normal toolkit solution (e.g. GitHub/Robot_Toolkit/Robot_Toolkit.sln).
+
If you have followed the guide so far, this will work fine.
+
The only thing that this changes is that the DLLs are not copied in the BHoM central location if the "Test" configuration is selected: in you are developing some new functionalty and you want the change to appear in e.g. a UI like Grasshopper, you need to make sure to compile the solution with the "Debug" configuration!
+
+
Create a new a test project
+
At this point, you should have a Test solution .sln file in your Toolkit's .ci folder, e.g. something like GitHub/Robot_Toolkit/.ci/unit-tests/Robot_Toolkit_Tests.sln.
+You will now want to create a Test project where we can write tests.
+
Decide what the Test project should target
+
In order to create a new test project, you should decide what kind of functionality you will want to test there. Because BHoM functionality only resides in Engine and Adapter projects (not oM projects), we can have one test project corresponding to each Engine/Adapter project.
+
For example, say you want to write tests to verify the functionality that is contained in some Robot_Engine method, for example, Robot.Query.GetStringFromEnum(). Because this method resides in the Robot_Engine, we will need to place it into a Test project that is dedicated to testing Robot_Engine functionality.
+
We can create a new test project for this. Right-click on the Solution in the Solution Explorer and do "Add" and then "New Project":
+
+
Search for NUnit in the search bar and select it:
+
+
Because this test project will target functionality in the Robot_Engine, let's name it appropriately as Robot_Engine_Tests:
+
+
Click next and accept .NET 6.0 as the target framework, then click "Create".
+
+
We will end up with this new test project:
+
+
We can also delete the dummy test project at this point. Right-click the Robot_Toolkit_Test project and do "remove":
+
+
We end up with this situation:
+
+
Configure the default namespace for the test project
+
We want to set up the default namespace for tests included in this project. To do so, right-click the test project and go in Properties:
+
+
Type "default namespace" in the search bar at the top, then replace the text into the text box with an appropriate namespace. The convention is: start with BH.Tests., then append Engine. or Adapter. depending on what the test project tests will target; then end with the name of the software/toolkit that the project targets, for example Robot. For our example so far, we will have BH.Tests.Engine.Robot.
+
+
Adding references to a Test Project
+
Add existing project references
+
Because the test will verify some functionality placed in another project, namely the Robot_Engine, we need to add a reference to it. Right-click the project's dependencies and do "add project reference":
+
+
Then add the target project and any upstream dependency to the target project. For example, if adding an Engine project, make sure you add also the related oM project; if adding an Adapter project, add both the related Engine and oM projects.
+
+
Add other BHoM assemblies dependencies
+
Most likely you will need to reference also other assemblies in order to write unit tests. Again, right-click the project's dependencies and do "add project reference", then click on "Browse" and "Browse" again:
+
+
This will open a popup. Navigate to the central BHoM installation folder, typically C:\ProgramData\BHoM\Assemblies. Add any assembly that you may need. These will appear under the "Assemblies" section of the project's Dependencies.
+
Typically, a structural engineering Toolkit will need the following assembly references, although they will vary case by case:
+
+
Once you have added the assemblies, please select all of them as in the image above (click on the top one, then shift+click the bottom one) and then right click on one of them. Select "Properties" and under "Copy Local" make sure that "True" or "Yes" is selected:
+
+
This is required to make sure that NUnit can correctly grab the assemblies.
+
Adding extra NuGet packages
+
We can leverage some other NuGet packages to make tests simpler and nicer.
+
If you want your Unit test to be automatically invocable by CI/CD mechanisms, you should check with the DevOps lead if the NuGet packages you want to use are already supported or can be added to the CI/CD pipeline. The following packages are already supported.
+
Add FluentAssertions
+
We use the FluentAssertions NuGet package for easier testing and logging.
+Please add it by right-clicking the Project's Packages and do "Manage NuGet packages":
+
+
Click "Browse", then type "FluentAssertions" in the search bar. Select the first result and then click "Install":
+
+
We will provide some examples on how to use this library below. Please refer to the FluentAssertions documentation to see all the nice and powerful features of this library.
+
Writing tests
+
Let's image we want to write some test functionality for the Robot Query method called Robot.Query.GetStringFromEnum(). Because this method resides in the Robot_Engine, we will need to place it into the Robot_Engine_Tests project (created as explained above).
+
Because the method we want to test is a Query method, let's create a folder called Query:
+
+
Right-click the newly created Query folder and do Add new Item:
+
+
Let's call the new item as the method we want to test, e.g. GetStringFromEnum:
+
+
Let's edit the content of the generated file, so it looks like the following.
In particular, note that:
+- we added a using NUnit;, using NUnit.Framework; and using FluentAssertions; at the top;
+- we edited the name of the class appending Tests
+- We added an empty test method called as the Engine method we want to verify (GetStringFromEnum). The test method is decorated with the [Test] attribute.
+
Test sections: Arrange, Act, Assert
+
Every good test should be composed by these 3 clearly identifiable main sections (please refer to Microsoft's Unit testing best practices for more info and examples):
+
+
Arrange: any statement that defines the inputs and configurations required to do the verification;
+
Act: execute the functionality that we want to verify, given the Arrange setup;
+
Assert: statements that make sure that the result of the Act is as it should be.
+
+
The test structure should always be clear and follow this structure. Each test should only verify a specific functionality. You can have multiple assertion statements if they all concur to test the same functionality, but it can be a red flag if you have more than two or three: it often means that you should split (or parameterise) the test.
+
Your first test: a simplistic example
+
Following the example so far, we could write this code for the GetStringFromEnum() test method:
+
[Test]
+[Description("Verify that the GetStringFromEnum() method returns the correct string for a specific DesignCode_Steel enum value.")]
+publicvoidGetStringFromEnum()
+{
+// Arrange
+// Set up any input or configuration for this test method.
+varinput=oM.Adapters.Robot.DesignCode_Steel.BS5950;
+
+// Act
+// Call the target method that we want to verify with the given input.
+varresult=BH.Engine.Adapters.Robot.Query.GetStringFromEnum(input);
+
+// Assert
+// Make sure that the result of the Act is how it should be.
+result.Should().Be("BS5950");
+}
+
+
Note that we use FluentAssertions'Should().Be() method to verify that the value of the result is equal to the string BS5950, as it is supposed to be when calling the GetStringFromEnum engine method with the input DesignCode_Steel.BS5950.
+
Also note that a good practice is to add a test [Description] too! This is very helpful in case the test fails, so you get an explanation of what kind of functionality verification failed and what how it was supposed to work.
+
+
Why this is a bad example of unit test
+
This example is simplistic and shown for illustrative purposes. It's not a good unit test for several reasons:
+
+
we are not testing every possible combination of inputs to the GetStringFromEnum() engine method and related outputs.
+
it hard-codes the value BS5950. We took that value by copying it from the body of the GetStringFromEnum() method and putting it in the Assert statement. This effectively duplicates that value in two places. If the string in the engine method was modified, you would need to modify the test method too. You should avoid this kind of situation and limit yourself to verifying things variables defined as part of the "Arrange" step. If you need to verify multiple output value possibilities, you should be using a Data-Driven approach.
+
+
See below for better examples of unit tests.
+
+
Better examples of tests
+
To illustrate good unit tests, let's look at another repository, the Base BHoM_Engine. Let's look at the test in the IsNumericIntegralTypeTests class, which looks like this (edited and with additional comments for illustrative purposes):
+
namespaceBH.Tests.Engine.Base.Query
+{
+publicclassIsNumericIntegralTypeTests
+{
+[Test]
+publicvoidAreEnumsIntegral()
+{
+// Arrange. Set up the test data
+varinput=typeof(DOFType);
+
+// Act. Invoke the target engine method.
+varresult=BH.Engine.Base.Query.IsNumericIntegralType(input);
+
+// Assert. Verify that the output of the Act is how it should be.
+// If it fails the message in the string will be returned.
+result.ShouldBe(true,"By default, IsNumericIntegralType() considers enums as a numeric integral type.");
+}
+
+[Test]
+publicvoidAreIntsIntegral()
+{
+// Arrange. Set up the test data
+varinput=10.GetType();
+
+// Act. Invoke the target engine method.
+varresult=BH.Engine.Base.Query.IsNumericIntegralType(input);
+
+// Assert. Verify that the output of the Act is how it should be.
+// If it fails the message in the string will be returned.
+result.ShouldBe(true,"Integers should be recongnised as Numeric integral types.");
+}
+}
+}
+
+
As you can see, this class contains 2 tests: AreEnumsIntegral() and AreIntsIntegral(). A single test class should test the same "topic", in this case the BH.Engine.Base.Query.IsNumericIntegralType() method, but it can (and should) do so with as many tests as needed.
+The first test checks that C# Enums are recognised as integers by the method IsNumericIntegralType (they should be). The second test checks that the same method also recognises C# Integers are recognised as integers.
+
Why are these tests better examples of good unit tests than the one in the previous section?
+
+
Test should be "atomical" like this, because if something goes wrong, there is going to be a specific test telling you what did go wrong.
+
The possible outcomes are limited to True/False; it can be acceptable to "hard-code" True/False in the unit test itself. Writing result.ShouldBe(true) makes sense, as opposed to result.ShouldBe(someVerySpecificString) or result.ShouldBe(someHugeDataset).
+
+
A good idea would be to add a test that verifies that a non-integral numerical value is recognised as not an integer, for example a double like 0.15. Another test could be verifying that a non-numerical type is also recognised as not an integer, for example a string.
+
If the possible outcomes of the output data were not limited to True/False, the target method would have been better suited to be verified with a Data-driven test. However, in certain situations, like when doing Test Driven Development, it can be acceptable to write tests that verify complex output data, although it's likely that a full test coverage will only be reached with Data-driven tests.
+
For more examples of good tests, keep reading.
+
Unit tests VS Data-Driven VS Functional tests
+
Unit tests verify that a particular piece of code, generally a function, works as expected. The perspective of a unit test is often that of the developer who authored the target function and that wants to make sure it works properly.
+The power of unit tests comes by creating many of them that verify the smallest possible functionality with many different input combinations. You should always strive to write small, simple unit tests. Please refer to Microsoft's Unit testing best practices for more information and examples.
+
In some cases, as mentioned in the section above, the verification in a unit test may need to target a complex set of data. For example, you may want to test your method against a "realistic" set of object, for example, many different input objects that cannot be generated easily from the code itself, but that can be easily generated in e.g. Grasshopper. In these cases, you should rely on Data-driven testing. Data-driven testing provides for more robustness against changes, because it verifies that the target function always performs in the same way. If the test function needs to change, you will have to re-write also the expected output, and this procedure increases robustness.
+However, in certain situations, like when doing Test Driven Development (TDD), it can be acceptable and even extremely helpful to write tests that verify against complex data. For example, Functional tests may well rely on complex set of data, and it's common to write them when doing TDD. In this scenario, it's still likely that a full test coverage will only be obtainable by also doing some Data-driven testing.
+
Test that verify larger functionality are also possible, in which case we talk about Functional tests. Functional test often take the perspective of a user using a piece of software that does many things in the background, like Pushing or Pulling objects via a BHoM_Adapter (in the next section you can an example of this).
+Functional tests can be slow to execute and, when they fail, they do not always give good understanding of the possible causes for the failure, because they encompass many things. However, Functional tests can be very helpful to verify that large, complex pieces of functionality work as expected under precise conditions. They are also amazingly helpful when developing new pieces of functionality using the TDD approach.
+
In many cases, the best practice is to have a good balance of Unit, Functional and Data-driven tests. This comes with experience, just start with something and you'll get there!
+
+
unit test as an umbrella term
+
Sometimes, people use the term "unit tests" as an umbrella term for all kinds of tests.
+This is incorrect, as the only really generic umbrella term should be "test". However, it's a common misconception that it's often done in development.
+In BHoM we mistakenly perpetrate it in a couple of places:
in the name of the Data-Driven test component (which is called "unit test", but could be called "data driven test"). BHoM's data-driven tests are simply a type of unit test (equality assertion on the stored output data of a single method).
+
+
+
A Functional test example
+
Examples of Functional tests can be seen in the Robot_Adapter_Tests project. Adapter Test projects will likely contain lots of functional tests, as we care about testing complex behaviours like Push and Pull.
+
For example, see below the test PushBarsWithTagTwice() (this is slightly edited and with additional comments for illustration purposes). We test the behaviour of the Push and Pull functionality, which in the backend is composed by a very large set of function calls. The test a first set of 3 bars, then a second set of 3 bars, and all bars are pushed with the same Tag; then it verifies that the second set of bars has overridden the first set.
+
[Test]
+[Description("Tests that pushing a new set of Bars with the same push tag correctly replaces previous pushed bars and nodes with the same tag.")]
+publicvoidPushBarsWithTagTwice()
+{
+// Arrange. Create two sets of 3 bars.
+intcount=3;
+List<Bar>bars1=newList<Bar>();
+List<Bar>bars2=newList<Bar>();
+for(inti=0;i<count;i++)
+{
+bars1.Add(Engine.Base.Create.RandomObject(typeof(Bar),i)asBar);
+}
+
+for(inti=0;i<count;i++)
+{
+bars2.Add(Engine.Base.Create.RandomObject(typeof(Bar),i+count)asBar);
+}
+
+// Act. Push both the sets of bars. Note that the second set of bars is pushed with the same tag as the first set of bars.
+m_Adapter.Push(bars1,"TestTag");
+m_Adapter.Push(bars2,"TestTag");
+
+// Act. Pull the bars and the nodes.
+List<Bar>pulledBars=m_Adapter.Pull(newFilterRequest{Type=typeof(Bar)}).Cast<Bar>().ToList();
+List<Node>pulledNodes=m_Adapter.Pull(newFilterRequest{Type=typeof(Node)}).Cast<Node>().ToList();
+
+// Assert. Verify that the count of the pulled bars is only 3, meaning that the second set of bars has overridden the first set of bars.
+pulledBars.Count.ShouldBe(bars.Count,"Bars storing the tag has not been correctly replaced.");
+
+// Assert. Verify that the count of the pulled nodes is only 6, meaning that the second set of bars has overridden the first set of bars.
+pulledNodes.Count.ShouldBe(bars.Count*2,"Node storing the tag has not been correctly replaced.");
+}
+
+
Leveraging the NUnit test framework: setup and teardown
+
When writing unit tests, you should leverage the NUnit test framework and other libraries in order to write clear, simple and understandable tests.
+
You may want to define NUnit "startup" methods like [OneTimeSetup] or [Setup] in order to execute some functionality when a test starts, for example starting up an adapter connection to a software. Similarly, you can define "teardown" methods to define some functionality that must be executed when a test finishes, for example closing some adapter connection.
+
Please refer to the NUnit guide to learn how to define startup and teardown methods.
+Here, we use the OneTimeSetup method to define a behaviour that should be executed only once before the tests contained in the class PushTests are run. This behaviour is the initialization of the RobotAdapter, which is stored in a variable in the class. All tests are going to reuse the same RobotAdapter instance, avoiding things like having to re-start Robot for each and every test, which would be time-consuming.
+
All tests existing in a Test solution can be found in the Test Explorer. If you can't find the Test Explorer, use the search bar at the top and type "Test Explorer":
+
+
You can run a single test by right-clicking the test and selecting Run or Debug. If you choose "debug", you will be able to hit break points placed anywhere in the code.
+
By running tests often, you will be able to quickly develop new functionality while making sure you are not breaking any existing functionality.
+
Test Driven Development (TDD)
+
A good practice is Test Driven Development (TDD), which consists in writing tests first, and implement the functionality in the "Act" step later. You can create a stub of the implementation that does nothing, write the tests that should verify that it works fine, and then develop the functionality by adding code to the body of the stub. In other words:
+
+
Write one or, better, many tests that verify a piece of functionality. They should have Arrange, Act and Assert phases.
+
+
In the "Act" phase, just write a function call to the new function you want to define. Get inspired by the Arrange step to define the signature of the function call. Don't be bothered by the compiler complaining that the function doesn't exist!
+
[Test]
+publicvoid()
+{
+// Arrange
+varinput=someData;// data that I know I will want to use.
+
+// Act
+// DoSomething() does't exist yet!
+varoutput=BH.Engine.Something.Compute.DoSomething(input);
+
+// Assert
+output.Should().Be(expectedValue);
+}
+
+2. Write a stub for the target function:
+
publicpartialclassCompute
+{
+publicstaticobjectDoSomething(objectinput)
+{
+// You will implement this later. Don't do anything.
+returnnull;
+}
+}
+
+
+
+
Run the tests. Make sure they all fail! Add as many tests you can think of: they should describe well the functionality you want to develop.
+
+
Write the target function until all the tests pass!
+
+
Doing this allows focusing on the "what" first, and the "how" later.
+It helps to focus on the requirements and the target result that you want to achieve with the new function. In many cases, the implementation will then almost "write itself", and you will also end up with a nice collection of unit tests that can be re-run later to verify that everything keeps working (regression testing).
2022 Q1 Reflection oM Engine migration to Base oM Engine
+
+
Following the discussion in this issue and associated discussions in this issue and this issue, the Reflection oM was removed from BHoM, and significant changes made to the location of methods between Reflection_Engine and BHoM_Engine DLLs.
+
Reflection_oM has been removed entirely, while Reflection_Engine has been modified. Moving forward, Reflection_Engine will house methods which allow the code base to ask questions about itself, following the traditional route of Reflection in programming, so the engine will continue to exist, but core methods that are more commonly used for general operation of the eco-system have been migrated to the Base_Engine.
+
Pull Requests
+
To jump straight into the code changes, see these PRs:
Further changes were made to all repositories within the installer. A full list is available in the following files. These links will take you to the commit states at the time this work was done, and will highlight which repositories received the updates at the time. All repositories received the updates described in this article to ensure they could compile against the base changes, with no other changes provided during this work.
The biggest impact to repositories was via the migration of all Reflection_oM objects to the BHoM project, falling under the Base namespace. This included Attributes, Debugging, and the interfaces for MultiOutput objects.
+
The Attributes are a key part of BHoM documentation, providing Input, Output, and MultiOutput documentation attributes, as well as versioning attributes such as ToBeRemoved and PreviousVersion.
+
Prior to this work, they were housed under the namespace BH.oM.Reflection.Attributes, but this has now become BH.oM.Base.Attributes following the migration. Updating your using statements and referencing BHoM.dll rather than Reflection_oM.dll should be sufficient to resolve compilation issues here.
For anyone needing to use the Debugging objects of BHoM (such as Event), these are now housed in the BH.oM.Base.Debugging namespace. Existing uses of this should be sufficient to rename the using statement and ensure a reference to BHoM.dll rather than Reflection_oM.dll.
The Output<T> objects were housed in the top level of the Reflection_oM in the namespace BH.oM.Reflection. These have been moved to the top level of the BHoM in the namespace BH.oM.Base.
+
Anyone using Output<T, Tn> objects should find it sufficient to replace using BH.oM.Reflection; with using BH.oM.Base; and ensuring a reference to BHoM.dll rather than Reflection_oM.dll going forward.
These methods were primarily used by UIs to load DLLs appropriately into their platforms. These have moved to the Base Engine, in the BHoM_Engine.dll reference. Adding a reference to BHoM_Engine.dll and updating using statements and method calls should be sufficient.
+
The use of the name Reflect has been removed from the Base Engine to avoid confusion with the ongoing use of Reflection_Engine, and has become Extract. See this file for more information.
Another big change with the migration is the housing of methods related to the logging system within BHoM. These have been updated as above, with the same functionality as before. If your code was using the logging system, updating Reflection to Base and ensuring a reference to BHoM_Engine.dll should be sufficient.
+
Questions/Issues
+
If you encounter any problems following this migration, please reach out with discussion or issues as appropriate 😄
The two major subjects for backwards compatibility concerns methods/components and the objects/data itself.
+
Methods/Components
+
Only time these should have to break is when a parameter has been updated. This will in the long run be covered by the Version_Engine. See object name or namespace changed.
+
For all other cases the developer is responsible for ensuring that they never update public methods in a manner that can cause a script to break. Updates to methods will lead to scripts breaking if the interface of the method has been updated, which will be the case if at least one of the following is true:
+
+
Method name is changed
+
Method is moved to a different class
+
Method namespace is changed
+
Return type is changed
+
Input parameters are changed, in type, number or order
+
+
If none of the above holds true for the change being made, i.e. the change only concerns the body of the method, the change is free to do without any additional concern about versioning. (Obviously any fundamental change to the behavior of the method needs normal due care and documentation.)
+
If any of the above holds true the following process should be applied:
+
+
+
Implement the new method without removing the old.
+
+
+
Put a Deprecated tag on the old method you want to update. In the tag link over to the new method.
+
+
+
The method with the Deprecated tag can be removed when at least 2 minor releases have passed. (For example a method deprecated in version 2.2 should not be removed before version 2.4 at the earliest.)
+
+
+
Object models and serialised data
+
If an object schema is updated it will potentially lead to breaking previously serialized data and for some cases methods.
+
If the deserialisation from BSON or JSON fails, the Serialiser_Engine will fall back to deserialise any failing object to a CustomObject, containing all the data as keys in the CustomData.
+
To ensure that any old data is deserialised correctly to the updated object schema, methods in the Versioning_Engine will need to be implemented. Depending on the change made, different action needs to be taken as outlined below.
+
Object name or namespace changed
+
When a change has been made to the object name or namespace, a renaming method needs to be implemented in the Version_Engine, taking the previous full name as a string, including namespace (for example BH.oM.Structure.Element.Bar) and returning the new name as a string.
+
This will also be important when deserialising any method using the updated object as return type or input parameter.
+
Object definition changed
+
When the definition of an object has been changed, which could be:
+
+
Adding a property
+
Removing a property
+
Change name or type of a property
+
+
the object will be deserialised to a CustomObject, as outline above.
+
To ensure that the object is being correctly deserialised covering the change being made, a convert method between versions needs to be implemented in the Version_Engine, taking the CustomObject as an argument and returning a new CustomObject with properties updated to match the new object schema. The Versioning_Engine will then attempt to deserialize the updated schema to the correct object.
+
The method implemented should just cover update from one version to the next (for example 2.3 -> 2.4). This will make it possible to chain the updates when an object has gone through several changes over multiple versions.
Object name change and associated custom create method
+
In the Audience_oM I want to change the object name for ProfileParameters to TierProfileParameters. There are two Create methods that will also need to be upgraded. This page describes the steps to achieve that.
+
First I am going to set up some files and data to help with the process
+
+
Capture the JSON string of the object to change as described here.
+
+
Set up a simple file with the auto generated object create method component and related methods that the changes will impact:
+
+1. Use the VersioningKey component to get the string that will later be used for the the PreviousVersion Attribute that I will add to the affected methods.
+
+1. Copy the output of VersioningKey and paste into a text editor.
+
Change the code to change the object name
+
+
Change the object name and the file name for this object.
+
In the Engine and oM projects replace all instances of the old name with the new name.
+
+
+I'm using find and replace for the renaming - care should be taken here.
+
+
+
Check the solution builds.
+
+
Create and add the versioning JSON file to the project. See here for the content of an empty Versioning_XX.json file.
+
+
Add the key value pairs to describe the ToNew and ToOld upgrade / downgrade.
+
.
+1. At this we can rebuild the solution and rebuild the Versioning_Toolkit.
+1. First I'll check the upgrade using the json string and ToNewVersion:
+
+1. If this fails double check all the steps above.
+1. Open Rhino and the simple test file.
+1. We'll see the auto generated create method has correctly upgraded, but the others show errors:
+
+
+
+
Change the code to change the methods
+
+
I need to add the PreviousVersion attribute to ensure the methods are upgraded.
BHoM versioning provides a system to correctly load a method or component stored in a script that has had its code changed.
+
Why is Versioning needed?
+
When you save a script that contains BHoM stuff, all of the BHoM components save information about themselves so they can initialise properly when the script is re-opened. This information is about things like the component/method name, its inputs and outputs types and names; the information is simply stored in a text (Json serialised).
+
If someone changes a BHoM method or object that was stored in a script, upon reopening of the script it will be impossible to reload that same method or object: the method initialisation will fail and the old component in the script will throw a warning or error, unable to work.
+
Versioning fixes this by updating the old json text before using it to find the method.
+
What does BHoM versioning support?
+
BHoM versioning supports the following changes:
+
+
+
Changes to methods (e.g. saved in a script):
+
+
changes in the method name
+
changes in their input/outputs names and types.
+
+
+
+
Changes to Namespaces:
+
+
renaming namespaces
+
general modification to namespaces
+
+
+
+
Changes to classes (object types):
+
+
changes in class properties
+
changes in their name
+
complex structural changes
+
+
+
+
Changes to Datasets:
+
+
renaming or moving of location
+
deletion
+
+
+
+
Ok, tell me how to do versioning for my changes! 🚀
+
To implement versioning when you do your changes, see Versioning guide.
