🎉重中之重的前端基础🎉
主要为
- HTML
- CSS
- JavaScript
的必会知识点们
内容来源:《JavaScript高级程序设计~(第四版)~》/ 众多大佬们的知识博客/ 自己学习过程中记录的笔记/ MDN文档
重要的知识点要深入掌握,不要满足于只知道简单地概念,三段论学习新知识(/重点知识)法——
了解这个知识的概念是什么(最最基础的要求)
了解这个知识被提出来的目的是什么(不要像背答案一样学习新知识)?
将知识用一句话(简练地)说清楚(一步抓住面试官想要知道的内容,再拓展开来讲)!
这部分的内容回头尽量用这三段论的思路补全~
HTML(HyperText Markup Language,超文本标记语言)是为了发送 Web 上的超文本(Hypertext)而开发的标记语言。
- 超文本是一种文档系统,可将文档中任意位置的信息与其他信息(文本或图片等)建立关联,即超链接文本。
- 标记语言是指通过在文档的某部分穿插特别的 字符串标签,用来修饰文档的语言。我们把出现在 HTML 文档内的这种特殊字符串叫做 HTML 标签(Tag)。
select 元素可创建单选或多选菜单。
下方代码效果创建带有 4 个选项的选择列表:
<select>
<option value ="volvo">Volvo</option>
<option value ="saab">Saab</option>
<option value="opel">Opel</option>
<option value="audi">Audi</option>
</select>下方效果需在Typora(也许其他文本编辑器也行?)中长按来显示
Volvo Saab Opel Audi #### [`` - HTML(超文本标记语言) | MDN (mozilla.org)](https://developer.mozilla.org/zh-CN/docs/Web/HTML/Element/label)知识点来源:基础 HTML 和 HTML5: 创建一组复选框 | freeCodeCamp.org


-
href 超文本引用
href 用于建立标签和外部资源的关系
-
src是资源的意思
src 表示资源替代这个元素。
这个点还是比较重要的!
- 浏览器遇到href会并行下载资源,但是不会停止对文档进行解析。
- 浏览器遇到src会暂停其它资源的下载和文档解析,直到资源加载完毕。(这就是script标签不能放在头部的原因)
这张图拿出来看下 更有感觉了!!
很明显!脚本的加载(也可以称作下载)(蓝色那部分)在defer、async两个属性的作用下,是并行(可以和其他进程 比如文档渲染一起~)的!
而脚本的执行是并发的(需要阻塞掉其他进程~)

HTML5标签 参考手册 其中带new标签的是HTML5中的新标签
display:none visibility:hidden的区别
1.display:none是彻底消失,不在文档流中占位,浏览器也不会解析该元素;visibility:hidden是视觉上消失了,可以理解为透明度为0的效果,在文档流中占位,浏览器会解析该元素;

2.使用visibility:hidden比display:none性能上要好,
- display:none切换显示时页面产生回流(当页面中的一部分元素需要改变规模尺寸、布局、显示隐藏等,页面重新构建,此时就是回流。所有页面第一次加载时需要产生一次回流),
- 而visibility切换是否显示时则不会引起回流。
层叠顺序,英文称作 stacking order,表示元素发生层叠时有着特定的垂直显示顺序。下面是盒模型的层叠规则:
由上到下分别是:
(1)背景和边框:建立当前层叠上下文元素的背景和边框。
(2)负的 z-index:当前层叠上下文中,z-index 属性值为负的元素。
(3)块级盒:文档流内非行内级非定位后代元素。
(4)浮动盒:非定位浮动元素。
(5)行内盒:文档流内行内级非定位后代元素。
(6)z-index:0:层叠级数为 0 的定位元素。
(7)正 z-index:z-index 属性值为正的定位元素。
注意: 当定位元素 z-index:auto,生成盒在当前层叠上下文中的层级为 0,不会建立新的层叠上下文,除非是根元素。
- EM 是字体排印的一个单位,等同于当前指定的point-size。
h1 { font-size: 20px } /* 1em = 20px */
p { font-size: 16px } /* 1em = 16px */h1 {
font-size: 2em; /* 1em = 16px */
margin-bottom: 1em; /* 1em = 32px */
}
p {
font-size: 1em; /* 1em = 16px */
margin-bottom: 1em; /* 1em = 16px */
}
/* 两种状况下的margin-bottom的1em值不同
因为在父级元素*/- 这意味着
1rem等同于<html>中的font-size。

- 两个标准流box1 3发生外边距合并 它们之间的距离实际上是15px
- 而脱离文档流的box2的位置被box3挤占了 且 与box1没有外边距合并 所以box1和box2的距离实际上是30px
优质练习资源 小青蛙找荷叶
#pond {
display: flex;
flex-direction:column-reverse;/* 改变排列方式为竖直倒序 */
align-content: space-between;/* 决定行与行之间的距离 */
flex-wrap: wrap-reverse;/* 自动换行成多行(默认为强制在一行) */
justify-content: center;/* 居中 */
}效果如下:

经典问题-利用布局实现元素垂直居中
浮动这块儿讲究可多咧!回头还需要多研究下呐!
- 设置浮动的图片——实现文字环绕图片
- 设置了浮动的块级元素可以排列在同一行
- 设置了浮动的行内元素可以设置宽高 -
涨知识系列 - 可以按照浮动设置的方向对齐排列盒子 -
没见过这用法
- 设置了浮动,该元素脱离文档流。元素不占位置
- 如果父级盒子没有设置高度,需要被子盒子撑开,那么这时候父级盒子的高度就塌陷了,同时也会造成父级盒子后面的兄弟盒子布局受到影响
清除浮动的方法
- 伪元素清除浮动
.clearfix::after {
content: '';
display: table;
clear: both;
}- 给浮动元素父级添加
overflow:hidden; - 额外标签法:给浮动元素父级增加标签
<div class="wrap">
<div class='left fl'></div>
<div class='right fl'></div>
<div style='clear:both'></div>
</div>- 伪元素清除浮动:不会新增标签,不会有其他影响,是当下清除浮动最流行的方法
overflow:hidden;不会新增标签,但是如果父级元素有定位元素超出父级,超出部分会隐藏,在不涉及父级元素有超出内容的情况,overflow:hidden比较常用,毕竟写法方便简洁- 标签插入法:清除浮动的语法加在新增标签上,由于新增标签会造成不必要的渲染,所以这种方法目前不建议使用
伪类:
伪类是以:作为前缀的
伪类是附加在选择器末的关键字
伪类元素可以让指定的元素,在指定的状态,呈现特点样式的关键字。
伪元素:
伪元素是以::作为前缀的
伪元素是附加在选择器末的关键字
伪元素可以添加元素,虽然可以显示元素,但是创建元素不会在DOM树中存在。
-
写过一篇文章 重学数据(类型)、变量、内存,
-
聊了一下这几个数据类型要如何通过typeof instanceof判定;
-
聊了一下内存的问题——
- 基本数据类型赋值给变量,变量存在栈中;
- 引用数据类型赋值给变量,变量存在栈中,而对象保存在堆中,变量指向堆~
-
-
基本数据类型


var a = 1, b = 2;
function test(pre, cur){
pre = "hello world";// 函数作用域中的pre为"hello world"
cur = 666;// 函数作用域中的cur为666
// 这二位都不会影响到a b
}
function test2(){
a = a+1;
b = 666;
}
test(a, b);
console.log(a, b);// 1 2
test2();
console.log(a, b);// 2 666- 引用类型
Object
根据红宝书复习的内容
首先明确定义
parseInt
parseInt函数将其第一个参数转换为一个字符串,对该字符串进行解析,然后返回一个整数或 NaN。
第二个参数为其对应的进制(默认是十进制哈)
注意如果第一个参数从左到右数,遇到字符就会舍弃字符+字符后面的内容
parseInt('0001', 2);// 1 parseInt('00x1111', 2);// 0 parseInt('0011x11', 2);// 3
parseInt('123xxx', 5) // 先把'123xxx'转换为'123' 将'123'看作5进制数,返回十进制数38 => 1*5^2 + 2*5^1 + 3*5^0 = 38parseFloat
parseFloat() 函数解析一个参数(必要时先转换为字符串)并返回一个浮点数。
parseFloat('5556.6www');// 5556.6这里一个有趣的应用
var a = ["88","66"];
// 将a数组转换为数值型可以简单地这样做
a.map(parseFloat);// [88,66]这里其实我也不知道为啥可以XD
//a.map(parseInt) 返回就是 [88,NaN]🥺
// 也可以常规一些~
a.map(x => parseInt(x));// .map(x => parseFloat(x))字面量可分为数字字面量、字符串字面量、数组字面量、表达式字面量、对象字面量、函数字面量。
- 数字(Number)字面量 可以是整数或者是小数,或者是科学计数(e)。
3.14
123e5
- 字符串(String)字面量 是使用单引号或双引号定义的字符串。
"John Doe"
- 表达式字面量:
5 + 6
5 * 10
- 数组(Array)字面量 定义一个数组:
[40, 100, 1, 5, 25, 10]
- 对象(Object)字面量 定义一个对象:
{firstName: "John", lastName: "Doe", age: 50, eyeColor: "blue"}
- 函数(Function)字面量 定义一个函数:
function` `myFunction(a, b) { ``return` `a * b;}
- 箭头函数中 使用括号返回对象的字面量形式
//加括号的函数体返回对象字面量表达式:
params => ({foo: bar})- for in 遍历对象 而不是数组

- for of 遍历可迭代对象 Array Map Set

这个好用欸!

