FAQ
As per the EU legislation, the three certificate types are:
- Vaccination
- Test
- Recovery

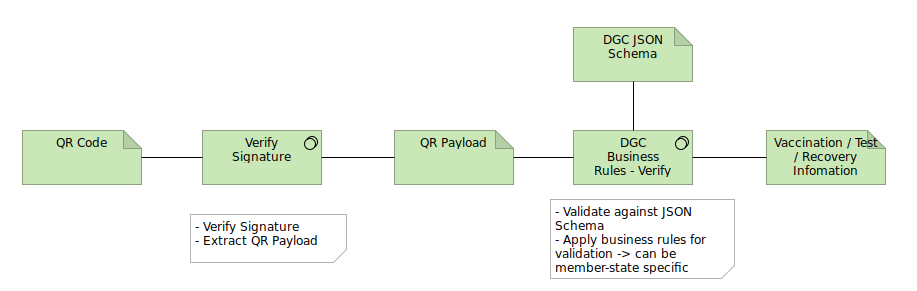
In both these cases there is a stage of processing in software in which business rules are applied. Examples of actions that may be present in business rules:
- If a required portion of a name is missing from the original data, set it to an empty value (see also: Mandatory Fields and Missing Data)
- If an ISO8601 date-time field is specified as mandatory in the DGC JSON schema but you do not wish to include the time portion as a matter of policy for your Member State, then you can set the hours, minutes and seconds (hh:mm:ss) fields to 00:00:00
- In generating the certificate id, the choice of which option to choose from Annex 2 in the eHealthNetwork Vaccination Interoperability Guidelines is delegated to a Member State. The business rules for issuance is an ideal place to create such a certificate id as per Member State policy.
-
If the QR payload you are reading contains a value unknown to you in a field governed by a defined ValueSet type, then you may choose whether you wish to validate the QR payload or not. An example of this is if there is a newer vaccine type available than is known to the verifier application. Assuming the issuing state is using a known, valid vaccine type then it can well be the case that the Verifier application is referring to a somewhat out-dated local version of the ValueSet for vaccine types. One possible action at this point as a Verifier application could be to ensure that the latest ValueSet values are available to it (e.g. download latest) and to re-try validation.
-
Process fields to arrive at a concrete payload. An example of this is to pass the
certificate idfield in full (see UVCI Format) to a name resolution service (arpa) which will map this to a resource according to the Member State name resolution rules. This resolved resource can in turn be used for further processing.
It can be the case that the data required to populate the DGC JSON schema is simply not present in the source data when queried. An oft-encountered example of this is with the patient name, where often the Family Name (EU Regulations: "Surname") is present, but the Given Name (EU Regulations: "Forename") is not. In the Annex to the proposed EU legislation it is stated that "Surname(s), Forename(s) shall be given, in that order". In order to make the DGC JSON Schema as conformant as possible to this legislation, both fields Family Name and Given Name can be marked as ["required"] in the JSON schema so we need to supply the values. However, our data source only has Family Name and not Given Name.
One solution is to use the DICOM approach of Type 2 values. In summary, this allows a value to be specified as mandatory but can be marked as being empty and have no value. The rich DICOM metadata approach to values is not available to us in JSON (although we could get very close using XML), but we can approximate the DICOM approach by setting the mandatory field to an empty value (i.e. empty string for string types, 0 for integer types, 0.0 for floating-point types etc). In this way, we can support both a mandatory value but allow the flexibility of handling the case when the source data simply does not have that mandatory value available for us.
Please note that if the value is available, then it is required to be set, as per DICOM Type 2:
[... defines] Type 2 Data Elements that shall be included and are mandatory Data Elements. However, it is permissible that if a Value for a Type 2 element is unknown it can be encoded with zero Value Length and no Value. If the Value is known the Value Field shall contain that value [...]. These Data Elements shall be included in the Data Set and their absence is a protocol violation.
Please also note that "if the value is available" will cover an often seen although incorrect usage of the person name which is to supply only the Family Name (and leave the Given Name field empty). However, the Family Name field will contain both Family and Given names in the one field separated by, typically, a '^' character e.g. "Surname^Given". This is seen, for example, when DICOM metadata information is (incorrectly) simply copied "blind" to the corresponding HL7 data field. In this case, the Given Name value is present, even if the Given Name field is empty. It is the responsibility of the Issuance business rules to ensure that the Given Name value is populated if it is present in the source data - including it being "hidden" in the string for Family Name.
For generating the certificate id: the choice of which option to choose from Annex 2 in the eHealthNetwork Vaccination Interoperability Guidelines is delegated to the Member State.
For verifying the certificate id: the complete certificate id field is simply passed to a standard (arpa) name resolution mechanism. Annex 2 also states that it is the responsibility of each Member State to maintain its own valid name resolution mapping:
[...] the Country or Authority identifier is well-managed; and each country (authority) is expected to manage its segment of the namespace well by never recycling or re-issuing identifiers.