If you want to know about how the upgrader does its job, this section is for you. Otherwise, feel free to skip it.
+
How does BHoM Versioning work?
+
Alongside the dlls installed in AppData\Roaming\BHoM\Assemblies, you can find in the bin sub-folder a series of BHoMUpgrader exe programs. When a type/method/object fails to deserialise from its string representation (json), those upgrader are called to the rescue.
+
Every quarter, when we release a new beta installer, we also produce a new upgrader named BHoMUpgrader with the version number attached at the end (e.g. BHoMUpgrader32 for version 3.2). That upgrader contains all the changes to the code that occurred during the quarter.
+
When deserialisation fails in the BHoM, the BHoM version used to serialise the object is retrieved from the json. The json is then upgraded to the following version repeatedly until it reaches the current version where it can finally be deserialised into a BHoM object.
+
+
Decentralisation of the upgrade information
+
We will go in details on how the upgrade information is stored inside an upgrader in the remaining sections. There is however one aspect worth mentioning already. Once a quarter is finished, an upgrader is never modified again and simply redistributed alongside the others. During that quarter however, the current upgrader is constantly updated to reflect the new changes. For everyone working on the BHoM to have to modify the exact same files inside the Versioning_Toolkit would be inconvenient and a frequent source of clashes. For that reason, the information related to the upgraded of the current quarter are stored locally at the root of each project where the change occurred.
+
+
Notice that the file name ends with the version of the BHoM it applies to.
+
The content of an empty Versioning_XX.json file is as follow:
When the UI_PostBuild process that copies all the BHoM assemblies to the Roaming folder is ran (i.e. when BHoM_UI is compiled), the information from all the Versioning_XX.json files is collected and compiled in to a single json file copied to the roaming folder next to the BHoMUpgrader executable. It's content will look similar to the local json files with an extra section for the methods (more onto that later):
The diagram below show the chains of calls between the 3 main upgrade methods:
+- UpgradeMethod
+- UpgradeType
+- UPgradeObject
+
Note that UpgradeType is actually covering both the namespace replacement and the type name replacement. The reason behind it is that they come down to the same string replacement principles both at the beginning of an item full name (since types include their namespace in their full name too).
+
Also note that those three are the 3 places where an older upgrader can be called if needed.
Versioning guide: implementing versioning for your changes
+
Versioning can be implemented in one or two ways, depending on the situation:
+
+
by adding the required information to a Versioning_XX.json file; and/or
+
by adding a PreviousVersion attribute to your changed method.
+
+
The choice of the appropriate one depends on the change you are doing, as explained in detail in the following sections.
+
Supported changes
+
BHoM Versioning supports:
+
+
+
Changes to methods (e.g. saved in a script):
+
+
changes in the method name
+
changes in their input/outputs names and types.
+
+
+
+
Changes to Namespaces:
+
+
renaming namespaces
+
general modification to namespaces
+
+
+
+
Changes to classes (object types):
+
+
changes in class properties
+
changes in their name
+
complex structural changes
+
+
+
+
Changes to Datasets:
+
+
renaming or moving of location
+
deletion
+
+
+
+
Head to the section below that is the most relevant to your case.
+
Changes to methods
+
This section addresses how to do Versioning for code changes done to methods, which are probably the most common. There are two possibilites here, and the first is simpler and to be preferred. Both options apply to either method renamings and/or changes in method inputs.
+
Via the PreviousVersion attribute
+
We recommend to simply add a PreviousVersion attribute on top of the method you are modifying. This attribute takes two arguments:
+
+
The first argument of the attribute is the current version of BHoM, e.g. 6.1.
In this example, a method whose full name was FilterFamilyTypesOfFamily, located in the namespace BH.Engine.Adapters.Revit and hosted under the static class Create, is renamed to FilterTypesOfFamily.
+
+
Versioning using the PreviousVersion attribute for a method being renamed
+
publicstaticpartialclassCreate
+{
+[PreviousVersion("3.2", "BH.Engine.Adapters.Revit.Create.FilterFamilyTypesOfFamily(BH.oM.Base.IBHoMObject)")]
+[Description("Creates an IRequest that filters Revit Family Types of input Family.")]
+[Input("bHoMObject", "BHoMObject that contains ElementId of a correspondent Revit element under Revit_elementId CustomData key - usually previously pulled from Revit.")]
+[Output("F", "IRequest to be used to filter Revit Family Types of a Family.")]
+publicstaticFilterTypesOfFamilyFilterTypesOfFamily(IBHoMObjectbHoMObject)
+{
+//....
+}
+
+
+
Example: PreviousVersion for a method's inputs change
+
In this example, a method inputs are being changed: an input (the second one) is being removed.
+The method in the example is a constructor, but the same example applies to any method. Constructors are rarely used in BHoM – we prefer Create Engine methods, which get exposed to UIs – but some types, in particular BHoM_Adapter implementations, make use of them.
+
+
Versioning using the PreviousVersion attribute for a method whose inputs are being changed
+
publicpartialclassXMLAdapter:BHoMAdapter
+{
+[PreviousVersion("3.2", "BH.Adapter.XML.XMLAdapter(BH.oM.Adapter.FileSettings, BH.oM.XML.Settings.XMLSettings)")]
+[Description("Specify XML file and properties for data transfer")]
+[Input("fileSettings", "Input the file settings to get the file name and directory the XML Adapter should use")]
+[Input("xmlSettings", "Input the additional XML Settings the adapter should use. Only used when pushing to an XML file. Default null")]
+[Output("adapter", "Adapter to XML")]
+publicXMLAdapter(BH.oM.Adapter.FileSettingsfileSettings=null)
+{
+//....
+}
+
+
+
Via the versioning json file
+
This alternative is trickier and not required in most cases.
+
The way to do it is to provide a Method section in the VersioningXX.json file:
+
+
Add a VersioningXX.json file to the project, if it does not yet exists for the current version of BHoM, as explained here.
Get a representational string of the method, like this. If you are changing a constructor method, just leave the methodName input empty.
+
Add the following to the Method section of the VersioningXX.json file, as shown in the below example; make sure to place your changing method's Versioning key and representational string.
+
+
+
Versioning using the Versioning.json file for a method whose inputs are being changed
This applies to the case where an entire namespace is renamed. This means all the elements inside that namespace will now belong to a new namespace.
+
To record that change:
+
+
Add a VersioningXX.json file to the project, if it does not yet exists for the current version of BHoM, as explained here.
+
provide the old namespace as key and the new namespace as value to the Namespace.ToNew section of the json file.
+
+
In order to make the change backward compatible (i.e. to allow downgrading, i.e. to open a newer BHoM script from a machine running an older version of BHoM), you can fill the ToOld section with mirrored information.
Modifying the name of a type (i.e. of a class, an object's type) requires to:
+
+
add a VersioningXX.json file to the project, if it does not yet exists for the current version of BHoM, as explained here.
+
add versioning information to the Versioning json file: provide the full name of the old type (namespace + type name) as key and the full name of the new type as value.
+
+
In order to make the change backward compatible (i.e. to allow downgrading, i.e. to open a newer BHoM script from a machine running an older version of BHoM), you can fill the ToOld section with mirrored information.
+
In the example below, we show how the Versioning json file looks like for two classes being renamed, respectively from DocumentBuilder to GBXMLDocumentBuilder and from XMLSettings to GBXMLSettings.
+
+
Adding information to the Versioning.json file regarding two classes being renamed
For the case where an object type (i.e. class) was only modified by renaming some of its property, we have a simple solution relying on the Versioning json file.
+It requires to:
+
+
add a VersioningXX.json file to the project, if it does not yet exists for the current version of BHoM, as explained here.
+
add versioning information to the Versioning json file under the Property.ToNew entry. As a key, provide the full name of the type that contains the property you are renaming (namespace + type name) followed by the old property name. The value must be the new property name.
+
+
In order to make the change backward compatible (i.e. to allow downgrading, i.e. to open a newer BHoM script from a machine running an older version of BHoM), you can fill the ToOld section with mirrored information.
+
In the following example, two properties of the object Bar that lives in the namespace BH.oM.Structure.Elements are being renamed repectively from StartNode to Start and from EndNode to End.
What if you completely redesigned a type of object and changed the properties that define it?
+
This case cannot be solved by a simple replacement of a string and will most likely require some calculations to go from the old object to the new one. This means we need a method that takes the old object in and return the new. This fact presents two challenges:
+
+
The old object definition will not exist anymore, so we cannot use that as the input of the conversion method. Instead we will use a Dictionary containing the properties for both input and output of that conversion method. The other benefit is that the upgrader will not have to depend on BHoM dlls to be able to do the conversion.
+
The conversion method needs to be compile and the upgrader needs to be able to access it. While there are ways to keep the conversion method decentralised, it is way simpler to have it in the versioning toolkit directly. This means this is the only case where you cannot just write the upgrade from your own repo. Luckily, this case is less frequent than the others.
+
+
So what do you need to do to cover the upgrade?
+
+
First, locate the Converter.cs file int the project of the current upgrader.
+
In that file, write a conversion method with the following signature: public static Dictionary<string, object> UpgradeOldClassName(Dictionary<string, object> old).
+
In the Converter constructor, add that method to the ToNewObject Dictionary. the key is that object type full name (namespace + type name) and the value is the method.
+
If you want to cover backward compatibility, you can also write a DowngradeNewClassName method and add it to the ToOldObject dictionary.
You are working from a Dictionary so make sure that the properties exist before using them
+
You will also need to cast them since the dictionary values are all objects
+
Make sure to provide the new object type in the dictionary by defining the "_t" property.
+
+
Changes to Datasets
+
Changes to a Dataset name or location
+
Updating the path to a Dataset works in a similar manner to changes to names of types. The path to a dataset is changed the path from C:\ProgramData\BHoM\Datasets leading up to the json file has been changed in any way. This could be for example be one or more of the following:
+
+
The name of the json file has been changed
+
The name of the folder or any super-folder of the json file has been changed
+
An additional folder has been added to the path
+
A folder has been removed from the path
+
+
When this has happened, you will need to:
+
+
add a VersioningXX.json file to the project, if it does not yet exists for the current version of BHoM, as explained here.
+
add versioning information to the Versioning json file under the Dataset entries, as shown in the example below.
+
+
In the example below, the Versioning json file specifies the move of some structural material files to a parent folder called Structure.
When versioning Dataset the ToNew segment is required, and not optional. This is for the BHoM_UI to be able to update components linking to the Dataset.
+
The ToOldversioning of Dataset is optional, but should be done if the developer wants to ensure that the Dataset still is acessible from the same serach paths as before, for calls to the methods in the Library_Engine to still work. This could for example be to ensure the call BH.Engine.Library.Libraries("Materials\\MaterialsEurope\\Concrete") still returns the same Dataset as before the change was made. It is strongly recomended that calls like the above from code is updated at the same time as the change to the dataset is made, but generally recomended that the ToOld versioning is done to ensure calls from any UI and that code calls to the methods outside the control of the developer making the change is still functions as before.
+
Deletion of a Dataset
+
When a dataset is removed without a replacement, a message should be provided, similar to how it is done for objects and methods. For datasets this is done via the MessageForDeleted section of the Dataset part of the upgrade. Example below showcasing a case where the European concrete and rebar materials have been removed:
+
+
Removed Dataset
+
{
+"Dataset":{
+"ToNew":{
+},
+"ToOld":{
+}
+"MessageForDeleted":{
+"Materials\\MaterialsEurope\\Concrete":"Clear message why this dataset has been removed. Point of contact (could be a github repository) where the user can ask questions about why this was removed.",
+"Materials\\MaterialsEurope\\Rebar":"Clear message why this dataset has been removed. Point of contact (could be a github repository) where the user can ask questions about why this was removed.",
+}
+}
+}
+
+
+
Items that cannot be versioned: deletions or foundational changes
+
In some cases, an upgrade/downgrade of a method or object is simply not possible:
+
+
The item was deleted without replacement
+
A replacement exists but is so different from the original that an automatic conversion is impossible.
+
+
In such cases, it is important to inform the user and provide them with as much information as possible to facilitate the transition to the new version of the code. You will need to:
+
+
add a VersioningXX.json file to the project, if it does not yet exists for the current version of BHoM, as explained here.
+
add versioning information to the Versioning json file under the MessageForDeleted and/or MessageForNoUpgrade entries. As shown in the example below.
+
+
+
Items that cannot be versioned
+
{
+...
+"MessageForDeleted":{
+"BH.oM.Adapters.DIALux.Furnishing":"This object was provided to build up DIALux models within a BHoM UI, but was deemed to be unnecessary with the suitable conversions between existing Environmental objects and DIALux provided by the DIALux Adapter. To avoid confusion, this object has been removed. If further assistance is needed, please raise an issue on https://github.com/BHoM/DIALux_Toolkit/issues",
+"BH.Engine.Grasshopper.Compute.IRenderMeshes(BH.oM.Geometry.IGeometry, Grasshopper.Kernel.GH_PreviewMeshArgs)":"The method was made internal to the Grasshopper Toolkit. If you still need to render objects, consider using one of the Render methods from BH.Engine.Representation instead",
+"BH.Engine.Adapters.Revit.Query.Location(BH.oM.Adapters.Revit.Elements.ModelInstance)":"This method was a duplicate of GetProperty method, please use the latter instead.",
+"BH.Engine.BuildingEnvironment.Convert.ToConstruction(BH.oM.Base.CustomObject)":"This method was providing a highly specific conversion between a specific custom data schema and Environment Materials that is no longer relevant to the workflows provided in Environments. It is advised to create materials manually using the Solid or Gas types as appropriate. For more assistance please raise an issue for discussion on https://github.com/BuroHappoldEngineering/BuildingEnvironments_Toolkit/issues",
+},
+"MessageForNoUpgrade":{
+"BH.oM.Structure.Loads.BarVaryingDistributedLoad":"The object has been redefined in such a way that automatic versioning is not possible. To reinstate the objects you could try exploding the CustomObject that will have been returned and make use of the BH.Enigne.Structure.Create.BarVaryingDistributedLoadDistanceBothEnds method from the Structures_Engine. If doing this, treat DistanceFromA as startToStartDistance and DistanceFromB as endToEndDistance. Also, treat ForceA and MomentA as ForceAtStart and MomentAtStart, and ForceB and MomentB as ForceAtEnd and MomentAtEnd. If you have any issues with the above, please feel free to raise an issue at https://github.com/BHoM/BHoM_Engine/issues.",
+"BH.Engine.Reflection.Modify.SetPropertyValue(System.Collections.Generic.List<BH.oM.Base.IBHoMObject>, System.Type, System.String, System.Object)":"Please use BH.Engine.Reflection.Modify.SetPropertyValue(object obj, string propName, object value) instead.",
+"BH.Engine.Base.Compute.Hash(BH.oM.Base.IObject, System.Collections.Generic.List<System.String>, System.Collections.Generic.List<System.String>, System.Collections.Generic.List<System.String>, System.Collections.Generic.List<System.Type>, System.Int32)":"This method's functionality has changed deeply with respect to an older version of BHoM. Please replace this component with BH.Engine.Base.Query.Hash(), then plug the inputs as needed.",
+"BH.Engine.Adapters.Revit.Create.ViewPlan":"This method is not available any more. To reinstate the object, please use BH.Engine.Adapters.Revit.Create(string, string) instead.",
+"BH.oM.LifeCycleAssessment.MEPScope":"This object has been updated to include new features to enhance calculations for LifeCycleAssesment workflows. Please update the object on the canvas using the default create component to update this component. For further assistance, please raise an issue on https://github.com/BHoM/LifeCycleAssessment_Toolkit/issues",
+}
+}
+
+
+
Obtaining a Versioning Key
+
A versioning key is like a signature identifying a method or object.
+You can obtain it by using the BH.Engine.Versioning.VersioningKey() method, as explained below.
+
+
Important: get the versioning key before the change
+
You need to get the versioning key of the object/method before it was changed.
+If you have already done your code changes, no worries: you can simply commit your changes on your branch, then switch back to the develop branch and recompile, then use the BH.Engine.Versioning.VersioningKey() as explained below.
+
+
Get the key for objects
+
Use the method BH.Engine.Versioning.VersioningKey() and just provide the input declaringType, which is the Full Name of the object that you are modifying (i.e. the name of the class preceded by its namespace).
+
+
Get the Versioning key for objects
+
+
+
Get the key for methods
+
Use the method BH.Engine.Versioning.VersioningKey() and provide both:
+
+
the input declaringType, which is the Full Name of the Query/Compute/Create/Modify/Convert class (i.e. the name of the class, preceded by its namespace) which contains the method that you are modifying;
+
the input methodName, which is the name of the method that you are modifying (in case you are renaming the method, this needs to be its name before the rename).
+
+
+
Get the Versioning key for methods
+
+
+
Adding a Versioning_XX.json file to the project
+
Adding a Versioning_XX.json file to the project is needed for certain versioning scenarios, but not all. In some cases (e.g. changes in a method) it may be sufficient to use the PreviousVersion attribute.
+
This is as simple as adding an empty json file to the project, named Versioning_XX.json, where the XX must be replaced with the current BHoM version. For example:
+
+
The empty file should then be immediately populated with the following content (copy-paste it!):
Then you can fill it in as described by the relevant "changes" section.
+
Why having a Versioning_XX.json file?
+
BHoM Versioning is implemented via a specific, stand-alone mechanism, hosted in the Versioning_Toolkit.
+
By adding a Versioning_XX.json file, the information related to code changes are stored locally in each project where the change occurred. This enables decentralisation, i.e. many people can independently code and change BHoM objects or methods in different Toolkits without the need to modify the Versioning_Toolkit, avoiding clashes.
+
Troubleshooting on Versioning
+
The upgrade doesn't happen - How can I debug ?
+
The upgrader are independent exe files so you cannot reach them by attaching to your UI process as you would normally do when debugging the BHoM. They are also hidden processed so you don't have command windows popping up when opening old scripts. In case, you need to figure out what is going on in there, you can always have those upgrade processes visible by commenting two lines of code in the Versioning_Engine (situated on the code BHoM_Engine repo):
+
+
In the Versioning-Engine project, find the ToNewVersion file
+
In that file, find the GetPipe method
+
Toward the end of that method, comment out the following line:
+- recompile the solution and the BHoM_UI as usual
+
You should now have command windows popping up as soon as the upgrader are needed. You should also find the BHoMUpgrader processes in your task manager.
Accessing various datasets, such as material or section datasets, can be useful when coding for BHoM. For example, you may need datasets when coding C# Unit Tests, or when programming some particular Engine function.
+
Access BHoM Datasets from a C# program, you need to ensure the correct dependencies are added to your project. The following steps will guide you through the process of adding the appropriate dependencies and demonstrate a few methods for accessing your desired dataset.
+
Step 1: Access Reference Manager
+
Access the Reference Manager in the C# project where you want to add the dependency.
+
+
+
Step 2: Browse for the DLL
+
Go to the "Browse" tab and click the "Browse" button in the bottom-right corner.
+
+
+
Navigate to the BHoM assemblies folder using the File Explorer window. The folder is usually located at C:\ProgramData\BHoM\Assemblies. Select Data_oM.dll and press "Add."
+
+
+
Step 3: Add Dependency
+
Make sure to check the box next to Data_oM.dll in the Reference Manager window and press "OK."
+
+
+
Step 4: Modify File Path
+
Open the project file of your specific C# project by double-clicking it with the left mouse button. Locate the line responsible for loading Data_oM.dll and modify the file path as shown in the image below.
+
+
+
Step 5: Get the Dataset data
+
The following example demonstrates how to access the Section Library from BHoM, specifically the .
+
To access the library, use the Match method as shown in the example below. This returns the HE1000M section defined in the EU_SteelSectionLibrary dataset.
The boolean values allow you to specify whether your search should be case-sensitive and whether to consider spaces within the object name.
+
Find Existing Libraries
+
If you're unsure about the available datasets, check the BHoM_Datasets repository.
+
Under BHoM_Datasets\DataSets, you'll find multiple folders and subfolders containing numerous json files. Each json is a dataset, and each folder acts as a dataset library.
+
For example, in the folder [BHoM_Datasets repo folder]\BHoM_Datasets\DataSets\Structure\SectionProperties\EU_SteelSections you will find the following json files:
+
+
+
These .json files contain multiple objects. To extract objects from these datasets, you'll need the name of the desired object. This can be found as an attribute within the .json file. To locate these names, you can open the .json file in an editor like Visual Studio Code and search for the object name you need.
+
Compliance
+
Compliance regulations for Datasets are outlined in IsValidDataset.
+
Source
+
For users of the data to be able to verify where it is coming from, it is important to populate the Source object for the dataset. As many of the properties of the source as available should generally be populated, with an emphasis on the following:
+
Title
+
The title of the publication/paper/website/... from which the data has been taken.
+
SourceLink
+
An HTTP link to the source. Important to allow users of the data to easily identify where the data is coming from.
+
Confidence
+
Level of confidence both in the data source and in how well the serialised data in the BHoM dataset has been ensured to match the source. It should be noted that, independent of the confidence level on the Dataset, all Datasets distributed with the BHoM are subject to the General Disclaimer.
+
The confidence is split into 5 distinct categories, and the creator/distributor/maintainer of the dataset should always aim for the highest level of confidence achievable.
+
Undefined
+
Default value - assume no fidelity and no source.
+
Should generally be avoided when adding a new Dataset for distribution with the BHoM - one of the levels below should be explicitly defined.
+
None
+
The Dataset may not have a reliable source and/or fidelity to the source has not been tested.
+
To be used for prototype Datasets where no reliable data is available, and not for general distribution within the BHoM.
+
Low
+
The Dataset comes from an unreliable source, but the data matches the source based on initial checks.
+
For cases where no reliable source for the data type is available. Can be allowed to be distributed with the BHoM in circumstances where no reliable source can be found and the data still can be deemed useful.
+
Medium
+
The Dataset comes from a reliable source and matches the source based on initial checks.
+
For most cases the minimum required level of confidence for distribution of a Dataset with the BHoM. To reach this level of confidence, the Source object should be properly filled in, and a substantial spot checking of the data should have been made. If at all possible, maintainers of a Medium confidence level Dataset should strive to fulfil the requirements of High confidence.
+
High
+
The Dataset comes from a reliable source and matches the source based on extensive review and testing.
+
Highest level of confidence for BHoM datasets, and should generally be the aspiration for all Datasets included with the BHoM.
+
To achieve this, a clear testing procedure should generally be in place, which outlines how all of the data points in the Dataset have been checked against the source data and/or verified by other means to be correct.
The data should be serialised in a Dataset object, and the relevant .csproj file in the repo, in which the Dataset is stored, should have a post build event implemented that ensures that the Dataset is copied to the C:\ProgramData\BHoM\Datasets folder. This will allow it to be picked up by the Library_Engine.
+
Generate a new dataset
+
To generate a new dataset to be used with the BHoM the following steps should be taken.
+
+
+
Generate the objects to be stored in the new Dataset. This means creating the BHoMObject of the correct type in any of the supported UIs. See below for an example of how to create a handful of standard European steel materials in Grasshopper. Remember to give the created objects an easily identifiable name as the name is what will show up when using the data in the dropdowns. Remember that all BHoM objects should be defined in SI units.
+
+
+
+
Store the created objects in a Dataset object and give the dataset an appropriate name. This is the name for the dataset - the name that appears in the UI is described the next step.
+
+
+
+
Populate the source object and assign it to the dataset. See guidance below regarding the source.
+
+
+
+
Convert the dataset object and store it to a single line json file. This is easiest done using the FileAdapter. The library engine relies on the json files to be a single line per object, while the default json output from the FileAdapter is putting the json over multiple lines. To make sure the produced json file is in the correct format for the library engine, provide a File.PushConfig with UseDatasetSerialization set to true and BeautifyJson set to false to the push command. Name the file something clearly identifiable, as the name of the file will be what is used to identify the dataset by the library engine, and will be what it is called in the UI menu.
+
+
+
+
For personal use, do one of the following:
+
+
Place the file in the relevant subfolder of the C:\ProgramData\BHoM\Datasets folder. If no relevant subfolder already exists, a new one can be added. The folder will be used to generate the menus used to find the dataset in the menu system, and also makes a whole folder searchable using the Library method. Remember that running an installer will reset the datasets folder so for this option backup the json file, or use option ii.
+
Place the json file in a subfolder of a folder of your own choice and use the custom dataset folder outlined below.
+
+
+
For distribution of the Dataset to the BHoM community do the following:
+
Store the dataset in the appropriate repository folder:
+
For a general dataset, such as standard materials etc., place the json file in an appropriate subfolder folder in BHoM_Datasets.