ES5新增的Array API
下面这些内容大部分为红宝书的内容
from()用于将 类数组结构转换为数组实例,而 of()用于将一组参数转换为数组实例
由于行为不一致和存在性能隐患,因此实践中要避免使用数组空位。
如果确实需要空位,则可以显式地用 undefined 值代替。
数组 length 属性的独特之处在于,它不是只读的。通过修改 length 属性,可以从数组末尾删除 / 添加元素
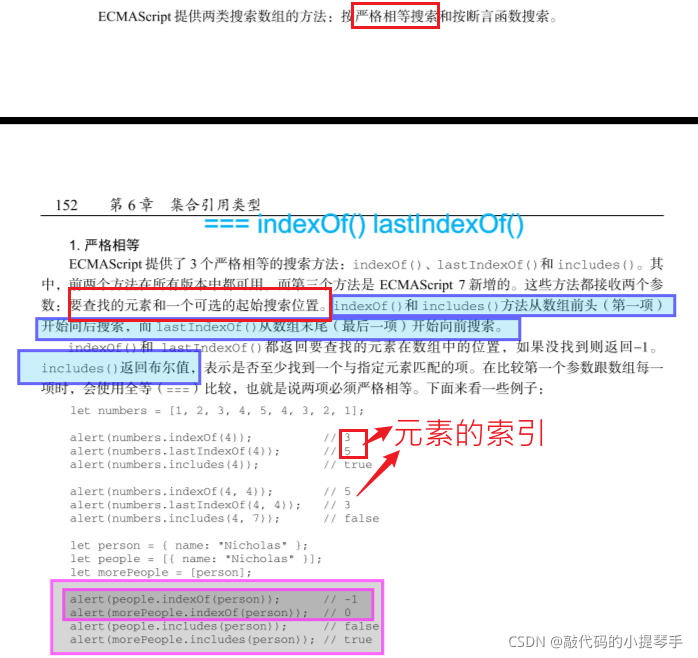
一个经典的 ECMAScript 问题是判断一个对象是不是数组。在只有一个网页(因而只有一个全局作 用域)的情况下,使用 instanceof 操作符就足矣:
使用
instanceof的问题是假定只有一个全局执行上下文。如果网页里有多个框架,则可能涉及两 个不同的全局执行上下文,因此就会有两个不同版本的 Array 构造函数。如果要把数组从一个框架传给另一个框架,则这个数组的构造函数将有别于在第二个框架内本地创建的数组。
为解决这个问题,ECMAScript提供了 Array.isArray()方法。这个方法的目的就是确定一个值是 否为数组,而不用管它是在哪个全局执行上下文中创建的
在 ES6 中,Array 的原型上暴露了 3 个用于检索数组内容的方法:keys()、values()和 entries()。keys()返回数组索引的迭代器,values()返回数组元素的迭代器,而 entries()返回索引/值对的迭代器:
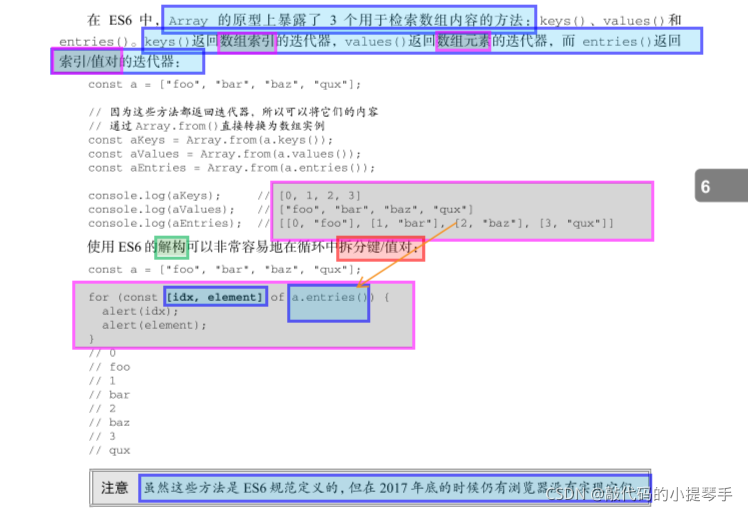

const zeros = [0,0,0,0,0];
//zeros.fill(填充数字,填充索引起始,填充索引结束前一位);
zeros.fill(7, 1, 3);
console.log(zeros);//[0,7,7,0,0]let ints,
reset = {} => ints =[0,1,2,3,4,5,6,7,8,9];
//ints.copyWithin(插入位置的索引,复制的索引起始,复制的索引结束前一位);
ints.copyWithin(4,0,3);//[0,1,2,3, 0,1,2, 7,8,9]得到——以逗号分隔数组值的字符串
toLocaleString()toString()数组.valueOf()
得到——以传入参数分割数组值的字符串
而
包装对象实例.valueOf()则返回包装对象实例对应的原始类型的值new Number(123).valueOf() // 123 new String('abc').valueOf() // "abc" new Boolean(true).valueOf() // true
join("xxx")

就只有 入队列的方法与栈不同 其他方法是一样的
使用shift
插入到队头
sort 这个sort有个坑 所以一般不直接用

注意字符串排序的小细节
根据ASCII值来比较 所以小写字母a会在大写字母Z后面

concat()

一个很有意思的用法——用来合并多个数组&数字(例子来自MDN)
var alpha = ['a', 'b', 'c'];
var alphaNumeric = alpha.concat(1, [2, 3]);
console.log(alphaNumeric);
// results in ['a', 'b', 'c', 1, 2, 3]
// 可以用来连接数字/数组slice()

splice()

简单来说就是删除/插入 然后根据这俩功能自然就可以做出来替换咯~ 来看看JS

超级好用的几个方法!
every()some()filter()

map()forEach()

reduce()
这里的reduce的第一个参数 prev要注意
如果求和时 一般会给其起名为total 用于存储截至此时的和

明确Map实例的格式 为 键值对
const map = new Map([
["key1", "val1"],
["key2", "val2"],
["key3", "val3"]
])- set() 添加键值对
- get() 获得某个键的值
- has() 查询是否有这个键
.size()获取键值对数量- delete() 删除某个键值对
- clear() 清除映射实例中的所有键值对
- entries() 返回一个新的包含
[key, value]对的Iterator对象,返回的迭代器的迭代顺序与Map对象的插入顺序相同。 - forEach() 按照插入顺序依次对
Map中每个键/值对执行一次给定的函数 - values()它包含按顺序插入Map对象中每个元素的value值。
举例:

另外 与Object只能使用数值、字符串、符号作为键不同
Map可以使用任何JS数据类型作为键!!(这也是为啥ES6要创键这个集合类型)
-
另外注意 Map实例对象2个有趣的特性:
- 一个key放入多个value —— 覆盖原先的value
var m = new Map(); m.set('Adam', 67); m.set('Adam', 88); m.get('Adam');//88
可以看出 key是不允许重复的!这也符合哈希表特性
但是重复了也不会出错 自动就覆盖掉了
- 值重复就没啥事儿(那肯定的嘛)

p191
又看到了 .entries() 迭代器方法!
——可以返回key value
跟Map的大多数API 和 行为 都是共有的
也是一组key的集合,但不存储value。
- 要创建一个
Set,需要提供一个Array作为输入,或者直接创建一个空Set:
var s1 = new Set(); // 空Set
var s2 = new Set([1, 2, 3]); // 含1, 2, 3
//其实跟map的初始化方法是一样的 就是初始化内容不同而已由于key不能重复,所以,在Set中,key是无法像Map实例中一样 可以覆盖的!
.sizehas()判断有没有这个元素clear()add()与map的set添加一组键值对不同 set添加个元素就好了
通过 apply() 方法,您能够编写用于不同对象的方法。(与call()方法非常类似,只有传参时有区别)
var person = {
fullName: function() {
return this.firstName + "调用成功" + this.lastName;
}
}
var person1 = {
firstName:"Bill",
lastName: "Gates"
}
person.fullName.apply(person1); // Bill调用成功Gatesvar person = {
fullName: function(city, country) {
return this.firstName + " " + this.lastName + "," + city + "," + country;
}
}
var person1 = {
firstName:"Bill",
lastName: "Gates"
}
// 还可以传参进去哈!与call不同于参数的类型 为 数组
person.fullName.apply(person1, ["Seatle", "USA"]); // Bill Gates,Seatle,USA您可以使用 Math.max() 方法找到(数字列表中的)最大数字:
由于 JavaScript 数组没有 max() 方法,因此您可以应用 Math.max.apply() 方法。
Math.max(1,2,3);
let arr = [1,2,3]
Math.max.apply(null, arr); // 也会返回 3 注意:第一个参数填啥没影响的,本次使用中没他事儿~在 JavaScript 严格模式下,如果 apply() 方法的第一个参数不是对象,则它将成为被调用函数的所有者(对象)。
在“非严格”模式下,它成为全局对象。
19.浅复制数组的一部分到同一数组的另一位置 copyWithin()
copyWithin() 方法浅复制数组的一部分到同一数组中的另一个位置,并返回它,不会改变原数组的长度。
const array1 = ['a', 'b', 'c', 'd', 'e'];
// copy to index 0 the element at index 3
console.log(array1.copyWithin(0, 3, 4));
// expected output: Array ["d", "b", "c", "d", "e"]
// copy to index 1 all elements from index 3 to the end
console.log(array1.copyWithin(1, 3));
// expected output: Array ["d", "d", "e", "d", "e"]神奇的方法~
为啥用呢 看看JS数据结构与算法中怎么说~

20.Array.of()创建新数组,复制一维数组的方法
Array.of() 方法创建一个具有可变数量参数的新数组实例,而不考虑参数的数量或类型。
Array.of() 和 Array 构造函数之间的区别在于处理整数参数:Array.of(7) 创建一个具有单个元素 7 的数组,而 Array(7) 创建一个长度为7的空数组(**注意:**这是指一个有7个空位(empty)的数组,而不是由7个undefined组成的数组)。
Array.of(7); // [7]
Array.of(1, 2, 3); // [1, 2, 3]
Array(7); // [ , , , , , , ]
Array(1, 2, 3); // [1, 2, 3]可以用来浅复制一个数组

官方文档中没有提到用of方法进行复制的操作
但是雀氏可以~ 下面额尝试可以清楚看出来复制为浅复制!

