McStas 3.0beta technology preview release notes
This page gives a status of the McStas 3.0beta technology preview to be released end of February 2020. The beta is very much result of a concerted effort done end of January 2020 by the whole McStas-McXtrace team and observers from RAMP.
Thanks:
- Thanks to all members of the joint McStas-McXtrace team, you guys ROCK!
- Thanks to Guido Juckeland (HZDR,DE) and Sebastian Alfthan (CSC,FI) who were behind the GPU Hackathons we participated in
- Thanks to our NVIDIA mentors Vishal Metha, Christian Hundt and Alexey Romanenko
Installation:
- As this is NOT a production release, we will only offer installation packages in the form of "manually installable" packages, see http://download.mcstas.org/mcstas-3.0beta/
-
New code-generation scheme based on functions instead of #defines, which brings
- Much improved compilation-times, the code is better suited for modern compilers
- In most cases a speed-up of order 20%
- The neutron
_particleis now represented by a struct - The component types and instances are also represented by structs
- In the generic
TRACEfunction of a given component type, the_compvar is short-hand for "whatever the component instance is" - New instrument section of
USERVARS %{ double example_flag; %}which enriches the_particlestruct - In component
DECLAREblocks, assignments can no longer be done and all declarations must be listed independently, i.edouble a;is OK,double a,b;is not. Variables in this scope are automatically so-called "OUTPUT PARAMETERS" (we may deprecate that keyword completely for the official McStas 3.0 release) - Components no longer support
DEFINITION PARAMETERS, instead theSETTING PARAMETERSmust be used, which now includes avectorandstringtype supplementing the (default)double/MCNUMandinttypes. - New macros have been added for
INSTRUMENT_GETPAR(parameter_name)-
COMP_GETPAR(component, parameter_name)which is similar to the legacyMC_GETPAR MC_GETPAR3(component_class, component_name,parameter_name)- FIXME: document these fully
- Further, the new cogen implements support for Nvidia GPU's, for details see point 2 below.
- Status on CPU (20200220) is that 134 out of 176 instruments from the mcstas-3.0 branch compile for CPU - and most run as expected.
-
Limited, experimental support for OpenACC acceleration on NVIDIA GPU's
-
#pragmadriven, inserted by the code-generation, but also implemented in (many, not all) libs and comps - Status on GPU (20200220) is that 91 out of 176 instruments from the mcstas-3.0 branch compile for GPU. These 91 instruments include in total 73 out of 213 components. Out of the functional instruments, around 45 produce meaningful data at this point.