+
For a toolkit specific dataset put the json file in a Dataset folder in the root folder of the toolkit to host the dataset. If no such folder exist, it should be created. Make sure that the oM project in the toolkit has the following post-build event code: xcopy "$(SolutionDir)DataSets\*.*" "C:\ProgramData\BHoM\DataSets" /Y /I /E that ensures that the dataset is copied over to the C:\ProgramData\BHoM\Datasets folder.
+
+
+
Raise a Pull request on GitHub and ask for review from relevant parties.
+
+
+
+
Custom dataset folder
+
By default, the Library_Engine scans the C:\ProgramData\BHoM\Datasets for all json files and loads them up to be queryable by the UI and the methods in the library engine. This location is reset with each BHoM install to make sure all datasets are up-to-date and that any modifications or fixes correctly are applied to the data. For some cases it can be also useful to have your own datasets stored in your own folder for example on a network drive to share during work on a particular project.
+
For these reasons it is possible to get the Library_Engine to scan other folders for datasets as well. This can easily be controlled via the AddUserPath and RemoveUserPath commands that can be called from any UI. After the AddUserPath command has been run once for a particular folder, the library engine will store the information about this folder in its settings and will keep on looking in subfolders of that location for any json files to be used as dataset.
+
+
To stop the Library_Engine from looking in this particular folder, use the RemoveUserPath command, providing a link to the folder you no longer want to be scanned by the Library_Engine.
+
+
Remember that the menu system of the Dataset dropdown components are built up using the subfolders, so even if only a single dataset is placed in this custom folder it might be a good idea to still put your json file in an appropriate subfolder.
+
+
+
+
+
+ Last update:
+ November 23, 2023
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git "a/Guides and Tutorials/Coding with BHoM/Diffing and Hashing/Diffing-and-Hashing-\342\200\223-guide-for-developers/index.html" "b/Guides and Tutorials/Coding with BHoM/Diffing and Hashing/Diffing-and-Hashing-\342\200\223-guide-for-developers/index.html"
new file mode 100644
index 000000000..4130f3702
--- /dev/null
+++ "b/Guides and Tutorials/Coding with BHoM/Diffing and Hashing/Diffing-and-Hashing-\342\200\223-guide-for-developers/index.html"
@@ -0,0 +1,4377 @@
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ Diffing and Hashing: guide for developers - BHoM documentation
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
This page gives a more in-depth technical explanation about some diffing methods, and also serves as a guide for developers to build functionality on top of existing diffing code.
+See the Diffing and the Hash wiki pages for a more quick-start guide.
The IDiffing() method is designed to be a "universal" entry point for users wanting to diff their objects; for this reason, it has an automated mechanism to call any Toolkit-specific diffing method that can is compatible with the input objects. This work similarly to the Extension Method discovery pattern that is often leveraged in many BHoM methods.
+
A Toolkit-specific Diffing method is defined as a method:
+- that is public;
+- whose name ends with Diffing;
+- that has the following inputs:
+ - a first IEnumerable<object> for the past objects;
+ - a second IEnumerable<object> for the following objects;
+ - any number of optional parameters;
+ - a final DiffingConfig parameter (that should default to null, and be auto initialised if null within the implementation).
The IDiffing method does a series of automated steps to ensure that the most appropriate diffing method gets invoked for the input objects.
+
Invoking of the Toolkit-specific diffing methods
+
The IDiffing first looks for any Toolkit-specific diffing method that is compatible with the input objects (relevant code here). This is done by checking if there is a IPersistentAdapterId stored on the objects; if there is, the namespace to which that IPersistentAdapterId object belongs is taken as the source namespace to get a compatible Toolkit-specific diffing method. For example, if the input objects own a RevitIdentifier fragment (which implements IPersistentAdapterId), then the namespace BH.oM.Adapters.Revit.Parameters is taken. This namespace, which is an .oM one, is "modified" to an .Engine one, so the related Toolkit Engine is searched for a diffing method.
+
If a Toolkit-specific diffing method match is found, that is then invoked. For example, this is how RevitDiffing() gets called by the IDiffing.
+Note that only the first matching method gets invoked. This is because we only allow to have 1 Toolkit-specific diffing method. If you have method overloading over your Toolkit-specific Diffing method (for example, because you want to provide the users with multiple choices when they choose to invoke directly your Toolkit-specific diffing method), you must ensure that all overloads are equally valid and can any can be picked by the IDiffing with the same results (like it happens for RevitDiffing(): all methods end up calling a single, private Diffing method, and additional inputs are optional, so they all behave the same if called by the IDiffing).
+
What happens for objects that do not have a Toolkit-specific diffing method
+
If the previous step does not find any Toolkit-specific diffing method compatible with the input objects, then a variety of steps are taken to try possible diffing methods. In a nutshell, a series of checks are done on the input objects to see what diffing method is most suitable. This is better described in the following diagram. For more details on each individual diffing method, see here.
+
+
Other Diffing methods inner workings
+
In addition to the main Diffing method IDiffing(), there are several other methods that can be used to perform Diffing. These are a bit more advanced and should be used only for specific cases. All diffing methods can be found in the Compute folder of Diffing_Engine.
+
Most diffing methods are simply relying on an ID that is associated to the input objects, or a similar way to determine which object should be compared to which. Once a match is found, the two matched objects (one from the pastObjects set and one from the followingObjects set) are sent to the ObjectDifferences() method, as illustrated by the following diagram.
+
This diagram also illustrates that only the DiffWithHash() method does not rely on the ObjectDifferences() method. The DiffWithHash() is a rather simple and limited method, in that it cannot identify Modified objects but only new/old ones, and it is described here.
This is the method that has the task of finding all the differences between two input objects. This method currently leverages an open-source, free library called CompareNETObjects by Kellerman software. It maps our ComparisonConfig options to the equivalent class in the CompareNETObjects library, and then executes the comparison using it.
+
Mapping our ComparisonConfig to Kellerman library
+
Because not all of the options available in the ComparisonConfig are mappable to Kellerman's, ObjectDifferences() has to adopt a workaround. For example, our numerical approximation options are not directly compatible.
+The general compatibility strategy is:
+- if an option is mappable/convertible, map/convert it from our ComparisonConfig to Kellerman's CompareLogic object. This is true for most of them.
+- if an option is not compatible with Kellerman (like our numerical approximation options), set Kellerman CompareLogic so it finds all possible differences with regards to that option (like we do for numerical differences), then iterate the differences found and cull out those that are non relevant (example for the numerical differences).
+
The loop to iterate over the differences found by Kellerman is also useful to further customise the output, as shown by the following section.
+
Customising the Diffing output: ComparisonInclusion() extension method
+
In order to customise our diffing output, we want to customise how the ObjectDifferences() method determines the differences between objects.
+This is done through a specific ComparisonInclusion() extension method that is invoked when we loop through the differences found by the Kellerman library. This is essentially an application of the Extension Method discovery pattern that is often leveraged in many BHoM methods.
+
You can implement a ObjectDifferences() method in your Toolkit to customise how the difference between two specific objects is to be considered by the diffing. This method must have the following inputs, in this order:
+- a fist object input (which will be the object coming from the pastObjs set);
+- a second object input, of the same type as the first object (which will be the object coming from the followingObjs set);
+- a string input, which will contain the Full Name of the property difference found by the ObjectDifferences() method;
+- a BaseComparisonConfig input, which will be passed in by the ObjectDifferences() method.
+
The method must return a ComparisonInclusion object, which will contain information on whether the difference should be included or not, and how to display it.
publicstaticComparisonInclusionComparisonInclusion(thisRevitParameterparameter1,RevitParameterparameter2,stringpropertyFullName,BaseComparisonConfigcomparisonConfig)
+{
+// Initialise the result.
+ComparisonInclusionresult=newComparisonInclusion();
+
+// Differences in any property of RevitParameters will be displayed like this.
+result.DisplayName=parameter1.Name+" (RevitParameter)";
+
+// Check if we have a RevitComparisonConfig input.
+RevitComparisonConfigrcc=comparisonConfigasRevitComparisonConfig;
+
+// Other logic
+...
+}
+
+
Note that this method supports Toolkit-specific ComparisonConfig objects, like e.g. RevitComparisonConfig. See the section below for more details.
+
Customising the Hash: HashString() extension method
+
If you want a specific object to be Hashed in a particular way, you can implement a HashString() extension method for that object in your Toolkit. The HashString() method will get invoked when computing the Hash(). This is essentially an application of the Extension Method discovery pattern that is often leveraged in many BHoM methods.
+
This method must have the following inputs, in this order:
+- An object input, which will be the object for which we are calculating the Hash.
+- A string input, which will indicated the FullName of the property being analysed by the Hash() method (for example when the input object is a property of another object; this can be useful in certain cases, and if not useful can simply be ignored).
+- A BaseComparisonConfig input, which can be used to will be passed in by the Hash() method.
publicstaticstringHashString(thisRevitParameterrevitParameter,stringpropertyFullName=null,BaseComparisonConfigcomparisonConfig=null)
+{
+// Null check.
+if(revitParameter==null)returnnull;
+
+stringhashString=revitParameter.Name+revitParameter.Value;
+
+// Check if we have a RevitComparisonConfig input.
+RevitComparisonConfigrcc=comparisonConfigasRevitComparisonConfig;
+
+// Other logic
+...
+}
+
+
Note that this method supports Toolkit-specific ComparisonConfig objects, like e.g. RevitComparisonConfig. See the section below for more details.
+
Toolkit-specific ComparisonConfig options
+
There are cases where you may need more options to further customise the Hash or Diffing process, to refine how they work with your Toolkit's objects.
+
The "default" comparisonConfig object gives all the default options, and it inherits from the BaseComparisonConfig abstract class. This abstract class can be extended by the "Toolkit-specific" comparisonConfigs, so you can include additional options to deal with certain objects in your Toolkit.
+See an example with Revit's RevitComparisonConfig.
+
If you implement your own Toolkit-specific ComparisonConfig object, you will need to implement the functions that deal with it too, which should include at least one of:
+- A toolkit-specific Diffing() method (example in Revit), which your users can call independently, or that may be automatically called by the IDiffing method, as shown here.
+- A toolkit-specific HashString() method (example in Revit), which will get invoked when computing the Hash().
+- Any number of ComparisonInclusion() methods that you might need to customise the diffing output per each object (example in Revit for RevitParameters), as explained here.
+
Testing and profiling
+
We have a DiffingTests repo which contains Unit Tests and profiling functions. These are required given the amount of options and use cases that both offer.
+
+
+
+
+
+ Last update:
+ November 23, 2023
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/Guides and Tutorials/Coding with BHoM/Getting-started-for-developers/index.html b/Guides and Tutorials/Coding with BHoM/Getting-started-for-developers/index.html
new file mode 100644
index 000000000..ad7852622
--- /dev/null
+++ b/Guides and Tutorials/Coding with BHoM/Getting-started-for-developers/index.html
@@ -0,0 +1,4531 @@
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ Getting started for developers - BHoM documentation
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Here's a quick start guide. After reading this, you might want to head to create your own Toolkit.
+
Building BHoM from Source
+
Please follow the steps below:
+
+
Use git clone (or use GitHub desktop) to download the repositories in the list below.
+
Use your preferred IDE to build the solutions in the order as they appear below.
+We recommend Visual Studio Community.
+
+
+
Build order
+
The first time you build BHoM you need to clone and build the repos in the order specified below.
+
You must pick all the Mandatory repos.
+
+
+
Rebuilding and seeing changes in the UIs (Grasshopper/Dynamo/Excel)
+
When building in visual studio, the compiled assemblies will go in the ./Build folder of your Repo; additionally, there is a Post-Build event that copies the files in the central BHoM folder: C:\ProgramData\BHoM\Assemblies.
+
When you build, if there is any UI open (e.g. Rhino/Grasshopper/Revit/Excel), the dlls will not be overwritten in the central folder because they are referenced by the UI software. Therefore, to ensure the changes are visible in the UI, you must make sure to close all UI software, then reopen it to see updated changes.
+
+
+
Tip
+
When developing a Toolkit, in order to reduce rebuild iterations, you might want to:
The last step will fire up your UI application and you will be able to modify the code while debugging, on-the-fly (just press the Pause button in Visual Studio).
+
Note that not all IDEs support this (notably, not the Express editions of Visual Studio – only the Community, Professional and Enterprise ones do).
+
An alternative that always works is, after steps 1 and 2 above, simply fire up your UI application and attach to its process.
+ This way you will be able to follow code execution and check exceptions; however, this does not allow for code modification while debugging.
I can't Rebuild the solution: NuGet package(s) missing error
+
Sometimes you might encounter this error. Although Visual Studio "Rebuild All" command should take care of Restoring the NuGet packages for you, to solve this just run that manually.
+Right click the solution → Restore NuGet Packages.
+
I have done some changes to my code, but when I open Grasshopper (or Dynamo, or Excel) the code still behaves as before! Why it is not updated?
+
After compiling, check that the Build was successful, by looking in the "Output" tab at the bottom of the VS interface; make sure no errors are there, and also that the Post-build event worked successfully. See the notes above.
+
+
+
+
+
+ Last update:
+ November 23, 2023
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/Guides and Tutorials/Coding with BHoM/IDEs/BHoM-Grasshopper-CSharp/index.html b/Guides and Tutorials/Coding with BHoM/IDEs/BHoM-Grasshopper-CSharp/index.html
new file mode 100644
index 000000000..b42ccfa3b
--- /dev/null
+++ b/Guides and Tutorials/Coding with BHoM/IDEs/BHoM-Grasshopper-CSharp/index.html
@@ -0,0 +1,4425 @@
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ Coding BHoM in a Grasshopper CSharp script component - BHoM documentation
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Coding BHoM in a Grasshopper CSharp script component
+
BHoM can be referenced and used in a Grasshopper "C# Script" component. The only additional requirement as of the current version is to also reference netstandard.dll in the same Grasshopper component.
+
Find the .NET Standard assembly dll file
+
Currently, a reference to the .NET Standard assembly is required to use BHoM from a C# script component in Grasshopper.
+
Download (or find on your drive) the .NET Standard assembly
+
You can download the right version of netstandard.dll (currently, 2.0.3 is the one used in BHoM) from here:
+1. Click on "download package".
+2. Open the downloaded .npckg file with a Zip archiver like 7zip.
+3. Go in the folder build/netstandard2.0/ref/ and you will find netstandard.dll.
+4. Place the netstandard.dll somewhere in your C: drive where you will be able to find it, and remember that location. You could place it in the BHoM installation directory (normally C:\ProgramData\BHoM\), but be aware that if you reinstall or update BHoM it will get deleted.
+
+
Note
+
If you downloaded netstandard.dll previously but you can't remember where you placed it, you can search for a copy of netstandard.dll in your disk.
+⚠️ However, there could be multiple copies/versions of a netstandard.dll file on your drive. If you find multiple files called netstandard.dll, then it's better to re-download it from the link above to make sure you are using the right version. ⚠️
+
Search for netstandard.dll in Explorer from your C: drive:
+
+
Once found, get its location by right-clicking on it and doing "Open location", then copy the location in Explorer. Take note of it.
+
+
Reference the assemblies in the C# Script component
+
To start coding let's create a "C# Script" component in Grasshopper where we will reference the required DLLs.
+
+
Drop a "C# Script" component in the canvas.
+
Right click it, do "Manage Assemblies". A window will pop up.
+
Click "Add". A File Explorer window will pop up.
+
Add a reference to the netstandard.dll file, found as explained above. Select it and do "Open". You will see that it appears in the Referenced Assemblies section.
+
Click "Add" again. Navigate to the BHoM assemblies directory (normally C:\ProgramData\BHoM\Assemblies). There you will find all BHoM DLLs. As a minimum, we will want to include BHoM.dll and BHoM_Engine.dll. We can add as many as we need, but don't add them all together. You will come back to add more in case the script complains that some are missing.
+
+
+
Start scripting!
+
Let's make an example where we want to create a BH.oM.Geometry.Point object in the script. To do so, we need to add another 2 references, Geometry_oM.dll and Dimensional_oM.dll. Let's do that as explained above. We will end up having the following:
Press OK, and voila, a BHoM point is created! You can also check its values with the Explode component:
+
+
Script with more complex objects
+
Do the same for any other BHoM object you may want to create. Using more complex objects will require to add more references, like explained in the previous section. For example, if we want to create a structural node with this point, we can do:
However, if you press OK, you will be met with an error like:
+
+
This simply means that you need to add references to Structure_oM.dll. If we add that and try again, the error will still not go away, but will be different:
+
+
This is because the Structure_oM.dll itself depends on Analytical_oM.dll.
+By adding this last dependency the error will go away.
+
+
+
+
+
+ Last update:
+ November 23, 2023
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/Guides and Tutorials/Coding with BHoM/IDEs/Using Visual Studio Code/index.html b/Guides and Tutorials/Coding with BHoM/IDEs/Using Visual Studio Code/index.html
new file mode 100644
index 000000000..7ab00cb95
--- /dev/null
+++ b/Guides and Tutorials/Coding with BHoM/IDEs/Using Visual Studio Code/index.html
@@ -0,0 +1,4444 @@
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ Using Visual Studio Code For BHoM Development - BHoM documentation
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
{
+// Use IntelliSense to learn about possible attributes.
+// Hover to view descriptions of existing attributes.
+// For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387
+//To attach to running process of your choosing
+"version":"0.2.0",
+"configurations":[
+{
+"name":"Attach to Process",
+"type":"clr",
+"request":"attach",
+"processId":"${command:pickProcess}"
+}
+],
+"postDebugTask":"echo"
+}
+
+
Attach to running process of pre-defined name
+
within your launch.json
+add the following
+
{
+// Use IntelliSense to learn about possible attributes.
+// Hover to view descriptions of existing attributes.
+// For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387
+//To attach to running process automatically
+"version":"0.2.0",
+"configurations":[
+{
+"name":"Attach to Revit",
+"type":"coreclr",
+"request":"attach",
+"processName":"Revit.exe",
+"justMyCode":false
+}
+],
+"postDebugTask":"echo"
+}
+
+
Working As A Team
+
Not all members of the team will want to work in VS Code.
+Please be considerate of this as you develop by adding the .vscode folder to your .gitignore
+
+
+
+
+
+ Last update:
+ November 23, 2023
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/Guides and Tutorials/Coding with BHoM/IDEs/examplescript.png b/Guides and Tutorials/Coding with BHoM/IDEs/examplescript.png
new file mode 100644
index 000000000..28739d923
Binary files /dev/null and b/Guides and Tutorials/Coding with BHoM/IDEs/examplescript.png differ
diff --git a/Guides and Tutorials/Coding with BHoM/IDEs/examplescript_error01.png b/Guides and Tutorials/Coding with BHoM/IDEs/examplescript_error01.png
new file mode 100644
index 000000000..8c1d358c0
Binary files /dev/null and b/Guides and Tutorials/Coding with BHoM/IDEs/examplescript_error01.png differ
diff --git a/Guides and Tutorials/Coding with BHoM/IDEs/examplescript_error02.png b/Guides and Tutorials/Coding with BHoM/IDEs/examplescript_error02.png
new file mode 100644
index 000000000..4e63107c4
Binary files /dev/null and b/Guides and Tutorials/Coding with BHoM/IDEs/examplescript_error02.png differ
diff --git a/Guides and Tutorials/Coding with BHoM/IDEs/examplescript_output.png b/Guides and Tutorials/Coding with BHoM/IDEs/examplescript_output.png
new file mode 100644
index 000000000..7fa5bb3db
Binary files /dev/null and b/Guides and Tutorials/Coding with BHoM/IDEs/examplescript_output.png differ
diff --git a/Guides and Tutorials/Coding with BHoM/IDEs/image-1.png b/Guides and Tutorials/Coding with BHoM/IDEs/image-1.png
new file mode 100644
index 000000000..528206c86
Binary files /dev/null and b/Guides and Tutorials/Coding with BHoM/IDEs/image-1.png differ
diff --git a/Guides and Tutorials/Coding with BHoM/IDEs/image-2.png b/Guides and Tutorials/Coding with BHoM/IDEs/image-2.png
new file mode 100644
index 000000000..42b9317d6
Binary files /dev/null and b/Guides and Tutorials/Coding with BHoM/IDEs/image-2.png differ
diff --git a/Guides and Tutorials/Coding with BHoM/IDEs/image-8.png b/Guides and Tutorials/Coding with BHoM/IDEs/image-8.png
new file mode 100644
index 000000000..808af1a97
Binary files /dev/null and b/Guides and Tutorials/Coding with BHoM/IDEs/image-8.png differ
diff --git a/Guides and Tutorials/Coding with BHoM/IDEs/referenced_assemblies01.png b/Guides and Tutorials/Coding with BHoM/IDEs/referenced_assemblies01.png
new file mode 100644
index 000000000..c19c2fdde
Binary files /dev/null and b/Guides and Tutorials/Coding with BHoM/IDEs/referenced_assemblies01.png differ
diff --git a/Guides and Tutorials/Coding with BHoM/IDEs/referenced_assemblies02.png b/Guides and Tutorials/Coding with BHoM/IDEs/referenced_assemblies02.png
new file mode 100644
index 000000000..44b7b8ca5
Binary files /dev/null and b/Guides and Tutorials/Coding with BHoM/IDEs/referenced_assemblies02.png differ
diff --git a/Guides and Tutorials/Visual Programming with BHoM/Diffing and Hashing/Configuring-Revit-objects-comparison-(RevitComparisonConfig)/index.html b/Guides and Tutorials/Visual Programming with BHoM/Diffing and Hashing/Configuring-Revit-objects-comparison-(RevitComparisonConfig)/index.html
new file mode 100644
index 000000000..f5550c679
--- /dev/null
+++ b/Guides and Tutorials/Visual Programming with BHoM/Diffing and Hashing/Configuring-Revit-objects-comparison-(RevitComparisonConfig)/index.html
@@ -0,0 +1,4361 @@
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ Configuring Revit objects comparison (RevitComparisonConfig) - BHoM documentation
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
As we've seen in the Diffing and Hash pages, we can customise how objects are compared to each other (either using Diffing or by comparing their Hashes) through the ComparisonConfig object.
+
In addition to the basic ComparisonConfig that we can use with any object, we also have a Revit-specific RevitComparisonConfig object that expands the available options.
+
Below is an example of how the RevitComparisonConfig looks in Grasshopper. Note that most of them are already covered by the ComparisonConfig object base wiki, while the Revit-specific options are only the first 4 (explained below).
+
+
+
Note for developers: Toolkit-specificComparisonConfig objects
+
The "default" comparisonConfig object inherits from the BaseComparisonConfig abstract class, which defines all the "basic" options. This abstract class can be extended by the "Toolkit-specific" comparisonConfigs, so you can include additional options to deal with certain objects in your Toolkit, of which RevitComparisonConfig is an example.
+
In general, if you implement your own Toolkit-specific comparisonConfig object, you will need to implement the functions that deal with it, i.e. a toolkit-specific Diffing() method and a toolkit-specific HashString() method.
+
The RevitComparisonConfig is in fact used by the RevitDiffing() method, and, when hashing, by Revit's HashString() method. These two methods can be invoked manually, to deal with Revit Objects, or are automatically invoked by the IDiffing() method when the input objects are Revit objects.
+
+
ParametersExceptions
+
Allows to specify Revit Parameter names that should not be considered while Diffing or computing an object's Hash.
+
This supports * wildcard matching.
+
ParametersToConsider
+
The ParametersToConsider input allows you to add parameter names that should be considered while Diffing or computing an object's Hash.
+
If you add a parameter name in this field, only the value held in that parameter will be considered.
+
If the parameter name that you specified is not found on the object, then no parameter will be considered for that object.
+
This input supports * wildcard matching.
+
ParameterNumericTolerance
+
This works similarly to the PropertyNumericTolerance option, but it applies to Revit Parameters only. See that wiki section for more details on how to use it.
+
ParameterSignificantFigures
+
This works similarly to the PropertySignificantFigures option, but it applies to Revit Parameters only. See that wiki section for more details on how to use it.
+
+
+
For a description of all remaining options, see /Configuring-objects-comparison:-%60ComparisonConfig%60.
+
+
+
+
+
+ Last update:
+ November 23, 2023
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/Guides and Tutorials/Visual Programming with BHoM/Diffing and Hashing/Configuring-objects-comparison-(ComparisonConfig)/index.html b/Guides and Tutorials/Visual Programming with BHoM/Diffing and Hashing/Configuring-objects-comparison-(ComparisonConfig)/index.html
new file mode 100644
index 000000000..97033e673
--- /dev/null
+++ b/Guides and Tutorials/Visual Programming with BHoM/Diffing and Hashing/Configuring-objects-comparison-(ComparisonConfig)/index.html
@@ -0,0 +1,4959 @@
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ Configuring objects comparison (ComparisonConfig) - BHoM documentation
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
As seen in the Diffing and the Hash wiki pages, the real power of object comparison is given by the options that you have when performing it. For this reason, we expose options to customise these operations via the ComparisonConfig object.