可以写一下经典的 217. 存在重复元素 我的题解——【数据结构入门每日刷题打卡1/33】暴力遍历、哈希表、排序(拓展了下手写快排 注释贼清楚!) - 存在重复元素 - 力扣(LeetCode) (leetcode-cn.com)
数组去重12种方法 - 这边里利用对象实现去重的思路挺有意思的 亮点是不用辅助数组 直接在原数组上操作 数组熟练度++~
let arr = [12,1,12,3,1,88,66,9,66];
function unique(arr) {
let obj = {};
for(let i=0;i<arr.length;i++){
let cur = arr[i];
if(obj[cur]){// 如果当前遍历到的元素之前碰到过,进入逻辑把它从arr中删了
// 01 删除重复元素法一
arr.splice(i,1);// 导致数组塌陷——用i--的方式规避数组塌陷!
// 删除重复元素法二
// arr[i]=arr[arr.length-1];// 重复元素的坑给数组最后一个元素勒
// arr.length--;// 删除最后一项
console.log(i);// 2 4 6
// 02 对重复元素进行操作之后 手动将索引值-1 保证数组的每一项都被遍历~
i--;// 注意!删了这个元素之后它之后的数组元素都提前勒!要倒回去一个索引获得原本的下一个数组元素。
continue;// 跳过obj[cur] = cur,给i加上1 进入下一轮循环(其实这句不加也无所谓,给对象重复赋值也没啥影响~)
}
obj[cur]=cur;// 给obj新增键值对;属性名和属性值是一样的
}
}
unique(arr);
console.log(arr);// 法一答案 [12, 1, 3, 88, 66, 9] 法二答案 [12, 1, 66, 3, 9, 88] 写得挺好的 搭配 384. 打乱数组 食用更佳
首先是伪随机的两种方法
- 随机取数
从原数组中随机抽取一个数,然后使用 splice 删掉该元素
function getRandomArrElement(arr, count) {
let res = []
while (res.length < count) {
// 生成随机 index
let randomIdx = (Math.random() * arr.length) >> 0;
// splice 返回的是一个数组
res.push(arr.splice(randomIdx, 1)[0]);
}
return res
}上面生成随机 index 用到了按位右移操作符 >>
当后面的操作数是 0 的时候,该语句的结果就和 Math.floor() 一样,是向下取整
但位操作符是在数值表示的最底层执行操作,因此速度更快
// 按位右移
(Math.random() * 100) >> 0
// Math.floor
Math.floor(Math.random() * 100)
/* 这两种写法的结果是一样的,但位操作的效率更高 */- 通过 sort 乱序
首先认识一下 Array.prototype.sort() 不了解的查看下 这个必须滚瓜烂熟
let arr = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9'];
arr.sort((a, b) => 0.5 - Math.random());但这并不是真正的乱序,计算机的 random 函数因为循环周期的存在,无法生成真正的随机数(力扣那题用这个方法也跑不通XD)
- Fisher–Yates shuffle 洗牌算法
这个方法太漂亮勒!
另外这个作者的写法也很漂亮!棒!
洗牌算法的思路是:
【1】先从数组末尾开始,选取最后一个元素,与数组中随机一个位置的元素交换位置
【2】然后在已经排好的最后一个元素以外的位置中,随机产生一个位置,让该位置元素与倒数第二个元素进行交换
以此类推,打乱整个数组的顺序
function shuffle(arr) {
let len = arr.length;
while (len) {
let i = (Math.random() * len--) >> 0;// 获得随机数
// 交换位置
let temp = arr[len];
arr[len] = arr[i];
arr[i] = temp;
}
return arr;
}再结合 ES6 的解构赋值,使用洗牌算法就更方便了:
Array.prototype.shuffle = function() {
let m = this.length, i;
while (m) {
i = (Math.random() * m--) >>> 0;
[this[m], this[i]] = [this[i], this[m]]
}
return this;
}【1】暴力toString
嗯 Array.prototype.toString() 能这么用是我没想到的

再遍历下数组对数组元素挨个Number()一下 字符串->整数
- 不使用API来打平多维数组
参考:红宝书
结合下面的过程看 很清晰~

本算法的递归调用边界和平常力扣(做二叉树/链表)遇到的不太相似(设置一个退出条件)
本算法中,只有前面的if else执行完了,才会弹出递归调用栈~
理解这一点 就很好想了!
另外,递归出口(弹栈时机)——
return xxx;把这个点想好,也是理解递归问题的关键!
【2】出递归调用栈时 0插入结果数组(return flattenedArray——[0])
然后的一维元素没有进入递归调用栈 1 2插入结果数组
【3】将函数flatten([3,[4,5]], [0,1,2]) 插入递归调用栈
【4】调用flatten([3,[4,5]], [0,1,2]) 时 3插入结果数组
【5】将函数flatten([4,5],[0,1,2,3]) 插入递归调用栈
【6】出递归调用栈时 4 5插入结果数组(return flattenedArray——[4,5])
最终flatten([3,[4,5]], [0,1,2])弹出递归调用栈(这块儿上面的图不太对哈!)(return flattenedArray——[0,1,2,3,4,5])
然后的一维元素没有进入递归调用栈 插入结果数组6
- 限定打平到第几层嵌套递归
参考 红宝书

- 调用ES2019的新API flat~~
arr.flat(Infinity)可以扁平化不管多深的多维数组~

- 还有一个没咋见过的flatMap()操作hhh

知识点:V8中sort函数的实现机制
sort()方法用原地算法对数组的元素进行排序,并返回数组。默认排序顺序是在将元素转换为字符串,然后比较它们的UTF-16代码单元值序列时构建的— MDN
关于
Array.prototype.sort(),ES 规范并没有指定具体的算法,在 V8 引擎中, 7.0 版本之前 ,数组长度小于10时,Array.prototype.sort()使用的是插入排序,否则用快速排序。在 V8 引擎 7.0 版本之后 就舍弃了快速排序,因为它不是稳定的排序算法,在最坏情况下,时间复杂度会降级到 O(n^2^)。
于是采用了一种混合排序的算法:TimSort 。
这种功能算法最初用于Python语言中,严格地说它不属于以上10种排序算法中的任何一种,属于一种混合排序算法:
在数据量小的子数组中使用插入排序,然后再使用归并排序将有序的子数组进行合并排序,时间复杂度为
O(nlogn)。作者:an_371e 链接:https://www.jianshu.com/p/a557e9006186 来源:简书 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
对象是非常重要的概念
我们把对象理解为:存放属性的容器
-
常用的内置对象:Math JSON Map Set Array
-
JSON是序列化传输数据的方式(是一个数据格式)
-
JSON.stringify()方法将一个 JavaScript 对象或值转换为 JSON 字符串-
console.log(JSON.stringify({ x: 5, y: 6 })); // expected output: "{"x":5,"y":6}" console.log(JSON.stringify([new Number(3), new String('false'), new Boolean(false)])); // expected output: "[3,"false",false]" console.log(JSON.stringify({ x: [10, undefined, function(){}, Symbol('')] })); // expected output: "{"x":[10,null,null,null]}" console.log(JSON.stringify(new Date(2006, 0, 2, 15, 4, 5))); // expected output: ""2006-01-02T15:04:05.000Z""
-
-
JSON.parse()方法用来解析JSON字符串,构造由字符串描述的JavaScript值或对象-
const json = '{"result":true, "count":42}'; const obj = JSON.parse(json); console.log(obj.count); // expected output: 42 console.log(obj.result); // expected output: true
-
-
-
-
宿主对象
- 浏览器宿主:Window、History、Location
- Node宿主:global等
toString方法在Object的显示原型上,其他对象对toString方法进行了重写~

toString() 方法可把一个 Number 对象转换为一个字符串,并返回结果。
语法
NumberObject.toString(radix)// radix就是指进制数比较有趣的一个点

小数居然算是NumberObject…? ==存疑!==
看了下MDN Number.prototype.toString() 依旧困惑。暂且记住好了
- (10) 是 numObj 10不是
- (0.6) 是 numObj 0.6也是numObj

var count = 10; console.log(count.toString()); // 输出 '10' console.log((17).toString()); // 输出 '17' console.log(17.toString()); // Uncaught SyntaxError: Invalid or unexpected token console.log((17.2).toString()); // 输出 '17.2' console.log(17.2.toString()); // 输出 '17.2' var x = 6; console.log(x.toString(2)); // 输出 '110' console.log((254).toString(16)); // 输出 'fe' console.log((-10).toString(2)); // 输出 '-1010' console.log((-0xff).toString(2)); // 输出 '-11111111'又来了个神奇的操作
10..toString();// 输出"10"听前辈说这个是因为 . 指代不明确
- 利用这个方法 配合
substr()方法 可以实现随机验证码生成
Math.random().toString(36).substr(2, 10);// 以36进制将随机数转换为随机字符串,从得到的随机字符串的第二位开始拿10个字符~根本重复不了!以36进制将随机数转换为随机字符串,从得到的随机字符串的第二位开始拿10个字符~根本重复不了!