The DGC Schema supports conformity to the proposed EU legislation and is intended to be a vehicle for serialization and de-serialization according to several differing Member State requirements. For example, one Member State wishes to generate one QR code per certificate type and another may wish to generate a QR code combining two or three types of certificate. Both of these scenarios are supported by the DGC Schema. The business rules for that Member State, however, determine precisely which data the DGC schema will be populated with at the time of generation.
The DGC schema presented here allows for multiple of all entries (in essence: array of ).
This is because the DGC schema:
- is designed in such a way that if regulations require (or allow) more than one entry per type, then there is no fundamental schema structure change, and
- that the current regulation-conform implementation of only one entry can just be considered as an array of one element.
The proposed EU legislation specifies in the Annex which fields shall be present for a given instance of a particular certificate type. It must therefore be possible to create a QR payload (the DGC schema) with this information.
The current schema allows us to conform to EU regulation, which is the main criteria. It also allows for extension if / when needed (the Open-Closed Principle of "open for extension, closed for modification") - the 'O' in SOLID. The absolute final say on what is valid for (i) the EU and (ii) a given member state can be applied in the business rules part of the processing.
The UVCI checksum algorithm used is Luhn-Mod-N.
For ease of reference, the following is taken directly from Annex 2 in the eHealthNetwork Vaccination Interop Guidelines
- Charset: Only uppercase US-ASCII alpha numerical characters (
AtoZ,0to9) are allowed; with additional special characters for separation from RFC3986 , namely {/,#,:};- Maximum length: designers should try to aim for a length of 27-30 characters
- Version prefix: This refers to the version of the UVCI schema. The version prefix is
01for this version of the document. The version > prefix is composed of two digits.- Country prefix: The country code is specified by ISO 3166-1 alpha-2. Longer codes (e.g. 3 characters and up (e.g
UNHCR) are reserved > for future use- Code suffix / Checksum:
- Member States should use a checksum when it is likely that transmission, (human) transcription or other corruptions may occur (i.e. when used in print).
- The checksum must not be relied upon for validating the certificate and is not technically part of the identifier but is used to verify the integrity of the code. This checksum should be the ISO-7812-1 (LUHN-10)7 summary of the entire UVCI in digital/wire transport format. The checksum is separated from the rest of the UVCI by a
#character.
ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789/:
Note that '#' is removed from the valid charset since it shall occur only as a separator for the Luhn-Mod-N checksum.
The prefix "URN:UVCI:" shall be used for Vaccination, Test and Recovery certificate ids.
This prefix shall be included in the checksum calculation.
URN:UVCI:01:NL:187/37512422923 using the charset above gives the corresponding checksum character Z.
Note that as per Annex 2, it is required to separate the Luhn-Mod-N checksum from the data via a '#' separator, thus the final field inclusive of checksum character becomes: URN:UVCI:01:NL:187/37512422923#Z
A reference implemenation in Python is available in https://github.com/ehn-digital-green-development/ehn-dgc-schema , in the directory examples/Luhn-Mod-N.
The implementation is based on the original wikipedia article https://en.wikipedia.org/wiki/Luhn_mod_N_algorithm .
- Although the proposed EU legislation does not mandate the use of ISO8601 for date / date-time, the informative document those regulations reference as supporting material, the eHealthNetwork Vaccination Interop Guidelines, in Annex 2 clearly does state that the ISO8601 format shall be used. Thus whilst technically not legally mandated, it is, however, very much the intention that ISO8601 is used. Using "seconds since epoch" violates this recommendation.
- Even if it were not the case that ISO8601 was recommended, using "seconds since epoch" is not portable across platforms: in particular Windows and *nix (e.g. Linux, Unix) operating systems have a different epoch start time (see also e.g. Convert between Windows and Unix epoch ). Thus using "seconds since epoch" is poor from an interoperability perspective.
- The usual motivation for requesting "seconds since epoch" is ostensibly to "save space" (particularly with respect to generating a QR payload with only a limited number of bytes available). On closer inspection, it becomes rather debatable whether "seconds since epoch" offers any space saving. If you consider that the payload will be passed through some form of LZMA compression then any repeated (sub-)strings will be compressed into just one string occurence. For example, if the events all happened in the same year and in the same month, then the ISO8601 "YYYY-MM" field will occur once only in the compressed output. You can, of course, make similar arguments for at least parts of the "seconds since epoch" string, but at this point either format becomes very similar in terms of compression. You may save one character here or there - or maybe not, depending on the actual date / date-time involved and how often it repeats (or parts thereof) - by choosing one format over the other. This comes down to potentially one or two bytes (or not) depending on whichever representation you choose. This variance in byte length is insignificant (whichever format you choose) when you consider that the byte length of a person name field can easily vary by an order of magnitude greater than what you may (or may not) have saved in byte length by choosing either ISO8601 or "seconds since epoch". Thus the argument for potentially saving space in the QR payload by using "seconds since epoch" as opposed to ISO8601 is negligible (or even zero) 1 .
Footnotes
1. Although for ease of illustration I refer to LZMA compression of the original JSON source, the argument is transitively applicable to any stage of processing at which LZMA compression of the input data takes place, whether that input data is e.g. raw JSON or serialized CBOR etc. The achievable compression ratio for LZMA compression is, as ever, a function of the input data.