+
Here is an example of the ComparisonConfig object seen from Grasshopper:
+
+
There are also "Toolkit-specific" ComparisonConfig objects that extend the available options when dealing with certain objects, for example Revit's RevitComparisonConfig gives further options when dealing with Revit objects. More details on it in its dedicated page.
+
+
Note for developers
+
The "default" comparisonConfig object inherits from the BaseComparisonConfig abstract class, which defines all the "basic" options. This abstract class can be extended by the "Toolkit-specific" comparisonConfigs, so you can include additional options to deal with certain objects in your Toolkit, of which RevitComparisonConfig is an example.
+If you implement your own Toolkit-specific comparisonConfig object, you will need to implement the functions that deal with it too, which are a toolkit-specific Diffing() method (example in Revit), a toolkit-specific HashString() method (example in Revit), and any number of ComparisonInclusion() methods that you might need (example in Revit). More details can be found in the diffing guide for developers.
+
+
Description of the ComparisonConfig options
+
Let's see the ComparisonConfig options in detail.
+
Many of the following examples use the Bar class as a reference object.
You can specify one or more names of properties that you want to ignore (not consider, take as exceptions) when comparing objects.
+This allows to ignore properties and also sub-properties (i.e., properties of properties) of any object.
+This also supports * wildcard within property names, so you can match multiple properties.
+You can specify either the simple name of the property (e.g. StartNode), or the FullName of the property (e.g. BH.oM.Structure.Elements.Bar.StartNode) if you want to be more precise and avoid confusion in case you have properties/sub-properties with the same name.
+
To clarify the above, here are examples using the Bar class as a reference:
+
Property name VS Property Full Name - examples
+
+
Specifying the property name StartNode would ignore the StartNode property. It follows that any sub-property of StartNode will also be ignored.
+
Specifying the property Full NameBH.oM.Structure.Element.Bar.StartNode would achieve the same result, but it is safer than using only the simple name StartNode (and may as well save computation time, like in the case of PropertiesToConsider when Hashing).
+
+
To explain why using the property Full Name is safer, consider the example where you are Diffing a mix of objects which include both Bars and also GraphLinks, both of which own a StartNode property. If you input StartNode in the PropertyExceptions, you must be aware that both properties BH.oM.Structure.Elements.Bar.StartNode and BH.oM.Data.Collections.GraphLink.StartNode will be treated as exceptions, hence ignored. Specifying the property full name is safer.
Again, you can specify the Full Name even for sub-properties, like BH.oM.Structure.Elements.Bar.StartNode.Position.X, and as seen above, this is safer.
+
+
Wildcard examples
+
You can specify * wildcards within property names, so you can match multiple properties with a single text.
+
+
Specifying BH.oM.Structure.Elements.Bar.*.Position.Y would match:
+
BH.oM.Structure.Elements.Bar.StartNode.Position.Y
+
BH.oM.Structure.Elements.Bar.EndNode.Position.Y
+
+
so if this is specified in the PropertyExceptions, those 2 properties will be ignored.
+
+
Specifying BH.oM.Structure.Elements.Bar.*.Y would match:
so if this is specified in the PropertyExceptions, those 4 properties will be ignored.
+
+
+
Again, you can specify only the name instead of the Full Name to obtain the same result, i.e. *.Position.Y would achieve the same result as BH.oM.Structure.Elements.Bar.*.Position.Y when the input objects are only Bars, but you incur in the same risks illustrated above if your input objects are of different types (see property name VS property Full Name).
+
+
+
You can add as many * wildcards as you wish, which is especially handy when you have input objects of different types. Specifying BH.oM.Structure.*.Start*.*Y with both Bars and BarReleases input objects would match all of the following properties:
so if this is specified in the PropertyExceptions, and both Bars and BarReleases are in the input objects, all those 7 properties will be ignored.
+If instead you only had Bars in the input objects, the BH.oM.Structure.*.Start*.*Y would only match the first 3 properties in the list above.
+
PropertiesToConsider
+
The PropertiesToConsider input allows you to add property names that should be considered in the comparison.
+
If you add a property name in this field, only the value held in that property will be considered.
+
If the property name that you specified is not found on the object, then no properties will be considered. Therefore, make sure you input property names that exist on the object.
+
Like for the PropertyExceptions option, you can specify the property names as just the Name (e.g. StartNode), as a Full Name (e.g. BH.oM.Structure.Elements.Bar.StartNode) and/or using wildcards (e.g. BH.oM.Structure.Elements.*.StartNode) to get different matching results. See the section on PropertyExceptions for more details on Full Names and using wildcards.
+
+
Note: Hash performance when using PropertiesToConsider
+
Using PropertiesToConsider can be a resource-intensive operation when calculating an object's Hash (Diffing instead is only slightly affected). To speed up the Hash computation:
+- use only property Full Names as an input to PropertiesToConsider;
+- do not use Wildcards in PropertiesToConsider;
+- limit the amount of property names in PropertiesToConsider.
+
Technical explanation in the details below.
+
+
The Hash of an object is calculated by recursively navigating all properties of the object and taking their value. If you specify some PropertiesToConsider, the property value is only considered if its name matches a property name in there. Then, the recursion continues, and if the current property has some sub-property, the algorithm checks the sub-property, and so on. When checking a certain property, the algorithm doesn't know the names of all its sub-properties until it gets there.
+
If the property names include Wildcards or are not specified as Full Names, there can be situations where some nested sub-property needs to be considered, but then its parent's siblings must be ignored. When computing the Hash(), we are traversing the property tree of the object, but we do not know all the properties during the traversal. For example, say that your input object is a Bar, and you want to consider exclusively properties that match *.Name. The situation is:
+
+
One way of solving this could be to "consider" all the properties of the object while doing the Hash, and, at the end, cull away those that do not match any PropertiesToConsider. This basically is like saying that we build our knowledge of the object while computing its Hash. However, this can be wasteful for two reasons:
+- speed: many other operations may be done to the object values being considered when computing the Hash (e.g. numerical approximations);
+- space: we would need to store in RAM many values that we may never use.
+
For this reason, we instead build the knowledge of the property tree before computing the hash; in other words, we traverse the entire object once and look at the property names, and get the "consequent" PropertiesToConsider, i.e. all the properties of the object that match your wildcard or partial property name, translated to their Full Name form. By using Full Names, it the becomes easy for the Hash algorithm to consider or not a property: just check if the property full name matches any of the PropertiesToConsider.
+
The cost of this can be cut by specifying Full Names instead of just the name (i.e. BH.oM.Structure.Elements.Bar.StartNode instead of StartNode) and avoiding wildcards * when using PropertiesToConsider.
Setting a key name in CustomDataKeysExceptions means that if that key is found on in the CustomData dictionary of an object, it will not be considered.
+
This option does not support wildcard, unlike PropertyExceptions.
+
CustomDataKeysToConsider
+
Setting a key name in CustomDataKeysToConsider means that only that dictionary key will be considered amongst any BHoMObject's CustomData. If no matching CustomData key is found on the object, no CustomData entry will be considered.
+
This option does not support wildcard.
+
TypeExceptions
+
You can input any Type here. Any object or property of corresponding types will not be considered.
+
NamespaceExceptions
+
You can input the name of any namespace here. An example of a namespace is BH.oM.Structure.Elements.
+
Any object or property that belong to the corresponding namespace will not be considered.
+
This option does not support wildcard.
+
MaxNesting
+
This option limits the depth of property discovery when computing Diffing or an object's Hash.
+
Properties whose Nesting Level is equal to or larger than MaxNesting will not be considered.
+
+
Property Nesting Level definition
+
The nesting level of a property defines how deep we are in the object property tree.
+For example:
+- a Bar'sStartNode property is at Nesting Level 1 (it is also called a "top-level" property of the object)
+- a Bar'sStartNode.Position property is at Nesting Level 2, because Position is a sub-property of StartNode.
+
+
Top-level properties are at level 1. Setting MaxNesting to 1 will make the Hash or Diffing consider only top-level properties. Setting MaxNesting to 0 will disregard any object property (only the class name will end up in the Hash, and Diffing will not find any differences).
+
This option is better used as a safety measure to avoid excessive computation time when diffing or computing the hash for objects that may occasionally have one or more deeply nested properties of which we do not care about.
+
MaxPropertyDifferences
+
When Diffing, this indicates the maximum number of Property Differences that will be collected and returned. This setting does not affect the Hash calculation (in fact, this option should be moved in DiffingConfig instead).
+
You can not control what properties are returned and what remain excluded due to this numeric limit. Hence, this option is better used as a safety measure to avoid excessive computation time when:
+- we care about finding different objects, but do not care about what properties did change between them, although a better and faster option for this would be to use DiffingConfig.EnablePropertyDiffing set to false;
+- we are okay with finding only the first n differences between objects, whatever those may be.
+
NumericTolerance
+
This option sets the Numeric tolerance applied when considering any numerical property of objects.
+For example, a Bar'sStartNode.Position.X property is a numerical property.
+
When a numerical property is encountered, the function BH.Engine.Base.RoundWithTolerance() is applied to its value, which becomes approximated with the given NumericTolerance.
+
Therefore, when Hashing, the property's approximate value will be recorded in the Hash. When Diffing, the property approximate value will be used for the comparison.
+
If both NumericTolerance and SignificantFigures are provided in the ComparisonConfig, both approximations are executed, and the largest approximation among all (the least precise number) is registered.
+
+
RoundWithTolerance() details
+
The function BH.Engine.Base.RoundWithTolerance() will approximate the input value with the given tolerance, which is done by rounding (to floor) to the nearest tolerance multiplier.
+
Some examples of RoundWithTolerance() are:
+
+
+
+
Input number
+
Input Tolerance
+
Result (approximated number)
+
+
+
+
+
12
+
20
+
0
+
+
+
121
+
2
+
120
+
+
+
1.2345
+
1.1
+
1.1
+
+
+
0.014
+
0.01
+
0.01
+
+
+
0.014
+
0.02
+
0
+
+
+
+
+
PropertyNumericTolerance
+
This option applies a given Numeric Tolerance to a specific property, therefore considering its value approximated using the given tolerance.
+
In order to use it, you have to create and input in PropertyNumericTolerance one or more NamedNumericTolerance objects, where you set:
+- the Name of the property you want to target; this supports * wildcard usage;
+- the Tolerance that you want to apply to the given property.
+
The approximation will work exactly as per the NumericTolerance option, only it will target exclusively the properties with the name specified via the NamedNumericTolerance objects.
+
If a match is found, this takes precedence over the NumericTolerance option.
+If conflicting values/multiple matches are found among the ComparisonConfig's numerical precision options, the largest approximation among all (least precise number) is registered.
+
The Name field supports wildcard usage. Some examples:
+- BH.oM.Geometry.Vector: applies the corresponding tolerance to all numerical properties of Vectors, i.e. X, Y, Z
+- BH.oM.Structure.Elements.*.Position: applies the corresponding tolerance to all numerical properties of properties named Position under any Structural Element, e.g. Bar.Position.X, Bar.Position.Y, Bar.Position.Z and at the same time also Node.Position.X, Node.Position.Y,Node.Position.Z.
+
SignificantFigures
+
This option sets the Significant Figures considered for any numerical property of objects.
+For example, a Bar'sStartNode.Position.X property is a numerical property.
+
When a numerical property is encountered, the function BH.Engine.Base.RoundToSignificantFigures() is applied to its value, which becomes approximated with the given SignificantFigures.
+
Therefore, when Hashing, the property's approximate value will be recorded in the Hash. When Diffing, the property approximate value will be used for the comparison.
+
If both SignificantFigures and NumericTolerance are provided in the ComparisonConfig, both approximations are executed, and the largest approximation among all (the least precise number) is registered.
This option applies the approximation with given Significant Figures to a specific property.
+
In order to use it, you have to create and input in PropertyNumericTolerance one or more NamedSignificantFigures objects, where you set:
+- the Name of the property you want to target; this supports * wildcard usage;
+- the SignificantFigures that you want to consider when evaluating the given property.
If a match is found, this takes precedence over the SignificantFigures option.
+If conflicting values/multiple matches are found among the ComparisonConfig's numerical precision options, the largest approximation among all (least precise number) is registered.
+
The Name field supports wildcard usage. Some examples:
+- BH.oM.Geometry.Vector: applies the corresponding tolerance to all numerical properties of Vectors, i.e. X, Y, Z
+- BH.oM.Structure.Elements.*.Position: applies the corresponding tolerance to all numerical properties of properties named Position under any Structural Element, e.g. Bar.Position.X, Bar.Position.Y, Bar.Position.Z and at the same time also Node.Position.X, Node.Position.Y,Node.Position.Z.
+
+
+
+
+
+ Last update:
+ November 23, 2023
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git "a/Guides and Tutorials/Visual Programming with BHoM/Diffing and Hashing/Diffing-\342\200\223-tracking-changes-in-your-BHoM-objects/index.html" "b/Guides and Tutorials/Visual Programming with BHoM/Diffing and Hashing/Diffing-\342\200\223-tracking-changes-in-your-BHoM-objects/index.html"
new file mode 100644
index 000000000..157afb7e0
--- /dev/null
+++ "b/Guides and Tutorials/Visual Programming with BHoM/Diffing and Hashing/Diffing-\342\200\223-tracking-changes-in-your-BHoM-objects/index.html"
@@ -0,0 +1,4580 @@
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ Diffing: tracking changes between objects - BHoM documentation
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
Diffing is the process of determining what changed between two sets of objects.
+
Typically, the two sets of objects are two versions of the same thing (of a pulled Revit model, of a Structural Model that we want to Push to an Adapter, etc), in which case Diffing can effectively be used as a Version Control tool.
The Diffing_Engine gives many ways to perform diffing on sets of objects. Let's see them.
+
IDiffing method
+
The most versatile method for diffing is the BH.Engine.Diffing.Compute.Diffing() method, also called IDiffing. Ideally, you should always use this Diffing method, although other alternatives exist for specific cases (see Other diffing methods below). A detailed technical explanation of the IDiffing can be found in the guide for developers.
+
This method can be found in any UI by simply looking for diffing. See the below for an example file:
pastObject: objects belonging to a past version, a version that precedes the followingObjects's version.
+
followingObjects: objects belonging to a following version, a version that was created after the pastObject's version.
+
diffingConfig: configurations for the diffing, where you can set your ComparisonConfig object, see below.
+
+
The output of every diffing method is always a diff object, which we will describe in a section below.
+
+
How diffing works: identifiers
+
The IDiffing, like all diffing methods, relies on an identifier assigned to each object, which can be used to match objects, so it knows which to compare to which.
+
The identifer is generally a unique "signature" assigned to each object, and this signature is assumed to remain always the same even if the object is modified.
+
The identifier is typically stored on objects after they have been Pulled from an Adapter. This means that the IDiffing works best with objects pulled from a BHoM Adapter that stores the object Id on the object (most of them do).
+
In case no Identifier can be found on the objects, the IDiffing attempts to use alternative methods e.g. compare one-by-one the objects; it will give you a note if this happens.
+
(Technical sidenote: the identifier object is of a type called IPersistentAdapterId, searched in the object's Fragments. More on this in the diffing guide for developers.)
+
+
The Diffing output: the Diff object
+
The output of any Diffing method is an object of type Diff. The diff output can be Exploded to reveal all the available outputs:
AddedObjects: objects present in the second set that are not present in the first set.
+
RemovedObjects: objects not present in the second set that were present in the first set.
+
ModifiedObjects: objects that are recognised as present both in the first set and the second set, but that have some property that is different. The rules that were used to recognise modification are in the DiffingConfig.ComparisonConfig.
+
UnchangedObjects: objects that are recognised as the same in the first and second set.
+
ModifiedObjectsDifferences: all the differences found between the two input sets of objects.
+
DiffingConfig: the specific instance of DiffingConfig that was used to calculate this Diff. Useful in scenarios where a Diff is stored and later inspected.
+
+
The ModifiedObjectDifferences output contains a List of ObjectDifferences objects, one for each modified object, that contains information about the modified objects. These can be further Exploded:
PastObject: the object in the pastObjs set that was identified as modified (i.e., a different version of the same object was found in the followingObjs set).
+
FollowingObject: the object in the followingObjs set that was identified as modified (i.e., a different version of the same object was found in the pastObjs set).
+
Differences: all the differences found between the two versions of the modified object. This is a List of PropertyDifference objects, one for each difference found on the modified object.
+
+
Finally, exploding the Differences object, we find:
(Sorry, missing a more accurate screenshot here -- just keep exploding as in the grasshopper example)
+
+
+
+
+
+
+
DisplayName: name given to the difference found. This is generally the PropertyName (name of the property that changed), but it can also indicate other things. For example, if a ComparisonInclusion() extension method is defined for some of the input objects (like it happens for Revit's RevitParameters), then the DisplayName may also contain some specific naming useful to identify the difference (in the case of RevitParameter, this is the name of the RevitParameter that changed in the modified object).
+An example of a DisplayName could be StartNode.Position.X (given a modified object of type BH.oM.Structure.Elements.Bar).
+
PastValue: the modified value in the PastObject.
+
FollowingValue: the modified value in the FollowingObject.
+
FullName: this is the modified property Full Name. An object difference can always be linked to a precise object property that is different; this is given in the Full Name form, which includes the namespace. An example of this could be BH.oM.Structure.Elements.Bar.StartNode.Position.X. Note that this FullName can be significantly different from DisplayName (as happens for RevitParameters, where the Full Name will be something like e.g. BH.oM.Adapters.Revit.Parameters[3].RevitParameter.Value).
+
+
Options for the diffing: DiffingConfig (and ComparisonConfig)
+
The DiffingConfig object can be attached to any Diffing method and allows you to specify options for the Diffing comparison.
+
+The Diffing config has the following inputs:
+
+
ComparisonConfig allows you to specify all the object comparison options; it has many settings, please see its dedicated page.
+
EnablePropertyDiffing: optional, defaults to true. If disabled, Diffing does not checks all the property-level differences, running much faster but potentially ignoring important changes.
+
IncludedUnchangedObjects: optional, defaults to true. When diffing large sets of objects, you may want to not include the objects that did not change in the diffing output, to save RAM.
+
AllowDuplicateIds: optional, defaults to false. The diffing generally uses identifiers to track "who is who" and decide which objects to compare; in such operations, duplicates should never be allowed, but there could be edge cases where it is useful to keep them.
+
+
Other Diffing methods
+
In addition to the main Diffing method IDiffing(), there are several other methods that can be used to perform Diffing. These are a bit more advanced and should be used only for specific cases. The additional diffing methods can be found in the Compute folder of Diffing_Engine.
DiffWithFragmentId() and DiffWithCustomDataKeyId()
+
These two methods are "ID-based" diffing methods. They simply retrieve an Identifier associated to the input objects, and use it to match objects from the pastObjs set to objects in the followingObjs set, deciding who should be compared to who.
+
+
The DiffWithFragmentId() retrieves object identifiers from the objects' Fragments. You can specify which Fragment you want to get the ID from, and which property of the fragment is the ID.
+
The DiffWithCustomDataKeyId() retrieves object identifiers from the objects' CustomData dictionary. You can specify which dictionary Key you want to get the ID from.
+
+
Both method then call the DiffWithCustomIds() to perform the comparison with the extracted Ids, see below.
Two input objects sets that you want to compare, pastObjs and followingObjs;
+
Two input identifiers sets, pastObjsIds and followingObjsIds, with the Ids associated to the pastObjs and followingObjs.
+
+
You can specify some null Ids in the pastObjsIds and followingObjsIds; however these two lists must have the same number of elements as pastObjs and followingObjs, respectively.
+
The IDs are then used to match the objects from the pastObjs set to objects in the followingObjs set, to decide who should be compared to who:
+
+
If an object in the pastObjs does not have a corresponding object in the followingObjs set, it means that it has been deleted in the following version, so it is identified as "Removed" (old).
+
If an object in the followingObjs does not have a corresponding object in the pastObjs set, it means that it has been deleted in the past version, so it is identified as "Added" (new).
+
If an object in the pastObjs matches by ID an object in the followingObjs, then it is identified as "Modified" (it changed between the two versions). This means that the two objects will be compared and all their differences will be found. This is done by invoking the ObjectDifferences() method, that is explained in detail here.
+
+
DiffOneByOne()
+
The DiffOneByOne() method simply takes two input lists, pastObjs and followingObjects, and these have the objects in the same identical order. It then simply compares each object one-by-one. If matched objects are equal, they are "Unchanged", otherwise, they are "Modified" and their property difference is returned.
+
For this reason, this method is not able to discover "Added" (new) or "Removed" (old) objects.
+
DiffWithHash()
+
The DiffWithHash() method simply does a Venn Diagram of the input objects' Hashes:
+
+
The Venn Diagram is computed by means of a HashComparer, which simply means that the Hash of all input objects gets computed.
+
If objects with the same hash are found they are identified as "Unchanged"; otherwise, objects are either "Added" (new) or "Removed" (old) depending if their hash exists exclusively in following or past set. For this reason, this method is not able to discover "Modified" objects.
+
The Hash is leveraged by this method so you are able to customise how the diffing behaves by specifying a ComparisonConfig options in the DiffingConfig.
+
DiffRevisions
+
This method was designed for the AECDeltas workflow and is currently not widely used.
+
It essentially expects the input objects to be wrapped into a Revision object, which is useful to attach additional Versioning properties to them.
+The Revisions can then be provided as an input to DiffRevisions(), and the logic works very similarly to the other diffing methods seen above.
+
+
+
+
+
+ Last update:
+ November 23, 2023
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git "a/Guides and Tutorials/Visual Programming with BHoM/Diffing and Hashing/Hash-\342\200\223-an-object's-identity/index.html" "b/Guides and Tutorials/Visual Programming with BHoM/Diffing and Hashing/Hash-\342\200\223-an-object's-identity/index.html"
new file mode 100644
index 000000000..8b5089b4b
--- /dev/null
+++ "b/Guides and Tutorials/Visual Programming with BHoM/Diffing and Hashing/Hash-\342\200\223-an-object's-identity/index.html"
@@ -0,0 +1,4348 @@
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ Hash – an object's identity - BHoM documentation
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
A Hash, sometimes called also hash code, is the "unique signature" or "identity" of an object.
+
The hash is generally a string (a text) containing alphanumeric characters. It is composed by applying a Hash algorithm to an object, which parses the input object, all its properties, and the values assigned to those properties. The returned hash is a "combination of all the variables" present in the object. It follows that its most important feature is that the hash remains the same as long as the object remains the same (under certain criteria, which can be customised).
+
The Hash for objects can be used in many different kinds of comparisons, or for any case where a unique identification of an object is needed. Examples include:
+- you can compute hash for objects to quickly and safely compare objects with each other, so you can determine unique objects (i.e., what objects are duplicates or not)
+- you can compare an object's hash at different points in time. You can store the hash of an object in a certain moment; then, some time later, you can check if the object changed (i.e., even a slight variation of one of its properties) by checking if its hash changed.
+
BHoM's Hash() method
+
BHoM exposes a Hash() method to calculate the Hash for any BHoM object (any object implementing the IObject interface).
+
This method is defined in the base BHoM_Engine: BH.Engine.Base.Query.Hash(). Here is an example of how the method can be used in Grasshopper:
+
+
The method returns a string, a textual Hash code that uniquely represents the input object.
+
This method's most parameters are:
+- the IObject you want to get the Hash for;
+- comparisonConfig configurations on how the Hash is calculated (see the dedicated section);
+- hashFromFragment: if instead of computing the Hash of the object, you want to retrieve a Hash that was previously stored in the object's Fragments.
+ In order to set the HashFragment on a BHoMObject's Fragment, you can use the SetHashFrament() method:
+
Hash ComparisonConfig: options to compute the Hash
+
The real potential of the Hash algorithm is given by its customisation options, which we call ComparisonConfig (comparison configurations).
+
For example, you may want to configure the Hash algorithm so it only considers numerical properties that changed within a certain tolerance. This way, you can determine if an object changed by looking at changes in the Hash, and you will be alerted only if the change was a numerical change greater than the given tolerance.
+
For this reasons, we expose many configurations in a ComparisonConfig object:
Note that some ComparisonConfig options may slow down the computation of the Hash, which becomes particularly noticeable when hashing large sets of objects. An option that may have particular negative impact when computing the Hash is PropertiesToConsider, as explained here.