Function.prototype.call() - JavaScript | MDN (mozilla.org)
call() 方法使用一个指定的 this 值和单独给出的一个或多个参数来调用一个函数。
注意:该方法的语法和作用与 apply() 方法类似,只有一个区别,就是 call() 方法接受的是一个参数列表,而 apply() 方法接受的是一个包含多个参数的数组。
function Product(name, price) {
this.name = name;
this.price = price;
}
function Food(name, price) {
Product.call(this, name, price);
console.log(this);// Object { name: "cheese", price: 5 }
this.category = 'food';
}
console.log(new Food('cheese', 5).name);// "cheese"apply() 方法调用一个具有给定this值的函数
const numbers = [5, 6, 2, 3, 7];
const max = Math.max.apply(null, numbers);
console.log(max);// expected output: 7
const min = Math.min.apply(null, numbers);
console.log(min);// expected output: 2bind() 方法创建一个新的函数,在 bind() 被调用时,这个新函数的 this 被指定为 bind() 的第一个参数,而其余参数将作为新函数的参数,供调用时使用。
const module = {
x: 42,
getX: function() {
return this.x;
}
};
const unboundGetX = module.getX;
console.log(module.getX()); // 42
console.log(unboundGetX()); // The function gets invoked at the global scope expected output: undefined
// expected output: undefined
const boundGetX = unboundGetX.bind(module);
console.log(boundGetX());// expected output: 42通过原型链实现子类对父类的继承
Child.prototype = new Father();别忘了修正Child类显示原型的
constructor
Child.prototype.constructor = Child
-
原型链继承 : 得到方法
- 通过
Child.prototype = new Parent()继承父函数 从而继承了属性与方法 - 缺点:通过Child构造的对象 的原型对象 的
constructor属性指向Parent!这不好!- 我们需要让子类型的原型的
constructor指向子类型 才对! - 这个问题可以通过
Child.prototype.constructor = Child;来修正constructor属性
- 我们需要让子类型的原型的
function Parent(){} Parent.prototype.test = function(){}; function Child(){} Child.prototype = new Parent(); // 子类型的原型指向父类型实例 Child.prototype.constructor = Child;// 修正constructor属性 var child = new Child(); //有test()
- 通过
-
借用构造函数 : 得到属性
- 通过
Parent.call(this,name,age)继承(调用父类型构造函数) - 缺点:获得父类型的方法很麻烦!还得借助call方法一个个地弄
Parent.func.call(this,参数)
function Parent(xxx){this.xxx = xxx} Parent.prototype.test = function(){}; function Child(xxx,yyy){ Parent.call(this, xxx);//借用构造函数 this.Parent(xxx) // 相当于 this.Parent(xxx) } var child = new Child('a', 'b'); //child.xxx为'a', 但child没有test()
- 通过
-
组合
function Parent(xxx){this.xxx = xxx} Parent.prototype.test = function(){}; function Child(xxx,yyy){ Parent.call(this, xxx);//借用构造函数 this.Parent(xxx) } Child.prototype = new Parent(); //得到test() var child = new Child(); //child.xxx为'a', 也有test()
使用 原型链结合构造函数
在父类型属性有很多条时 使用
Parent.call(this,父函数属性)让子类型继承
function Parent(attribute,other){
this.attribute = attribute;
this.other = other;
}
Parent.prototype.output = function(){
console.log("此方法位于Parent的显式原型中 Child构造函数继承了我 所以Child的实例对象可以顺着隐式原型连找到这个对象(在Object对象上)");
}
function Child(attribute, other){
Parent.call(this,attribute,other);// 继承父类型的属性
}
Child.prototype = new Parent();// 原型链继承!让子类型的显式原型指向父类型的实例!
Child.prototype.constructor = Child;// 出于严谨 这里修正constructor属性 要不然Child的显式原型的constructor就是Parent了 这就很奇怪!
var child = new Child('a', 'b');// ['a', 'b']
child.output();
上面的属性的输出有些问题
JS继承最佳实践完整版输出如下:

好吧上面的还是不全 有点小问题——
Child.prototype.constructor = Child;// 出于严谨 这里修正constructor属性 要不然Child的显式原型的constructor就是Parent了 这就很奇怪!
// 修正完 constructor指向Child构造函数
this会作为变量一直向上级词法作用域查找,直至找到为止
coderwhy文章
call()方法使用一个指定的this值和单独给出的一个或多个参数来调用一个函数。该方法的语法和作用与
apply()方法类似,只有一个区别,就是call()方法接受的是一个参数列表,而apply()方法接受的是一个包含多个参数的数组。function.call(thisArg, arg1, arg2, ...)
- thisArg
可选的。在
function函数运行时使用的this值。请注意,
this可能不是该方法看到的实际值:如果这个函数处于非严格模式下,则指定为null或undefined时会自动替换为指向全局对象,原始值会被包装。
- arg1, arg2, ...
指定的参数列表。
由于 箭头函数没有自己的this指针,通过 call() 或 apply() 方法调用一个函数时,只能传递参数(不能绑定this---译者注),他们的第一个参数会被忽略。(这种现象对于bind方法同样成立---译者注)
举个例子就知道了
var adder = {
base: 1,
add:function(a){
var f = value => value + this.base;
return f(a);// thisArg未指定则默认指向全局对象adder
},
addThruCall:function(a){
var b = {base: 666};
var f = value => value + this.base;// 如果这里是个普通函数,则进行call时,将给b这个对象调用f方法,base为666
return f.call(b, a);
}
}
console.log(adder.add(1));// 2(adder.base + 1)
console.log(adder.addThruCall(1));// 2(依然是adder.base(而不是b.) + 1)this指向函数运行时所在的环境,那么为什么this关键字有这样的作用?函数的运行环境是如何决定的?看看阮一峰大大写得这篇文章,你会有新的感悟!(真的让我对内存、对象等知识都有了新的认识!)
粘一下this的定义:
由于函数可以在不同的运行环境执行,所以需要有一种机制,能够在函数体内部获得当前的运行环境(context)。所以,
this就出现了,它的设计目的就是在函数体内部,指代函数当前的运行环境。
在JavaScript中
this的指向总是让人很困惑,它到底指的啥?。this在不同的执行环境,不同的用法下会有所不同,以下分几种情况,讨论this的指向。
总结:
- 对于函数中的
this,通过查看()左边所属的对象去确定,真的很好用。- 实质上,
this是在创建函数的执行环境时,在创建阶段确定的,因此,弄透执行环境,去思考执行环境创建阶段的this的指向,this的指向就不会弄错了雀氏!在使用new关键字创建对象时,其中一步就是“构造函数内部的this被赋值为这个创建好的新对象(即this指向新对象)”(参考红宝书)