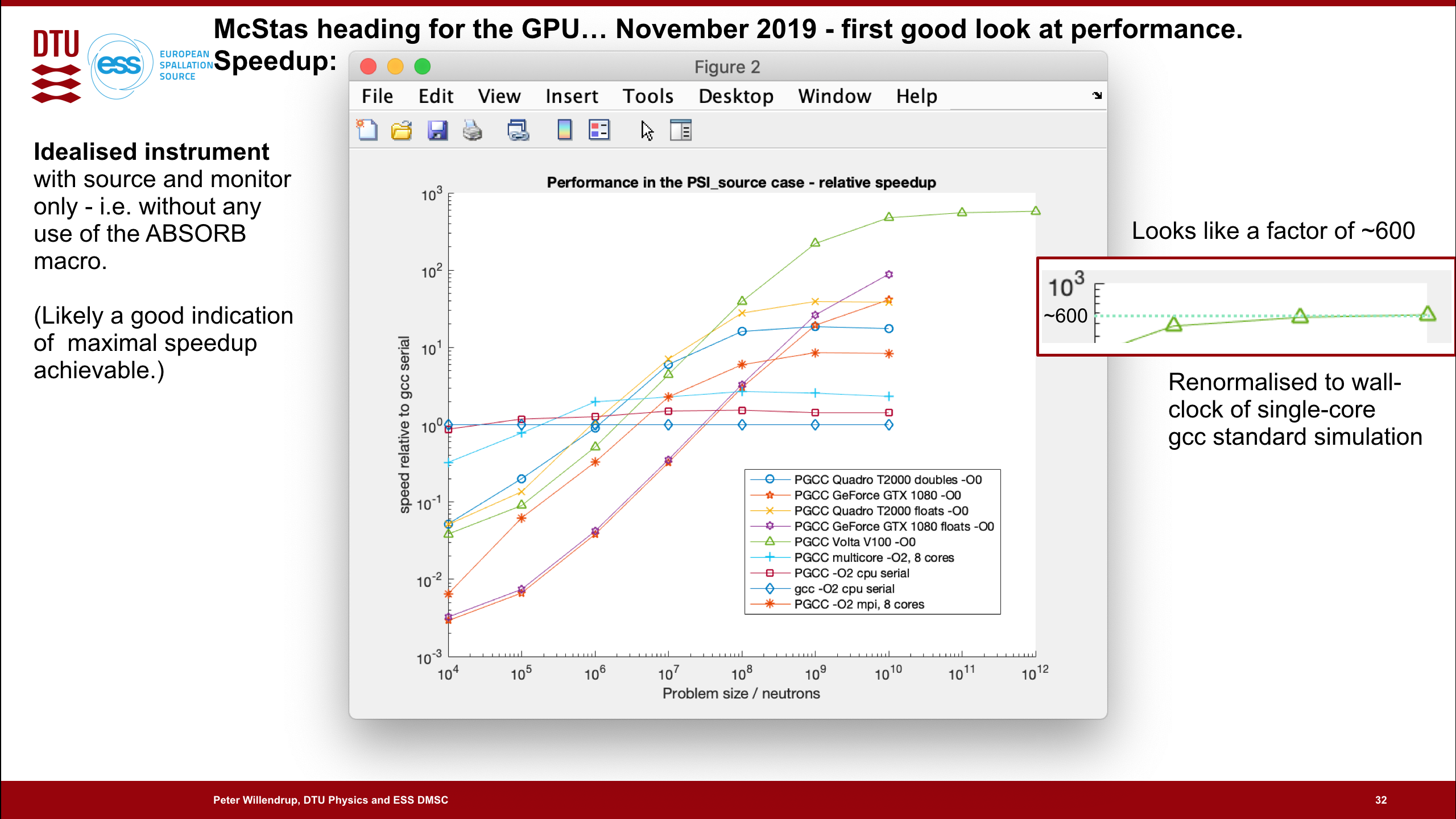
- Speedups measured using top-notch NVIDIA V100 datacenter cards are in the range of 10-600 with respect to a single-core CPU, see below figure which was generated for an "ideally" parallel instrument. Consult e.g. the graphical output page for the February 20th test run.
-
-
Platform support / compiler configuration
- Required compiler for GPU/OpenACC: PGI 19.4 or newer. Community edition works fine
- Required GPU hardware: NVIDIA Tesla card + configured driver
- Windows: At this point unsupported for GPU/OpenACC since the
managedmemory mode is not available for this platform. (Very simple instruments without monitors may work, at this point untested). The multi-threading should work withpgcc -ta:multicore -DOPENACC. - macOS: Only CPU-thread parallelisation is supported, since NVIDIA Cards at this point are unsupported on recent macOS versions. Parallelises similarly to MPI, but slightly slower.
- Linux: Full acceleration support with GPU, and with multicore.
- Install the compiler and put it on your system
PATH. Install and configure Nvidia drivers for your card. - We hope that GCC will better support OpenACC in the near future.
-
Tool support
- On Linux and macOS mcrun is preconfigured so that
mcrun -c --openacccompiles with: - Linux:
pgcc -ta:tesla,managed,deepcopy -DOPENACC - macOS:
pgcc -ta:multicore -DOPENACC - For both of the above, adding
-Minfo:accelwill output verbose information on parallelisation - In mcgui, the mcrun --openacc configuration can be selected via the preferences
- On Linux and macOS mcrun is preconfigured so that
-
Interoperability with McStas 2.6
- Rudimentary support for MCPL event interchange has been added through a set of MCPL_input_GPU and MCPL_output_GPU components.
-
Known limitations
- As mentioned above, not all components/instruments are ported to the GPU technology yet
- We have not fully decided if our newly implemented random number algorithm is sufficiently robust/stable.
- Monitor_nD user vars can not currently access the neutron
USERVARS, but a solution is in the pipe. - Not all features of all components correspond to those from McStas 2.6, partly because not all modifications have been ported from the 2.6 tree to the 3.0 tree.
- Especially the sample components may
- Create GPU-side segmentation faults etc. with big datasets / large statistic, this is a targeted area of development before the actual release of 3.0. :-)
- Give simulation results that are systematically 'off' with respect to CPU results.