+
+
+
Note for developers: customising an object's Hash
+
If you want a specific object to be Hashed in a particular way, you can implement a specific HashString() method for that object in your Toolkit.

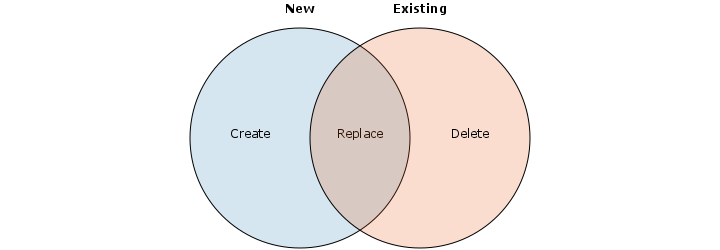

 +
+




















 +
+
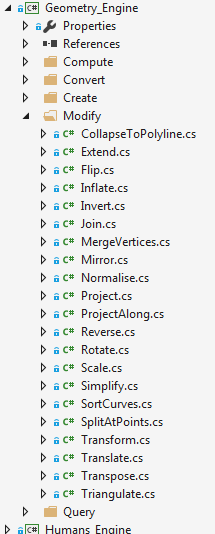
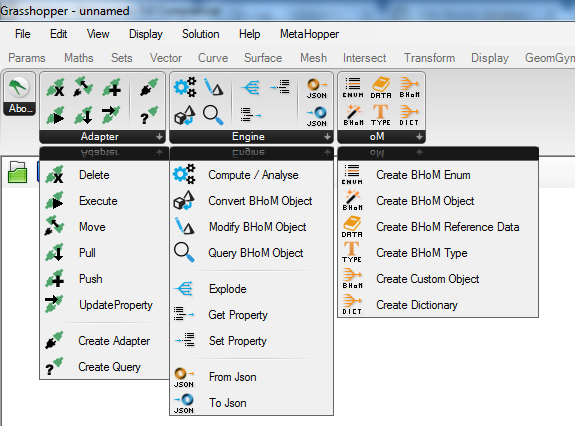
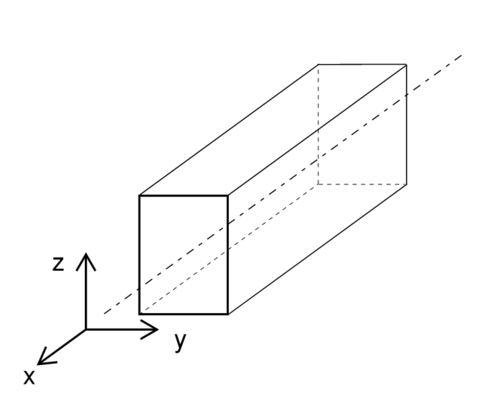
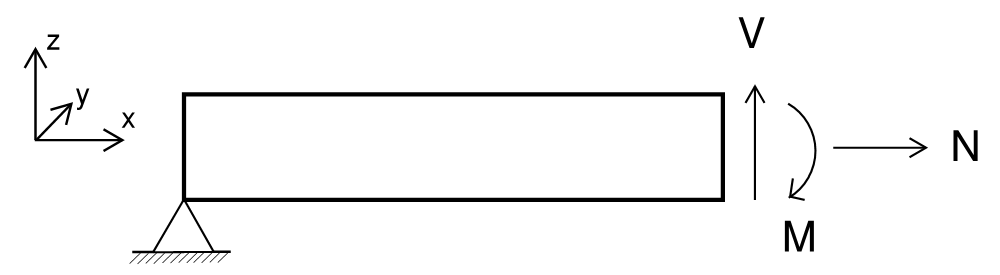
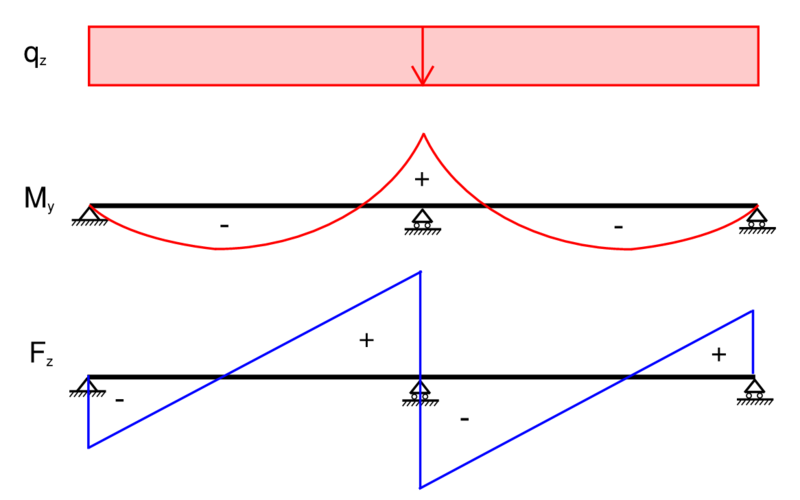
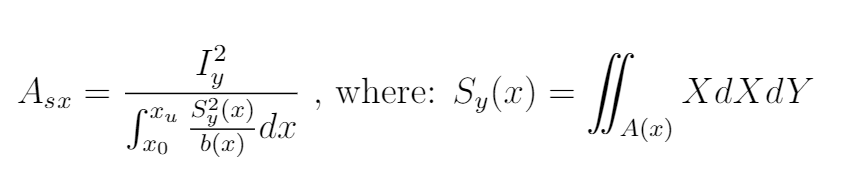
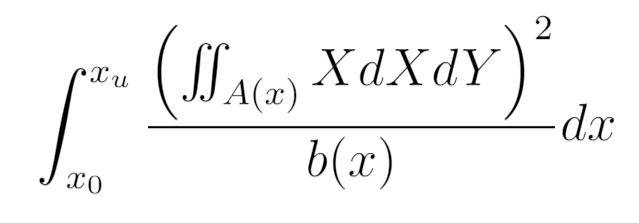
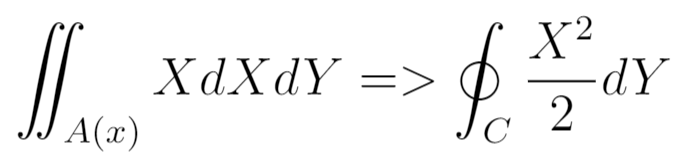
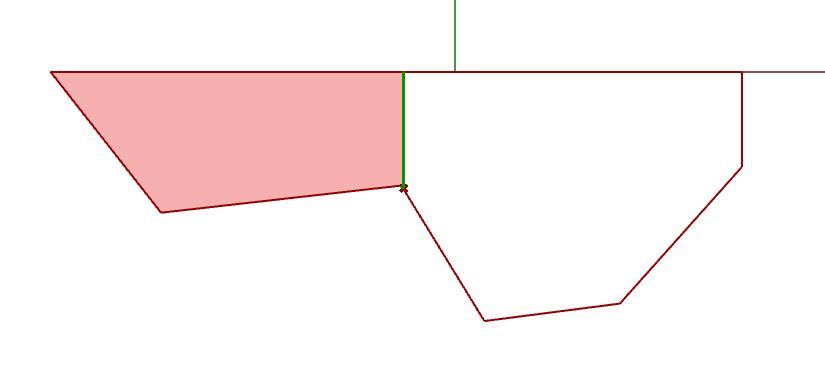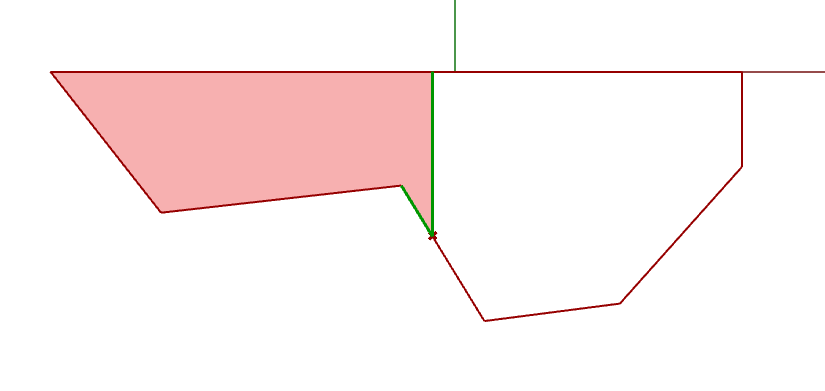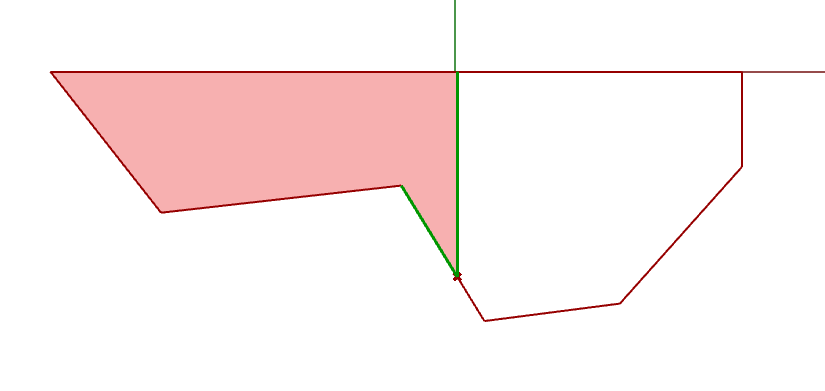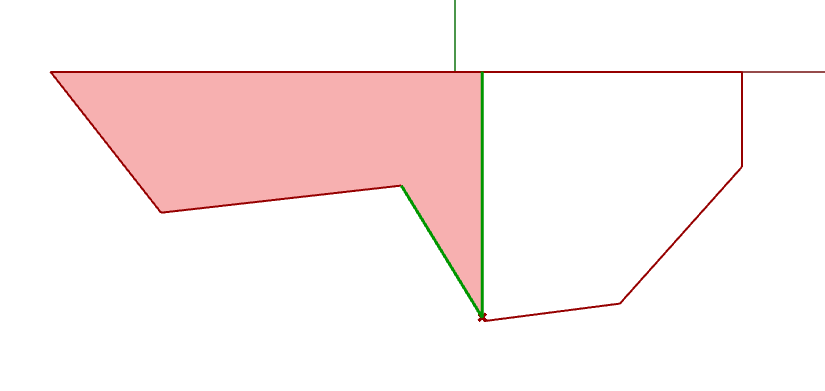