又是一篇前辈的文章,例子和情景都很全面!
小结:
函数在执行时,会在函数体内部自动生成一个this指针。谁直接调用产生这个this指针的函数,this就指向谁。
由于js是采用的静态作用域(也叫词法作用域),这就意味着函数的执行依赖于函数定义的时候所产生(而不是函数调用的时候产生)的变量作用域。
在全局作用域中“定义”一个函数的时候,只会创建包含全局作用域的作用域链。只有“执行”该函数的时候,才会复制创建时的作用域,并将当前函数的局部作用域放在作用域链的顶端。
去取变量值的时候,首先看本函数里有没有该值,如果没有再到函数定义的外部去找
[JavaScript中arguments0表示的是什么?](https://www.zhihu.com/question/21466212)
var length = 10;
function fn(){
alert(this.length)
}
var obj = {
length: 5,
method: function(fn) {
arguments[0]()
}
}
obj.method(fn)// 输出1
obj.method(fn,1,1)// 输出3为啥这里的this指向了arguments呢?因为在Javascript里,数组只不过使用数字做属性名的方法,也就是说:arguments[0]()的意思,和arguments.0()的意思差不多(当然这么写是不允许的),你更可以这么理解:
arguments = {
0: fn, //也就是 functon() {alert(this.length)}
1: 第二个参数, //没有
2: 第三个参数, //没有
...,
length: 1 //只有一个参数
}- 变式 输出10
var length = 10;
function fn(){
alert(this.length)
}
var obj = {
length: 5,
method: function(fn) {
fn()
}
}
obj.method(fn)// 输出10——全局的length- 变式 输出5
var length = 10;
function fn(){
console.log(this.length)
}
var obj = {
length: 5,
method: fn
}
obj.method()// 输出5 fn中的this绑定的是objvar length = 10;
function fn(){
console.log(this.length)
}
var obj = {
length: 5,
method: function(fn) {
fn.call(obj)
// fn.call(this)
}
}
obj.method(fn)1.箭头函数的参数只有一个时,可以省略小括号(但是!这里最好是带上括号哦!),函数里面的执行语句只有一条时,可以省略花括号(但是!如果回调函数没有return 则最好加上大括号 ——减少副作用) 2.箭头函数本身没有this,它会继承作用域链上一层的this 3.箭头函数不能使用call, bind, apply来改变this指向
function foo() {
console.log('1')
}
let foo = ()=> {
console.log('1')
}//普通函数
foo()
function foo() {
console.log('1')
}
//箭头函数
foo() //报错 foo is not a function
let foo = ()=> {
console.log('1')
}let Person = (name) => {
this.name = name
}
let xiao_ming = new Person('小明')
console.log(xiao_ming.name) //undefined普通函数的this指向的是谁调用该函数就指向谁
箭头函数的this指向的是在你书写代码时候的上下文环境对象的this,如果没有上下文环境对象,那么就指向最外层对象window。
function foo() {
console.log(arguments)
let foo1 = () => {
console.log(arguments)
}
foo1()
}
foo('test')
//[Arguments] { '0': 'test' }
//[Arguments] { '0': 'test' }先说明下new.target是干嘛的,这家伙是用来检测函数是否被当做构造函数使用,他会返回一个指向构造函数的引用。
因为箭头函数不能当做构造函数使用,自然是没有new.target的。
其实this指向的问题情况并不多,但是它在不同的执行条件下可能会绑定(指向)不同的对象,如果想要再深入了解,可以看一下coderwhy的这篇文章
- 普通函数中:this->window
- 定时器中:this->window
- 构造函数中:this->当前实例化的对象
- 事件处理函数中:this->事件触发对象
- 在 js 中一般理解就是谁调用这个 this 就指向谁
每一个构造函数的内部都有一个 prototype 属性,它的属性值是一个对象,这个对象包含了可以由该构造函数的所有实例共享的属性和方法。
当使用构造函数新建一个对象后,在这个对象的内部将包含一个指针,这个指针指向构造函数的 prototype 属性对应的值,在 ES5 中这个指针被称为对象的原型。
浏览器中实现了 __proto__ 属性来访问这个属性,但是最好不要使用这个属性,因为它不是规范中规定的。
ES5 中新增了一个 Object.getPrototypeOf() 方法,可以通过这个方法来获取对象的原型。
使用hasOwnProperty()方法来判断属性是否属于原型链的属性:
hasOwnProperty()方法会返回一个布尔值,指示对象自身属性中是否具有指定的属性(也就是,是否有指定的键)。
function iterate(obj){
var res=[];
for(var key in obj){
if(obj.hasOwnProperty(key))
res.push(key+': '+obj[key]);
}
return res;
} 这不比判断原型链啥的省脑子hh(当然方法还是得顺着原型链找咯)
isPrototypeOf() 方法用于测试一个对象是否存在于另一个对象的原型链上。
isPrototypeOf()与instanceof运算符不同。在表达式 "object instanceof AFunction"中,object的原型链是针对AFunction.prototype进行检查的,而不是针对AFunction本身。
本示例展示了 Baz.prototype, Bar.prototype, Foo.prototype 和 Object.prototype 在 baz 对象的原型链上:
function Foo() {}
function Bar() {}
function Baz() {}
Bar.prototype = Object.create(Foo.prototype);
Baz.prototype = Object.create(Bar.prototype);
var baz = new Baz();
console.log(Baz.prototype.isPrototypeOf(baz)); // true
console.log(Bar.prototype.isPrototypeOf(baz)); // true
console.log(Foo.prototype.isPrototypeOf(baz)); // true
console.log(Object.prototype.isPrototypeOf(baz)); // true对闭包Scope的理解
另外之前写过一篇入门级的文章 从函数提升谈到闭包~
闭包是指有权访问另一个函数作用域中变量的函数,创建闭包的最常见的方式就是在一个函数内创建另一个函数,创建的函数可以访问到当前函数的局部变量。
- 比如,函数 A 内部有一个函数 B,函数 B 可以访问到函数 A 中的变量,那么函数 B 就是闭包。
function A() {
let a = 1
window.B = function () {
console.log(a)
}
}
A()
B() // 1在 JS 中,闭包存在的意义就是让我们可以间接访问函数内部的变量。

- 经典面试题:循环中使用闭包解决 var 定义函数的问题
for (var i = 1; i <= 5; i++) {
setTimeout(function timer() {
console.log(i)
}, i * 1000)
}首先因为 setTimeout 是个异步函数,所以会先把循环全部执行完毕,这时候 i 就是 6 了,所以会输出一堆 6。解决办法有三种:
- 第一种是使用闭包的方式
for (var i = 1; i <= 5; i++) {
(function(j) {
setTimeout(function timer() {
console.log(j)
}, j * 1000)
})(i)
}在上述代码中,首先使用了立即执行函数将 i 传入函数内部,这个时候值就被固定在了参数 j 上面不会改变,当下次执行 timer 这个闭包的时候,就可以使用外部函数的变量 j,从而达到目的。
- 第二种就是使用
setTimeout的第三个参数,这个参数会被当成timer函数的参数传入。
for (var i = 1; i <= 5; i++) {
setTimeout(
function timer(j) {
console.log(j)
},
i * 1000,
i
)
}- 第三种就是使用
let定义i了来解决问题了,这个也是最为推荐的方式
for (let i = 1; i <= 5; i++) {
setTimeout(function timer() {
console.log(i)
}, i * 1000)
}研究闭包的时候很好奇,啥时候闭包被销毁?
最终结论-如果没有特殊的垃圾回收算法(暂时没有搜索到有这种算法)会造成闭包常驻!除非手动设置为null 否则就会造成内存泄露!
查阅官方文档——
高级语言解释器嵌入了“垃圾回收器”,它的主要工作是跟踪内存的分配和使用,以便当分配的内存不再使用时,自动释放它。这只能是一个近似的过程,因为要知道是否仍然需要某块内存是无法判定的(无法通过某种算法解决)。
“垃圾回收实现只能有限制的解决一般问题,垃圾回收算法主要依赖于引用的概念。”
举个例子(来自官方文档,我加了一些注释)
var o = {
a: {
b:2
}
};
// 下面提到的"这个对象" 即为 {a:{b:2}}
// 两个对象被创建,一个作为另一个的属性被引用,另一个被分配给变量o
// 很显然,没有一个可以被垃圾收集
var o2 = o; // o2变量是第二个对“这个对象”的引用
o = 1; // 现在,“这个对象”只有一个o2变量的引用了,“这个对象”的原始引用o(原来是对象{a:{b:2}},现在是个数值型,直接扔栈里就可以了!)已经没有
var oa = o2.a; // 引用“这个对象”的a属性
// 现在,“这个对象”有两个引用了,一个是o2,一个是oa
o2 = "yo"; // 虽然最初的对象现在已经是零引用了,可以被垃圾回收了
// 但是它的属性a的对象还在被oa引用,所以还不能回收
oa = null; // a属性的那个对象现在也是零引用了
// 它可以被垃圾回收了(1)全局作用域
- 最外层函数和最外层函数外面定义的变量拥有全局作用域
- 所有未定义直接赋值的变量自动声明为全局作用域
- 所有window对象的属性拥有全局作用域
- 全局作用域有很大的弊端,过多的全局作用域变量会污染全局命名空间,容易引起命名冲突。
(2)函数作用域
- 函数作用域声明在函数内部的变量,一般只有固定的代码片段可以访问到
- 作用域是分层的,内层作用域可以访问外层作用域,反之不行
- 使用ES6中新增的let和const指令可以声明块级作用域,块级作用域可以在函数中创建也可以在一个代码块中创建(由
{ }包裹的代码片段) - let和const声明的变量不会有变量提升,也不可以重复声明
- 在循环中比较适合绑定块级作用域,这样就可以把声明的计数器变量限制在循环内部。
在当前作用域中查找所需变量,但是该作用域没有这个变量,那这个变量就是自由变量。如果在自己作用域找不到该变量就去父级作用域查找,依次向上级作用域查找,直到访问到window对象就被终止,这一层层的关系就是作用域链。
作用域链的作用是保证对执行环境有权访问的所有变量和函数的有序访问,通过作用域链,可以访问到外层环境的变量和函数。
作用域链的本质上是一个指向变量对象的指针列表。变量对象是一个包含了执行环境中所有变量和函数的对象。作用域链的前端始终都是当前执行上下文的变量对象。全局执行上下文的变量对象(也就是全局对象)始终是作用域链的最后一个对象。
当查找一个变量时,如果当前执行环境中没有找到,可以沿着作用域链向后查找。
(1)全局执行上下文
任何不在函数内部的都是全局执行上下文,它首先会创建一个全局的window对象,并且设置this的值等于这个全局对象,一个程序中只有一个全局执行上下文。
(2)函数执行上下文
当一个函数被调用时,就会为该函数创建一个新的执行上下文,函数的上下文可以有任意多个。
- JavaScript引擎使用执行上下文栈来管理执行上下文
- 当JavaScript执行代码时,首先遇到全局代码,会【1】创建一个全局执行上下文并且压入执行栈中,每当遇到一个函数调用,就会【2】为该函数创建一个新的执行上下文并压入栈顶,引擎会执行位于执行上下文栈顶的函数,当函数执行完成之后,【3】执行上下文从栈中弹出,【4】继续执行下一个上下文。当所有的代码都执行完毕之后,从【5】栈中弹出全局执行上下文。
let a = 'Hello World!';
function first() {
console.log('Inside first function');// 1
second();// 2
console.log('Again inside first function');// 3
}
function second() {
console.log('Inside second function');
}
first();
//执行顺序
//先执行second(),再执行first()-这里存疑 虽说second函数确实是在栈顶吧!创建执行上下文有两个阶段:创建阶段和执行阶段
1)创建阶段
(1)this绑定
- 在全局执行上下文中,this指向全局对象(window对象)
- 在函数执行上下文中,this指向取决于函数如何调用。如果它被一个引用对象调用,那么 this 会被设置成那个对象(
let func = new Fn()这里构造函数中的this就被设置为这个实例对象了!),否则 this 的值被设置为全局对象或者 undefined
下面这俩没听说过的说
(2)创建词法环境组件
- 词法环境是一种有标识符——变量映射的数据结构,标识符是指变量/函数名,变量是对实际对象或原始数据的引用。
- 词法环境的内部有两个组件:加粗样式:环境记录器:用来储存变量个函数声明的实际位置外部环境的引用:可以访问父级作用域
(3)创建变量环境组件
- 变量环境也是一个词法环境,其环境记录器持有变量声明语句在执行上下文中创建的绑定关系。
2)执行阶段
此阶段会完成对变量的分配,最后执行完代码。
简单来说执行上下文就是指:
在执行一点JS代码之前,需要先解析代码。解析的时候会【1】先创建一个全局执行上下文环境,先【2】把代码中即将执行的变量、函数声明都拿出来,【3】变量先赋值为undefined,【4】函数先声明好可使用。这一步执行完了,才【5】开始正式的执行程序。
在一个函数执行之前,也会创建一个函数执行上下文环境,跟全局执行上下文类似,不过函数执行上下文会多出this、arguments和函数的参数。
- 全局上下文:变量定义,函数声明
- 函数上下文:变量定义,函数声明,
this,arguments
var x = 10;
function fn(){
console.log(x);// 10
}
function show(f){
var x = 20;
f();
}
show(fn);// 打印10记住一句话——
在其他函数中被调用不影响x在打印语句中的值(x在一开始定义的时候就确定了 打印的x是全局中的(毕竟是在人家全局那里调用的函数show嘛~))
21/10/17 更新 感觉可以用执行上下文来解释?毕竟涉及到了函数调用,很动态~