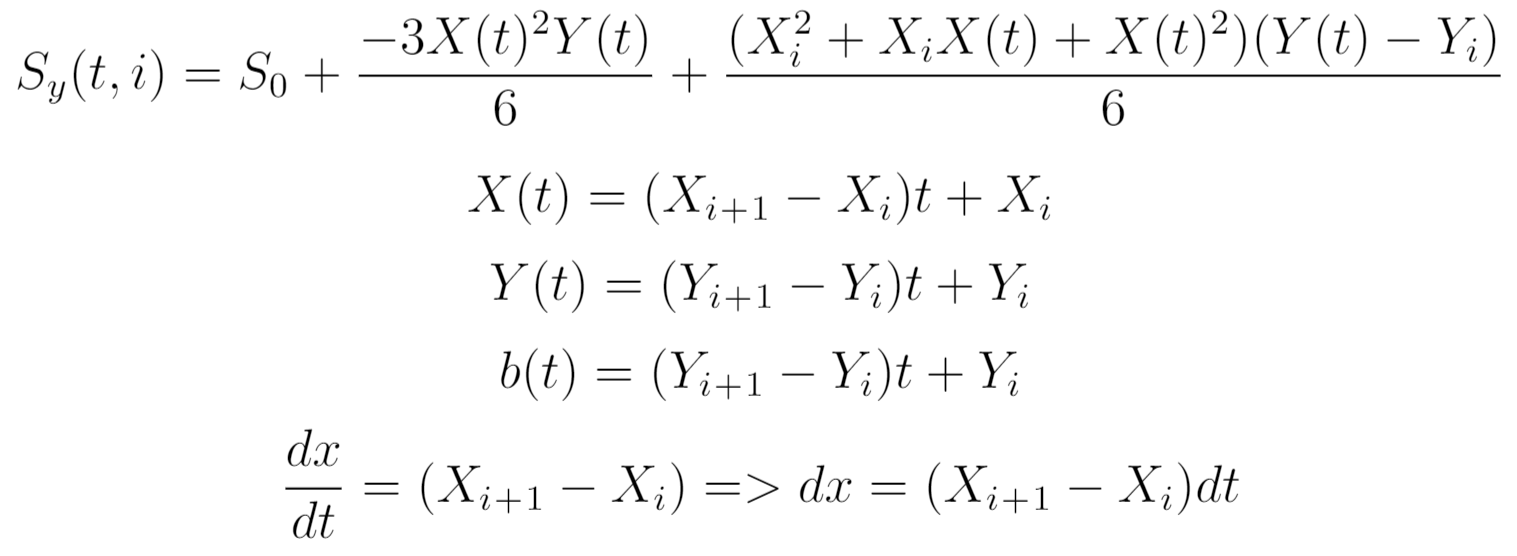
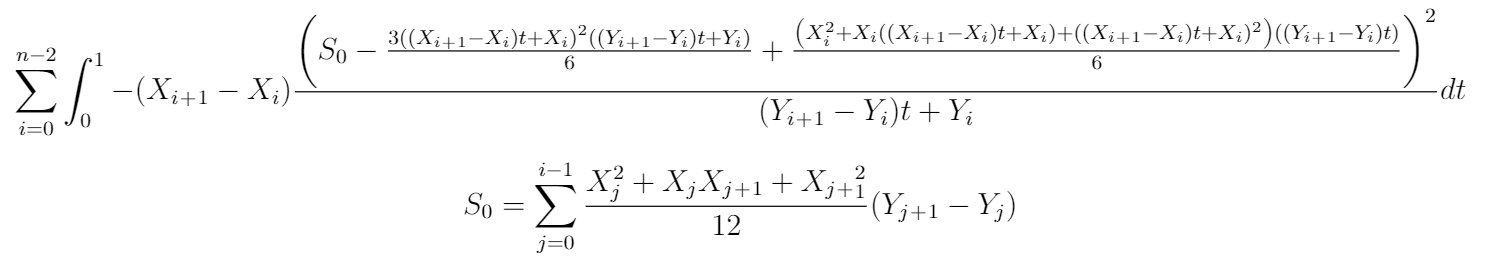
 +
+ 
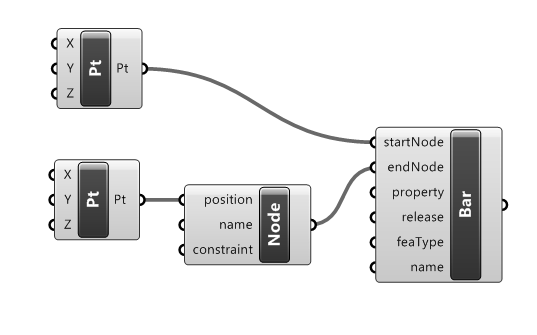
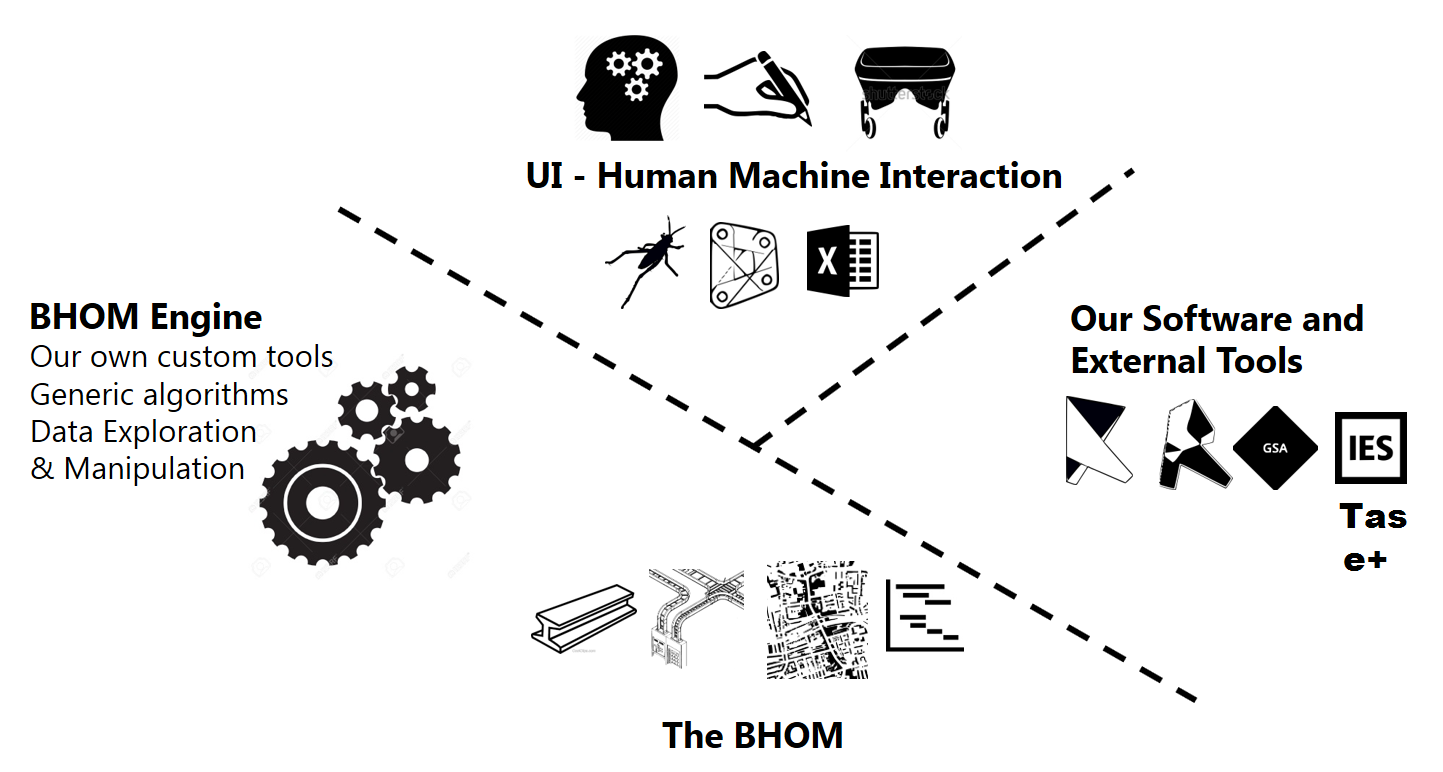

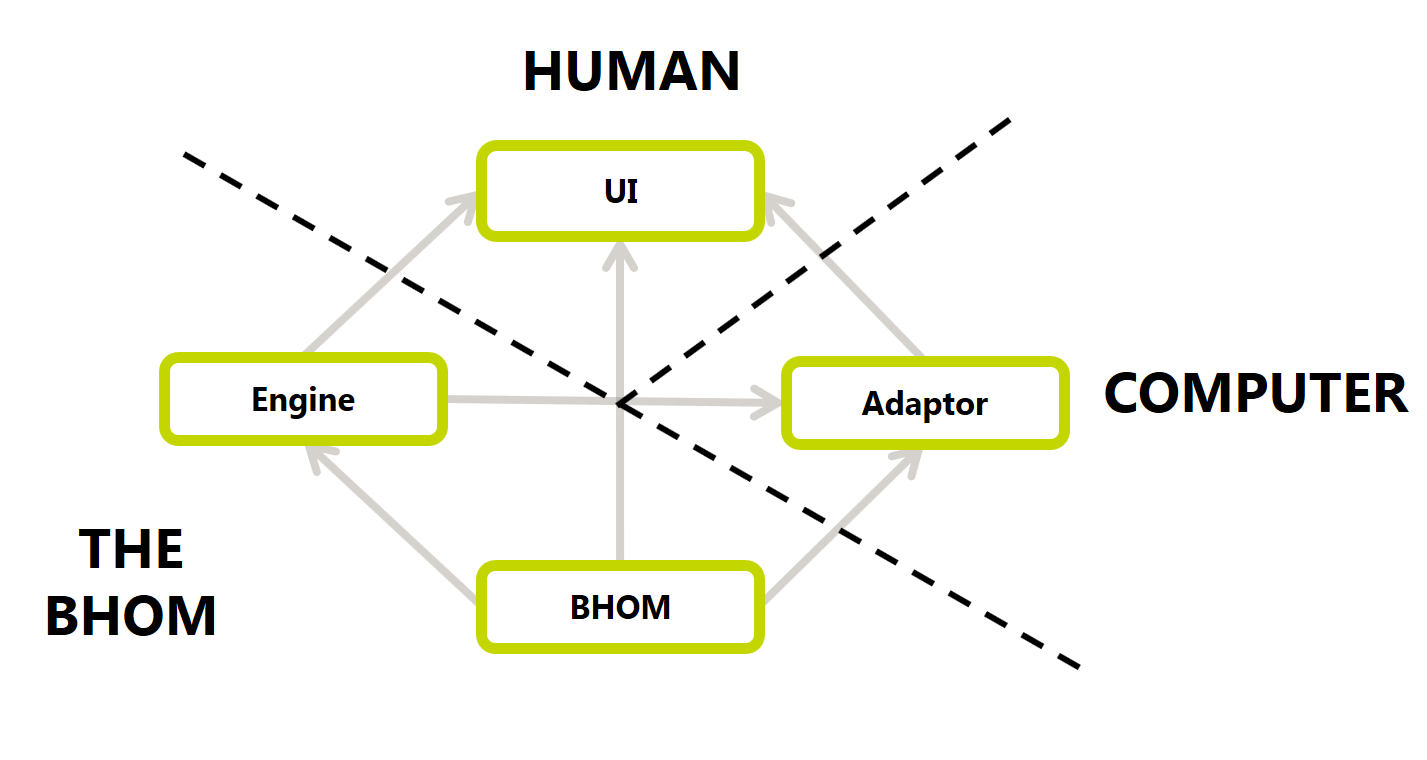
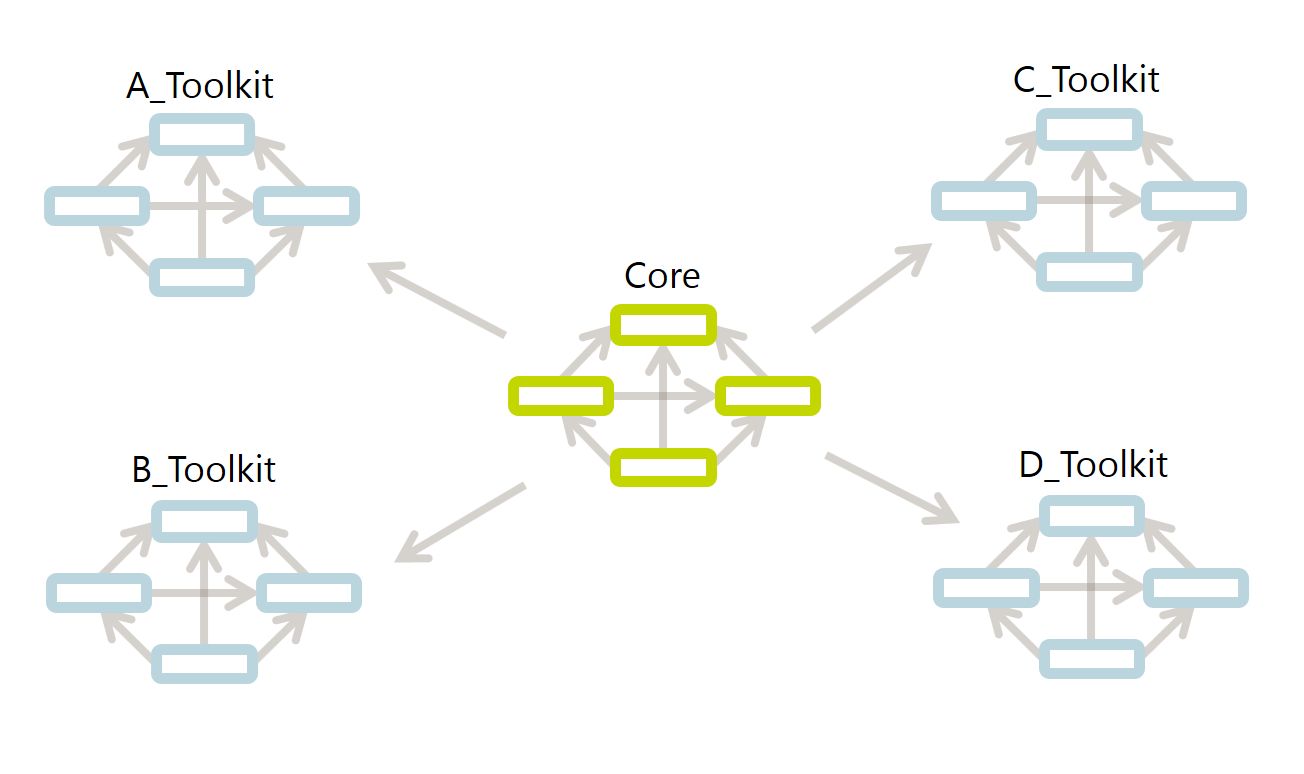
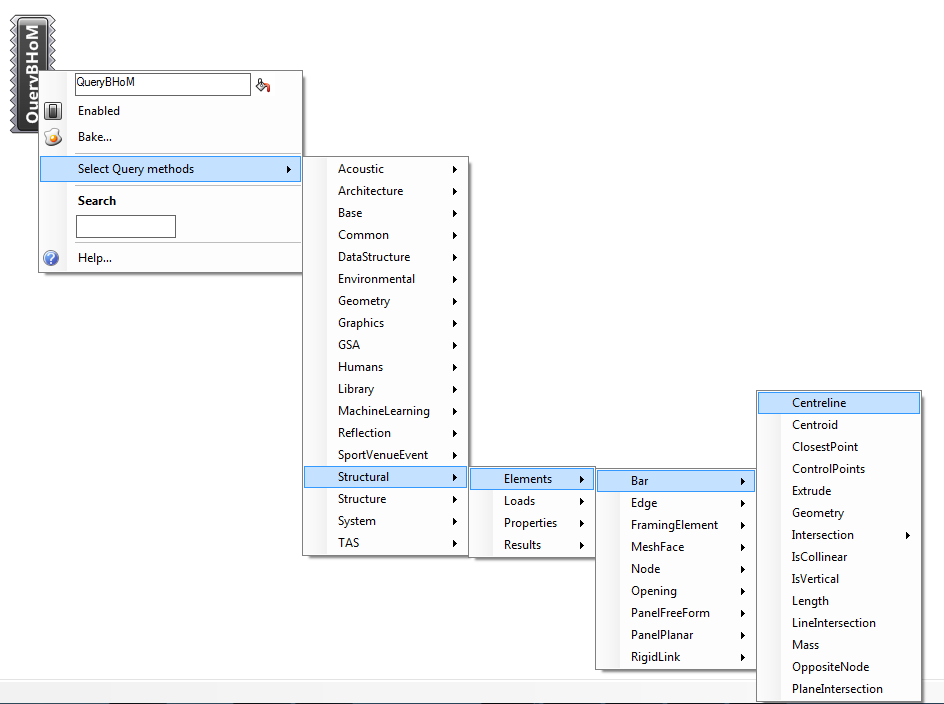
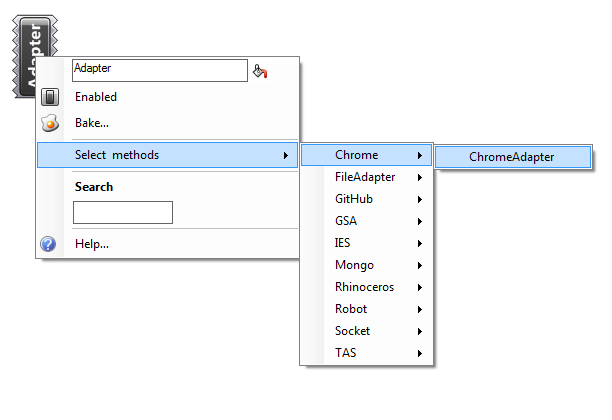
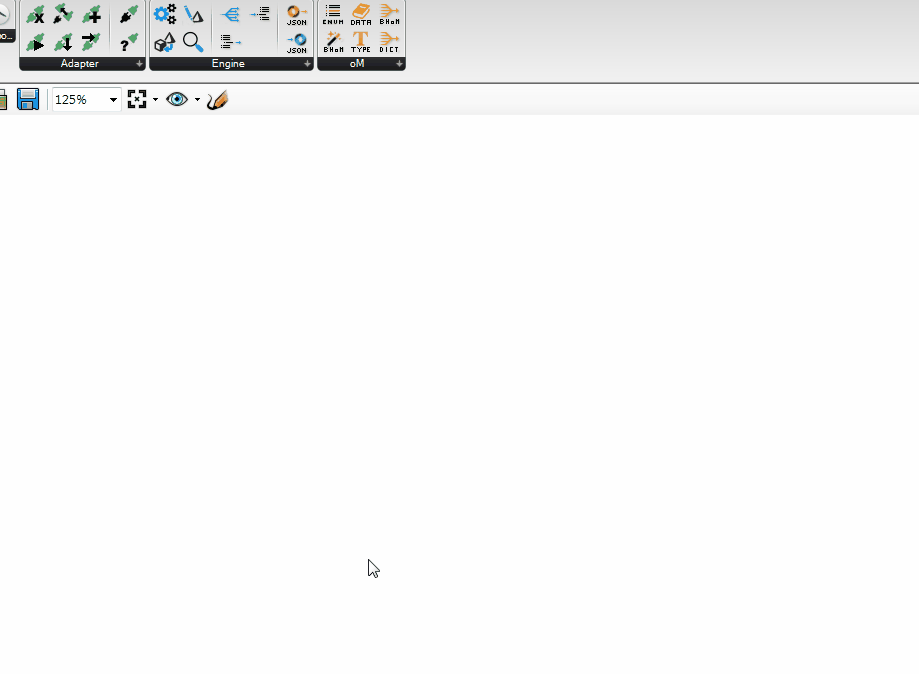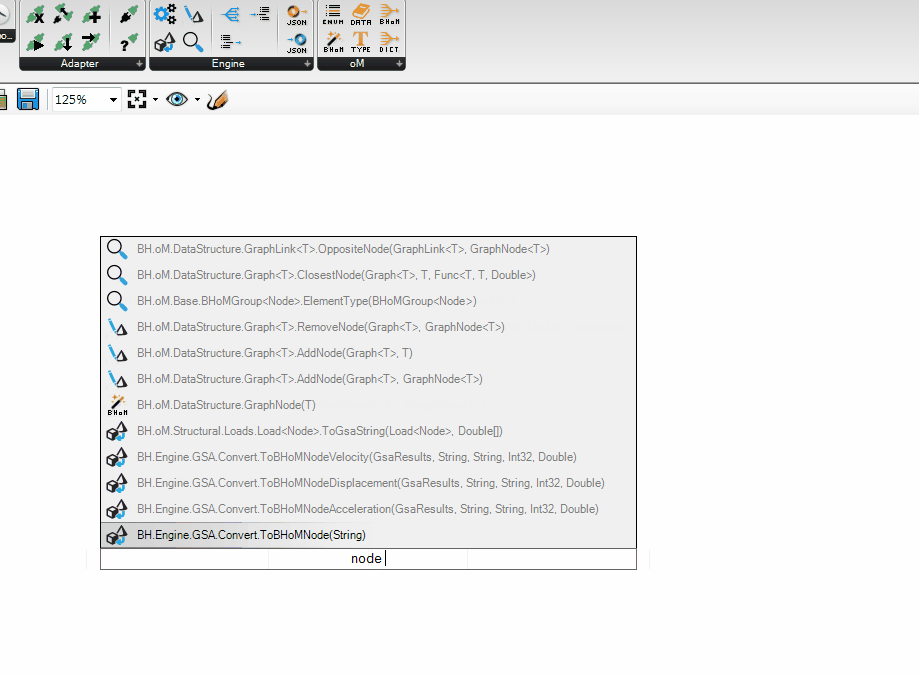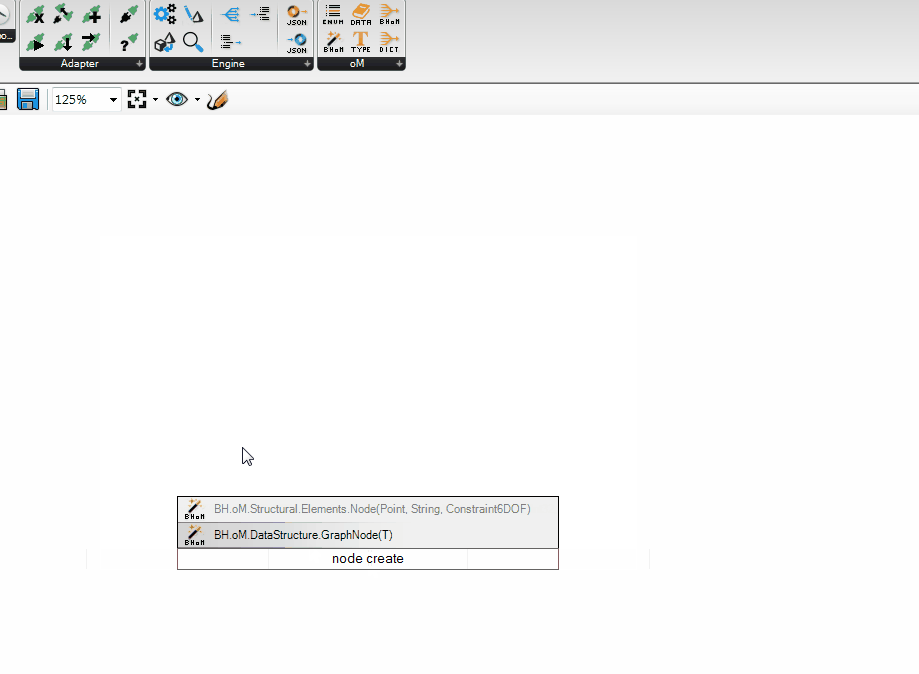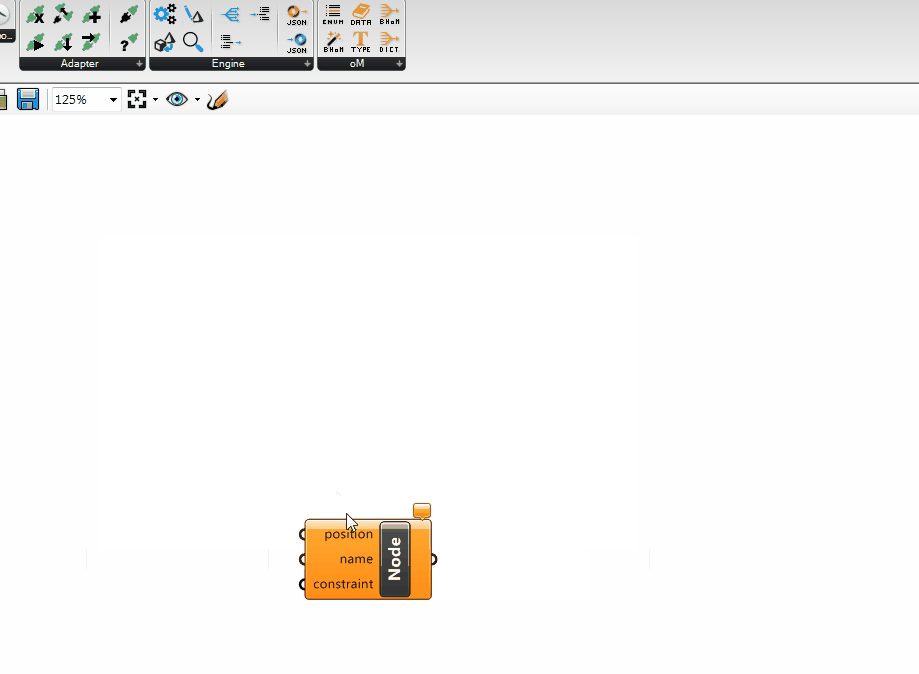
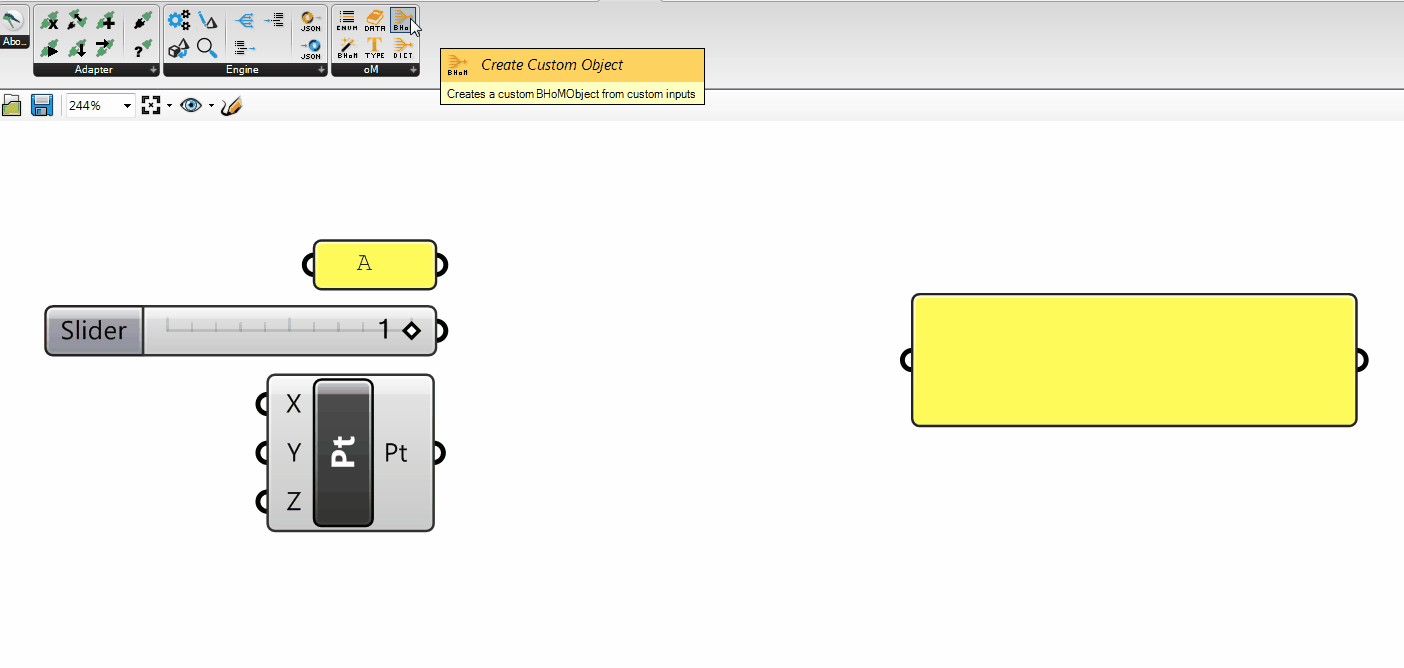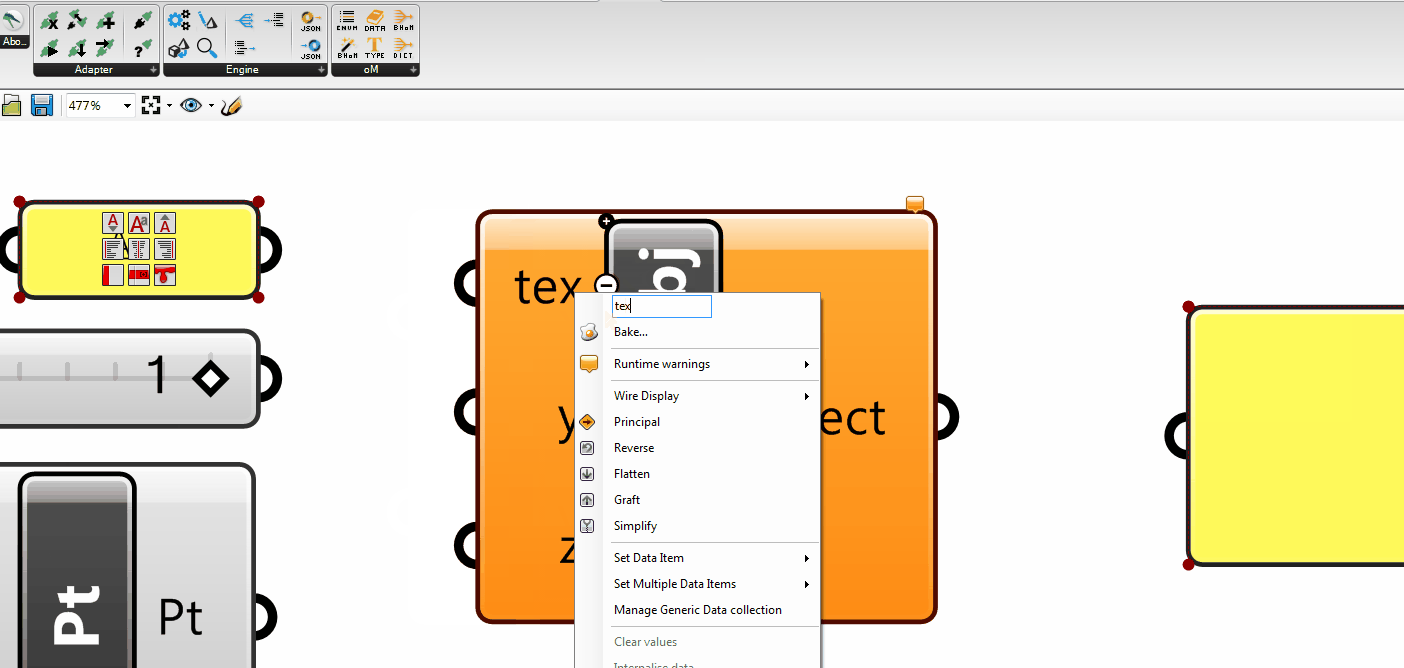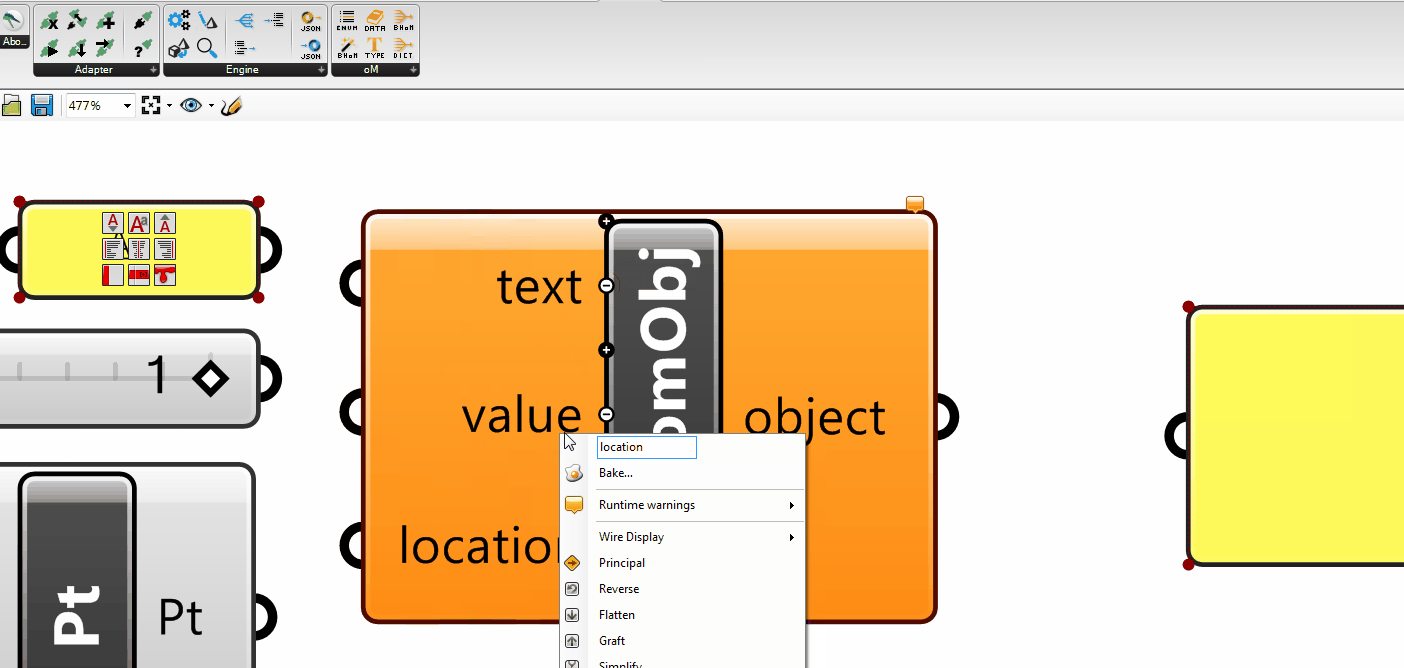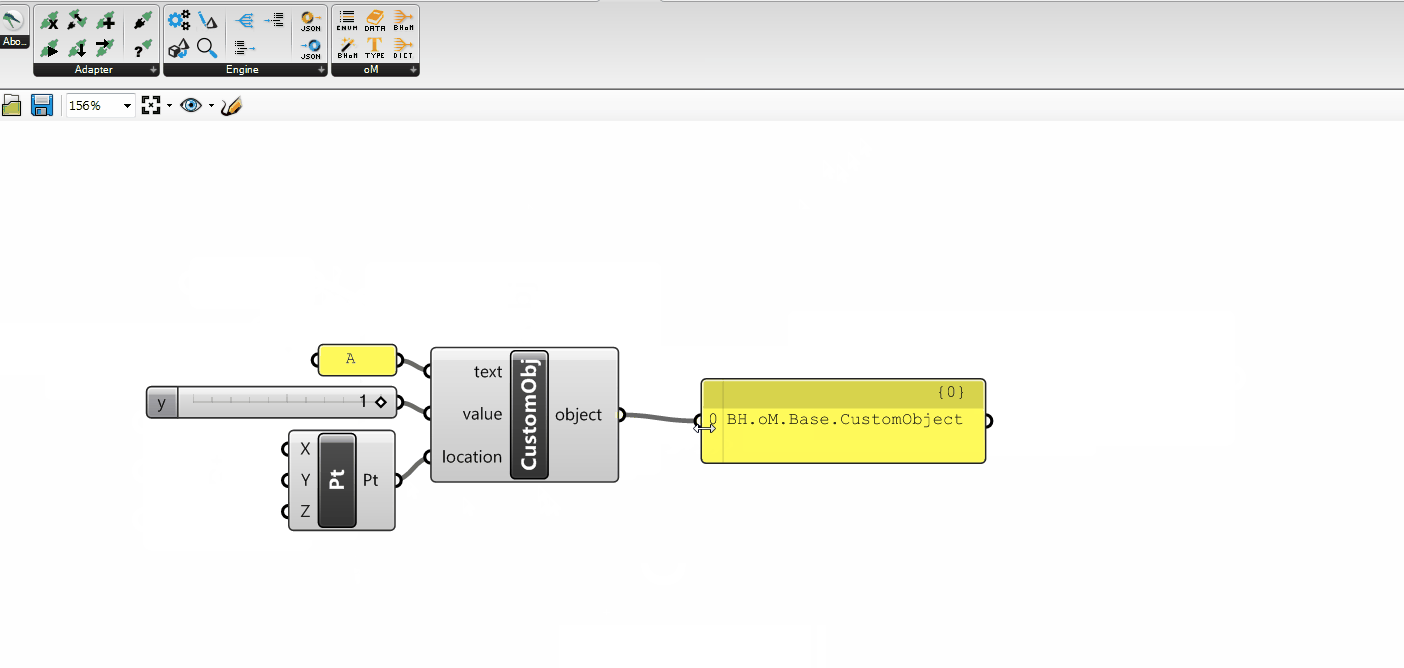

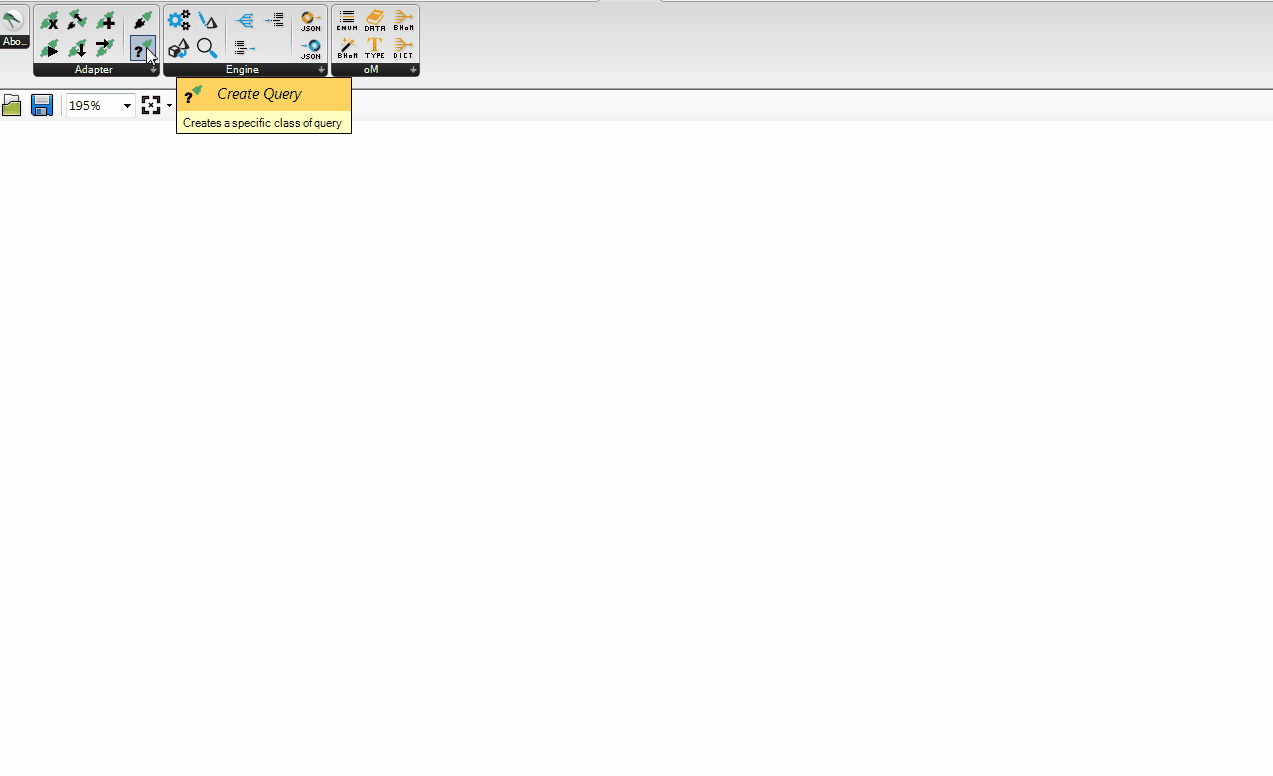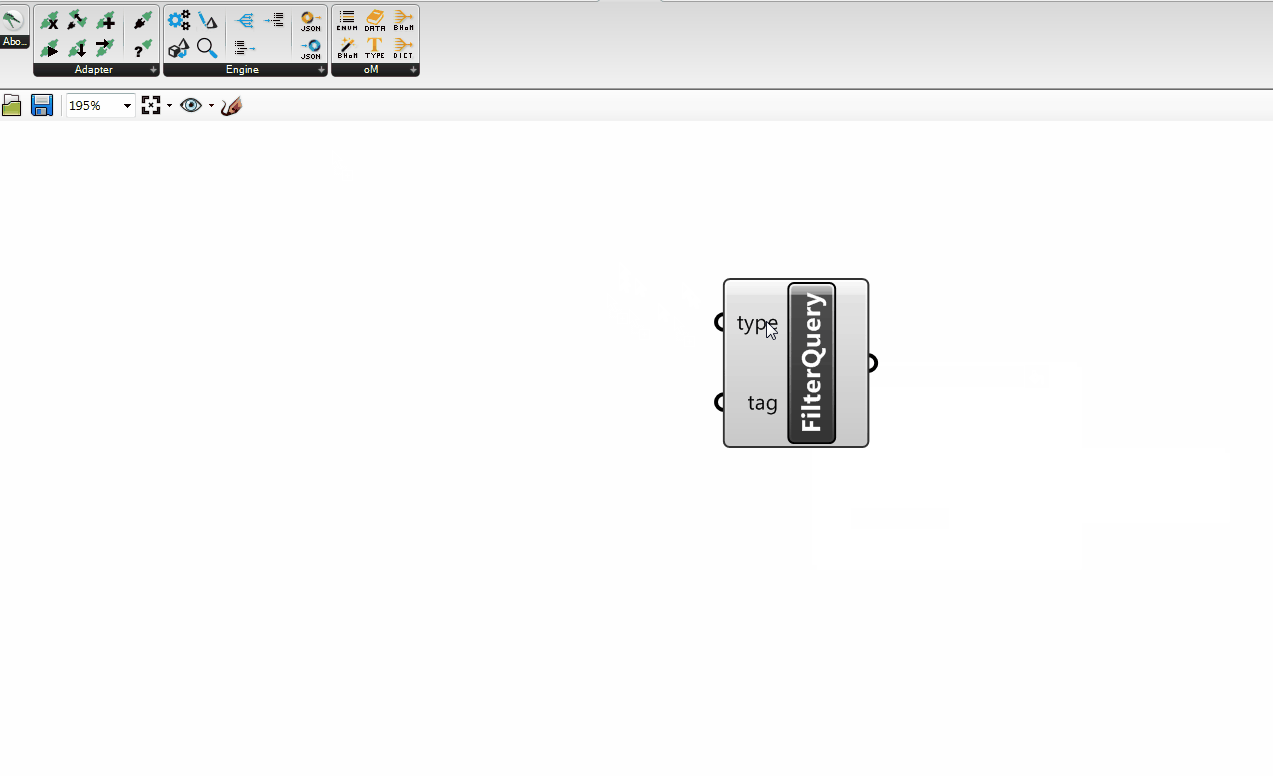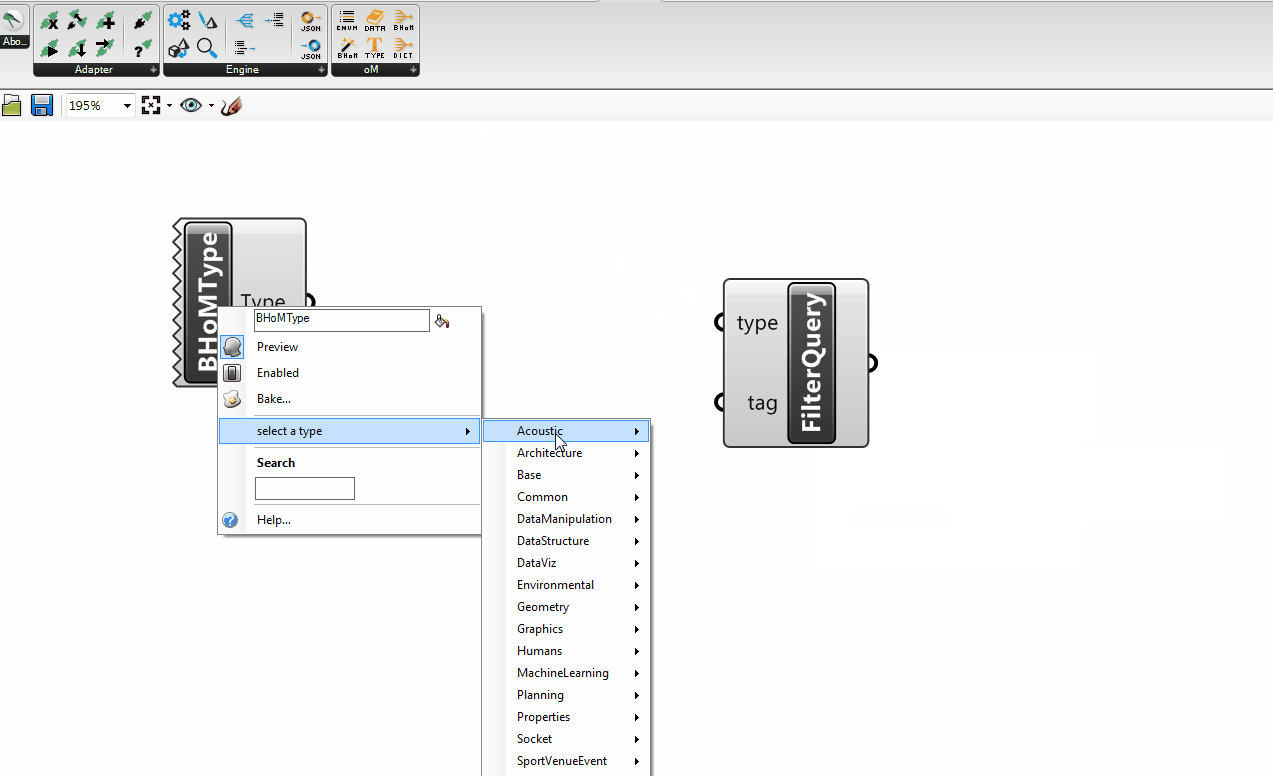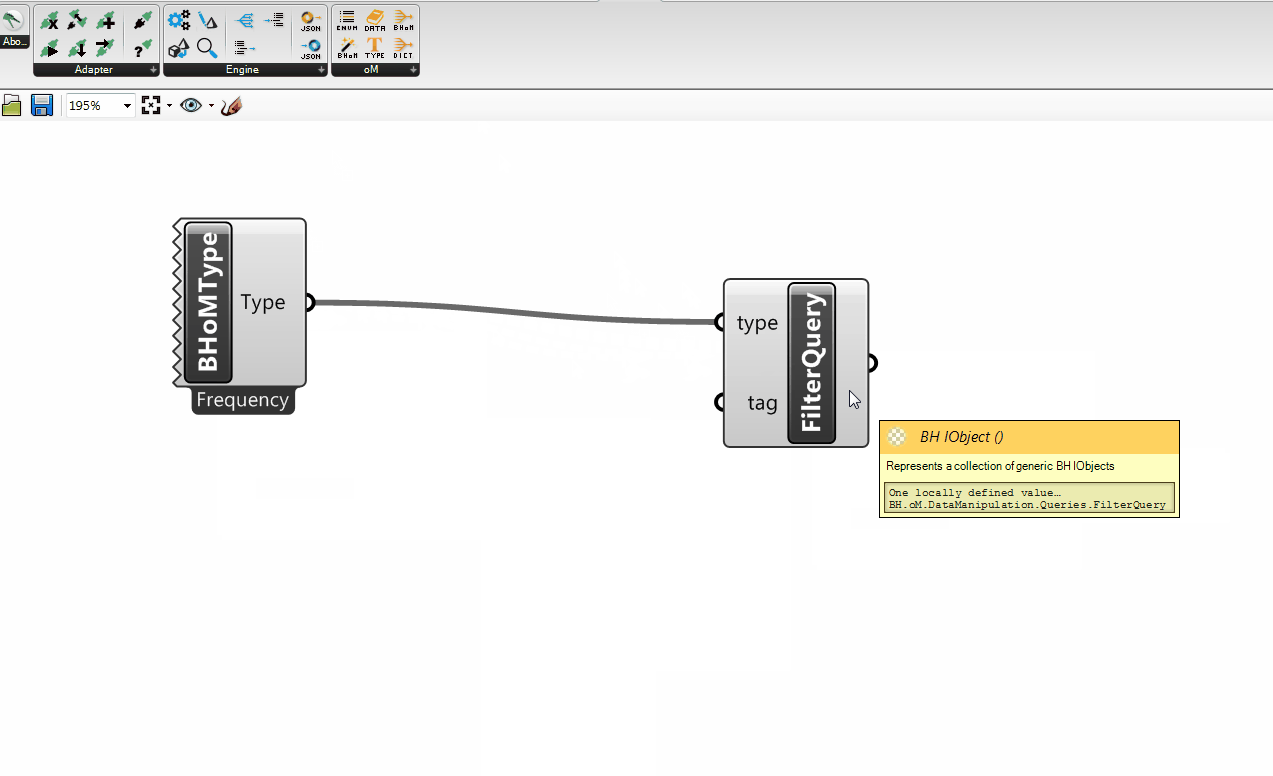