21/10/31更新
又见到了一次这道题
感觉上面的说法可能有一定道理,但是作用域的“静态性”才是最权威解释——在调用一个函数时,要找到它最开始被创建时的位置,进行寻值
var fn = function () {
console.log(fn)//function(){console.log(fn)}
var fn2 = function(){
console.log("找不到我吧~");
}
}
fn()
var obj = {
fn2: function () {
console.log(fn2)// 报错 fn2 is not defined
console.log(this.fn2)//function(){...}
}
}
obj.fn2()-
首先 第二行的打印是 fn对象(人家顺着作用域链就能轻松找到位于全局作用域中的fn咯~)
-
第十一行 报错 来看看fn2的心路历程
- 先在fn2构造函数的函数作用域中找 没有定义过fn2!
- 再去全局作用域里找 全局变量也没它这号变量!
- 再去同级的函数作用域里找找行么?
- 不行!😂
-
第十二行 打印fn2对象 加上this 表示obj对象 obj对象拥有这个fn2函数啊 没问题~

简单来说
如果await等到的不是一个 Promise 对象,那 await 表达式的运算结果就是它等到的东西。 如果await等到的是一个 Promise 对象,await 就忙起来了,它会阻塞后面的代码,等着 Promise 对象 resolve,然后得到 resolve 的值,作为 await 表达式的运算结果。
举例,用 setTimeout 模拟耗时的异步操作,先来看看不用 async/await 会怎么写
function takeLongTime() {
return new Promise(resolve => {
setTimeout(() => resolve("long_time_value"), 1000);
});
}
takeLongTime().then(v => {
console.log("got", v);
});如果改用 async/await 呢,会是这样
function takeLongTime() {
return new Promise(resolve => {
setTimeout(() => resolve("long_time_value"), 1000);
});
}
async function test() {
const v = await takeLongTime();
console.log(v);
}
test();单一的 Promise 链并不能发现 async/await 的优势,但是,如果需要处理由多个 Promise 组成的 then 链的时候,优势就能体现出来了(很有意思,Promise 通过 then 链来解决多层回调的问题,现在又用 async/await 来进一步优化它)。
假设一个业务,分多个步骤完成,每个步骤都是异步的,而且依赖于上一个步骤的结果。我们仍然用 setTimeout 来模拟异步操作:
/**
* 传入参数 n,表示这个函数执行的时间(毫秒)
* 执行的结果是 n + 200,这个值将用于下一步骤
*/
function takeLongTime(n) {
return new Promise(resolve => {
setTimeout(() => resolve(n + 200), n);
});
}
function step1(n) {
console.log(`step1 with ${n}`);
return takeLongTime(n);
}
function step2(n) {
console.log(`step2 with ${n}`);
return takeLongTime(n);
}
function step3(n) {
console.log(`step3 with ${n}`);
return takeLongTime(n);
}现在用 Promise 方式来实现这三个步骤的处理
function doIt() {
console.time("doIt");
const time1 = 300;
step1(time1)
.then(time2 => step2(time2))
.then(time3 => step3(time3))
.then(result => {
console.log(`result is ${result}`);
console.timeEnd("doIt");
});
}
doIt();
// c:\var\test>node --harmony_async_await .
// step1 with 300
// step2 with 500
// step3 with 700
// result is 900
// doIt: 1507.251ms输出结果 result 是 step3() 的参数 700 + 200 = 900。doIt() 顺序执行了三个步骤,一共用了 300 + 500 + 700 = 1500 毫秒,和 console.time()/console.timeEnd() 计算的结果一致。
如果用 async/await 来实现呢,会是这样
async function doIt() {
console.time("doIt");
const time1 = 300;
const time2 = await step1(time1);
const time3 = await step2(time2);
const result = await step3(time3);
console.log(`result is ${result}`);
console.timeEnd("doIt");
}
doIt();结果和之前的 Promise 实现是一样的,但是这个代码看起来是不是清晰得多,==几乎跟同步代码一样==
获取DOM中的节点
document.getElementById('id')document.querySelector('selecotrs')- id、class
querySelector('#root')
- 更高级一些——标签名、CSS属性值
querySelector(input[name = 'login'])name属性为login的input元素
- id、class
动态地创建节点并插入到DOM中
element.style.xxx(MDN里甚至没有中文ORZ)- 设置获取元素的属性
document.createElement(要创建的标签名称/类名)node.appendChild(子节点)- 将子节点追加给父节点
Element.innerHTML
获取/设置元素的样式
监听事件
- 注册事件方法1
- 内容HTML和交互JS绑定在一起了,这样不好~(比较古老的写法)
<button id='btn'>onclick = "eventLog('onclick')"</button>
<script>
function eventLog(type){
console.log('触发的事件是:' + type)
}
</script>- 注册事件的方法2
- 不用给标签加事件,直接用JS获取标签对应的元素然后使用
addEventListener(这个用得真的超级多!)
- 不用给标签加事件,直接用JS获取标签对应的元素然后使用
function eventLog(type){
console.log('触发的事件是:' + type)
}
const btn = document.querySelector('#btn');
btn.addEventListener('click', function(){
eventLog('onclick');
})-
常见事件
- 鼠标点击事件
onclick = "回调函数"
- 鼠标移入移出事件
onmouseover = "回调函数" onmouseout = "回调函数"
- 文本改变事件
onchange = "回调函数";// 经常用onchange来监听输入框中的改变
- 键盘输入事件
oninput = "回调函数";// 用这个监听全局的键盘键入
- 输入框(光标)focus(聚焦)事件
onfocus = "回调函数"
- 输入框(光标)blur失焦事件
onblur = "回调函数"
-
虽然我们现在侦听事件一般用
addEventListener(‘xxx’, 回调函数)吧~(不包括框架!)但是原生的JS操作DOM还是要理解咧!- 因为追溯根源,框架就是帮助我们操作了DOM文档对象模型,后期性能优化的了解上这个必不可少!
浏览器对象模型(Browser Object Model)的核心是 window 对象。是每个浏览器⼚商在浏览器上提供的,提供与浏览器交互的⽅法和接⼝(⽐如,跳转⻚⾯,获取窗⼝⼤⼩,获 取历史记录,获取当前页面URL,获取⽂档节点等) ⼤部分我们常⽤的接⼝都是相同的调⽤⽅式,但是浏览 器他们底层实现的⽅式会不同。
- method01 页面元素(标签)提供的事件属性
<button onclick="myClick()" id="btn">xx</button>- method02 使用DOM对象的事件属性
var btn = document.getElementById("btn");
// 给指定元素添加事件监听器
btn.onclick = myClick;
function myClick(){
xxx
}- method03 事件监听器
var btn = document.getElementById("btn");
// 给指定元素添加事件监听器
btn.addEventListener('click', function () {
xxx
})借鉴了这里
可以通过addEventListener()的第三个参数来确定捕获还是冒泡,第一个参数是要绑定的事件,第二个参数是回调函数,第三个参数默认是false,代表事件冒泡阶段调用事件处理函数,如果设置成true,则在事件捕获阶段调用处理函数。
冒泡:
点这个demo试试看
还可以点JS30中第25个demo
微软提出了事件冒泡的事件流,事件会从最内层的元素开始发生,一直向上传播,直到document对象。p元素上发生click事件的顺序应该是p -> body -> html -> document
捕获:
网景提出了事件捕获的事件流,事件捕获相反,事件会从最外层开始发生,直到最具体的元素。p元素上发生click事件的顺序应该是document -> html -> body -> div -> p
W3C制定了统一的标准,先捕获再冒泡。
可以通过addEventListener()的第三个参数来确定捕获还是冒泡,第一个参数是要绑定的事件,第二个参数是回调函数,第三个参数默认是false,代表事件冒泡阶段调用事件处理函数,如果设置成true,则在事件捕获阶段调用处理函数。
在浏览器中,如果父子元素都设置了捕获和冒泡的输出,当点击子元素时:
- 先捕获父元素
- 子元素输出先注册的事件,如果是捕获先输出捕获,如果是冒泡先输出冒泡
- 再输出父元素的冒泡事件
使用
event.stopPropagation();// 阻止冒泡event.defaultPrevented();// 阻止点击事件
event.cancelable();// 这样也可以?!图如果看不了的话 直接访问图片链接好了orz
https://gitee.com/su-fangzhou/blog-image/raw/master/202111150020231.png

const map = new Map([
["(", ")"],
["[", "]"],
["{", "}"]
])键值对不多可以用map.set(key, value)
碰到一道力扣 677. 键值映射,用到了字符串的这个API,很有趣也很实用!
var MapSum = function() {
this.map = new Map();
};
MapSum.prototype.insert = function(key, val) {
this.map.set(key, val);
};
MapSum.prototype.sum = function(prefix) {
let res = 0;
for (const s of this.map.keys()) {
console.log(typeof(s));// string
if (s.startsWith(prefix)) {
// 如果s开头是prefix,返回true
res += this.map.get(s);
}
}
return res;
};【7000字】一晚上爆肝浏览器从输入到渲染完毕原理 - 掘金 (juejin.cn)
-
回流(生成渲染树那一步):当渲染树中的一部分(或全部)因为元素的尺寸、布局、显隐发生改变而需要重新构建,就是回流。回流后会进行重绘(上图中 绘制那一步)👇。
- 添加或者删除可见的 DOM 元素
- 元素的位置发生改变
- 元素的尺寸发生改变--边距、填充、边框、宽高
- 内容改变--比如文本改变或者图片大小改变而引起的计算值宽高的改变
- 页面初始化渲染
- 浏览器窗口尺寸改变
-
重绘:当只是元素的外观、风格变化,不影响布局的,重新渲染的过程就叫重绘。
-
回流必将引起重绘,而重绘不一定会引起回流。每个页面至少回流一次,就是在页面第一次加载的时候。
-
如何减少回流和重绘
- 使用 cssText 或者 className 一次性改变属性
- 使用 document fragment
- 对于多次重排的元素,如动画,使用绝对定位脱离文档流,使其改变不影响其他元素。
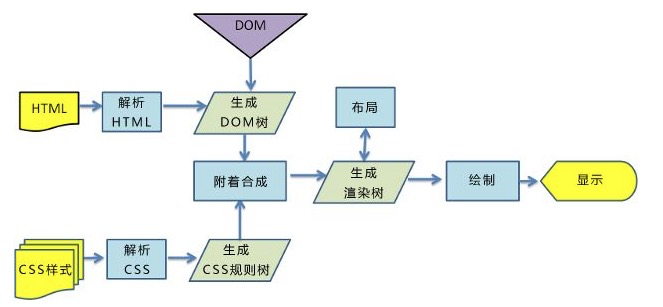
【1】解析 HTML 构建DOM树
【2】解析CSS 构建CSSOM树
【3】利用上面两个树构建渲染树(渲染树的节点即为“渲染对象”)
【4】渲染对象被创建并添加到树中,它们并没有位置和大小,所以当浏览器生成渲染树以后,就会根据渲染树来进行布局(也可以被称作“回流”)这一阶段浏览器要做的事情是要弄清楚各个节点在页面中的确切位置和大小。通常这一行为也被称为“自动重排”。
【5】上述几步过后,布局结束;最后进行绘制,遍历渲染树并调用渲染对象的 paint 方法将它们的内容显示在屏幕上,绘制使用 UI 基础组件。
记住这张图:
完整过程中的一些细节——
- 首先解析收到的文档,根据文档定义构建一棵 DOM 树,DOM 树是由 DOM 元素及属性节点组成的。
- 然后对 CSS 进行解析,生成 CSSOM 规则树。
- 根据 DOM 树和 CSSOM 规则树构建渲染树。渲染树的节点被称为渲染对象,渲染对象是一个包含有颜色和大小等属性的矩形,渲染对象和 DOM 元素相对应,但这种对应关系不是一对一的,不可见的 DOM 元素不会被插入渲染树。还有一些 DOM元素对应几个可见对象,它们一般是一些具有复杂结构的元素,无法用一个矩形来描述。
- 当渲染对象被创建并添加到树中,它们并没有位置和大小,所以当浏览器生成渲染树以后,就会根据渲染树来进行布局(也可以叫做回流)。这一阶段浏览器要做的事情是要弄清楚各个节点在页面中的确切位置和大小。通常这一行为也被称为“自动重排”。
- 布局阶段结束后是绘制阶段,遍历渲染树并调用渲染对象的 paint 方法将它们的内容显示在屏幕上,绘制使用 UI 基础组件。
**注意:**这个过程是逐步完成的,为了更好的用户体验,渲染引擎将会尽可能早的将内容呈现到屏幕上,并不会等到所有的html 都解析完成之后再去构建和布局 render 树。它是解析完一部分内容就显示一部分内容,同时,可能还在通过网络下载其余内容。
- 脚本的加载会阻塞文档解析
如果没有 defer 或 async 属性,浏览器会立即加载并执行相应的脚本。它不会等待后续加载的文档元素,读取到就会开始加载和执行,这样就阻塞了后续文档的加载。
下图可以直观的看出三者之间的区别:
所以script要放在底部/加async defer关键字
拓展学习:
JavaScript 的加载、解析与执行会阻塞文档的解析,也就是说,在构建 DOM 时,HTML 解析器若遇到了 JavaScript,那么它会暂停文档的解析,将控制权移交给 JavaScript 引擎,等 JavaScript 引擎运行完毕,浏览器再从中断的地方恢复继续解析文档。
也就是说,如果想要首屏渲染的越快,就越不应该在首屏就加载 JS 文件,这也是都建议将 script 标签放在 body 标签底部的原因。
- 当然在当下,并不是说 script 标签必须放在底部,因为你可以给 script 标签添加 defer 或者 async 属性。
- CSS 如何阻塞文档解析?
理论上,既然样式表不改变 DOM 树,也就没有必要停下文档的解析等待它们。
面试官也提到了这里,CSS的解析并不阻塞文档~
- 但是可以拓展一下,JS的脚本会因为CSSOM树没被构建好而延迟执行,所以!要把script放在底部/加async defer关键字
然而,存在一个问题,JavaScript 脚本执行时可能在文档的解析过程中请求样式信息(比如根据样式获取元素节点),如果样式还没有加载和解析,脚本将得到错误的值,显然这将会导致很多问题。所以——
如果浏览器尚未完成 CSSOM 的下载和构建,而我们却想在此时运行脚本,那么浏览器将延迟 JavaScript 脚本执行和文档的解析,直至其完成 CSSOM 的下载和构建。也就是说,在这种情况下,浏览器会先下载和构建 CSSOM,然后再执行 JavaScript,最后再继续文档的解析。这样就会间接阻塞了文档解析
前面问的细节,这个问题比较全面了就
要明确——首先渲染的前提是生成渲染树
- 所以 HTML 和 CSS 肯定会阻塞渲染。
如果你想渲染的越快,你越应该降低一开始需要渲染的文件大小,并且扁平层级,优化选择器。
- 浏览器在解析到 script 标签时,会暂停构建 DOM,完成后才会从暂停的地方重新开始。
也就是说,如果你想首屏渲染的越快,就越不应该在首屏就加载 JS 文件,这也是都建议将 script 标签放在 body 标签底部的原因。
拓展知识
并不是说 script 标签必须放在底部,因为你可以给 script 标签添加 defer 或者 async 属性
- 当 script 标签加上 defer 属性以后,表示该 JS 文件会并行下载,但是会放到 HTML 解析完成后顺序执行,所以对于这种情况你可以把 script 标签放在任意位置。
- 同理,对于没有任何依赖的 JS 文件可以加上 async 属性,表示 JS 文件下载和解析不会阻塞渲染(async属性不能保证JS文件的执行是按顺序的~)。
记住下面这个图就好~
蓝色代表 js 脚本网络加载时间,红色代表 js 脚本执行时间,绿色代表 html 解析
又看到篇好文~
看了下这篇文章 简单入门10分钟理解JS引擎的执行机制
注意本文中所有执行流程是基于浏览器环境,而不是node环境
node轮询有phase(阶段)的概念 浏览器和NodeJS中不同的Event Loop
事件循环的核心机制是:宏任务、微任务及其相关队列的执行流程图
单线程的JS通过事件循环 Event Loop 实现异步
JS的执行机制是
- 首先判断JS是同步还是异步,同步就进入主线程,异步就进入event table
- 异步任务在event table中注册函数,当满足触发条件后,被推入event queue
- 同步任务进入主线程后一直执行,直到主线程空闲时,才会去event queue中查看是否有可执行的异步任务,如果有就推入主线程中
以上三步循环执行,这就是event loop
举个例子
console.log(1) setTimeout(function(){ console.log(2) },0) console.log(3)1.console.log(1) 是同步任务,放入主线程里 2.setTimeout() 是异步任务,被放入event table, 0秒之后被推入event queue里 3.console.log(3) 是同步任务,放到主线程里 // 当 1、 3在控制条被打印后,主线程去event queue(事件队列)里查看是否有可执行的函数,执行setTimeout里的函数
但这还不够!
如果有多个任务在event queue里呆着呢?谁先?谁后?上新概念!
上道题
setTimeout(function(){
console.log('定时器开始啦')
});
new Promise(function(resolve){
console.log('马上执行for循环啦');
for(var i = 0; i < 10000; i++){
i == 99 && resolve();
}
}).then(function(){
console.log('执行then函数啦')
});
console.log('代码执行结束');尝试按照,上文我们刚学到的JS执行机制去分析
【1】setTimeout 是异步任务,被放到event table
【2】new Promise 是同步任务,被放到主线程里,直接执行打印 console.log('马上执行for循环啦')
【3】.then里的函数是 异步任务,被放到event table
【4】 console.log('代码执行结束')是同步代码,被放到主线程里,直接执行所以,结果是 【马上执行for循环啦 --- 代码执行结束 --- 定时器开始啦 --- 执行then函数啦】吗?
亲自执行后,结果居然不是这样,而是【马上执行for循环啦 --- 代码执行结束 --- 执行then函数啦 --- 定时器开始啦】
欸?不是setTimeout这个任务先进的event table麽?
并不是!上述根据异步同步一股脑划分的方法不对!
而准确的划分方式是:
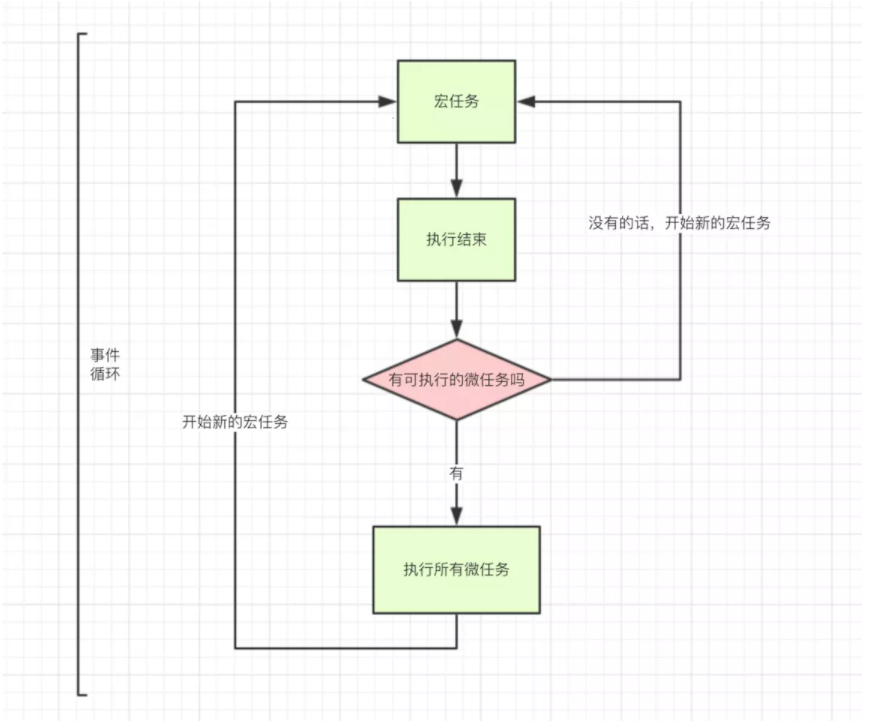
- macro-task(宏任务):包括
script脚本的执行;setTimeout,setInterval一类的定时事件;I/O操作,UI渲染 - micro-task(微任务):
Promise,process.nextTick(Node独有)
按照这种分类方式:JS的执行机制是
- 【1】执行一个宏任务(JS脚本中的内容都是宏任务~),过程中如果【2】遇到微任务,就将其【3】放到微任务的【事件队列】里
- 当前【4】宏任务执行完成后,会查看微任务的【事件队列】,并【5】将里面全部的微任务依次执行完
重复以上2步骤,结合event loop(1) event loop(2) ,就是更为准确的JS执行机制了。
尝试按照刚学的执行机制,去分析例2:
1.首先执行script下的宏任务,遇到setTimeout,将其放到宏任务的【队列】里
2.遇到 new Promise直接执行,打印"马上执行for循环啦"
3.遇到then方法,是微任务,将其放到微任务的【队列里】
4.打印 "代码执行结束"
5.本轮宏任务执行完毕,查看本轮的微任务,发现有一个then方法里的函数, 打印"执行then函数啦"
6.到此,本轮的event loop 全部完成。
7.下一轮的循环里,先执行一个宏任务,发现宏任务的【队列】里有一个 setTimeout里的函数,执行打印"定时器开始啦"所以最后的执行顺序是【马上执行for循环啦 --- 代码执行结束 --- 执行then函数啦 --- 定时器开始啦】
这段setTimeout代码什么意思? 我们一般说: 3秒后,会执行setTimeout里的那个函数
setTimeout(function(){
console.log('执行了')
},3000) 但是这种说并不严谨,准确的解释是: 3秒后,setTimeout里的函数会被推入event queue,而event queue(事件队列)里的任务,只有在主线程空闲时才会执行。
所以只有满足 (1)3秒后 (2)主线程空闲,同时满足时,才会3秒后执行该函数
如果主线程执行内容很多,执行时间超过3秒,比如执行了10秒,那么这个函数只能10秒后执行了