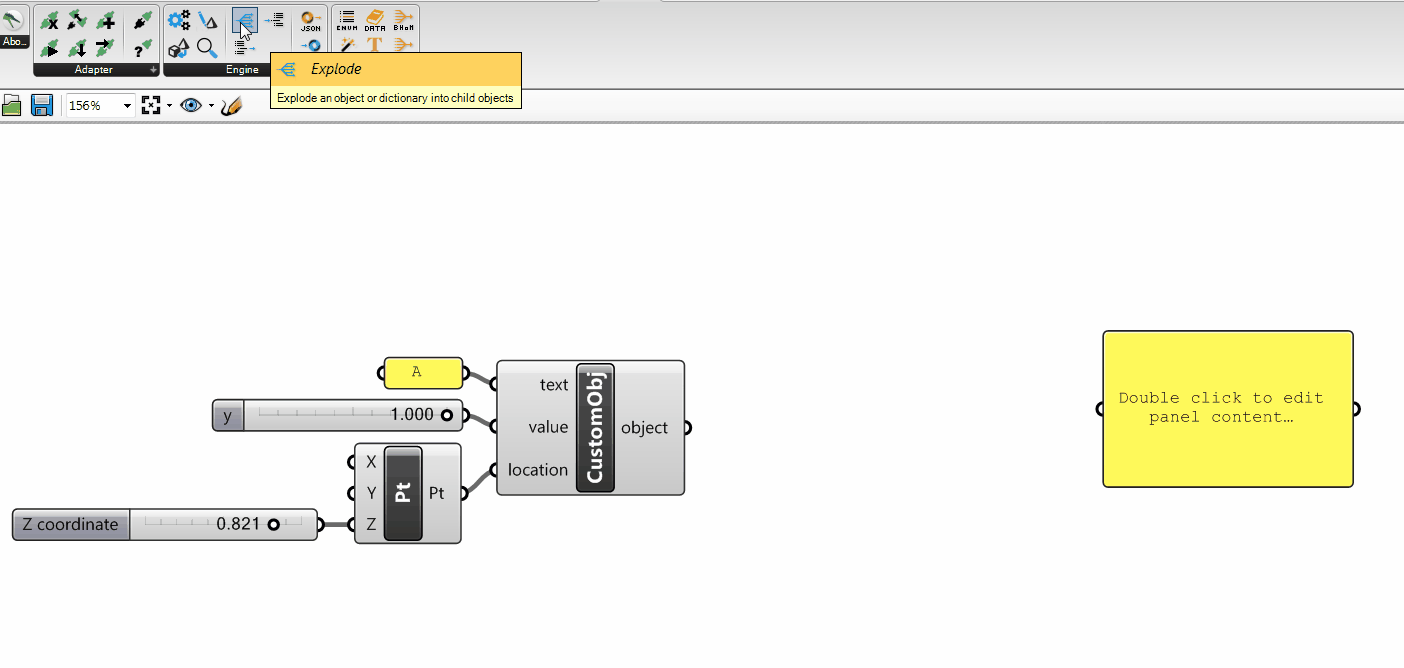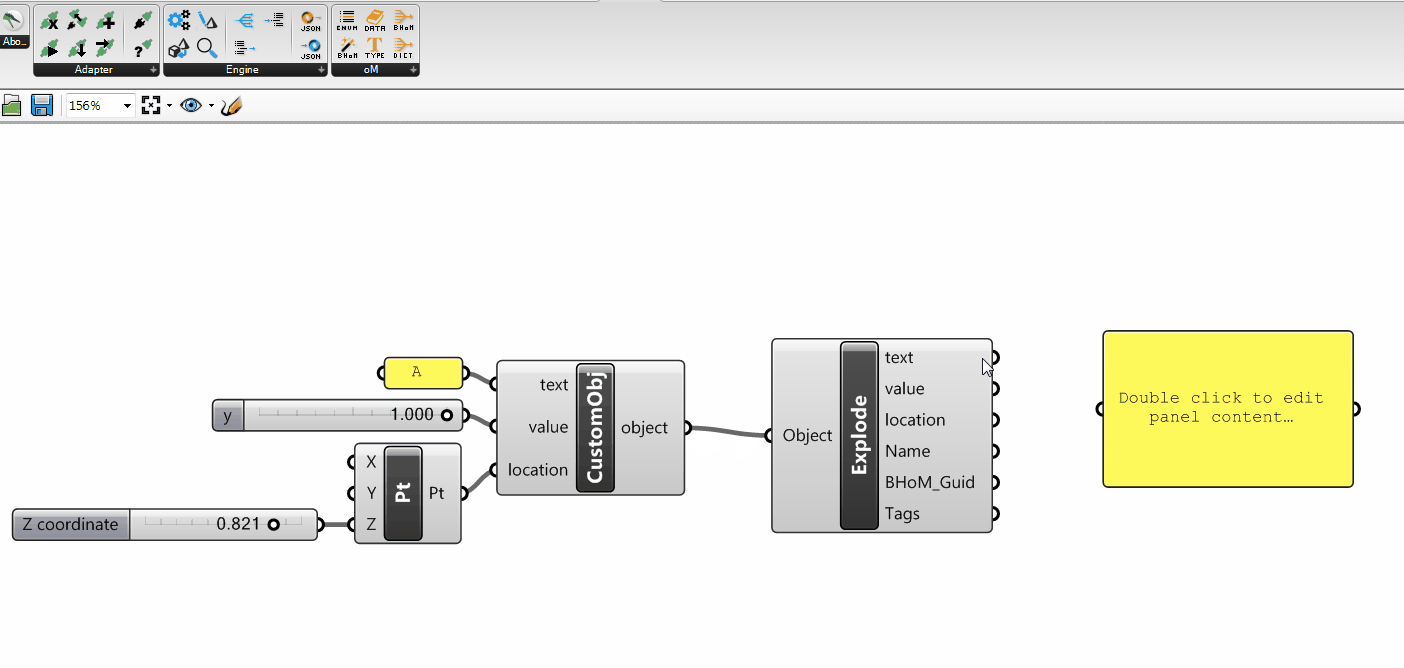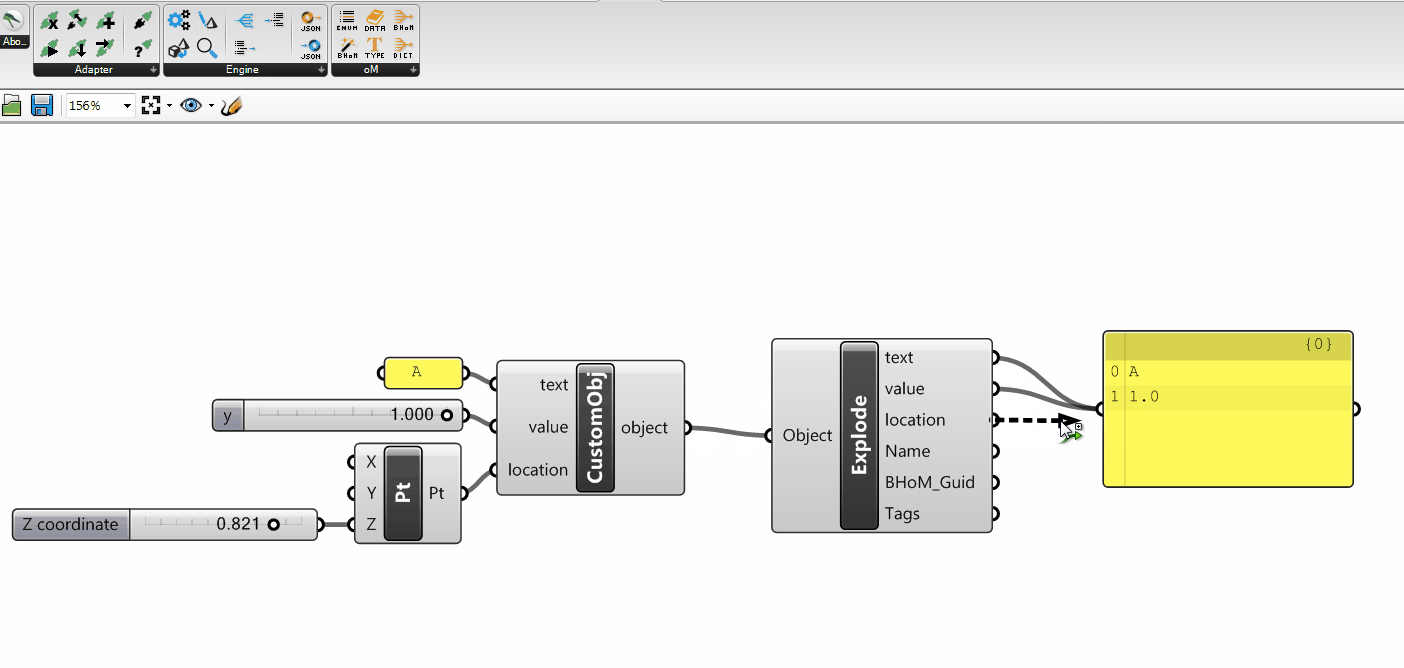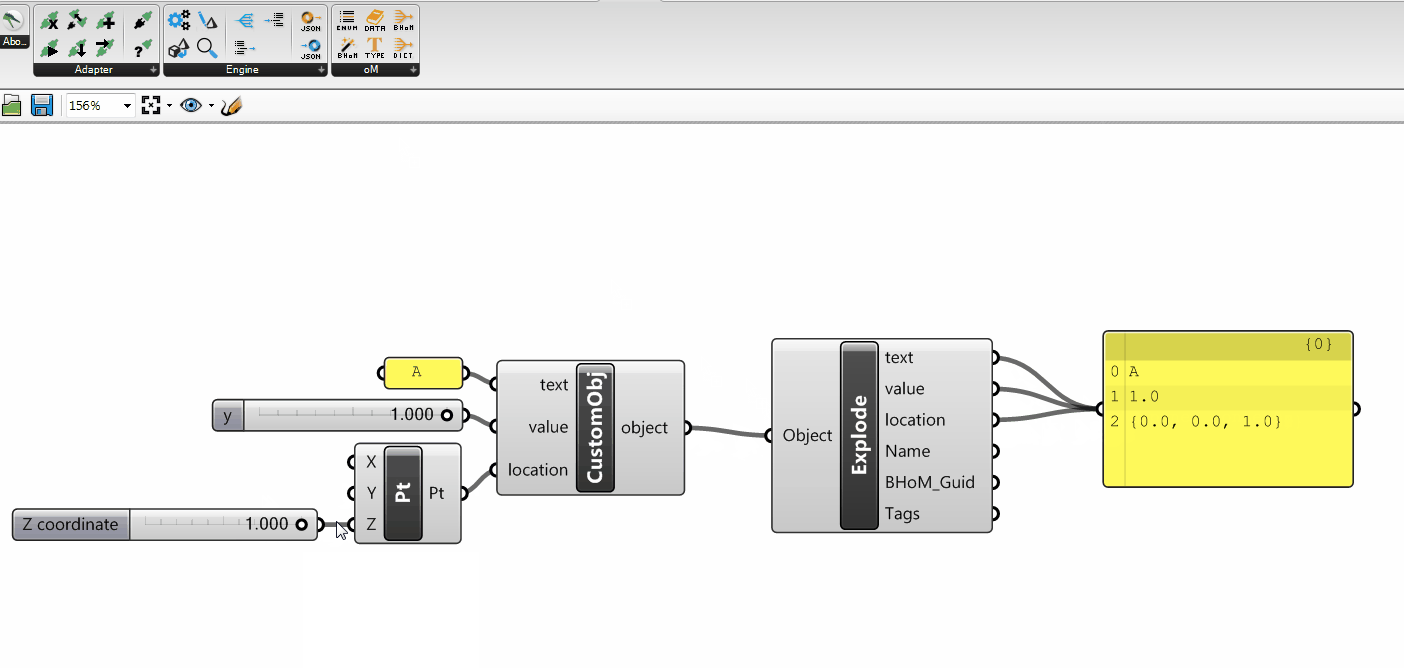
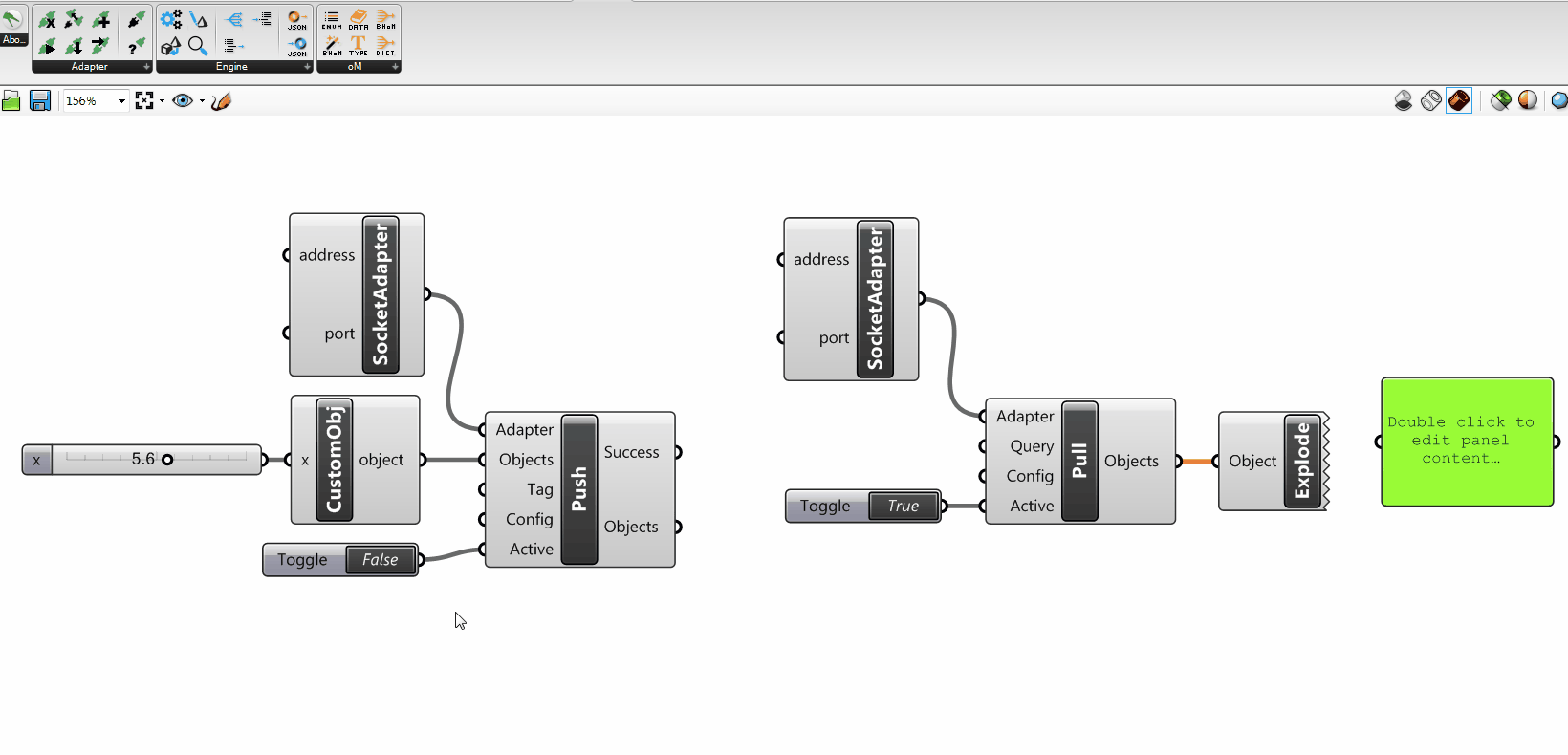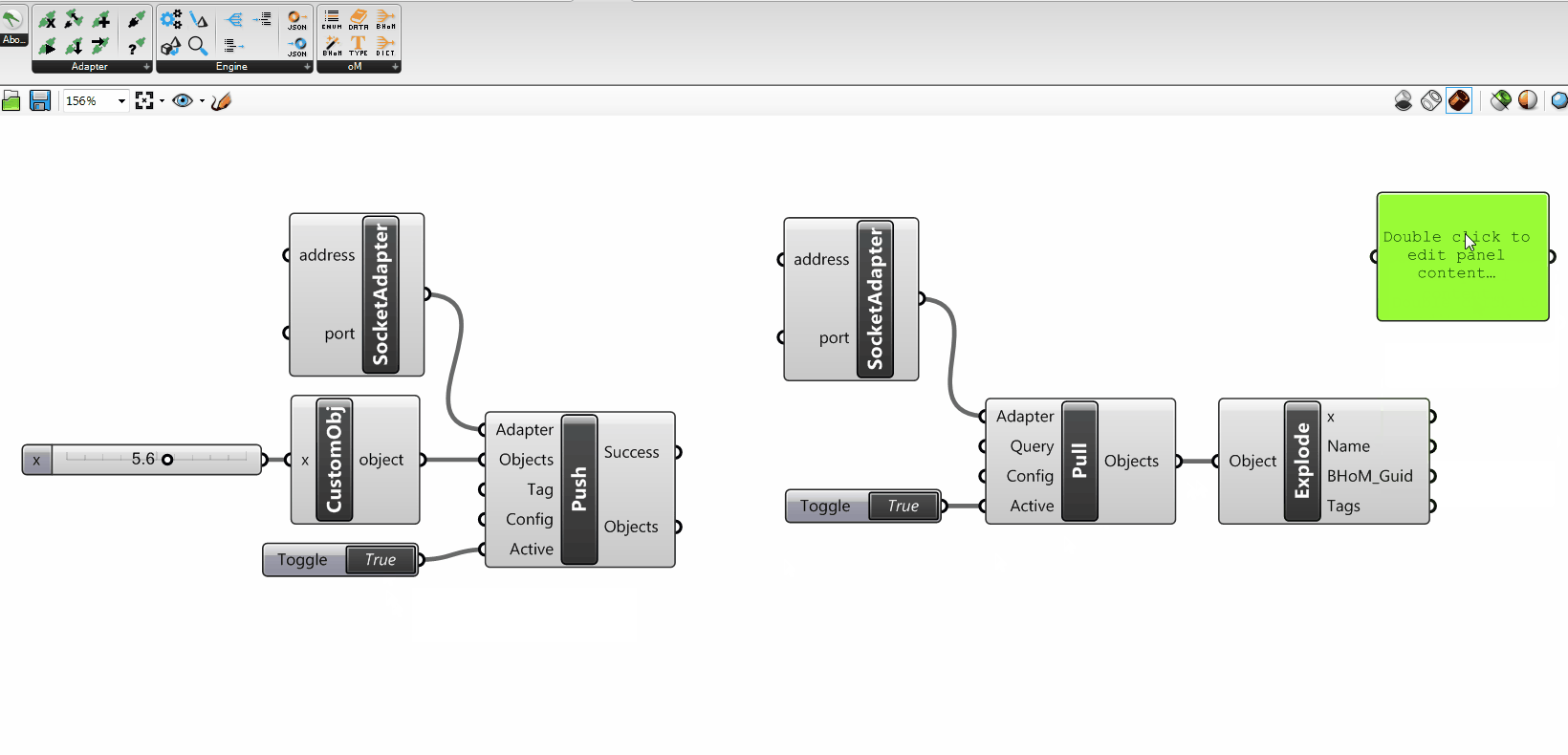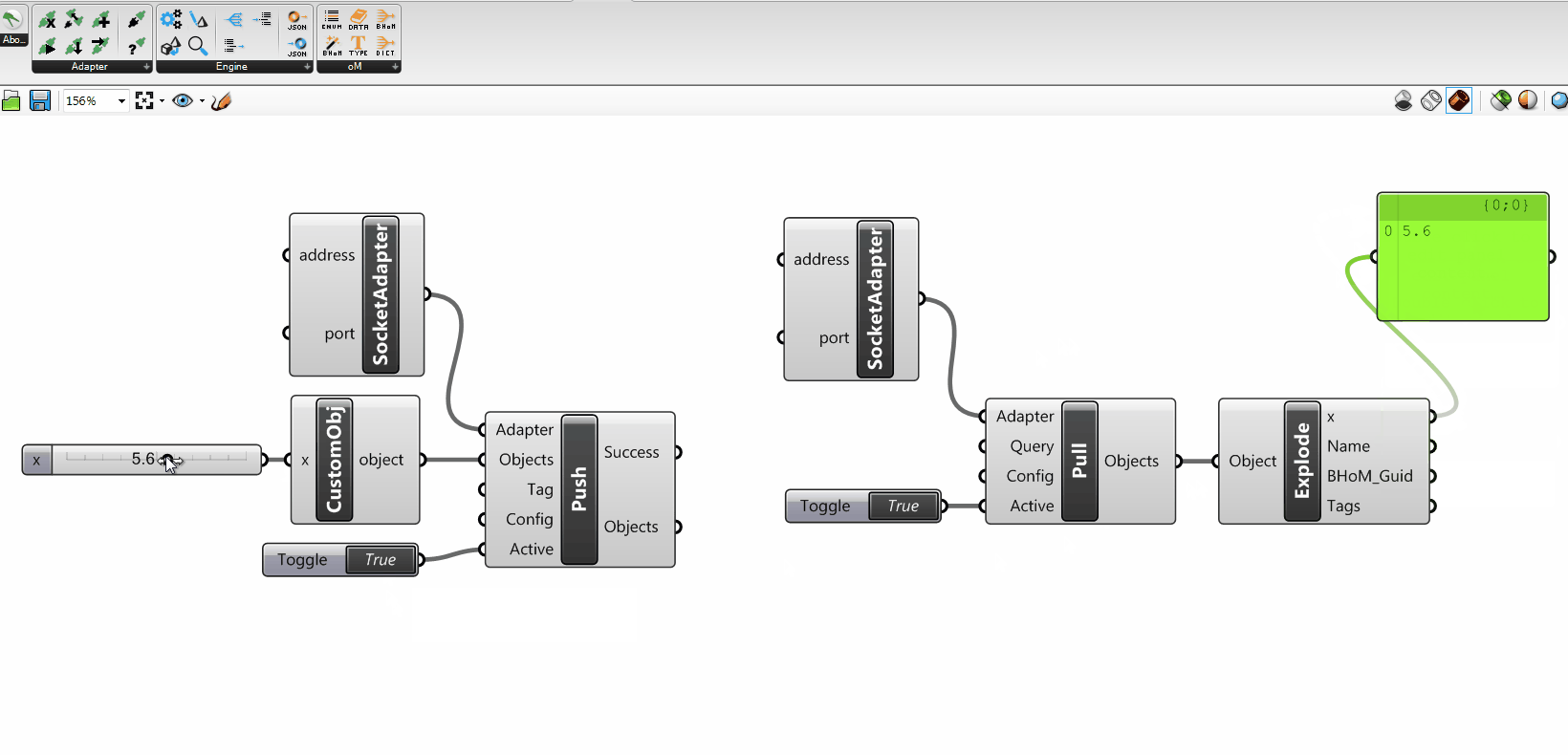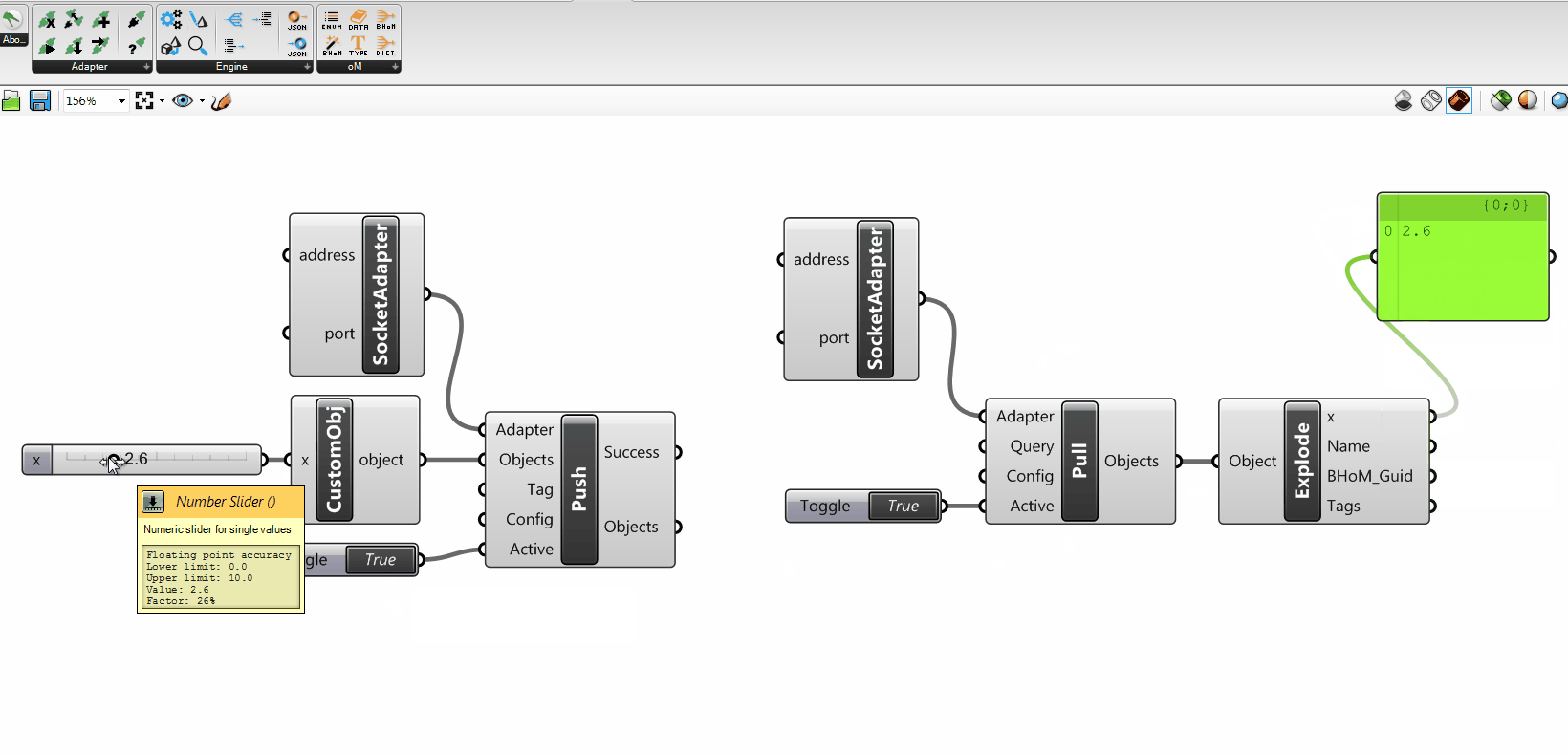
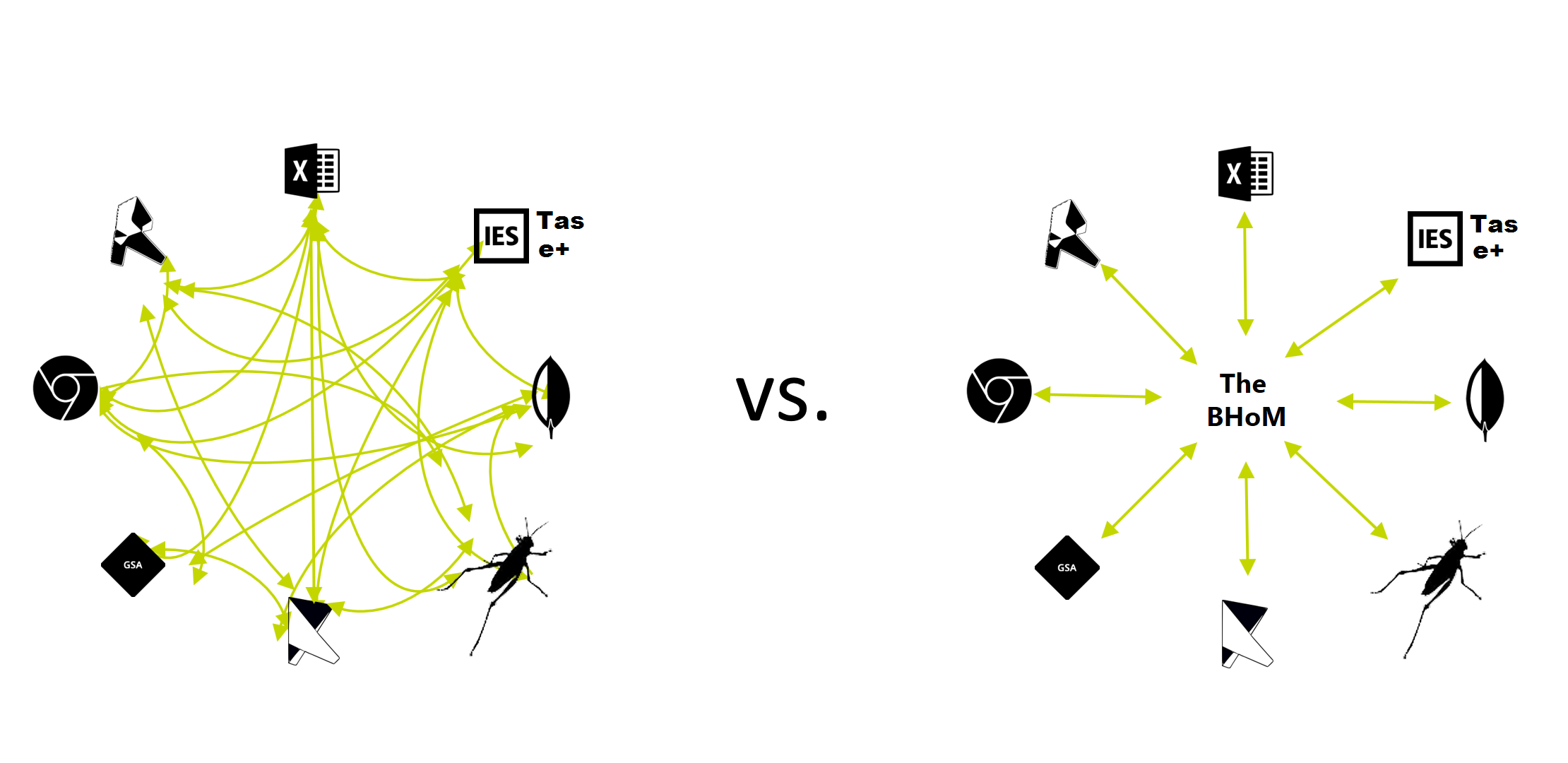




 .
.
















 +1. Use the
+1. Use the  +1. Copy the output of
+1. Copy the output of  +I'm using find and replace for the renaming - care should be taken here.
+I'm using find and replace for the renaming - care should be taken here. .
+1. At this we can rebuild the solution and rebuild the
.
+1. At this we can rebuild the solution and rebuild the  +1. If this fails double check all the steps above.