- 同步任务直接进入主执行栈(call stack)中执行
- 等待主执行栈中任务执行完毕,由EL将异步任务推入主执行栈中执行
面试中感觉经常问呐!
网站开发中,如何实现图片的懒加载 - 掘金 (juejin.cn)
图片懒加载实际上是一种网页优化技术。同普通静态资源一样,图片在被请求时,也会占用网络资源。若是一次性将整个页面的所有图片都加载完,这将大大增加页面的首屏加载时间(给人很卡很慢的现象)。为了解决这种问题,开发人员让图片仅在浏览器当前视窗内出现时才进行加载。而这种减少首屏图片请求数,且根据当前视口加载图片的的技术,就被称为“图片懒加载”。(像我平时看的漫画网站就是用的这种方式 导致网速慢的时候 想看漫画得在下拉的过程中等一会儿才行QAQ)
上面说的可能有点绕,这里换句通俗的话:图片懒加载就是鼠标滑动到哪里,图片就加载到哪里。 当然,这话说得不是很严谨,但是胜在易理解。
实现思路:

巩固基础知识,手写并深入理解JS-API

Array.prototype._reduce = function(callback, initialValue){
// 谁调用_reduce this就指向谁~ 为了语义化 这里把this赋值给arr
let arr = this;
if (typeof callback !== "function") {
throw "传入的回调函数捏?";
}
// 初始值有无——reduce的归并操作不同
let index = 0
if (!initialValue) {
index = 1;
acc = arr[0];
} else {
acc = initialValue;
}
for(; index < arr.length; index++){
/**
* Accumulator (acc) (累计器) —— 必须传入
* Current Value (cur) (当前值) —— 必须传入
* Current Index (idx) (当前索引)
* Source Array (src) (源数组)
*/
acc = callback(acc, arr[index], index, arr)
}
return acc
}
let arr = [1,2,3]
console.log(arr._reduce((pre, cur) => pre + cur));// 6
console.log(arr._reduce((pre, cur) => pre + cur, 60));// 66
console.log(arr._reduce(666));// Uncaught 传入的回调函数捏?之前还有方法用来判断arr是否为数组,那步没啥意义 它抛出错误会显示为—— arr._reduce is not a function——毕竟是写在数组原型上的方法 不用数组调肯定是不行的 这个不用额外判断了~