+1. Open Rhino and the simple test file.
+1. We'll see the auto generated create method has correctly upgraded, but the others show errors:
+1. If this fails double check all the steps above.
+1. Open Rhino and the simple test file.
+1. We'll see the auto generated create method has correctly upgraded, but the others show errors:
 +1. And adding the
+1. And adding the 







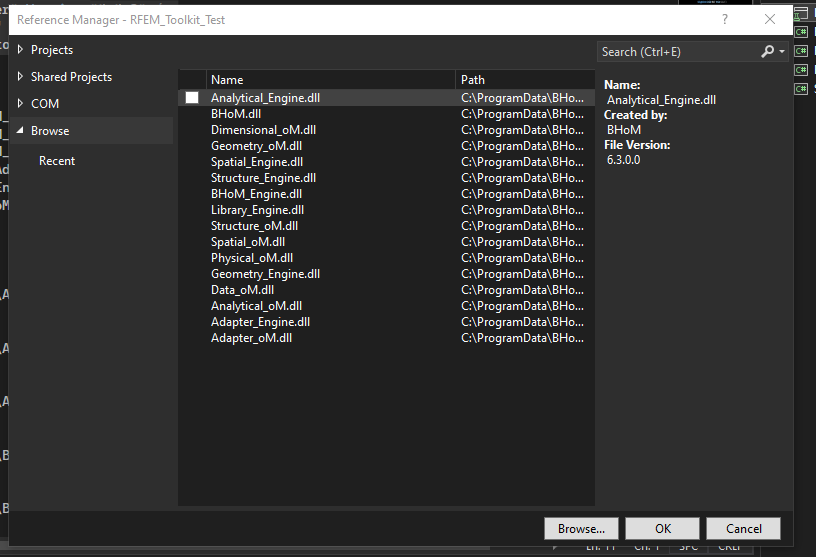
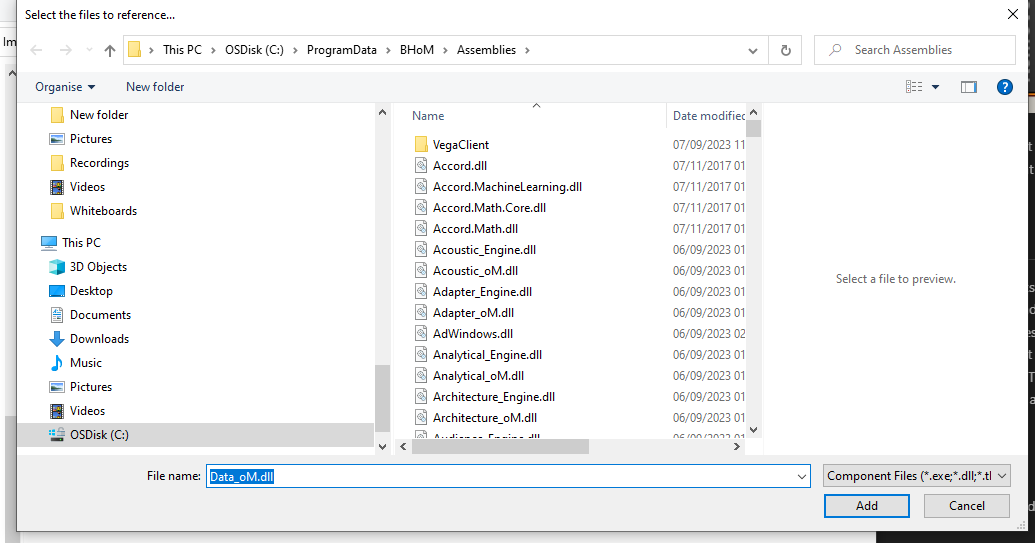
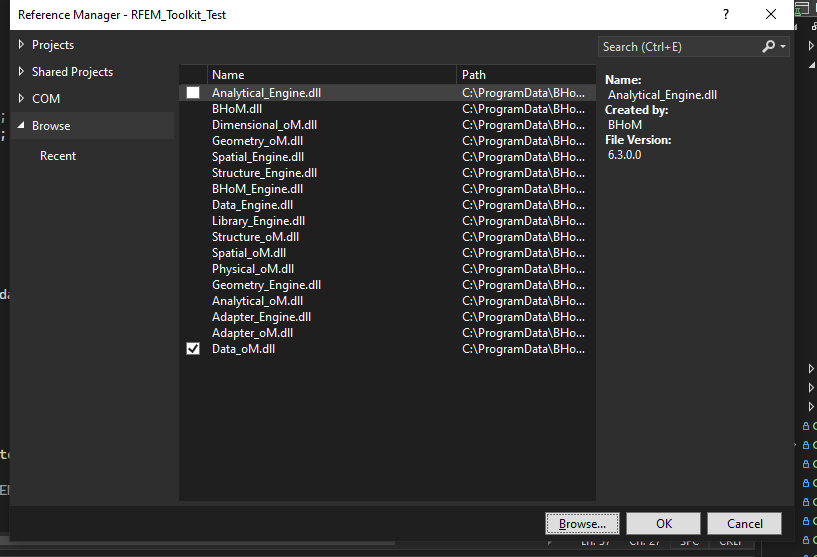
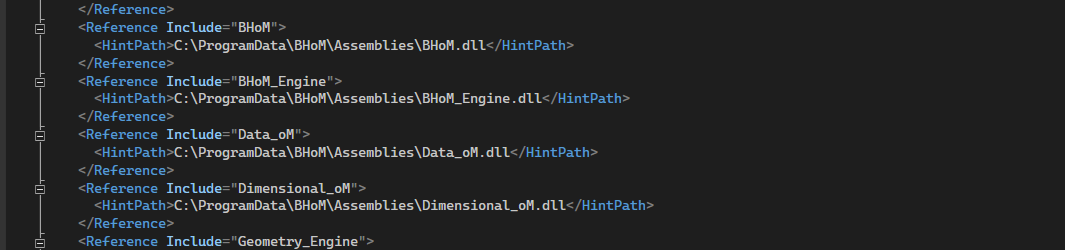
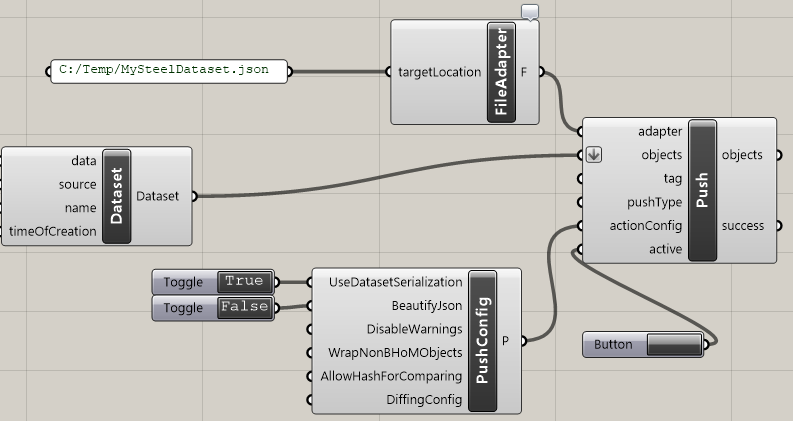













 +
+



 +The Diffing config has the following inputs:
+The Diffing config has the following inputs:



{kind=link}
{kind=link}
{kind=link}